 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
PK-Chat: Pointer Network Guided Knowledge Driven Generative Dialogue Model
Apr 02, 2023
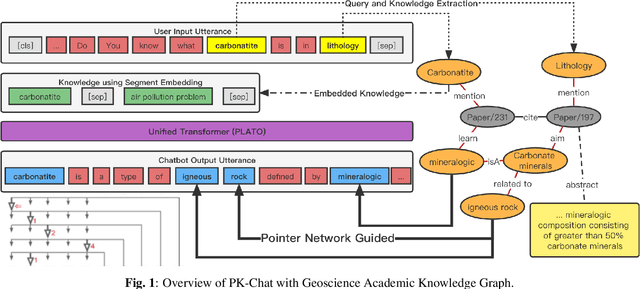
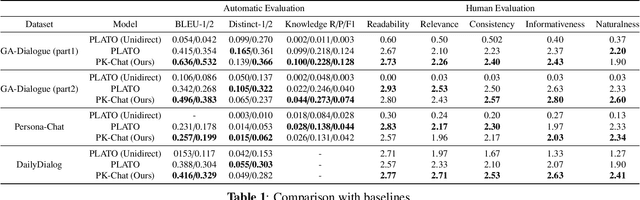
In the research of end-to-end dialogue systems, using real-world knowledge to generate natural, fluent, and human-like utterances with correct answers is crucial. However, domain-specific conversational dialogue systems may be incoherent and introduce erroneous external information to answer questions due to the out-of-vocabulary issue or the wrong knowledge from the parameters of the neural network. In this work, we propose PK-Chat, a Pointer network guided Knowledge-driven generative dialogue model, incorporating a unified pretrained language model and a pointer network over knowledge graphs. The words generated by PK-Chat in the dialogue are derived from the prediction of word lists and the direct prediction of the external knowledge graph knowledge. Moreover, based on the PK-Chat, a dialogue system is built for academic scenarios in the case of geosciences. Finally, an academic dialogue benchmark is constructed to evaluate the quality of dialogue systems in academic scenarios and the source code is available online.
Safe and Efficient Navigation in Extreme Environments using Semantic Belief Graphs
Apr 02, 2023
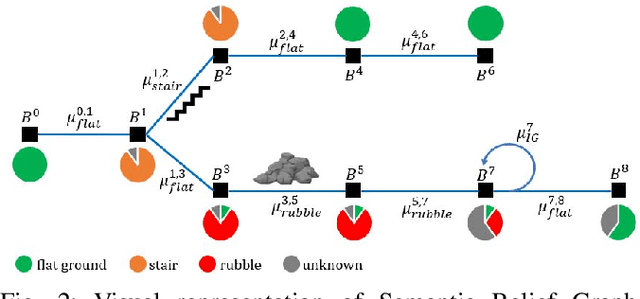
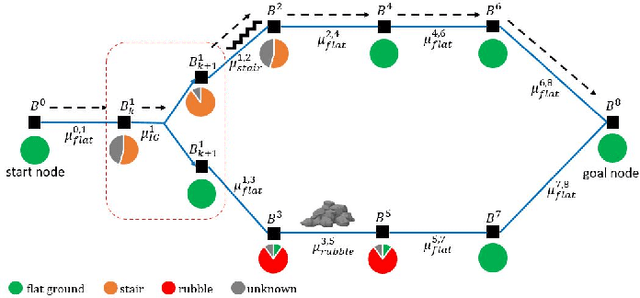
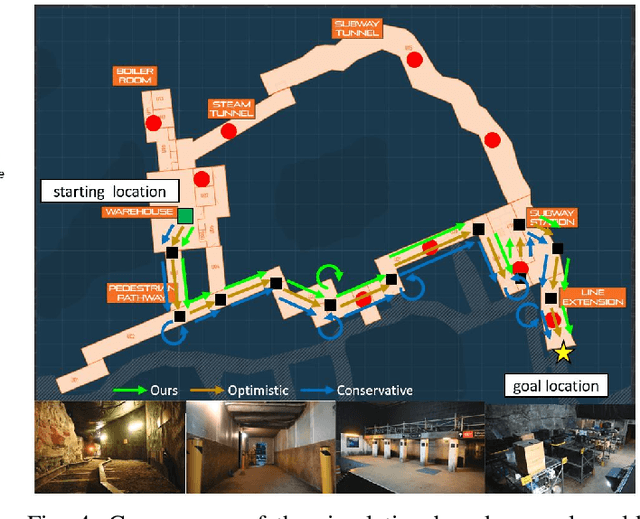
To achieve autonomy in unknown and unstructured environments, we propose a method for semantic-based planning under perceptual uncertainty. This capability is crucial for safe and efficient robot navigation in environment with mobility-stressing elements that require terrain-specific locomotion policies. We propose the Semantic Belief Graph (SBG), a geometric- and semantic-based representation of a robot's probabilistic roadmap in the environment. The SBG nodes comprise of the robot geometric state and the semantic-knowledge of the terrains in the environment. The SBG edges represent local semantic-based controllers that drive the robot between the nodes or invoke an information gathering action to reduce semantic belief uncertainty. We formulate a semantic-based planning problem on SBG that produces a policy for the robot to safely navigate to the target location with minimal traversal time. We analyze our method in simulation and present real-world results with a legged robotic platform navigating multi-level outdoor environments.
Investigating Catastrophic Overfitting in Fast Adversarial Training: A Self-fitting Perspective
Feb 23, 2023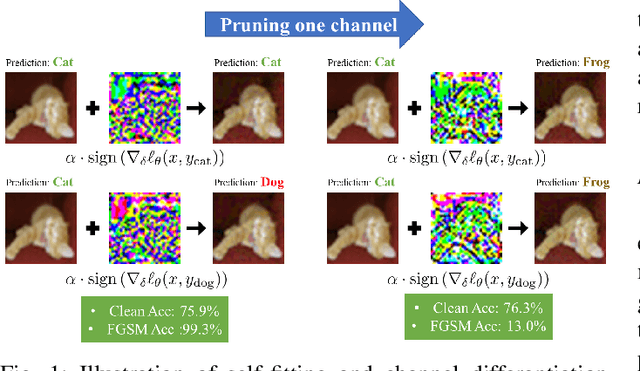
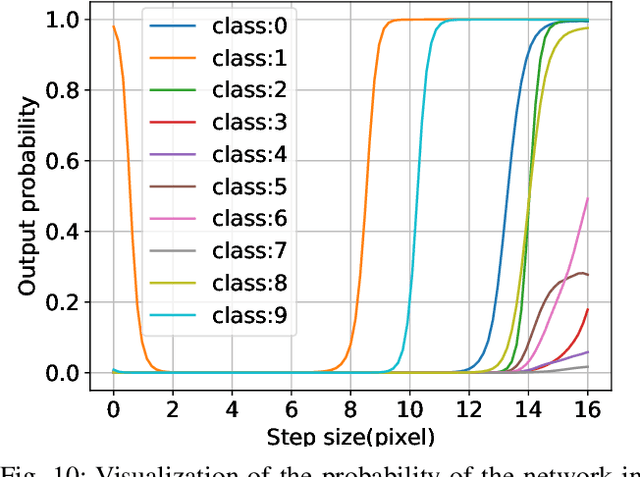
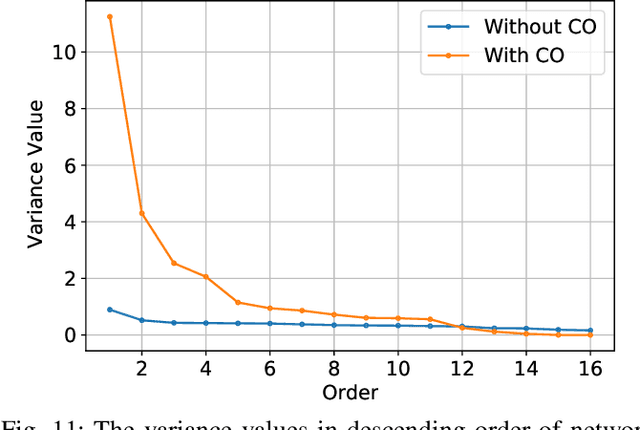
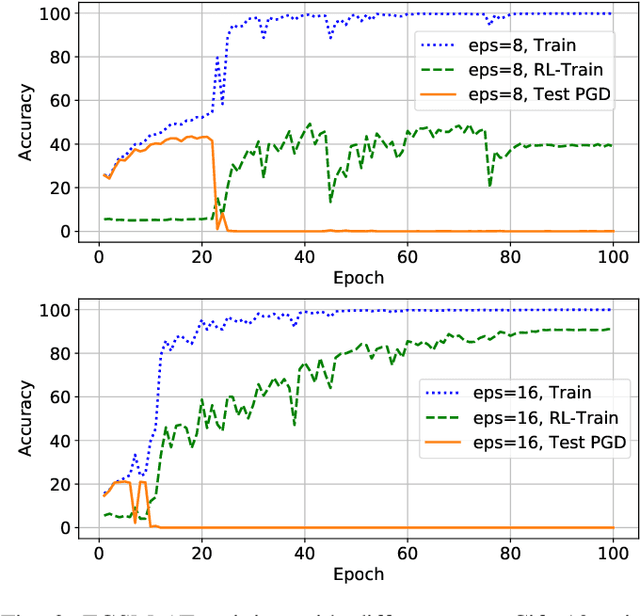
Although fast adversarial training provides an efficient approach for building robust networks, it may suffer from a serious problem known as catastrophic overfitting (CO), where the multi-step robust accuracy suddenly collapses to zero. In this paper, we for the first time decouple the FGSM examples into data-information and self-information, which reveals an interesting phenomenon called "self-fitting". Self-fitting, i.e., DNNs learn the self-information embedded in single-step perturbations, naturally leads to the occurrence of CO. When self-fitting occurs, the network experiences an obvious "channel differentiation" phenomenon that some convolution channels accounting for recognizing self-information become dominant, while others for data-information are suppressed. In this way, the network learns to only recognize images with sufficient self-information and loses generalization ability to other types of data. Based on self-fitting, we provide new insight into the existing methods to mitigate CO and extend CO to multi-step adversarial training. Our findings reveal a self-learning mechanism in adversarial training and open up new perspectives for suppressing different kinds of information to mitigate CO.
Class-Guided Image-to-Image Diffusion: Cell Painting from Brightfield Images with Class Labels
Mar 29, 2023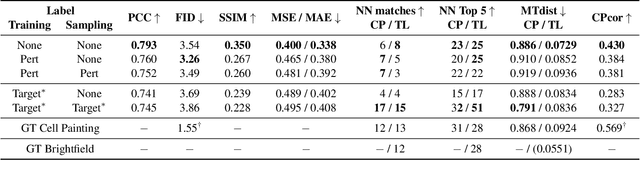
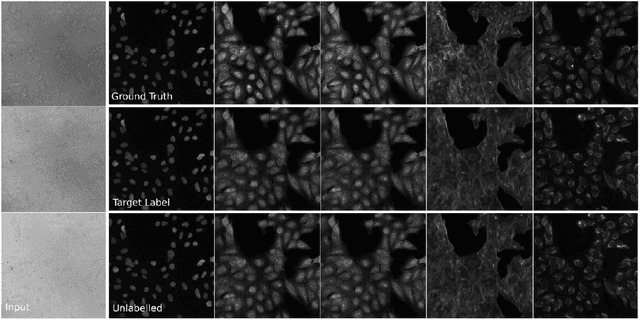
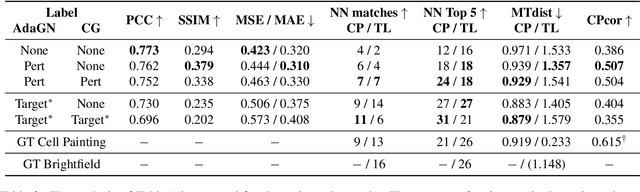
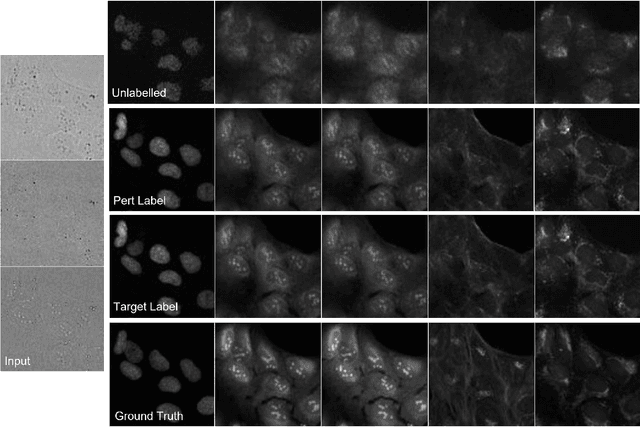
Image-to-image reconstruction problems with free or inexpensive metadata in the form of class labels appear often in biological and medical image domains. Existing text-guided or style-transfer image-to-image approaches do not translate to datasets where additional information is provided as discrete classes. We introduce and implement a model which combines image-to-image and class-guided denoising diffusion probabilistic models. We train our model on a real-world dataset of microscopy images used for drug discovery, with and without incorporating metadata labels. By exploring the properties of image-to-image diffusion with relevant labels, we show that class-guided image-to-image diffusion can improve the meaningful content of the reconstructed images and outperform the unguided model in useful downstream tasks.
Attack is Good Augmentation: Towards Skeleton-Contrastive Representation Learning
Apr 08, 2023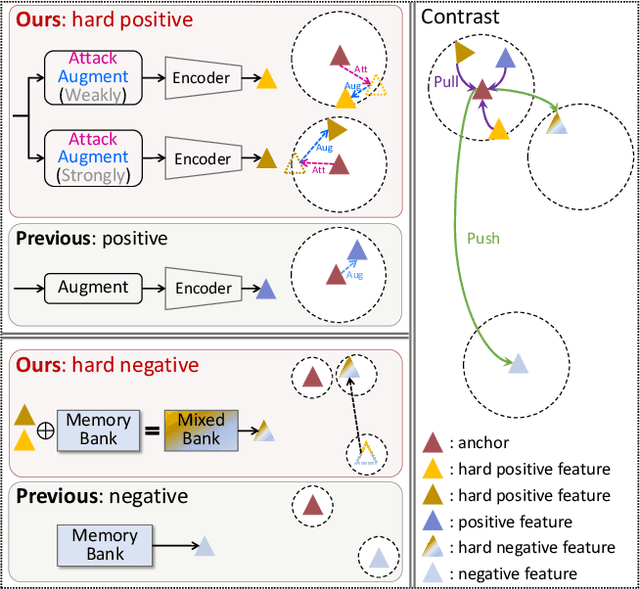
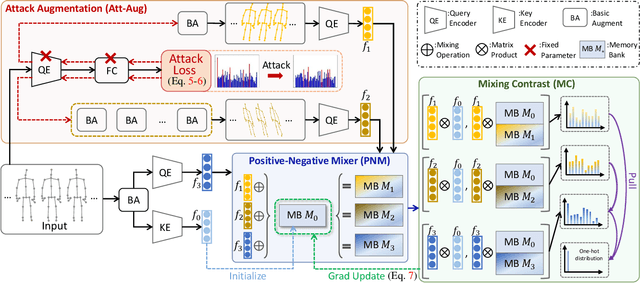
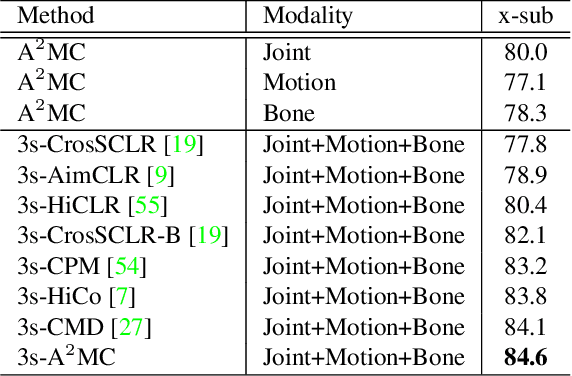
Contrastive learning, relying on effective positive and negative sample pairs, is beneficial to learn informative skeleton representations in unsupervised skeleton-based action recognition. To achieve these positive and negative pairs, existing weak/strong data augmentation methods have to randomly change the appearance of skeletons for indirectly pursuing semantic perturbations. However, such approaches have two limitations: 1) solely perturbing appearance cannot well capture the intrinsic semantic information of skeletons, and 2) randomly perturbation may change the original positive/negative pairs to soft positive/negative ones. To address the above dilemma, we start the first attempt to explore an attack-based augmentation scheme that additionally brings in direct semantic perturbation, for constructing hard positive pairs and further assisting in constructing hard negative pairs. In particular, we propose a novel Attack-Augmentation Mixing-Contrastive learning (A$^2$MC) to contrast hard positive features and hard negative features for learning more robust skeleton representations. In A$^2$MC, Attack-Augmentation (Att-Aug) is designed to collaboratively perform targeted and untargeted perturbations of skeletons via attack and augmentation respectively, for generating high-quality hard positive features. Meanwhile, Positive-Negative Mixer (PNM) is presented to mix hard positive features and negative features for generating hard negative features, which are adopted for updating the mixed memory banks. Extensive experiments on three public datasets demonstrate that A$^2$MC is competitive with the state-of-the-art methods.
NeBLa: Neural Beer-Lambert for 3D Reconstruction of Oral Structures from Panoramic Radiographs
Apr 08, 2023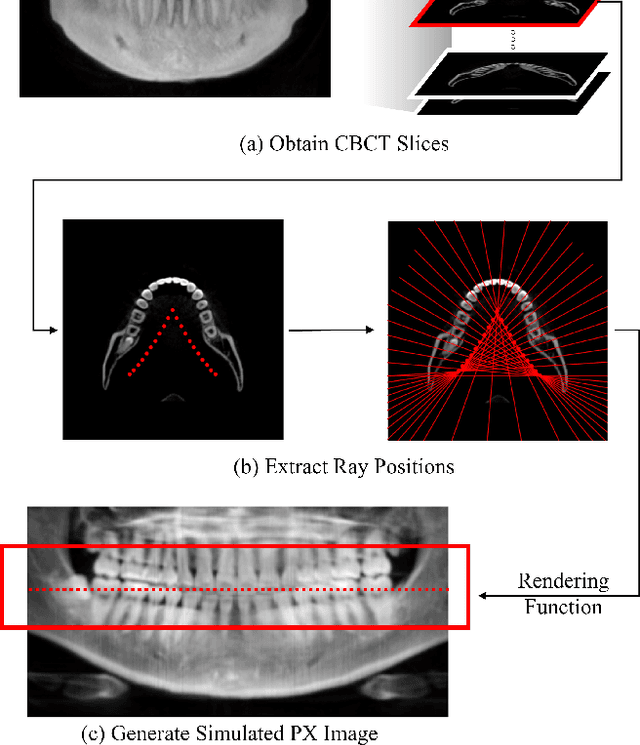
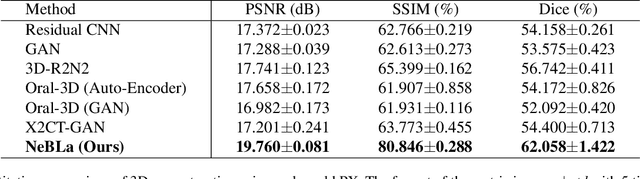
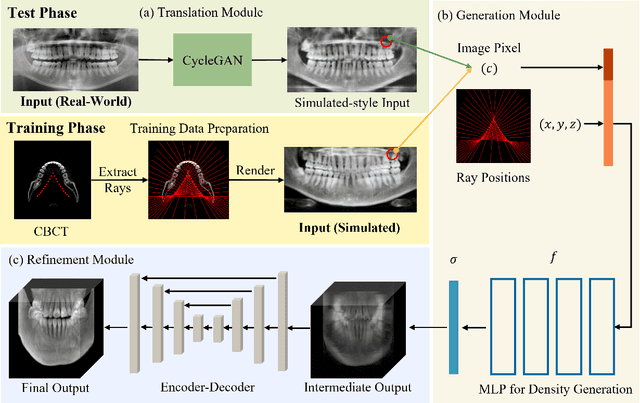
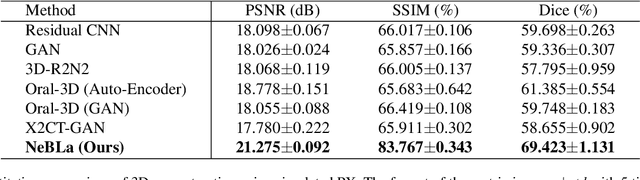
Panoramic radiography (panoramic X-ray, PX) is a widely used imaging modality for dental examination. However, its applicability is limited as compared to 3D Cone-beam computed tomography (CBCT), because PX only provides 2D flattened images of the oral structure. In this paper, we propose a new framework which estimates 3D oral structure from real-world PX images. Since there are not many matching PX and CBCT data, we used simulated PX from CBCT for training, however, we used real-world panoramic radiographs at the inference time. We propose a new ray-sampling method to make simulated panoramic radiographs inspired by the principle of panoramic radiography along with the rendering function derived from the Beer-Lambert law. Our model consists of three parts: translation module, generation module, and refinement module. The translation module changes the real-world panoramic radiograph to the simulated training image style. The generation module makes the 3D structure from the input image without any prior information such as a dental arch. Our ray-based generation approach makes it possible to reverse the process of generating PX from oral structure in order to reconstruct CBCT data. Lastly, the refinement module enhances the quality of the 3D output. Results show that our approach works better for simulated and real-world images compared to other state-of-the-art methods.
PVD-AL: Progressive Volume Distillation with Active Learning for Efficient Conversion Between Different NeRF Architectures
Apr 08, 2023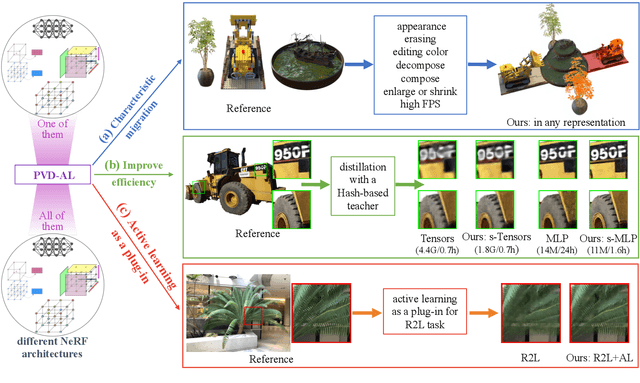
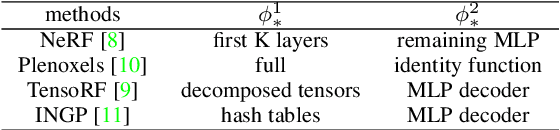
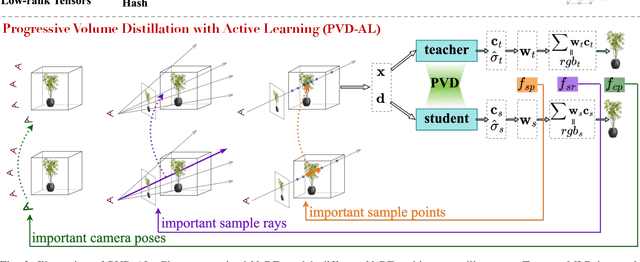
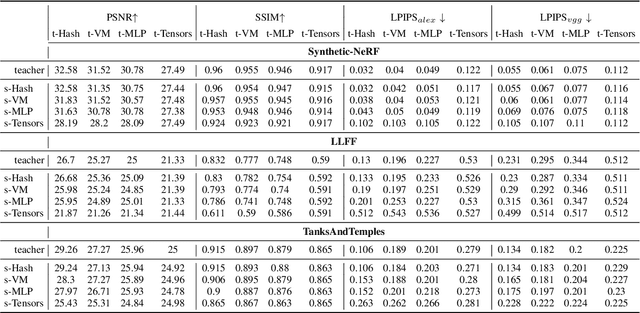
Neural Radiance Fields (NeRF) have been widely adopted as practical and versatile representations for 3D scenes, facilitating various downstream tasks. However, different architectures, including plain Multi-Layer Perceptron (MLP), Tensors, low-rank Tensors, Hashtables, and their compositions, have their trade-offs. For instance, Hashtables-based representations allow for faster rendering but lack clear geometric meaning, making spatial-relation-aware editing challenging. To address this limitation and maximize the potential of each architecture, we propose Progressive Volume Distillation with Active Learning (PVD-AL), a systematic distillation method that enables any-to-any conversions between different architectures. PVD-AL decomposes each structure into two parts and progressively performs distillation from shallower to deeper volume representation, leveraging effective information retrieved from the rendering process. Additionally, a Three-Levels of active learning technique provides continuous feedback during the distillation process, resulting in high-performance results. Empirical evidence is presented to validate our method on multiple benchmark datasets. For example, PVD-AL can distill an MLP-based model from a Hashtables-based model at a 10~20X faster speed and 0.8dB~2dB higher PSNR than training the NeRF model from scratch. Moreover, PVD-AL permits the fusion of diverse features among distinct structures, enabling models with multiple editing properties and providing a more efficient model to meet real-time requirements. Project website:http://sk-fun.fun/PVD-AL.
Depth-Aware Image Compositing Model for Parallax Camera Motion Blur
Mar 30, 2023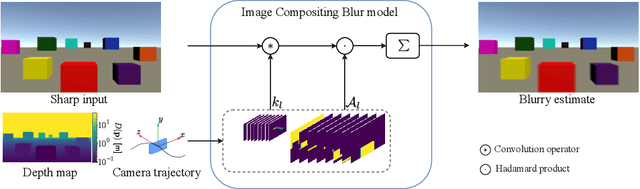
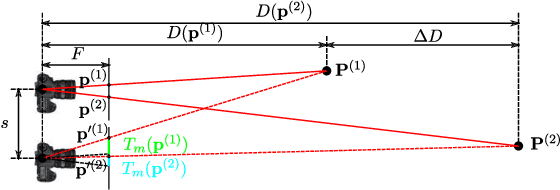
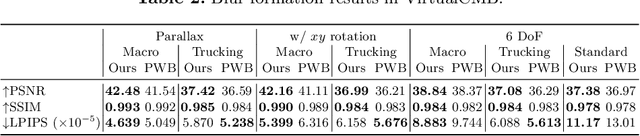
Camera motion introduces spatially varying blur due to the depth changes in the 3D world. This work investigates scene configurations where such blur is produced under parallax camera motion. We present a simple, yet accurate, Image Compositing Blur (ICB) model for depth-dependent spatially varying blur. The (forward) model produces realistic motion blur from a single image, depth map, and camera trajectory. Furthermore, we utilize the ICB model, combined with a coordinate-based MLP, to learn a sharp neural representation from the blurred input. Experimental results are reported for synthetic and real examples. The results verify that the ICB forward model is computationally efficient and produces realistic blur, despite the lack of occlusion information. Additionally, our method for restoring a sharp representation proves to be a competitive approach for the deblurring task.
3D-aware Image Generation using 2D Diffusion Models
Mar 31, 2023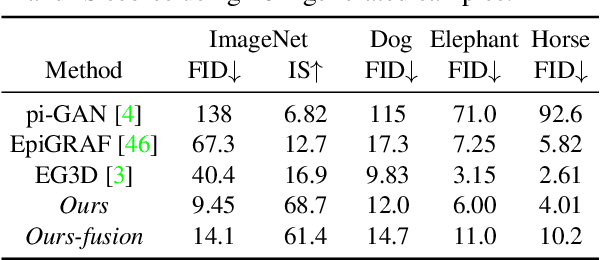
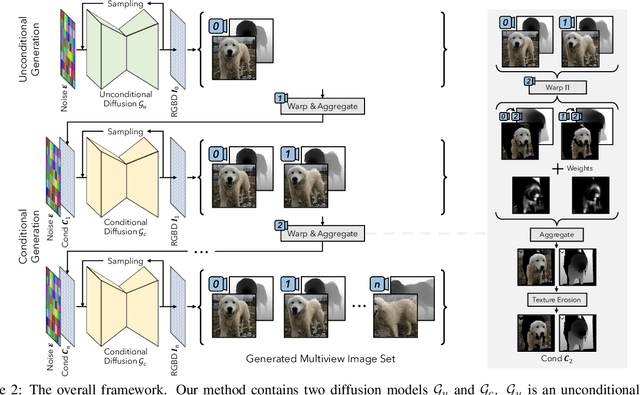
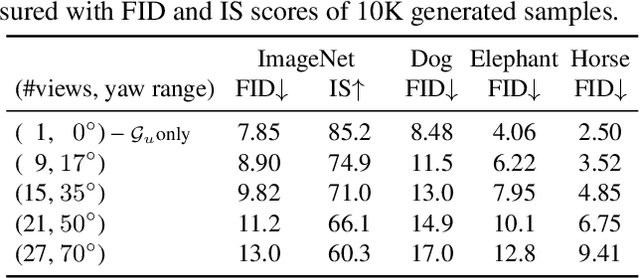
In this paper, we introduce a novel 3D-aware image generation method that leverages 2D diffusion models. We formulate the 3D-aware image generation task as multiview 2D image set generation, and further to a sequential unconditional-conditional multiview image generation process. This allows us to utilize 2D diffusion models to boost the generative modeling power of the method. Additionally, we incorporate depth information from monocular depth estimators to construct the training data for the conditional diffusion model using only still images. We train our method on a large-scale dataset, i.e., ImageNet, which is not addressed by previous methods. It produces high-quality images that significantly outperform prior methods. Furthermore, our approach showcases its capability to generate instances with large view angles, even though the training images are diverse and unaligned, gathered from "in-the-wild" real-world environments.
Exploring the Limits of Deep Image Clustering using Pretrained Models
Mar 31, 2023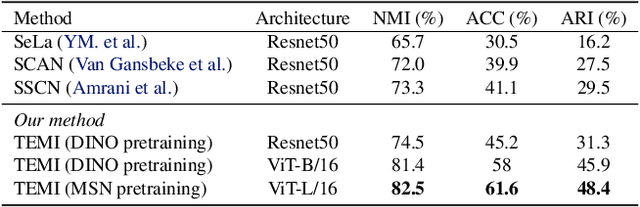
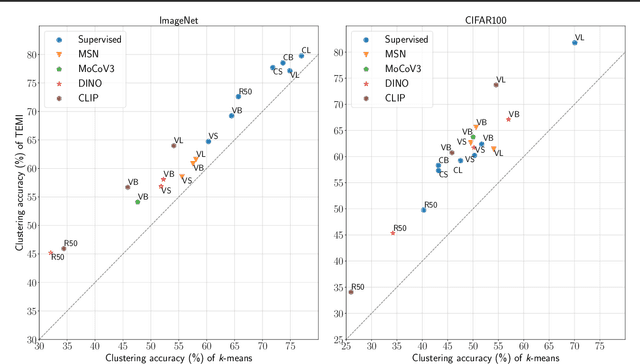
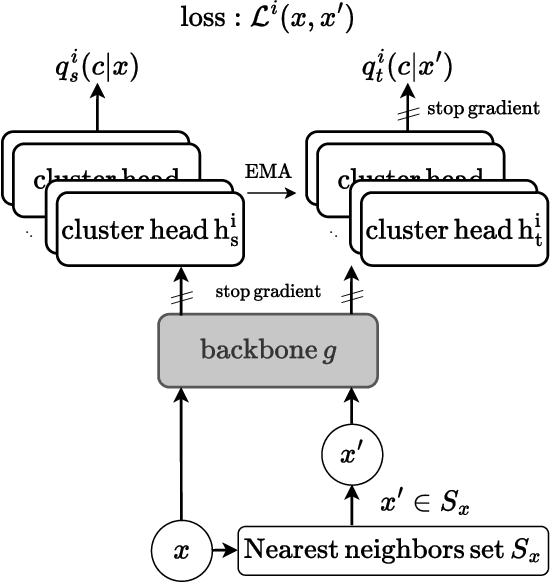
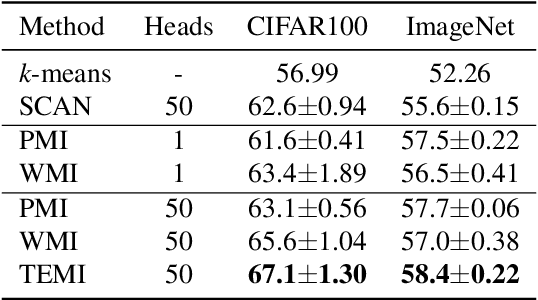
We present a general methodology that learns to classify images without labels by leveraging pretrained feature extractors. Our approach involves self-distillation training of clustering heads, based on the fact that nearest neighbors in the pretrained feature space are likely to share the same label. We propose a novel objective to learn associations between images by introducing a variant of pointwise mutual information together with instance weighting. We demonstrate that the proposed objective is able to attenuate the effect of false positive pairs while efficiently exploiting the structure in the pretrained feature space. As a result, we improve the clustering accuracy over $k$-means on $17$ different pretrained models by $6.1$\% and $12.2$\% on ImageNet and CIFAR100, respectively. Finally, using self-supervised pretrained vision transformers we push the clustering accuracy on ImageNet to $61.6$\%. The code will be open-sourced.