 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Learning to Manipulate a Commitment Optimizer
Feb 26, 2023

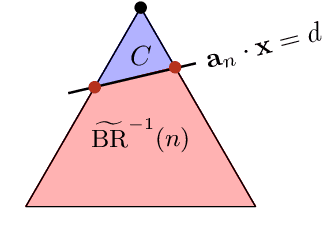


It is shown in recent studies that in a Stackelberg game the follower can manipulate the leader by deviating from their true best-response behavior. Such manipulations are computationally tractable and can be highly beneficial for the follower. Meanwhile, they may result in significant payoff losses for the leader, sometimes completely defeating their first-mover advantage. A warning to commitment optimizers, the risk these findings indicate appears to be alleviated to some extent by a strict information advantage the manipulations rely on. That is, the follower knows the full information about both players' payoffs whereas the leader only knows their own payoffs. In this paper, we study the manipulation problem with this information advantage relaxed. We consider the scenario where the follower is not given any information about the leader's payoffs to begin with but has to learn to manipulate by interacting with the leader. The follower can gather necessary information by querying the leader's optimal commitments against contrived best-response behaviors. Our results indicate that the information advantage is not entirely indispensable to the follower's manipulations: the follower can learn the optimal way to manipulate in polynomial time with polynomially many queries of the leader's optimal commitment.
Learning Spatial-Temporal Implicit Neural Representations for Event-Guided Video Super-Resolution
Mar 24, 2023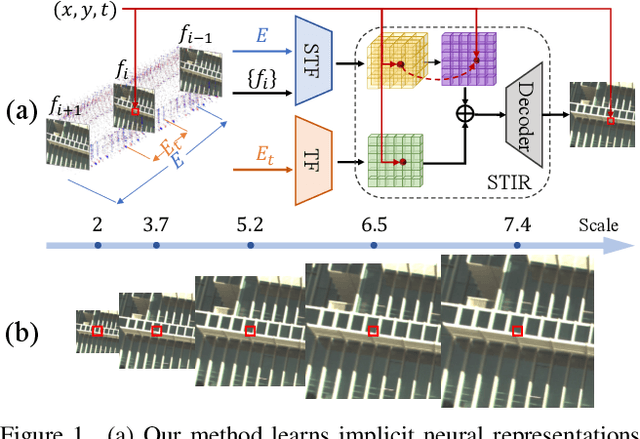
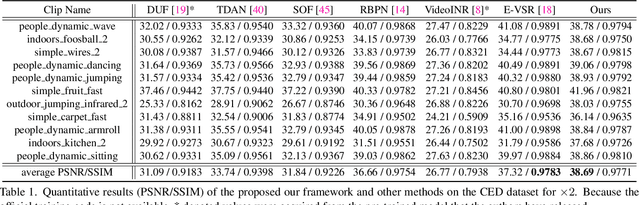
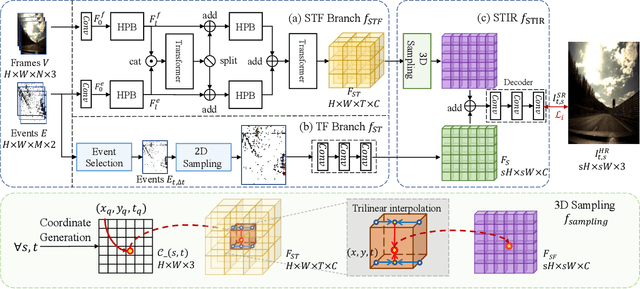
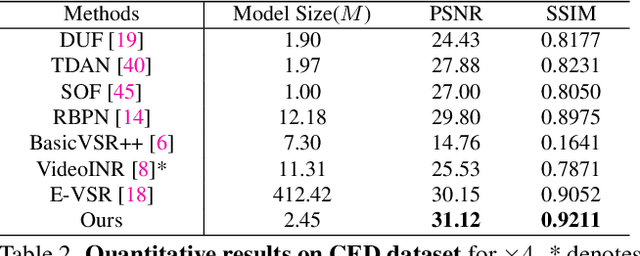
Event cameras sense the intensity changes asynchronously and produce event streams with high dynamic range and low latency. This has inspired research endeavors utilizing events to guide the challenging video superresolution (VSR) task. In this paper, we make the first attempt to address a novel problem of achieving VSR at random scales by taking advantages of the high temporal resolution property of events. This is hampered by the difficulties of representing the spatial-temporal information of events when guiding VSR. To this end, we propose a novel framework that incorporates the spatial-temporal interpolation of events to VSR in a unified framework. Our key idea is to learn implicit neural representations from queried spatial-temporal coordinates and features from both RGB frames and events. Our method contains three parts. Specifically, the Spatial-Temporal Fusion (STF) module first learns the 3D features from events and RGB frames. Then, the Temporal Filter (TF) module unlocks more explicit motion information from the events near the queried timestamp and generates the 2D features. Lastly, the SpatialTemporal Implicit Representation (STIR) module recovers the SR frame in arbitrary resolutions from the outputs of these two modules. In addition, we collect a real-world dataset with spatially aligned events and RGB frames. Extensive experiments show that our method significantly surpasses the prior-arts and achieves VSR with random scales, e.g., 6.5. Code and dataset are available at https: //vlis2022.github.io/cvpr23/egvsr.
LUKE-Graph: A Transformer-based Approach with Gated Relational Graph Attention for Cloze-style Reading Comprehension
Mar 12, 2023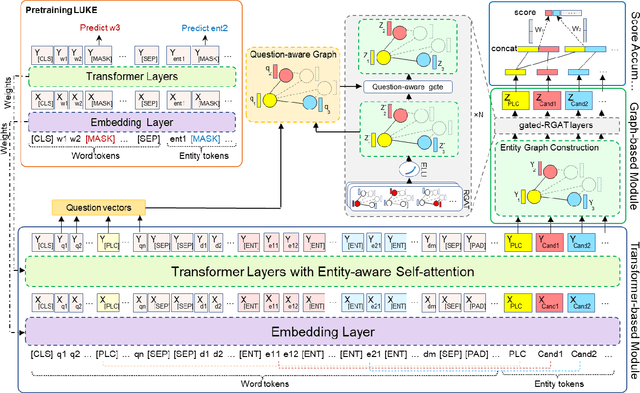
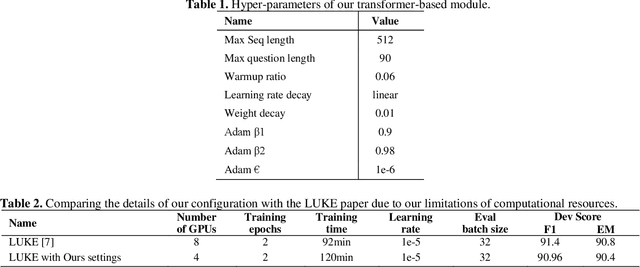
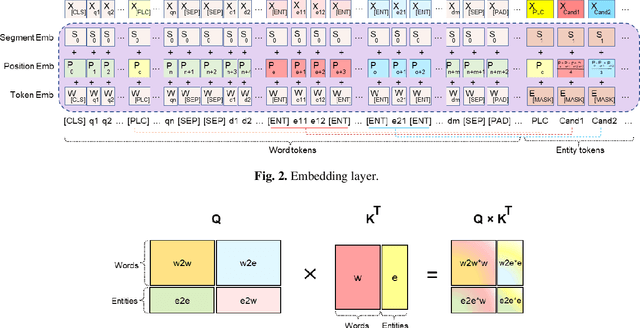
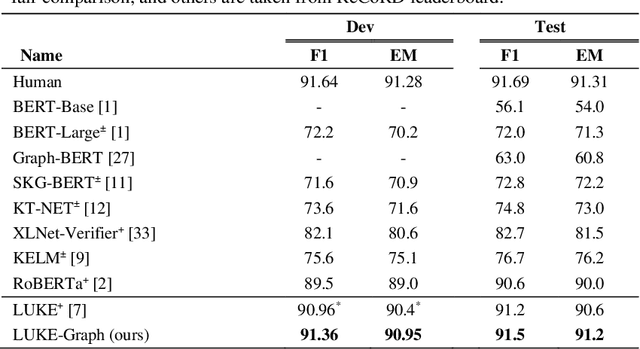
Incorporating prior knowledge can improve existing pre-training models in cloze-style machine reading and has become a new trend in recent studies. Notably, most of the existing models have integrated external knowledge graphs (KG) and transformer-based models, such as BERT into a unified data structure. However, selecting the most relevant ambiguous entities in KG and extracting the best subgraph remains a challenge. In this paper, we propose the LUKE-Graph, a model that builds a heterogeneous graph based on the intuitive relationships between entities in a document without using any external KG. We then use a Relational Graph Attention (RGAT) network to fuse the graph's reasoning information and the contextual representation encoded by the pre-trained LUKE model. In this way, we can take advantage of LUKE, to derive an entity-aware representation; and a graph model - to exploit relation-aware representation. Moreover, we propose Gated-RGAT by augmenting RGAT with a gating mechanism that regulates the question information for the graph convolution operation. This is very similar to human reasoning processing because they always choose the best entity candidate based on the question information. Experimental results demonstrate that the LUKE-Graph achieves state-of-the-art performance on the ReCoRD dataset with commonsense reasoning.
Multi-Scale Control Signal-Aware Transformer for Motion Synthesis without Phase
Mar 03, 2023

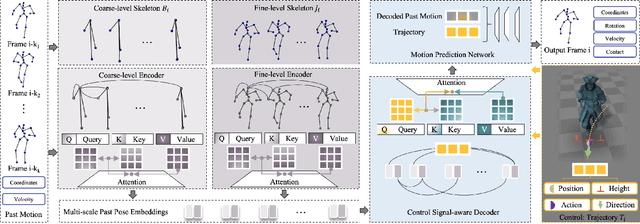
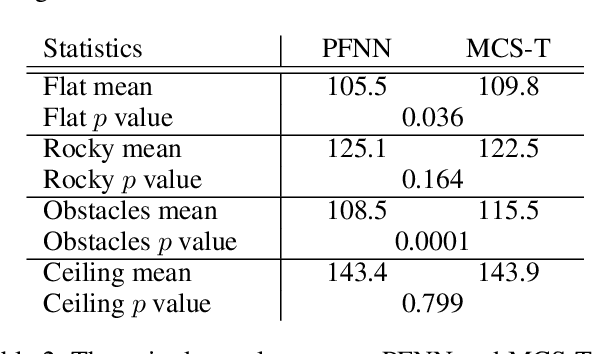
Synthesizing controllable motion for a character using deep learning has been a promising approach due to its potential to learn a compact model without laborious feature engineering. To produce dynamic motion from weak control signals such as desired paths, existing methods often require auxiliary information such as phases for alleviating motion ambiguity, which limits their generalisation capability. As past poses often contain useful auxiliary hints, in this paper, we propose a task-agnostic deep learning method, namely Multi-scale Control Signal-aware Transformer (MCS-T), with an attention based encoder-decoder architecture to discover the auxiliary information implicitly for synthesizing controllable motion without explicitly requiring auxiliary information such as phase. Specifically, an encoder is devised to adaptively formulate the motion patterns of a character's past poses with multi-scale skeletons, and a decoder driven by control signals to further synthesize and predict the character's state by paying context-specialised attention to the encoded past motion patterns. As a result, it helps alleviate the issues of low responsiveness and slow transition which often happen in conventional methods not using auxiliary information. Both qualitative and quantitative experimental results on an existing biped locomotion dataset, which involves diverse types of motion transitions, demonstrate the effectiveness of our method. In particular, MCS-T is able to successfully generate motions comparable to those generated by the methods using auxiliary information.
StyleGAN Salon: Multi-View Latent Optimization for Pose-Invariant Hairstyle Transfer
Apr 05, 2023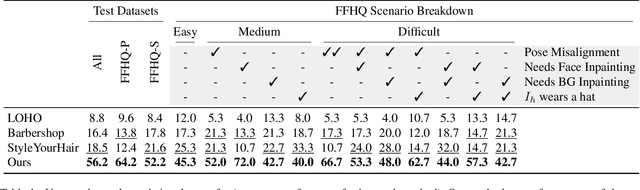
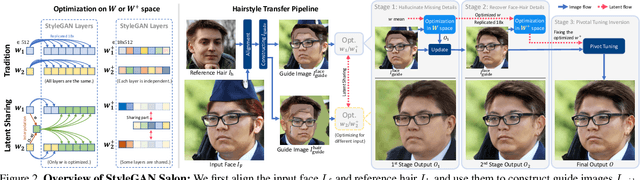
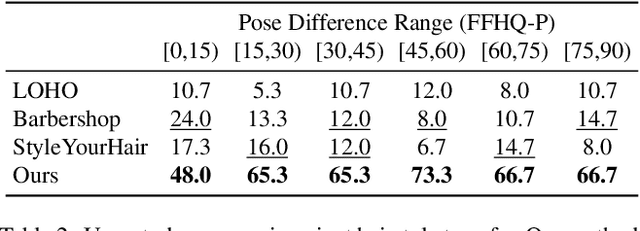

Our paper seeks to transfer the hairstyle of a reference image to an input photo for virtual hair try-on. We target a variety of challenges scenarios, such as transforming a long hairstyle with bangs to a pixie cut, which requires removing the existing hair and inferring how the forehead would look, or transferring partially visible hair from a hat-wearing person in a different pose. Past solutions leverage StyleGAN for hallucinating any missing parts and producing a seamless face-hair composite through so-called GAN inversion or projection. However, there remains a challenge in controlling the hallucinations to accurately transfer hairstyle and preserve the face shape and identity of the input. To overcome this, we propose a multi-view optimization framework that uses "two different views" of reference composites to semantically guide occluded or ambiguous regions. Our optimization shares information between two poses, which allows us to produce high fidelity and realistic results from incomplete references. Our framework produces high-quality results and outperforms prior work in a user study that consists of significantly more challenging hair transfer scenarios than previously studied. Project page: https://stylegan-salon.github.io/.
X-TIME: An in-memory engine for accelerating machine learning on tabular data with CAMs
Apr 05, 2023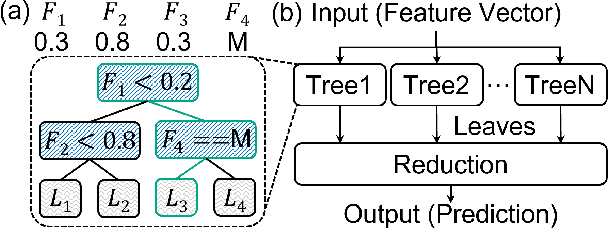
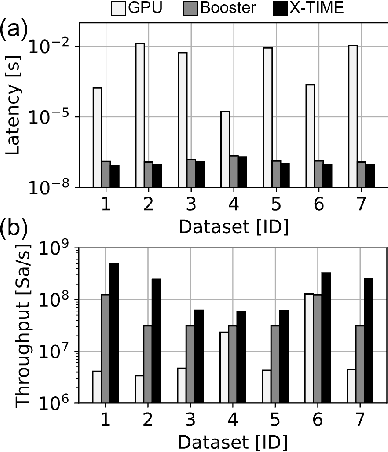
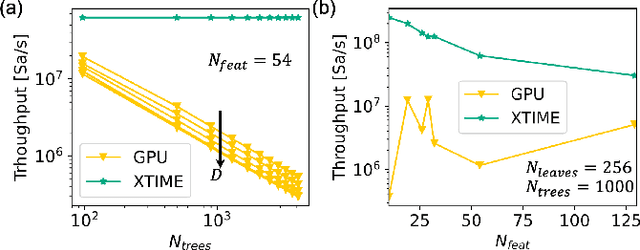
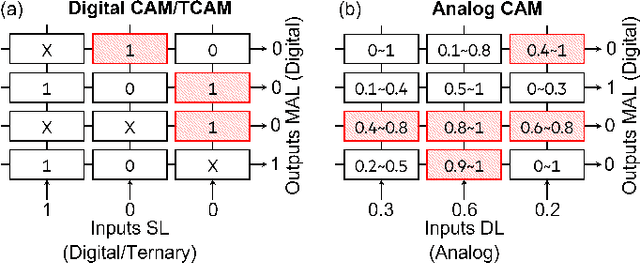
Structured, or tabular, data is the most common format in data science. While deep learning models have proven formidable in learning from unstructured data such as images or speech, they are less accurate than simpler approaches when learning from tabular data. In contrast, modern tree-based Machine Learning (ML) models shine in extracting relevant information from structured data. An essential requirement in data science is to reduce model inference latency in cases where, for example, models are used in a closed loop with simulation to accelerate scientific discovery. However, the hardware acceleration community has mostly focused on deep neural networks and largely ignored other forms of machine learning. Previous work has described the use of an analog content addressable memory (CAM) component for efficiently mapping random forests. In this work, we focus on an overall analog-digital architecture implementing a novel increased precision analog CAM and a programmable network on chip allowing the inference of state-of-the-art tree-based ML models, such as XGBoost and CatBoost. Results evaluated in a single chip at 16nm technology show 119x lower latency at 9740x higher throughput compared with a state-of-the-art GPU, with a 19W peak power consumption.
Domain Generalization with Adversarial Intensity Attack for Medical Image Segmentation
Apr 05, 2023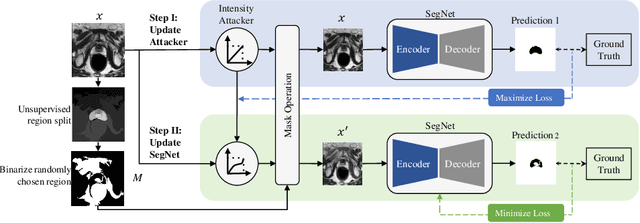
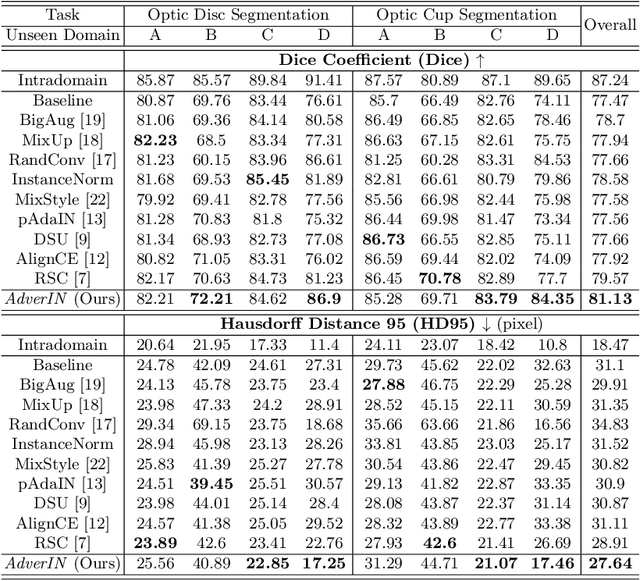
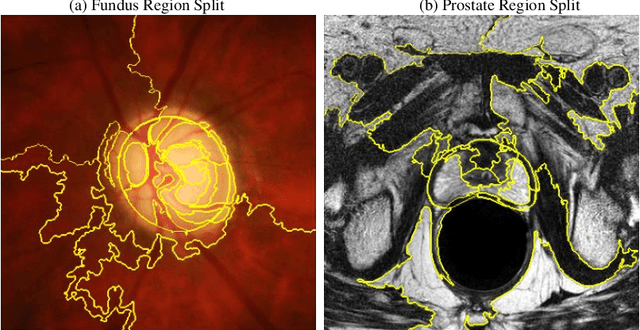
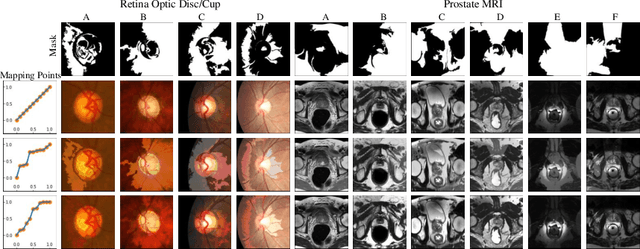
Most statistical learning algorithms rely on an over-simplified assumption, that is, the train and test data are independent and identically distributed. In real-world scenarios, however, it is common for models to encounter data from new and different domains to which they were not exposed to during training. This is often the case in medical imaging applications due to differences in acquisition devices, imaging protocols, and patient characteristics. To address this problem, domain generalization (DG) is a promising direction as it enables models to handle data from previously unseen domains by learning domain-invariant features robust to variations across different domains. To this end, we introduce a novel DG method called Adversarial Intensity Attack (AdverIN), which leverages adversarial training to generate training data with an infinite number of styles and increase data diversity while preserving essential content information. We conduct extensive evaluation experiments on various multi-domain segmentation datasets, including 2D retinal fundus optic disc/cup and 3D prostate MRI. Our results demonstrate that AdverIN significantly improves the generalization ability of the segmentation models, achieving significant improvement on these challenging datasets. Code is available upon publication.
What's in a Name? Beyond Class Indices for Image Recognition
Apr 05, 2023

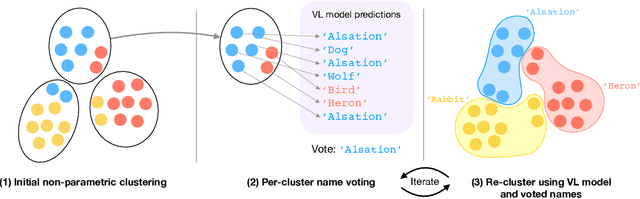

Existing machine learning models demonstrate excellent performance in image object recognition after training on a large-scale dataset under full supervision. However, these models only learn to map an image to a predefined class index, without revealing the actual semantic meaning of the object in the image. In contrast, vision-language models like CLIP are able to assign semantic class names to unseen objects in a `zero-shot' manner, although they still rely on a predefined set of candidate names at test time. In this paper, we reconsider the recognition problem and task a vision-language model to assign class names to images given only a large and essentially unconstrained vocabulary of categories as prior information. We use non-parametric methods to establish relationships between images which allow the model to automatically narrow down the set of possible candidate names. Specifically, we propose iteratively clustering the data and voting on class names within them, showing that this enables a roughly 50\% improvement over the baseline on ImageNet. Furthermore, we tackle this problem both in unsupervised and partially supervised settings, as well as with a coarse-grained and fine-grained search space as the unconstrained dictionary.
Face Transformer: Towards High Fidelity and Accurate Face Swapping
Apr 05, 2023
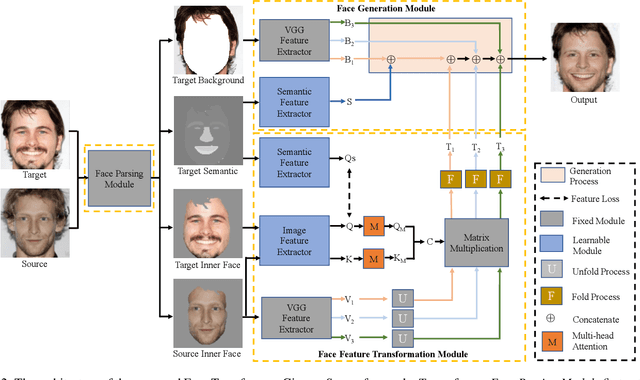
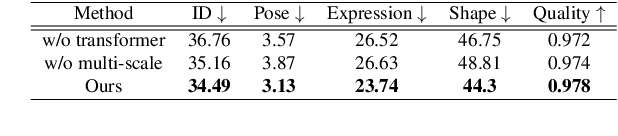
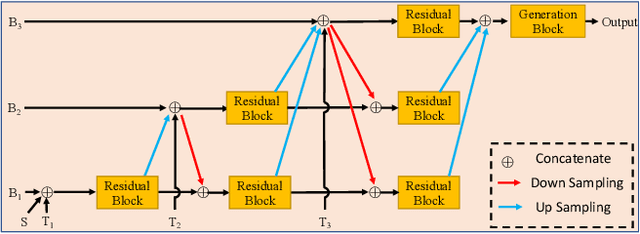
Face swapping aims to generate swapped images that fuse the identity of source faces and the attributes of target faces. Most existing works address this challenging task through 3D modelling or generation using generative adversarial networks (GANs), but 3D modelling suffers from limited reconstruction accuracy and GANs often struggle in preserving subtle yet important identity details of source faces (e.g., skin colors, face features) and structural attributes of target faces (e.g., face shapes, facial expressions). This paper presents Face Transformer, a novel face swapping network that can accurately preserve source identities and target attributes simultaneously in the swapped face images. We introduce a transformer network for the face swapping task, which learns high-quality semantic-aware correspondence between source and target faces and maps identity features of source faces to the corresponding region in target faces. The high-quality semantic-aware correspondence enables smooth and accurate transfer of source identity information with minimal modification of target shapes and expressions. In addition, our Face Transformer incorporates a multi-scale transformation mechanism for preserving the rich fine facial details. Extensive experiments show that our Face Transformer achieves superior face swapping performance qualitatively and quantitatively.
A new filter for dimensionality reduction and classification of hyperspectral images using GLCM features and mutual information
Nov 01, 2022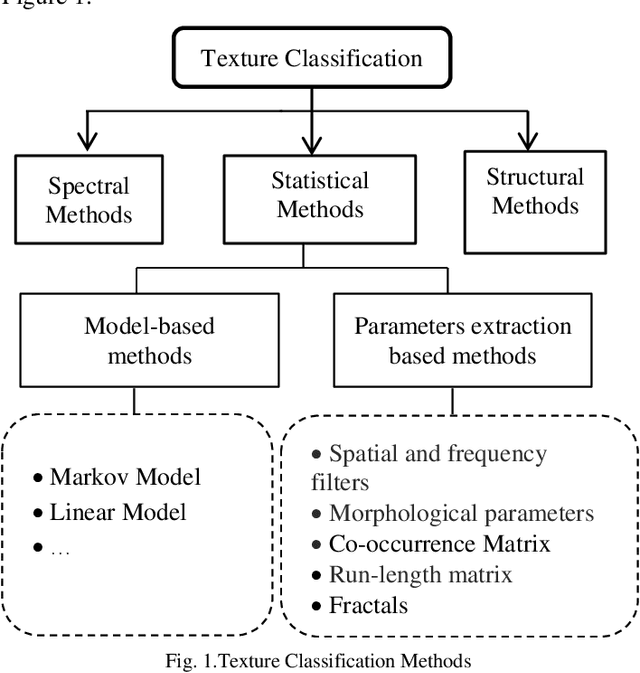
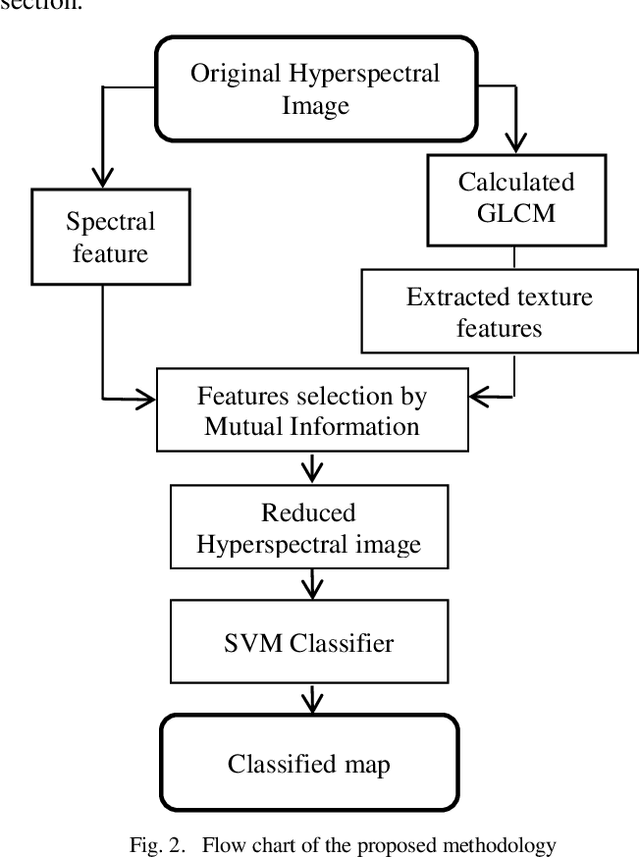
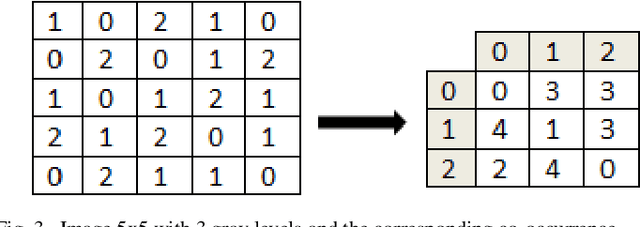
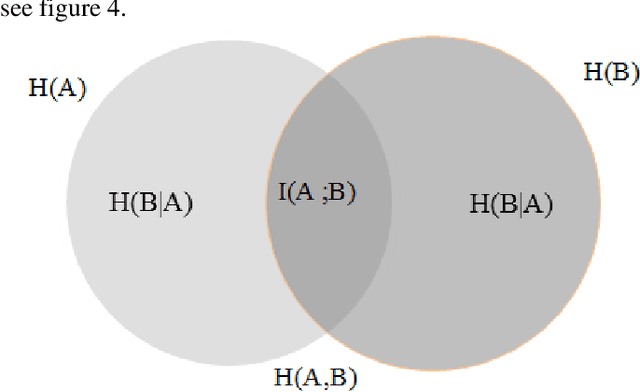
Dimensionality reduction is an important preprocessing step of the hyperspectral images classification (HSI), it is inevitable task. Some methods use feature selection or extraction algorithms based on spectral and spatial information. In this paper, we introduce a new methodology for dimensionality reduction and classification of HSI taking into account both spectral and spatial information based on mutual information. We characterise the spatial information by the texture features extracted from the grey level cooccurrence matrix (GLCM); we use Homogeneity, Contrast, Correlation and Energy. For classification, we use support vector machine (SVM). The experiments are performed on three well-known hyperspectral benchmark datasets. The proposed algorithm is compared with the state of the art methods. The obtained results of this fusion show that our method outperforms the other approaches by increasing the classification accuracy in a good timing. This method may be improved for more performance Keywords: hyperspectral images; classification; spectral and spatial features; grey level cooccurrence matrix; GLCM; mutual information; support vector machine; SVM.