 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
POEM: Reconstructing Hand in a Point Embedded Multi-view Stereo
Apr 08, 2023
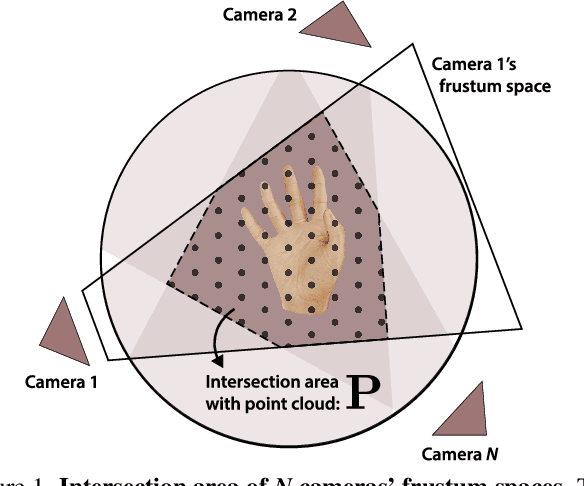
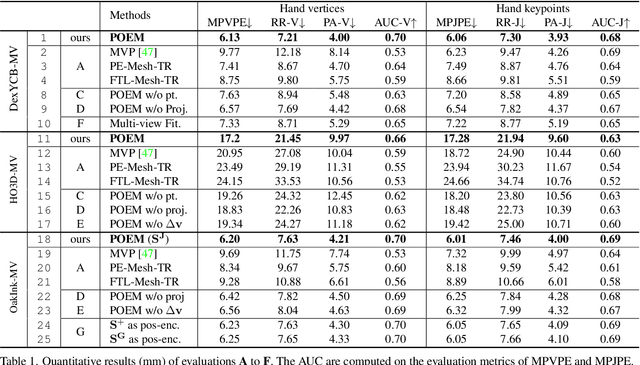
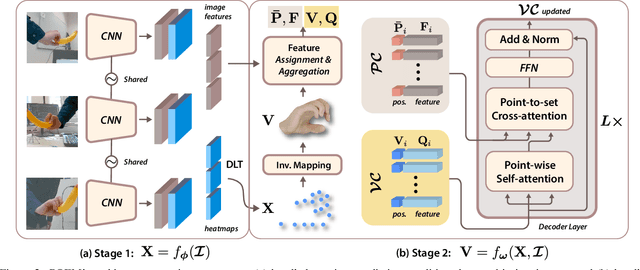
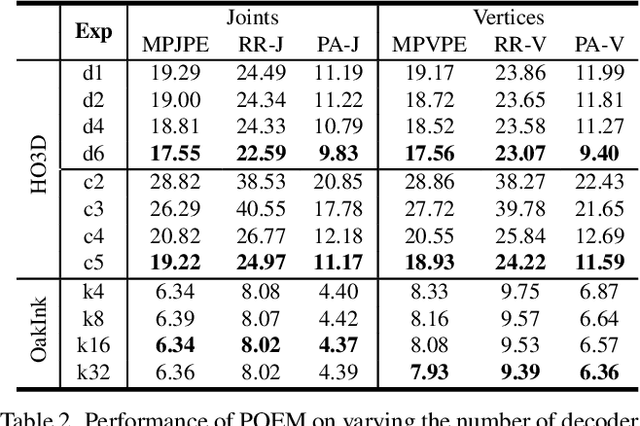
Enable neural networks to capture 3D geometrical-aware features is essential in multi-view based vision tasks. Previous methods usually encode the 3D information of multi-view stereo into the 2D features. In contrast, we present a novel method, named POEM, that directly operates on the 3D POints Embedded in the Multi-view stereo for reconstructing hand mesh in it. Point is a natural form of 3D information and an ideal medium for fusing features across views, as it has different projections on different views. Our method is thus in light of a simple yet effective idea, that a complex 3D hand mesh can be represented by a set of 3D points that 1) are embedded in the multi-view stereo, 2) carry features from the multi-view images, and 3) encircle the hand. To leverage the power of points, we design two operations: point-based feature fusion and cross-set point attention mechanism. Evaluation on three challenging multi-view datasets shows that POEM outperforms the state-of-the-art in hand mesh reconstruction. Code and models are available for research at https://github.com/lixiny/POEM.
Querying Large Language Models with SQL
Apr 02, 2023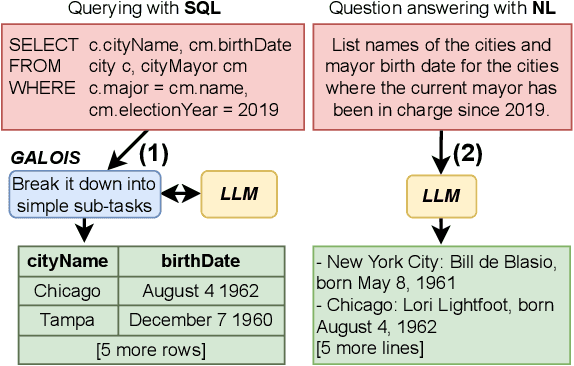

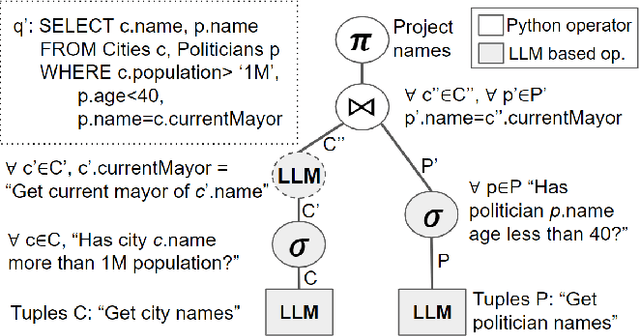
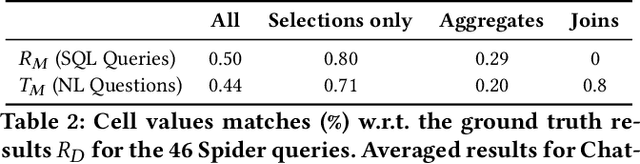
In many use-cases, information is stored in text but not available in structured data. However, extracting data from natural language text to precisely fit a schema, and thus enable querying, is a challenging task. With the rise of pre-trained Large Language Models (LLMs), there is now an effective solution to store and use information extracted from massive corpora of text documents. Thus, we envision the use of SQL queries to cover a broad range of data that is not captured by traditional databases by tapping the information in LLMs. To ground this vision, we present Galois, a prototype based on a traditional database architecture, but with new physical operators for querying the underlying LLM. The main idea is to execute some operators of the the query plan with prompts that retrieve data from the LLM. For a large class of SQL queries, querying LLMs returns well structured relations, with encouraging qualitative results. Preliminary experimental results make pre-trained LLMs a promising addition to the field of database systems, introducing a new direction for hybrid query processing. However, we pinpoint several research challenges that must be addressed to build a DBMS that exploits LLMs. While some of these challenges necessitate integrating concepts from the NLP literature, others offer novel research avenues for the DB community.
Digital Shadows of Safety for Human Robot Collaboration in the World-Wide Lab
Apr 04, 2023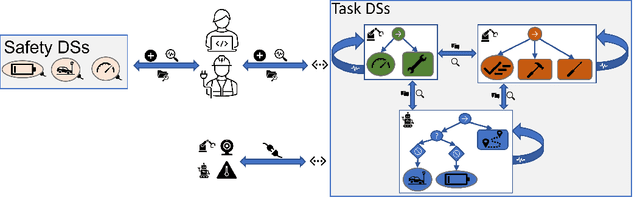
The World Wide Lab (WWL) connects the Digital Shadows (DSs) of processes, products, companies, and other entities allowing the exchange of information across company boundaries. Since DSs are context- and purpose-specific representations of a process, as opposed to Digital Twins (DTs) which offer a full simulation, the integration of a process into the WWL requires the creation of DSs representing different aspects of the process. Human-Robot Collaboration (HRC) for assembly processes was recently studied in the context of the WWL where Behaviour Trees (BTs) were proposed as a standard task-level representation of these processes. We extend previous work by proposing to standardise safety functions that can be directly integrated into these BTs. This addition uses the WWL as a communication and information exchange platform allowing industrial and academic practitioners to exchange, reuse, and experiment with different safety requirements and solutions in the WWL.
COV19IR : COVID-19 Domain Literature Information Retrieval
Nov 08, 2022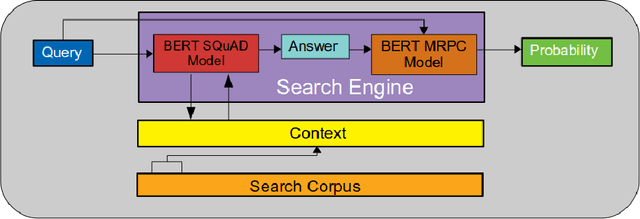
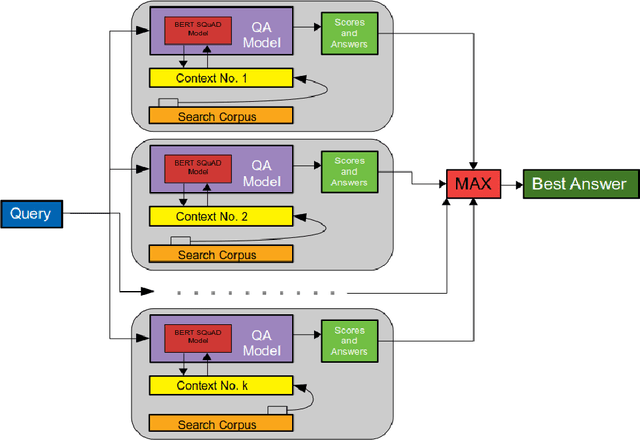
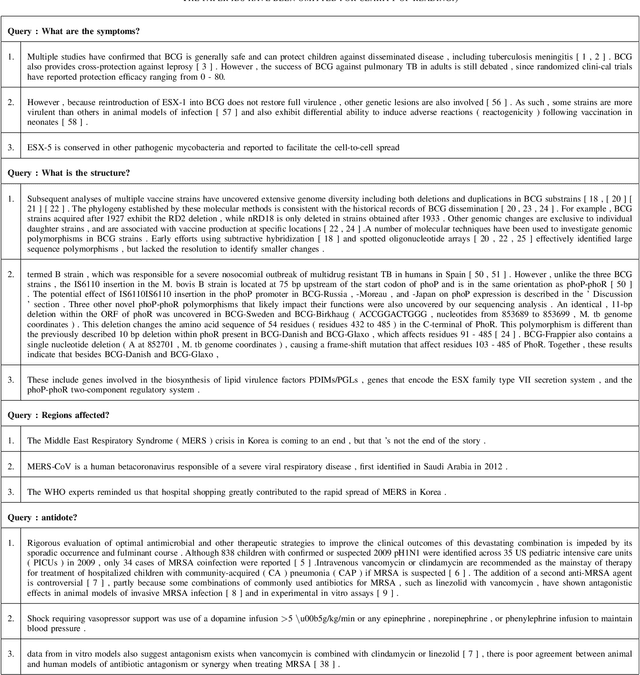
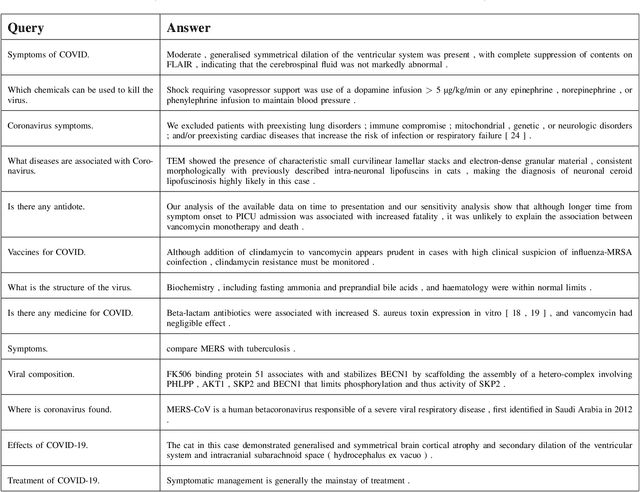
Increasing number of COVID-19 research literatures cause new challenges in effective literature screening and COVID-19 domain knowledge aware Information Retrieval. To tackle the challenges, we demonstrate two tasks along withsolutions, COVID-19 literature retrieval, and question answering. COVID-19 literature retrieval task screens matching COVID-19 literature documents for textual user query, and COVID-19 question answering task predicts proper text fragments from text corpus as the answer of specific COVID-19 related questions. Based on transformer neural network, we provided solutions to implement the tasks on CORD-19 dataset, we display some examples to show the effectiveness of our proposed solutions.
Rumor Detection with Hierarchical Representation on Bipartite Adhoc Event Trees
Apr 27, 2023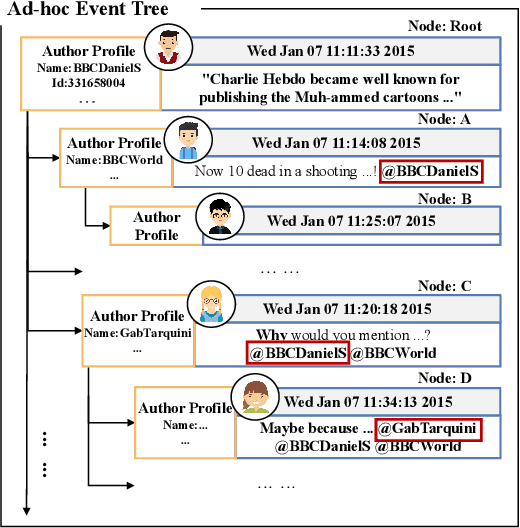
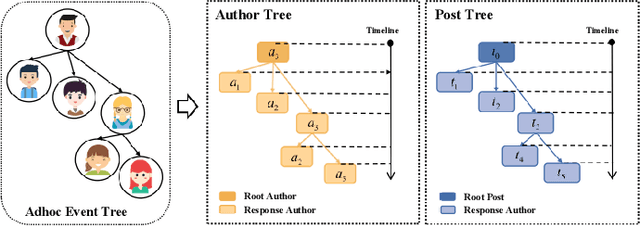
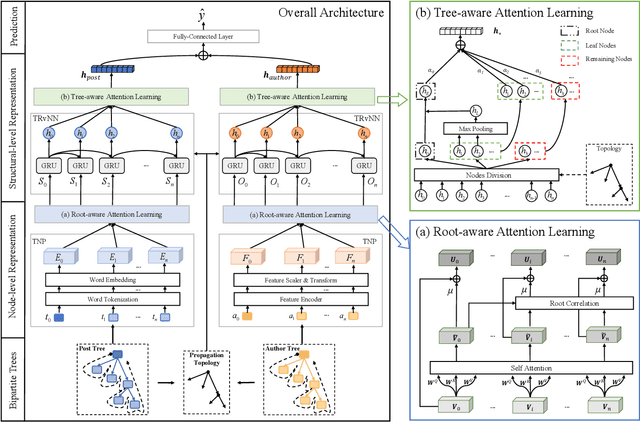
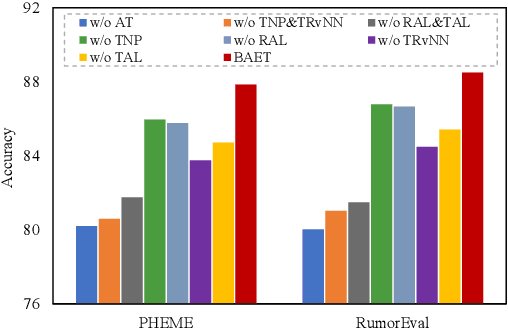
The rapid growth of social media has caused tremendous effects on information propagation, raising extreme challenges in detecting rumors. Existing rumor detection methods typically exploit the reposting propagation of a rumor candidate for detection by regarding all reposts to a rumor candidate as a temporal sequence and learning semantics representations of the repost sequence. However, extracting informative support from the topological structure of propagation and the influence of reposting authors for debunking rumors is crucial, which generally has not been well addressed by existing methods. In this paper, we organize a claim post in circulation as an adhoc event tree, extract event elements, and convert it to bipartite adhoc event trees in terms of both posts and authors, i.e., author tree and post tree. Accordingly, we propose a novel rumor detection model with hierarchical representation on the bipartite adhoc event trees called BAET. Specifically, we introduce word embedding and feature encoder for the author and post tree, respectively, and design a root-aware attention module to perform node representation. Then we adopt the tree-like RNN model to capture the structural correlations and propose a tree-aware attention module to learn tree representation for the author tree and post tree, respectively. Extensive experimental results on two public Twitter datasets demonstrate the effectiveness of BAET in exploring and exploiting the rumor propagation structure and the superior detection performance of BAET over state-of-the-art baseline methods.
Towards hypergraph cognitive networks as feature-rich models of knowledge
Apr 13, 2023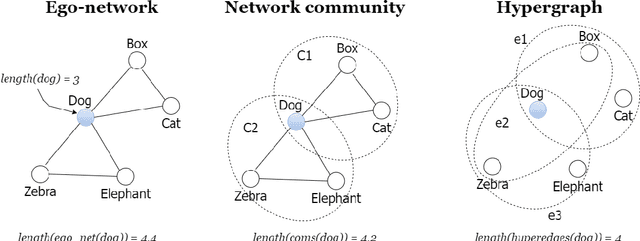
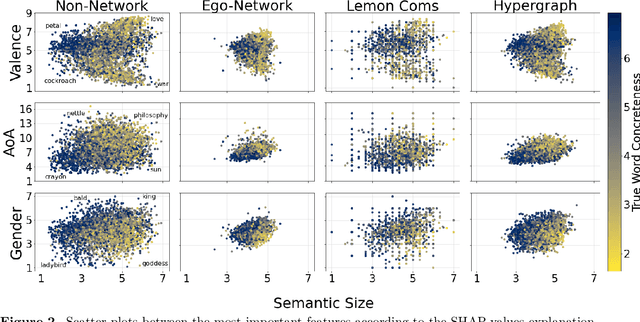
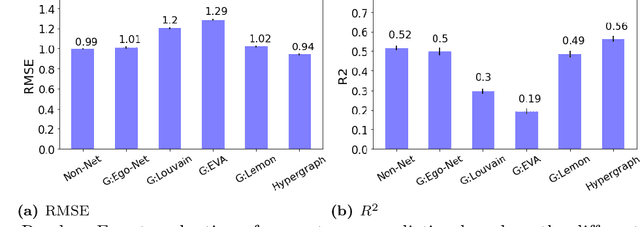
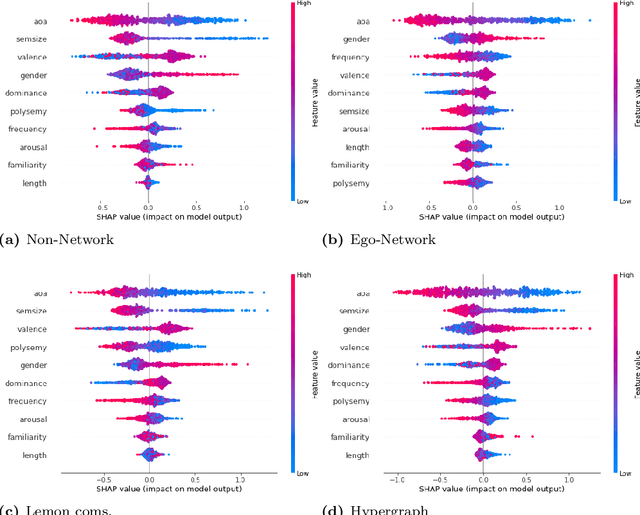
Semantic networks provide a useful tool to understand how related concepts are retrieved from memory. However, most current network approaches use pairwise links to represent memory recall patterns. Pairwise connections neglect higher-order associations, i.e. relationships between more than two concepts at a time. These higher-order interactions might covariate with (and thus contain information about) how similar concepts are along psycholinguistic dimensions like arousal, valence, familiarity, gender and others. We overcome these limits by introducing feature-rich cognitive hypergraphs as quantitative models of human memory where: (i) concepts recalled together can all engage in hyperlinks involving also more than two concepts at once (cognitive hypergraph aspect), and (ii) each concept is endowed with a vector of psycholinguistic features (feature-rich aspect). We build hypergraphs from word association data and use evaluation methods from machine learning features to predict concept concreteness. Since concepts with similar concreteness tend to cluster together in human memory, we expect to be able to leverage this structure. Using word association data from the Small World of Words dataset, we compared a pairwise network and a hypergraph with N=3586 concepts/nodes. Interpretable artificial intelligence models trained on (1) psycholinguistic features only, (2) pairwise-based feature aggregations, and on (3) hypergraph-based aggregations show significant differences between pairwise and hypergraph links. Specifically, our results show that higher-order and feature-rich hypergraph models contain richer information than pairwise networks leading to improved prediction of word concreteness. The relation with previous studies about conceptual clustering and compartmentalisation in associative knowledge and human memory are discussed.
Road Network Representation Learning: A Dual Graph based Approach
Apr 13, 2023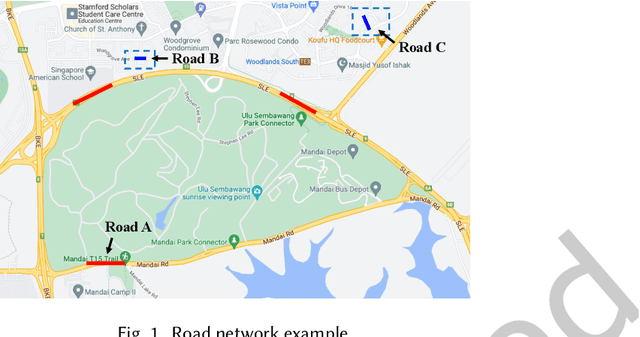
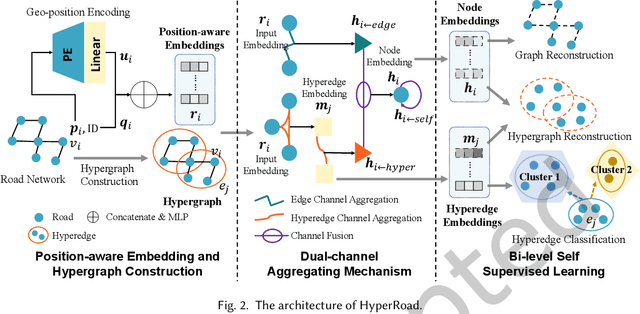
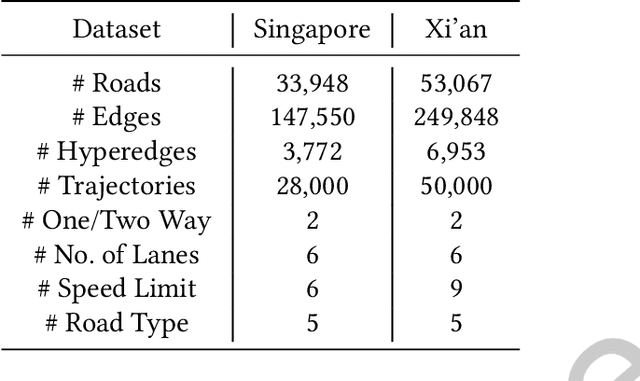
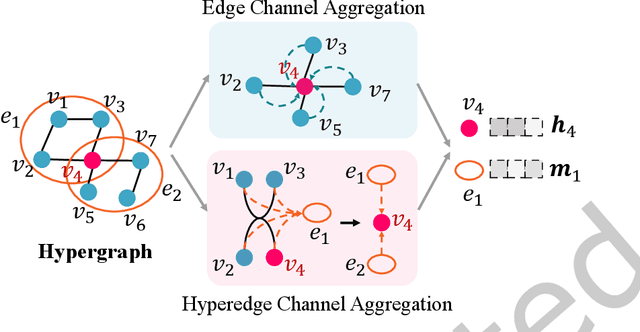
Road network is a critical infrastructure powering many applications including transportation, mobility and logistics in real life. To leverage the input of a road network across these different applications, it is necessary to learn the representations of the roads in the form of vectors, which is named \emph{road network representation learning} (RNRL). While several models have been proposed for RNRL, they capture the pairwise relationships/connections among roads only (i.e., as a simple graph), and fail to capture among roads the high-order relationships (e.g., those roads that jointly form a local region usually have similar features such as speed limit) and long-range relationships (e.g., some roads that are far apart may have similar semantics such as being roads in residential areas). Motivated by this, we propose to construct a \emph{hypergraph}, where each hyperedge corresponds to a set of multiple roads forming a region. The constructed hypergraph would naturally capture the high-order relationships among roads with hyperedges. We then allow information propagation via both the edges in the simple graph and the hyperedges in the hypergraph in a graph neural network context. The graph reconstruction and hypergraph reconstruction tasks are conventional ones and can capture structural information. The hyperedge classification task can capture long-range relationships between pairs of roads that belong to hyperedges with the same label. We call the resulting model \emph{HyperRoad}. We further extend HyperRoad to problem settings when additional inputs of road attributes and/or trajectories that are generated on the roads are available.
NELoRa-Bench: A Benchmark for Neural-enhanced LoRa Demodulation
Apr 20, 2023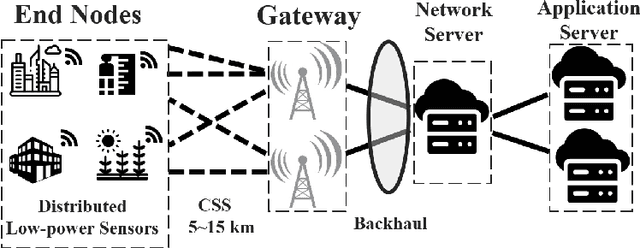
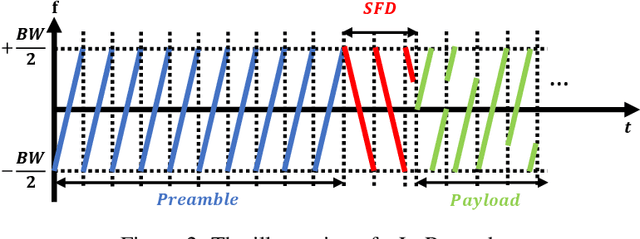
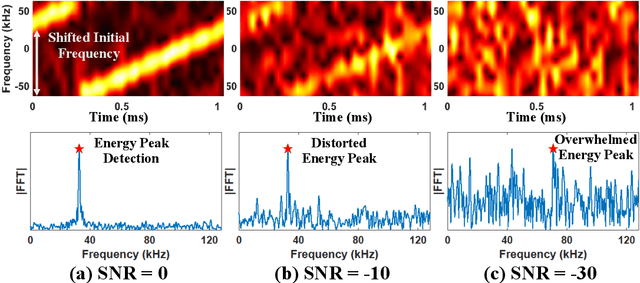

Low-Power Wide-Area Networks (LPWANs) are an emerging Internet-of-Things (IoT) paradigm marked by low-power and long-distance communication. Among them, LoRa is widely deployed for its unique characteristics and open-source technology. By adopting the Chirp Spread Spectrum (CSS) modulation, LoRa enables low signal-to-noise ratio (SNR) communication. The standard LoRa demodulation method accumulates the chirp power of the whole chirp into an energy peak in the frequency domain. In this way, it can support communication even when SNR is lower than -15 dB. Beyond that, we proposed NELoRa, a neural-enhanced decoder that exploits multi-dimensional information to achieve significant SNR gain. This paper presents the dataset used to train/test NELoRa, which includes 27,329 LoRa symbols with spreading factors from 7 to 10, for further improvement of neural-enhanced LoRa demodulation. The dataset shows that NELoRa can achieve 1.84-2.35 dB SNR gain over the standard LoRa decoder. The dataset and codes can be found at https://github.com/daibiaoxuwu/NeLoRa_Dataset.
SATA: Source Anchoring and Target Alignment Network for Continual Test Time Adaptation
Apr 20, 2023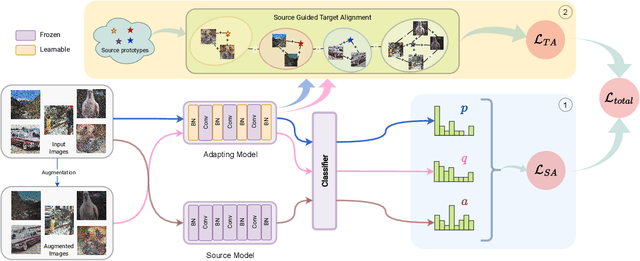
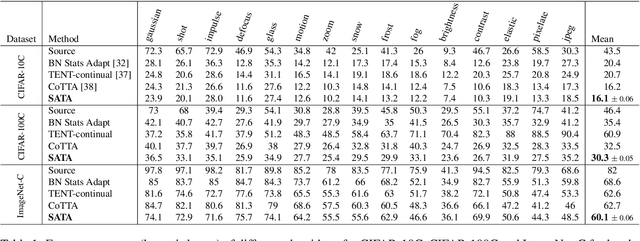
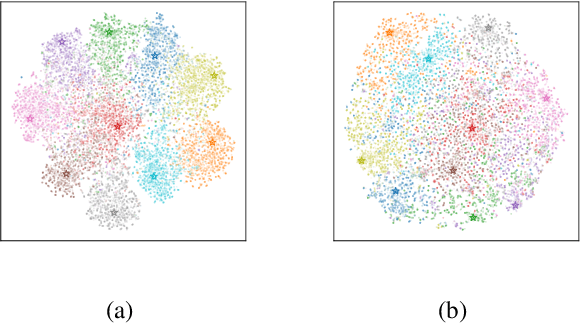

Adapting a trained model to perform satisfactorily on continually changing testing domains/environments is an important and challenging task. In this work, we propose a novel framework, SATA, which aims to satisfy the following characteristics required for online adaptation: 1) can work seamlessly with different (preferably small) batch sizes to reduce latency; 2) should continue to work well for the source domain; 3) should have minimal tunable hyper-parameters and storage requirements. Given a pre-trained network trained on source domain data, the proposed SATA framework modifies the batch-norm affine parameters using source anchoring based self-distillation. This ensures that the model incorporates the knowledge of the newly encountered domains, without catastrophically forgetting about the previously seen ones. We also propose a source-prototype driven contrastive alignment to ensure natural grouping of the target samples, while maintaining the already learnt semantic information. Extensive evaluation on three benchmark datasets under challenging settings justify the effectiveness of SATA for real-world applications.
HM-ViT: Hetero-modal Vehicle-to-Vehicle Cooperative perception with vision transformer
Apr 20, 2023
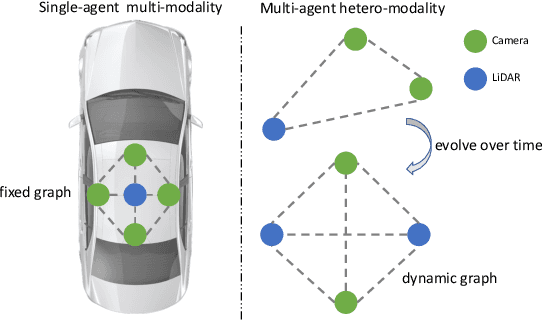
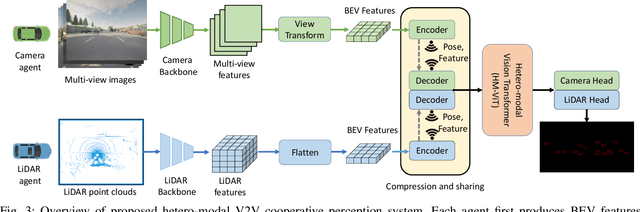
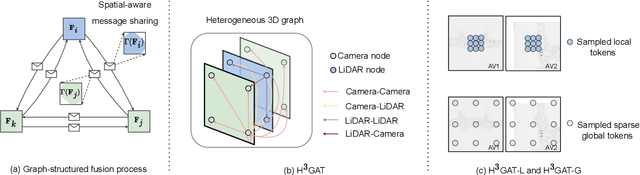
Vehicle-to-Vehicle technologies have enabled autonomous vehicles to share information to see through occlusions, greatly enhancing perception performance. Nevertheless, existing works all focused on homogeneous traffic where vehicles are equipped with the same type of sensors, which significantly hampers the scale of collaboration and benefit of cross-modality interactions. In this paper, we investigate the multi-agent hetero-modal cooperative perception problem where agents may have distinct sensor modalities. We present HM-ViT, the first unified multi-agent hetero-modal cooperative perception framework that can collaboratively predict 3D objects for highly dynamic vehicle-to-vehicle (V2V) collaborations with varying numbers and types of agents. To effectively fuse features from multi-view images and LiDAR point clouds, we design a novel heterogeneous 3D graph transformer to jointly reason inter-agent and intra-agent interactions. The extensive experiments on the V2V perception dataset OPV2V demonstrate that the HM-ViT outperforms SOTA cooperative perception methods for V2V hetero-modal cooperative perception. We will release codes to facilitate future research.