 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTask-guided Spatiotemporal Network with Diffusion Augmentation for EEG-based Dementia Diagnosis and MMSE Prediction
Apr 27, 2026Patients with dementia typically exhibit cognitive impairment, which is routinely assessed using the Mini-Mental State Examination (MMSE). Concurrently, their underlying neurophysiological abnormalities are reflected in Electroencephalography (EEG), providing a basis for joint modeling. However, traditional multi-task approaches suffer from feature entanglement, which leads to inter-task interference when handling heterogeneous objectives.To address this challenge, we propose a task-guided spatiotemporal network (TGSN) with diffusion augmentation for EEG-based dementia diagnosis and MMSE prediction. Specifically, TGSN integrates a multi-band feature fusion module to capture complementary spectral information from EEG. Meanwhile, a pre-trained data augmentation module utilizing a diffusion process is introduced toincrease sample diversity. To model the complex spatiotemporal patterns of EEG, we propose a gated spatiotemporal attention module that captures long-range spatial dependencies and temporal dynamics. Moreover, we design a task-guided query module to achieve task-specific feature extraction, thereby mitigating task interference. The effectiveness of TGSN is evaluated on the XY02 dataset. Experimental results demonstrate that the proposed network outperforms several state-of-the-art methods, achieving classification accuracies of 97.78\% for Alzheimer's Disease (AD)/Frontotemporal Dementia (FTD) and 83.93\% for AD/FTD/Vascular Cognitive Impairment (VCI), which exceed the best baselines by 16.39\% and 8.28\%, respectively. In parallel, it reduces the RMSE for MMSE prediction to 1.93 and 2.38, achieving significant error reductions of 1.44 and 1.43 compared to the best baselines. Additionally, validation on the DS004504 dataset demonstrates strong cross-dataset generalization...
Improving Novel view synthesis of 360$^\circ$ Scenes in Extremely Sparse Views by Jointly Training Hemisphere Sampled Synthetic Images
May 25, 2025Novel view synthesis in 360$^\circ$ scenes from extremely sparse input views is essential for applications like virtual reality and augmented reality. This paper presents a novel framework for novel view synthesis in extremely sparse-view cases. As typical structure-from-motion methods are unable to estimate camera poses in extremely sparse-view cases, we apply DUSt3R to estimate camera poses and generate a dense point cloud. Using the poses of estimated cameras, we densely sample additional views from the upper hemisphere space of the scenes, from which we render synthetic images together with the point cloud. Training 3D Gaussian Splatting model on a combination of reference images from sparse views and densely sampled synthetic images allows a larger scene coverage in 3D space, addressing the overfitting challenge due to the limited input in sparse-view cases. Retraining a diffusion-based image enhancement model on our created dataset, we further improve the quality of the point-cloud-rendered images by removing artifacts. We compare our framework with benchmark methods in cases of only four input views, demonstrating significant improvement in novel view synthesis under extremely sparse-view conditions for 360$^\circ$ scenes.
MMP-2K: A Benchmark Multi-Labeled Macro Photography Image Quality Assessment Database
May 25, 2025Macro photography (MP) is a specialized field of photography that captures objects at an extremely close range, revealing tiny details. Although an accurate macro photography image quality assessment (MPIQA) metric can benefit macro photograph capturing, which is vital in some domains such as scientific research and medical applications, the lack of MPIQA data limits the development of MPIQA metrics. To address this limitation, we conducted a large-scale MPIQA study. Specifically, to ensure diversity both in content and quality, we sampled 2,000 MP images from 15,700 MP images, collected from three public image websites. For each MP image, 17 (out of 21 after outlier removal) quality ratings and a detailed quality report of distortion magnitudes, types, and positions are gathered by a lab study. The images, quality ratings, and quality reports form our novel multi-labeled MPIQA database, MMP-2k. Experimental results showed that the state-of-the-art generic IQA metrics underperform on MP images. The database and supplementary materials are available at https://github.com/Future-IQA/MMP-2k.
Localization of Just Noticeable Difference for Image Compression
Jun 13, 2023



The just noticeable difference (JND) is the minimal difference between stimuli that can be detected by a person. The picture-wise just noticeable difference (PJND) for a given reference image and a compression algorithm represents the minimal level of compression that causes noticeable differences in the reconstruction. These differences can only be observed in some specific regions within the image, dubbed as JND-critical regions. Identifying these regions can improve the development of image compression algorithms. Due to the fact that visual perception varies among individuals, determining the PJND values and JND-critical regions for a target population of consumers requires subjective assessment experiments involving a sufficiently large number of observers. In this paper, we propose a novel framework for conducting such experiments using crowdsourcing. By applying this framework, we created a novel PJND dataset, KonJND++, consisting of 300 source images, compressed versions thereof under JPEG or BPG compression, and an average of 43 ratings of PJND and 129 self-reported locations of JND-critical regions for each source image. Our experiments demonstrate the effectiveness and reliability of our proposed framework, which is easy to be adapted for collecting a large-scale dataset. The source code and dataset are available at https://github.com/angchen-dev/LocJND.
Multi-modal Multi-kernel Graph Learning for Autism Prediction and Biomarker Discovery
Mar 03, 2023Multi-modal integration and classification based on graph learning is among the most challenging obstacles in disease prediction due to its complexity. Several recent works on the basis of attentional mechanisms have been proposed to disentangle the problem of multi-modal integration. However, there are certain limitations to these techniques. Primarily, these works focus on explicitly integrating at the feature level using weight scores, which cannot effectively address the negative impact between modalities. Next, a majority of them utilize single-sized filters to extract graph features, ignoring the heterogeneous information over graphs. To overcome these drawbacks, we propose MMKGL (Multi-modal Multi-Kernel Graph Learning). For the problem of negative impact between modalities, we use the multi-modal graph embedding module to construct a multi-modal graph. Different from the traditional manual construction of static graphs, a separate graph is generated for each modality by graph adaptive learning, where a function graph and a supervision graph are introduced for optimiztion during the multi-graph fusion embedding process. We then apply the multi-kernel graph learning module to extract heterogeneous information from the multi-modal graph. The information in the multi-modal graph at different levels is aggregated by convolutional kernels with different receptive field sizes, followed by generating a cross-kernel discovery tensor for disease prediction. Our method is evaluated on the benchmark Autism Brain Imaging Data Exchange (ABIDE) dataset and outperforms the state-of-the-art methods. In addition, discriminative brain regions associated with autism are identified by our model, providing guidance for the study of autism pathology.
Going the Extra Mile in Face Image Quality Assessment: A Novel Database and Model
Jul 11, 2022
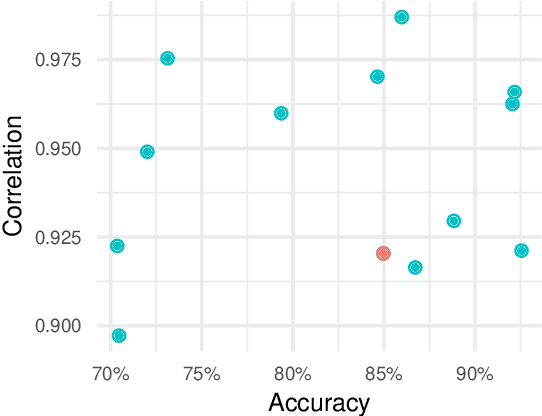

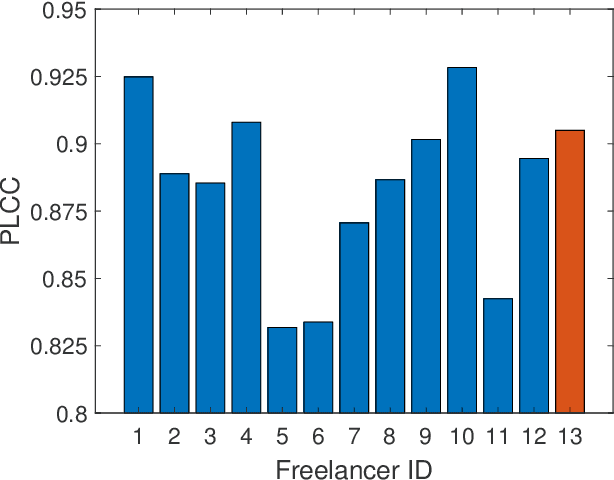
Computer vision models for image quality assessment (IQA) predict the subjective effect of generic image degradation, such as artefacts, blurs, bad exposure, or colors. The scarcity of face images in existing IQA datasets (below 10\%) is limiting the precision of IQA required for accurately filtering low-quality face images or guiding CV models for face image processing, such as super-resolution, image enhancement, and generation. In this paper, we first introduce the largest annotated IQA database to date that contains 20,000 human faces (an order of magnitude larger than all existing rated datasets of faces), of diverse individuals, in highly varied circumstances, quality levels, and distortion types. Based on the database, we further propose a novel deep learning model, which re-purposes generative prior features for predicting subjective face quality. By exploiting rich statistics encoded in well-trained generative models, we obtain generative prior information of the images and serve them as latent references to facilitate the blind IQA task. Experimental results demonstrate the superior prediction accuracy of the proposed model on the face IQA task.
TranSalNet: Visual saliency prediction using transformers
Oct 07, 2021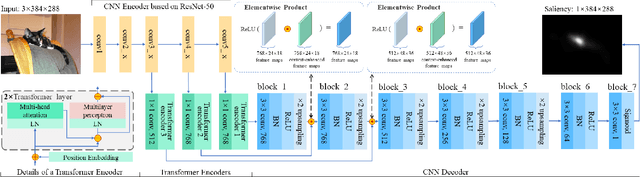


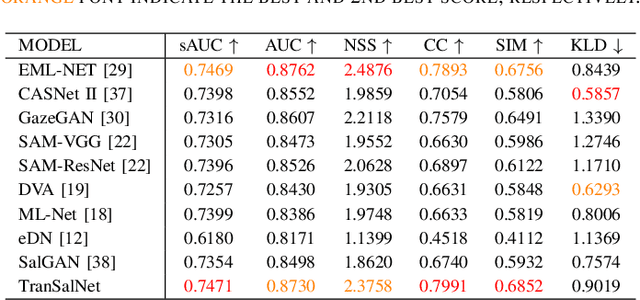
Convolutional neural networks (CNNs) have significantly advanced computational modeling for saliency prediction. However, the inherent inductive biases of convolutional architectures cause insufficient long-range contextual encoding capacity, which potentially makes a saliency model less humanlike. Transformers have shown great potential in encoding long-range information by leveraging the self-attention mechanism. In this paper, we propose a novel saliency model integrating transformer components to CNNs to capture the long-range contextual information. Experimental results show that the new components make improvements, and the proposed model achieves promising results in predicting saliency.
Subjective Image Quality Assessment with Boosted Triplet Comparisons
Jul 31, 2021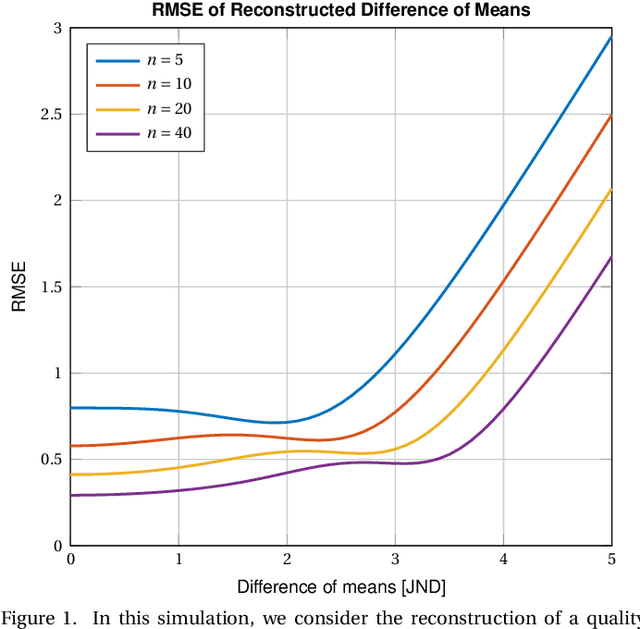


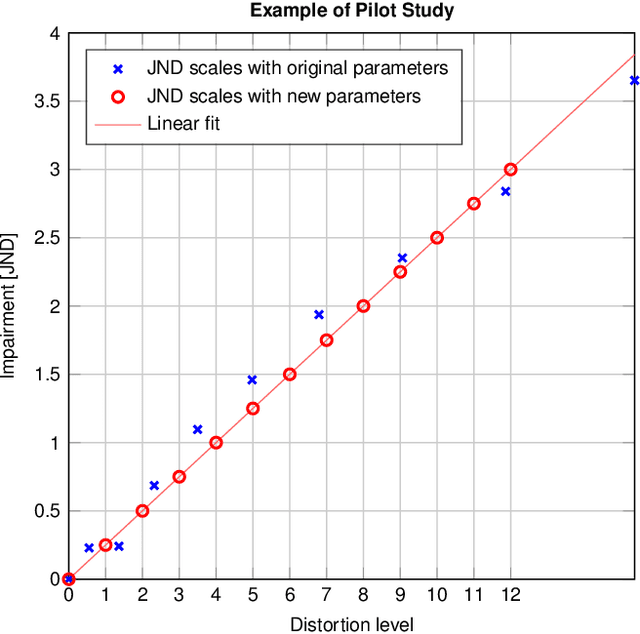
In subjective full-reference image quality assessment, differences between perceptual image qualities of the reference image and its distorted versions are evaluated, often using degradation category ratings (DCR). However, the DCR has been criticized since differences between rating categories on this ordinal scale might not be perceptually equidistant, and observers may have different understandings of the categories. Pair comparisons (PC) of distorted images, followed by Thurstonian reconstruction of scale values, overcome these problems. In addition, PC is more sensitive than DCR, and it can provide scale values in fractional, just noticeable difference (JND) units that express a precise perceptional interpretation. Still, the comparison of images of nearly the same quality can be difficult. We introduce boosting techniques embedded in more general triplet comparisons (TC) that increase the sensitivity even more. Boosting amplifies the artefacts of distorted images, enlarges their visual representation by zooming, increases the visibility of the distortions by a flickering effect, or combines some of the above. Experimental results show the effectiveness of boosted TC for seven types of distortion. We crowdsourced over 1.7 million responses to triplet questions. A detailed analysis shows that boosting increases the discriminatory power and allows to reduce the number of subjective ratings without sacrificing the accuracy of the resulting relative image quality values. Our technique paves the way to fine-grained image quality datasets, allowing for more distortion levels, yet with high-quality subjective annotations. We also provide the details for Thurstonian scale reconstruction from TC and our annotated dataset, KonFiG-IQA, containing 10 source images, processed using 7 distortion types at 12 or even 30 levels, uniformly spaced over a span of 3 JND units.
EvolGAN: Evolutionary Generative Adversarial Networks
Sep 28, 2020

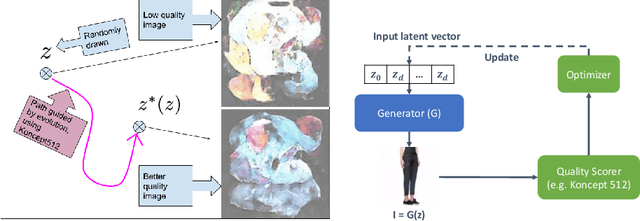
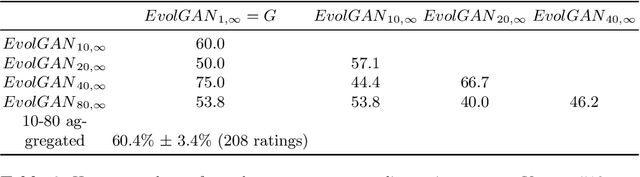
We propose to use a quality estimator and evolutionary methods to search the latent space of generative adversarial networks trained on small, difficult datasets, or both. The new method leads to the generation of significantly higher quality images while preserving the original generator's diversity. Human raters preferred an image from the new version with frequency 83.7pc for Cats, 74pc for FashionGen, 70.4pc for Horses, and 69.2pc for Artworks, and minor improvements for the already excellent GANs for faces. This approach applies to any quality scorer and GAN generator.
Tarsier: Evolving Noise Injection in Super-Resolution GANs
Sep 25, 2020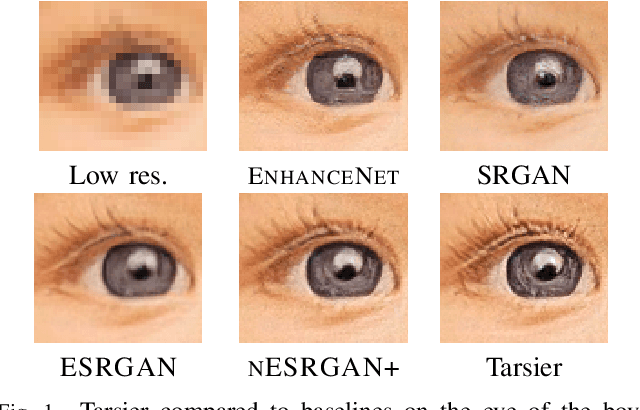

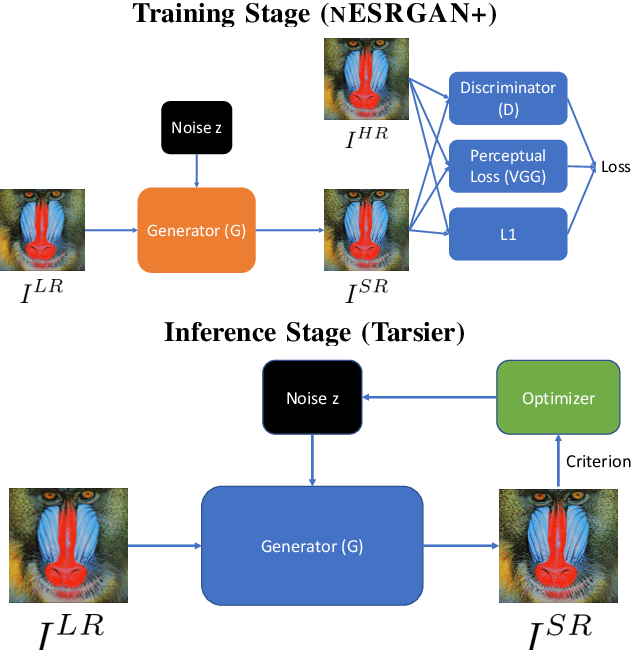
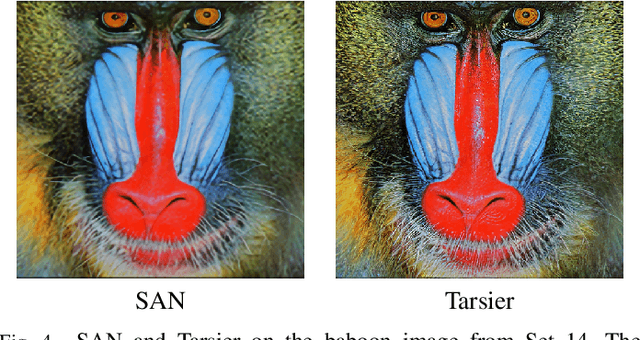
Super-resolution aims at increasing the resolution and level of detail within an image. The current state of the art in general single-image super-resolution is held by NESRGAN+, which injects a Gaussian noise after each residual layer at training time. In this paper, we harness evolutionary methods to improve NESRGAN+ by optimizing the noise injection at inference time. More precisely, we use Diagonal CMA to optimize the injected noise according to a novel criterion combining quality assessment and realism. Our results are validated by the PIRM perceptual score and a human study. Our method outperforms NESRGAN+ on several standard super-resolution datasets. More generally, our approach can be used to optimize any method based on noise injection.