 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Using Multiple RDF Knowledge Graphs for Enriching ChatGPT Responses
Apr 12, 2023
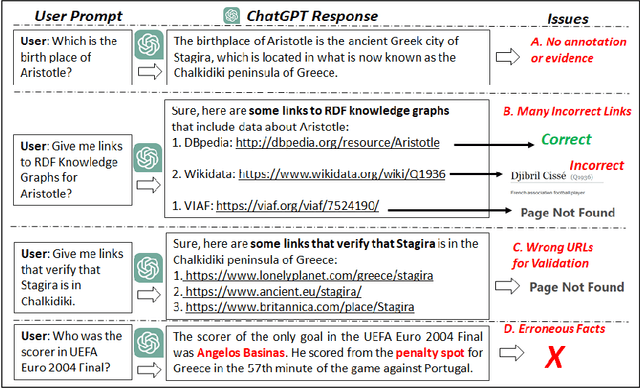
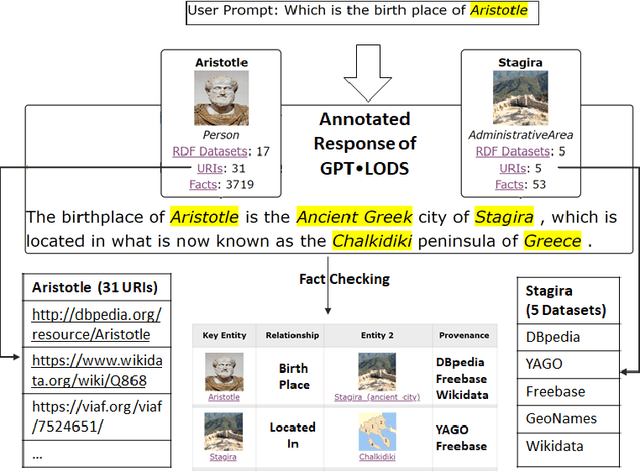
There is a recent trend for using the novel Artificial Intelligence ChatGPT chatbox, which provides detailed responses and articulate answers across many domains of knowledge. However, in many cases it returns plausible-sounding but incorrect or inaccurate responses, whereas it does not provide evidence. Therefore, any user has to further search for checking the accuracy of the answer or/and for finding more information about the entities of the response. At the same time there is a high proliferation of RDF Knowledge Graphs (KGs) over any real domain, that offer high quality structured data. For enabling the combination of ChatGPT and RDF KGs, we present a research prototype, called GPToLODS, which is able to enrich any ChatGPT response with more information from hundreds of RDF KGs. In particular, it identifies and annotates each entity of the response with statistics and hyperlinks to LODsyndesis KG (which contains integrated data from 400 RDF KGs and over 412 million entities). In this way, it is feasible to enrich the content of entities and to perform fact checking and validation for the facts of the response at real time.
From Words to Code: Harnessing Data for Program Synthesis from Natural Language
May 03, 2023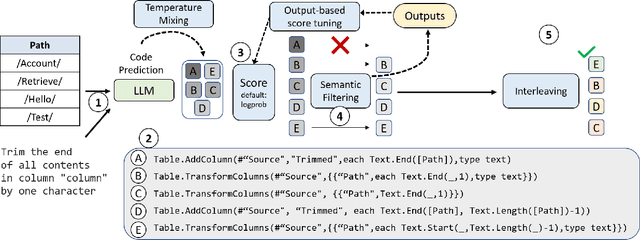
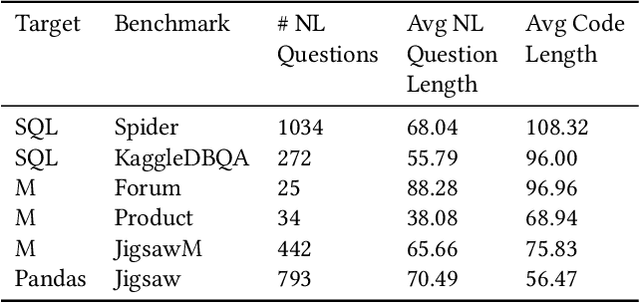
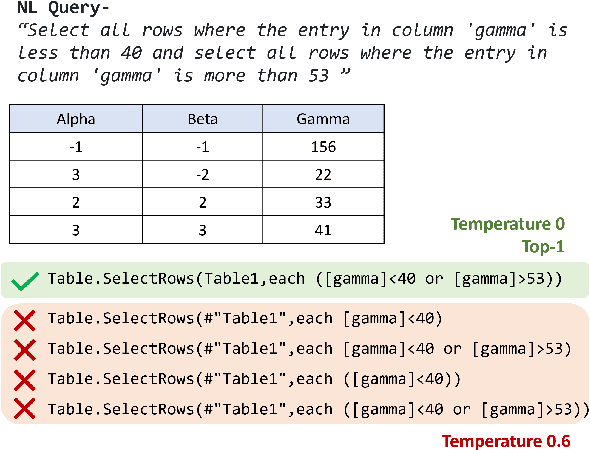
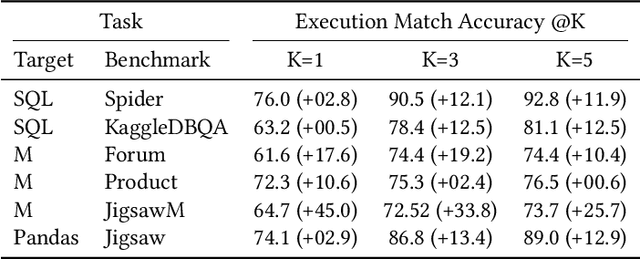
Creating programs to correctly manipulate data is a difficult task, as the underlying programming languages and APIs can be challenging to learn for many users who are not skilled programmers. Large language models (LLMs) demonstrate remarkable potential for generating code from natural language, but in the data manipulation domain, apart from the natural language (NL) description of the intended task, we also have the dataset on which the task is to be performed, or the "data context". Existing approaches have utilized data context in a limited way by simply adding relevant information from the input data into the prompts sent to the LLM. In this work, we utilize the available input data to execute the candidate programs generated by the LLMs and gather their outputs. We introduce semantic reranking, a technique to rerank the programs generated by LLMs based on three signals coming the program outputs: (a) semantic filtering and well-formedness based score tuning: do programs even generate well-formed outputs, (b) semantic interleaving: how do the outputs from different candidates compare to each other, and (c) output-based score tuning: how do the outputs compare to outputs predicted for the same task. We provide theoretical justification for semantic interleaving. We also introduce temperature mixing, where we combine samples generated by LLMs using both high and low temperatures. We extensively evaluate our approach in three domains, namely databases (SQL), data science (Pandas) and business intelligence (Excel's Power Query M) on a variety of new and existing benchmarks. We observe substantial gains across domains, with improvements of up to 45% in top-1 accuracy and 34% in top-3 accuracy.
Ground-to-UAV Integrated Network: Low Latency Communication over Interference Channel
May 03, 2023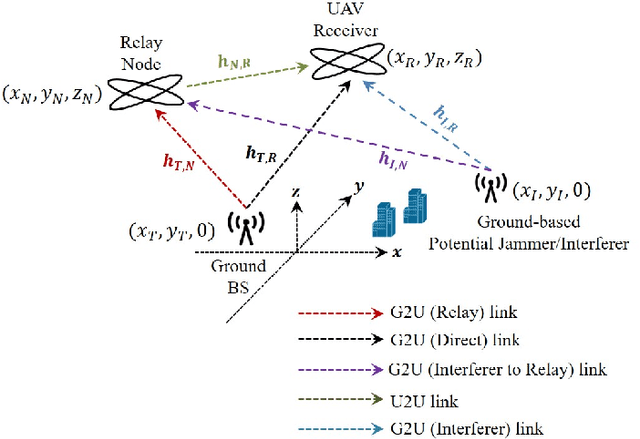
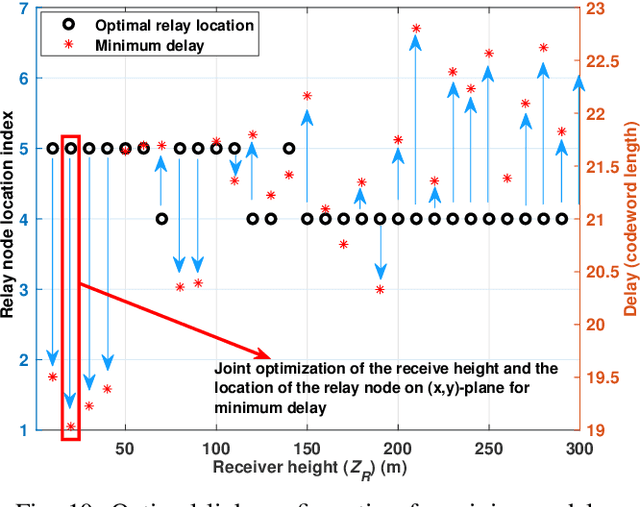
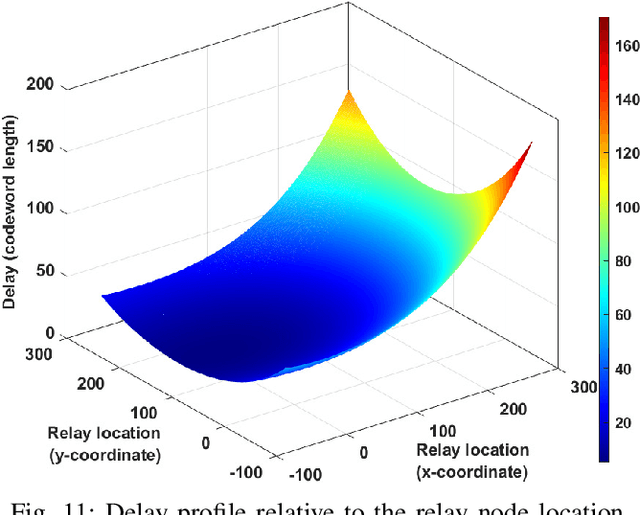
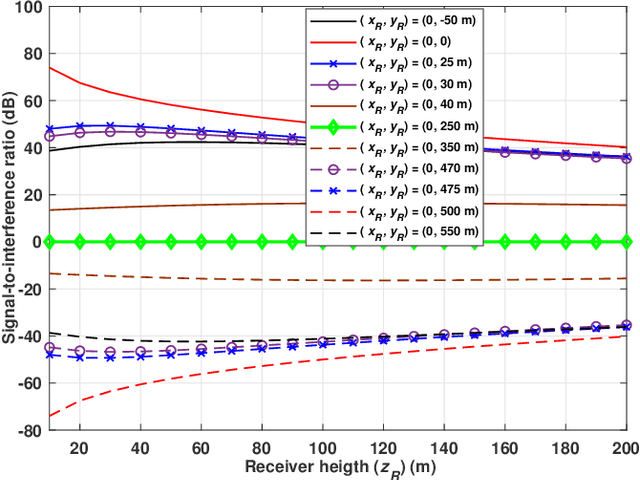
We present a novel and first-of-its-kind information-theoretic framework for the key design consideration and implementation of a ground-to-UAV (G2U) communication network to minimize end-to-end transmission delay in the presence of interference. The proposed framework is useful as it describes the minimum transmission latency for an uplink ground-to-UAV communication must satisfy while achieving a given level of reliability. To characterize the transmission delay, we utilize Fano's inequality and derive the tight upper bound for the capacity for the G2U uplink channel in the presence of interference, noise, and potential jamming. Subsequently, given the reliability constraint, the error exponent is obtained for the given channel. Furthermore, a relay UAV in the dual-hop relay mode, with amplify-and-forward (AF) protocol, is considered, for which we jointly obtain the optimal positions of the relay and the receiver UAVs in the presence of interference. Interestingly, in our study, we find that for both the point-to-point and relayed links, increasing the transmit power may not always be an optimal solution for delay minimization problems. Moreover, we prove that there exists an optimal height that minimizes the end-to-end transmission delay in the presence of interference. The proposed framework can be used in practice by a network controller as a system parameters selection criteria, where among a set of parameters, the parameters leading to the lowest transmission latency can be incorporated into the transmission. The based analysis further set the baseline assessment when applying Command and Control (C2) standards to mission-critical G2U and UAV-to-UAV(U2U) services.
gSDF: Geometry-Driven Signed Distance Functions for 3D Hand-Object Reconstruction
Apr 24, 2023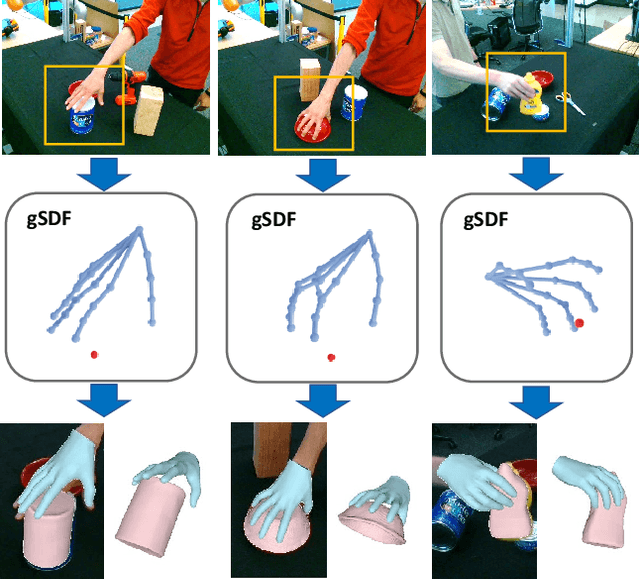
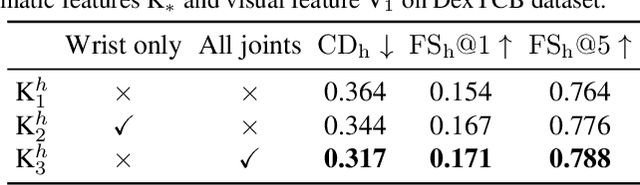
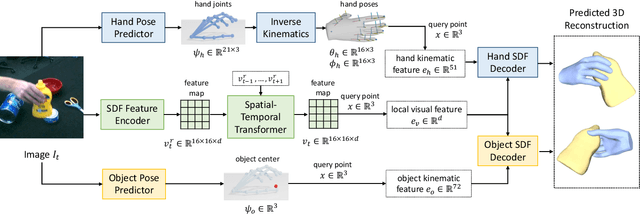

Signed distance functions (SDFs) is an attractive framework that has recently shown promising results for 3D shape reconstruction from images. SDFs seamlessly generalize to different shape resolutions and topologies but lack explicit modelling of the underlying 3D geometry. In this work, we exploit the hand structure and use it as guidance for SDF-based shape reconstruction. In particular, we address reconstruction of hands and manipulated objects from monocular RGB images. To this end, we estimate poses of hands and objects and use them to guide 3D reconstruction. More specifically, we predict kinematic chains of pose transformations and align SDFs with highly-articulated hand poses. We improve the visual features of 3D points with geometry alignment and further leverage temporal information to enhance the robustness to occlusion and motion blurs. We conduct extensive experiments on the challenging ObMan and DexYCB benchmarks and demonstrate significant improvements of the proposed method over the state of the art.
Beyond the Prior Forgery Knowledge: Mining Critical Clues for General Face Forgery Detection
Apr 24, 2023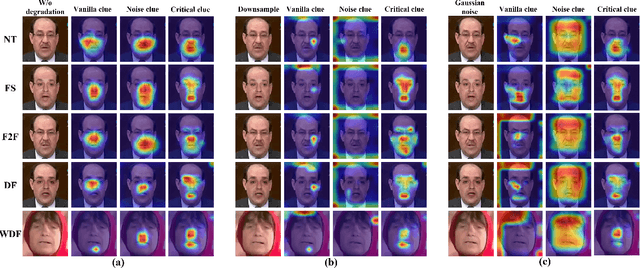
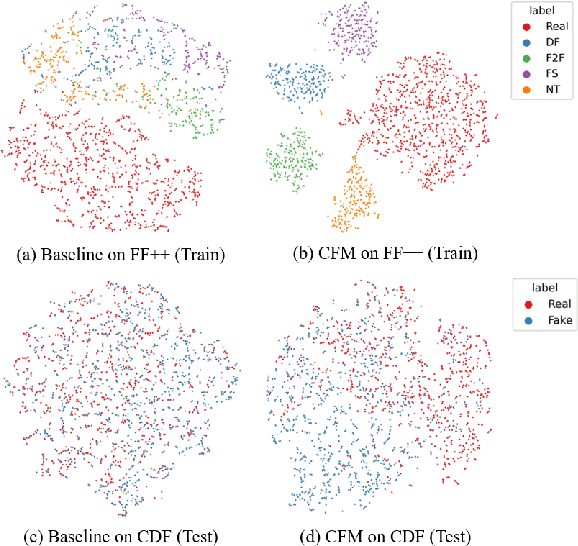
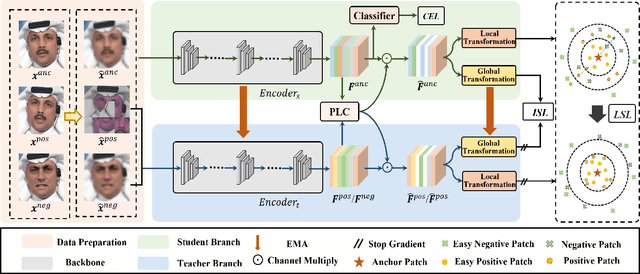
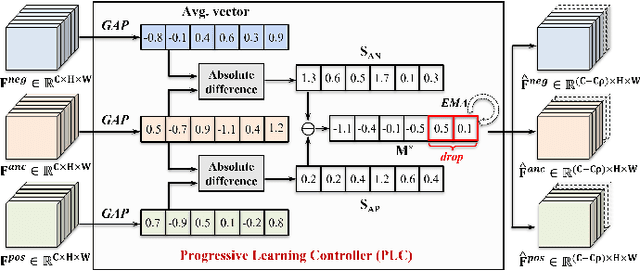
Face forgery detection is essential in combating malicious digital face attacks. Previous methods mainly rely on prior expert knowledge to capture specific forgery clues, such as noise patterns, blending boundaries, and frequency artifacts. However, these methods tend to get trapped in local optima, resulting in limited robustness and generalization capability. To address these issues, we propose a novel Critical Forgery Mining (CFM) framework, which can be flexibly assembled with various backbones to boost their generalization and robustness performance. Specifically, we first build a fine-grained triplet and suppress specific forgery traces through prior knowledge-agnostic data augmentation. Subsequently, we propose a fine-grained relation learning prototype to mine critical information in forgeries through instance and local similarity-aware losses. Moreover, we design a novel progressive learning controller to guide the model to focus on principal feature components, enabling it to learn critical forgery features in a coarse-to-fine manner. The proposed method achieves state-of-the-art forgery detection performance under various challenging evaluation settings.
Attention-guided Multi-step Fusion: A Hierarchical Fusion Network for Multimodal Recommendation
Apr 24, 2023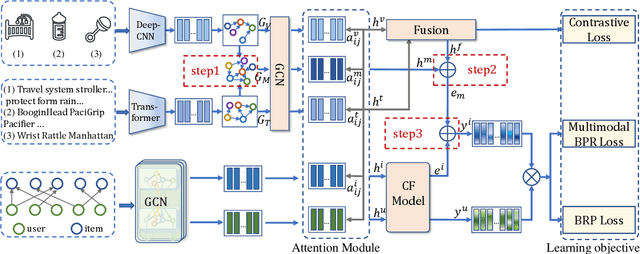
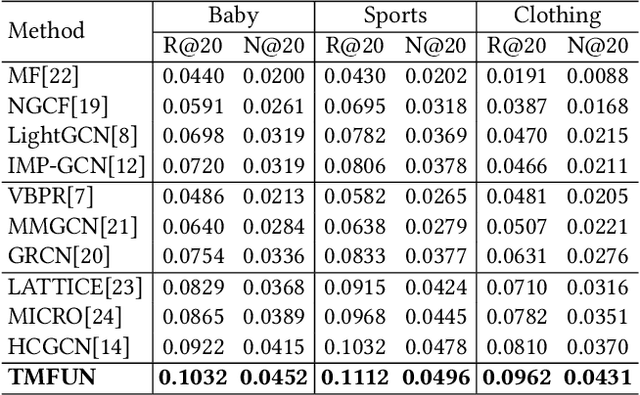
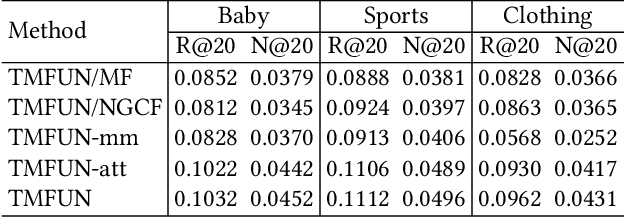
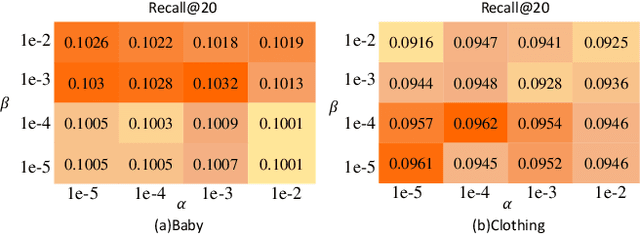
The main idea of multimodal recommendation is the rational utilization of the item's multimodal information to improve the recommendation performance. Previous works directly integrate item multimodal features with item ID embeddings, ignoring the inherent semantic relations contained in the multimodal features. In this paper, we propose a novel and effective aTtention-guided Multi-step FUsion Network for multimodal recommendation, named TMFUN. Specifically, our model first constructs modality feature graph and item feature graph to model the latent item-item semantic structures. Then, we use the attention module to identify inherent connections between user-item interaction data and multimodal data, evaluate the impact of multimodal data on different interactions, and achieve early-step fusion of item features. Furthermore, our model optimizes item representation through the attention-guided multi-step fusion strategy and contrastive learning to improve recommendation performance. The extensive experiments on three real-world datasets show that our model has superior performance compared to the state-of-the-art models.
Multimodal Shannon Game with Images
Mar 20, 2023

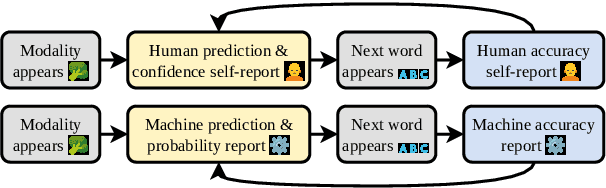

The Shannon game has long been used as a thought experiment in linguistics and NLP, asking participants to guess the next letter in a sentence based on its preceding context. We extend the game by introducing an optional extra modality in the form of image information. To investigate the impact of multimodal information in this game, we use human participants and a language model (LM, GPT-2). We show that the addition of image information improves both self-reported confidence and accuracy for both humans and LM. Certain word classes, such as nouns and determiners, benefit more from the additional modality information. The priming effect in both humans and the LM becomes more apparent as the context size (extra modality information + sentence context) increases. These findings highlight the potential of multimodal information in improving language understanding and modeling.
RSIR Transformer: Hierarchical Vision Transformer using Random Sampling Windows and Important Region Windows
Apr 27, 2023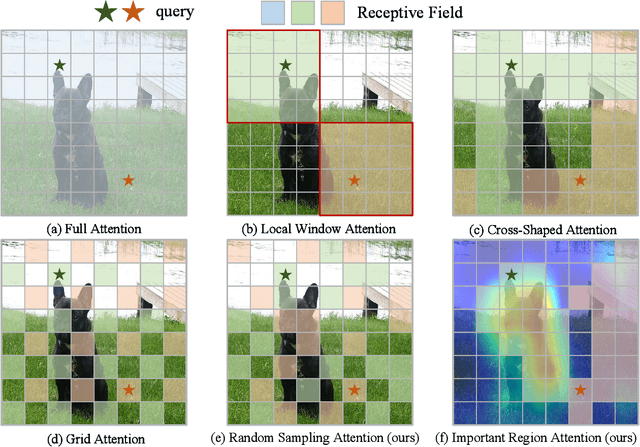
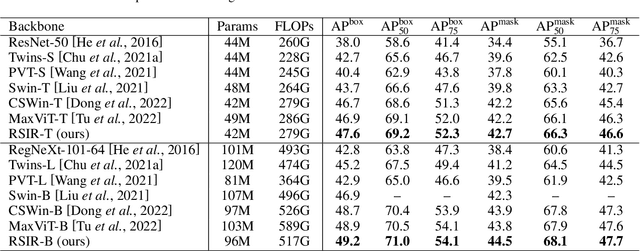
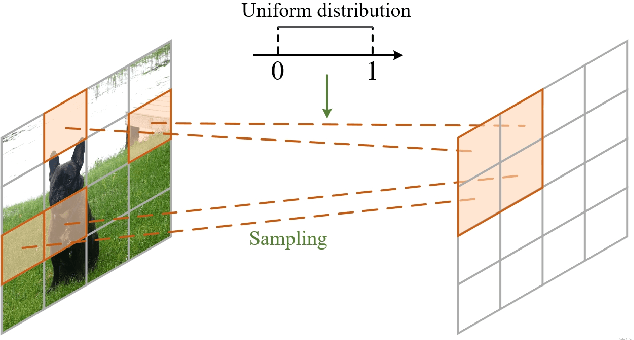
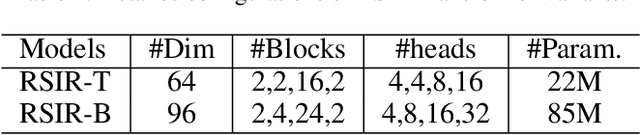
Recently, Transformers have shown promising performance in various vision tasks. However, the high costs of global self-attention remain challenging for Transformers, especially for high-resolution vision tasks. Local self-attention runs attention computation within a limited region for the sake of efficiency, resulting in insufficient context modeling as their receptive fields are small. In this work, we introduce two new attention modules to enhance the global modeling capability of the hierarchical vision transformer, namely, random sampling windows (RS-Win) and important region windows (IR-Win). Specifically, RS-Win sample random image patches to compose the window, following a uniform distribution, i.e., the patches in RS-Win can come from any position in the image. IR-Win composes the window according to the weights of the image patches in the attention map. Notably, RS-Win is able to capture global information throughout the entire model, even in earlier, high-resolution stages. IR-Win enables the self-attention module to focus on important regions of the image and capture more informative features. Incorporated with these designs, RSIR-Win Transformer demonstrates competitive performance on common vision tasks.
Human-machine knowledge hybrid augmentation method for surface defect detection based few-data learning
Apr 27, 2023
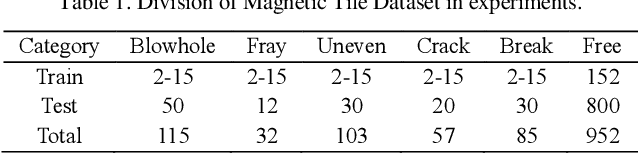
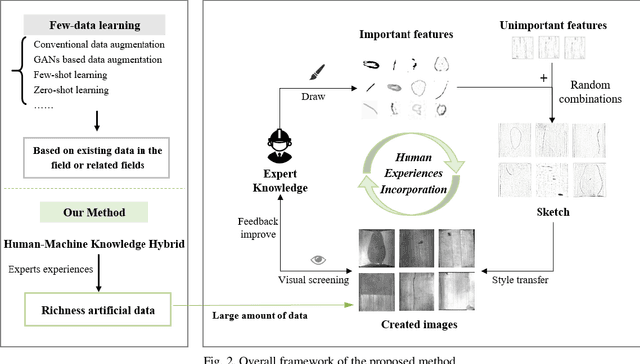

Visual-based defect detection is a crucial but challenging task in industrial quality control. Most mainstream methods rely on large amounts of existing or related domain data as auxiliary information. However, in actual industrial production, there are often multi-batch, low-volume manufacturing scenarios with rapidly changing task demands, making it difficult to obtain sufficient and diverse defect data. This paper proposes a parallel solution that uses a human-machine knowledge hybrid augmentation method to help the model extract unknown important features. Specifically, by incorporating experts' knowledge of abnormality to create data with rich features, positions, sizes, and backgrounds, we can quickly accumulate an amount of data from scratch and provide it to the model as prior knowledge for few-data learning. The proposed method was evaluated on the magnetic tile dataset and achieved F1-scores of 60.73%, 70.82%, 77.09%, and 82.81% when using 2, 5, 10, and 15 training images, respectively. Compared to the traditional augmentation method's F1-score of 64.59%, the proposed method achieved an 18.22% increase in the best result, demonstrating its feasibility and effectiveness in few-data industrial defect detection.
Retrieval-based Knowledge Augmented Vision Language Pre-training
Apr 27, 2023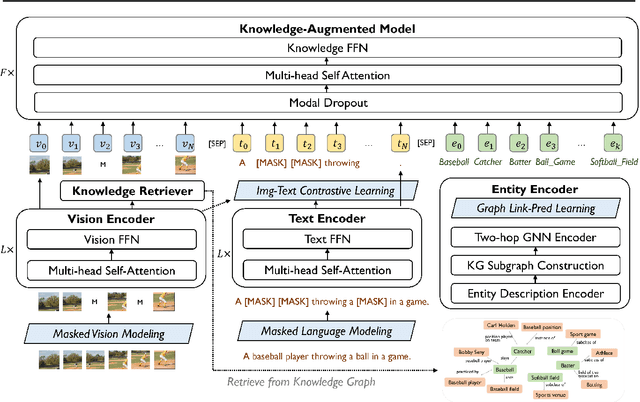
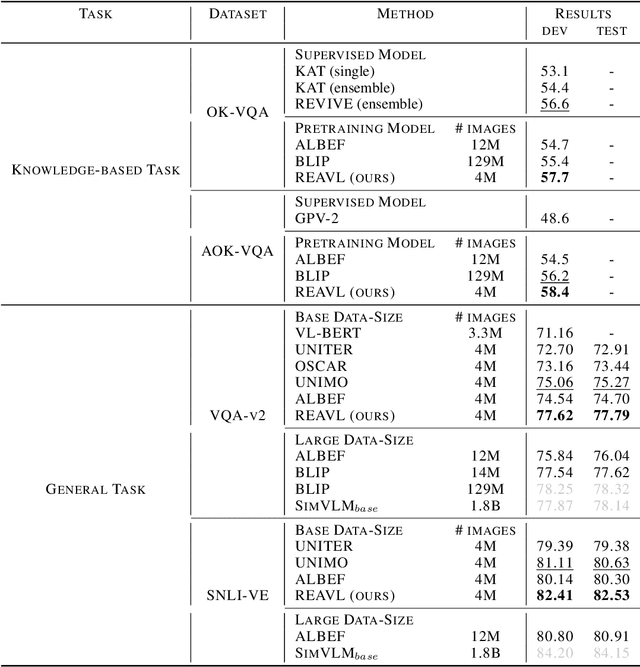
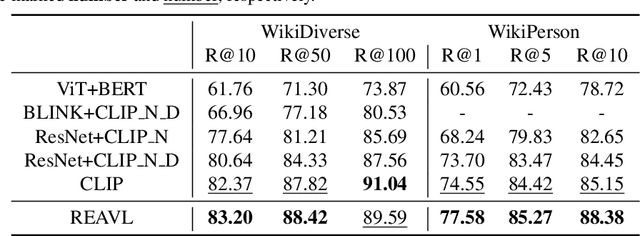
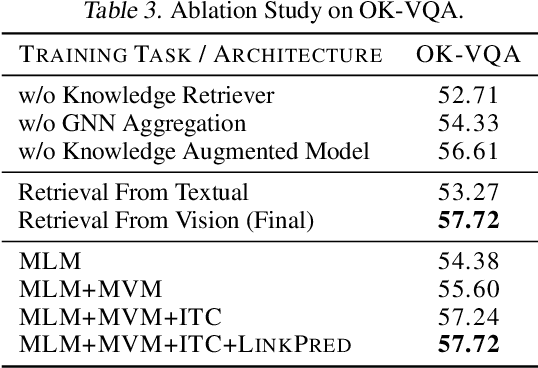
With recent progress in large-scale vision and language representation learning, Vision Language Pretraining (VLP) models have achieved promising improvements on various multi-modal downstream tasks. Albeit powerful, these pre-training models still do not take advantage of world knowledge, which is implicit in multi-modal data but comprises abundant and complementary information. In this work, we propose a REtrieval-based knowledge Augmented Vision Language Pre-training model (REAVL), which retrieves world knowledge from knowledge graphs (KGs) and incorporates them in vision-language pre-training. REAVL has two core components: a knowledge retriever that retrieves knowledge given multi-modal data, and a knowledge-augmented model that fuses multi-modal data and knowledge. By novelly unifying four knowledge-aware self-supervised tasks, REAVL promotes the mutual integration of multi-modal data and knowledge by fusing explicit knowledge with vision-language pairs for masked multi-modal data modeling and KG relational reasoning. Empirical experiments show that REAVL achieves new state-of-the-art performance uniformly on knowledge-based vision-language understanding and multimodal entity linking tasks, and competitive results on general vision-language tasks while only using 0.2% pre-training data of the best models.