 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Decoupled Kullback-Leibler Divergence Loss
May 23, 2023
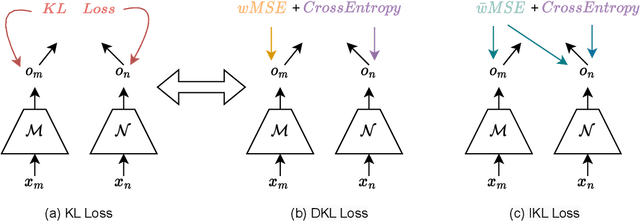
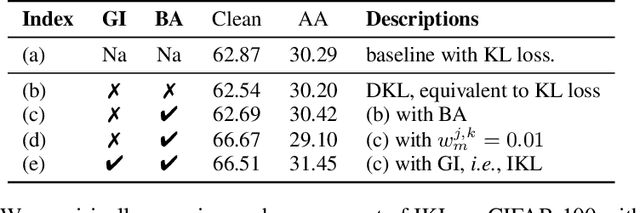
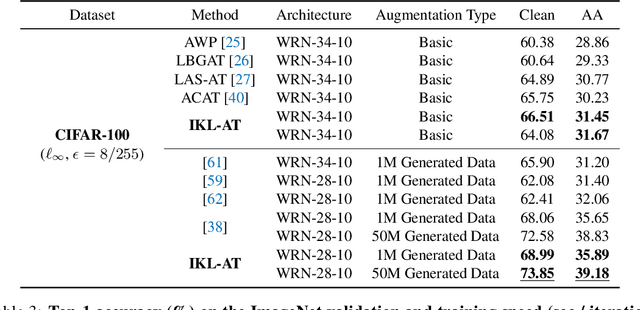
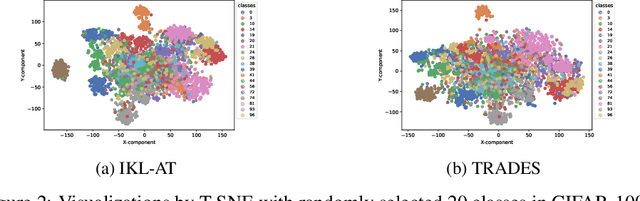
In this paper, we delve deeper into the Kullback-Leibler (KL) Divergence loss and observe that it is equivalent to the Doupled Kullback-Leibler (DKL) Divergence loss that consists of 1) a weighted Mean Square Error (wMSE) loss and 2) a Cross-Entropy loss incorporating soft labels. From our analysis of the DKL loss, we have identified two areas for improvement. Firstly, we address the limitation of DKL in scenarios like knowledge distillation by breaking its asymmetry property in training optimization. This modification ensures that the wMSE component is always effective during training, providing extra constructive cues. Secondly, we introduce global information into DKL for intra-class consistency regularization. With these two enhancements, we derive the Improved Kullback-Leibler (IKL) Divergence loss and evaluate its effectiveness by conducting experiments on CIFAR-10/100 and ImageNet datasets, focusing on adversarial training and knowledge distillation tasks. The proposed approach achieves new state-of-the-art performance on both tasks, demonstrating the substantial practical merits. Code and models will be available soon at https://github.com/jiequancui/DKL.
Diffusion Hyperfeatures: Searching Through Time and Space for Semantic Correspondence
May 23, 2023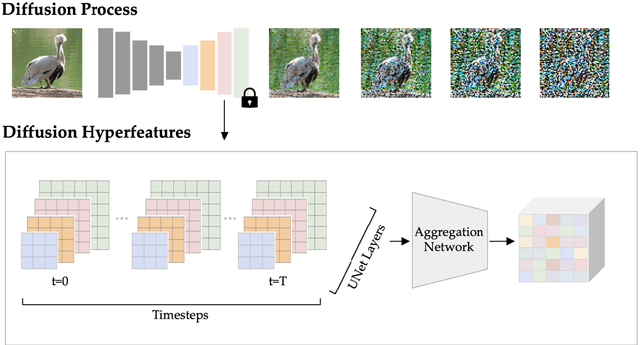
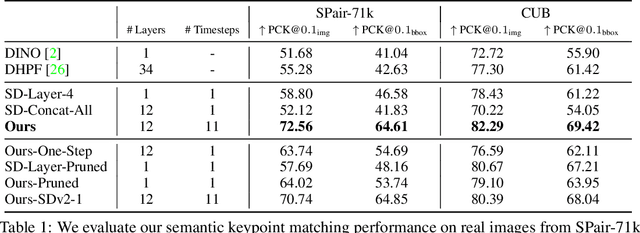
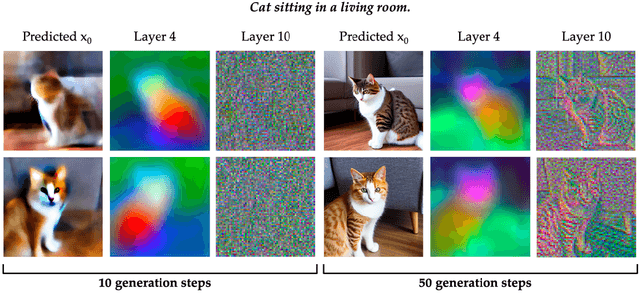
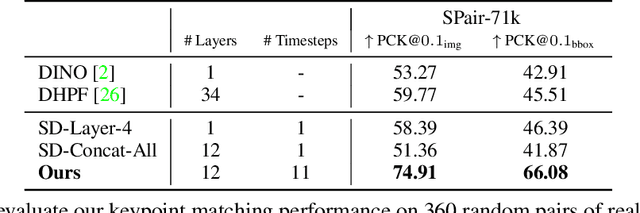
Diffusion models have been shown to be capable of generating high-quality images, suggesting that they could contain meaningful internal representations. Unfortunately, the feature maps that encode a diffusion model's internal information are spread not only over layers of the network, but also over diffusion timesteps, making it challenging to extract useful descriptors. We propose Diffusion Hyperfeatures, a framework for consolidating multi-scale and multi-timestep feature maps into per-pixel feature descriptors that can be used for downstream tasks. These descriptors can be extracted for both synthetic and real images using the generation and inversion processes. We evaluate the utility of our Diffusion Hyperfeatures on the task of semantic keypoint correspondence: our method achieves superior performance on the SPair-71k real image benchmark. We also demonstrate that our method is flexible and transferable: our feature aggregation network trained on the inversion features of real image pairs can be used on the generation features of synthetic image pairs with unseen objects and compositions. Our code is available at \url{https://diffusion-hyperfeatures.github.io}.
Instance-Level Semantic Maps for Vision Language Navigation
May 23, 2023
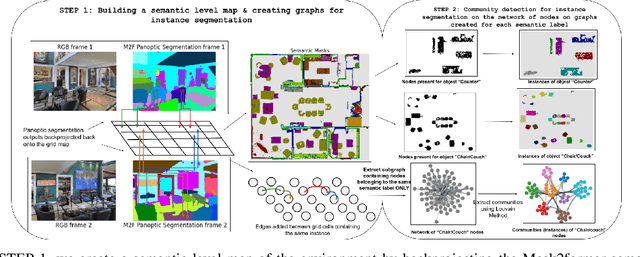
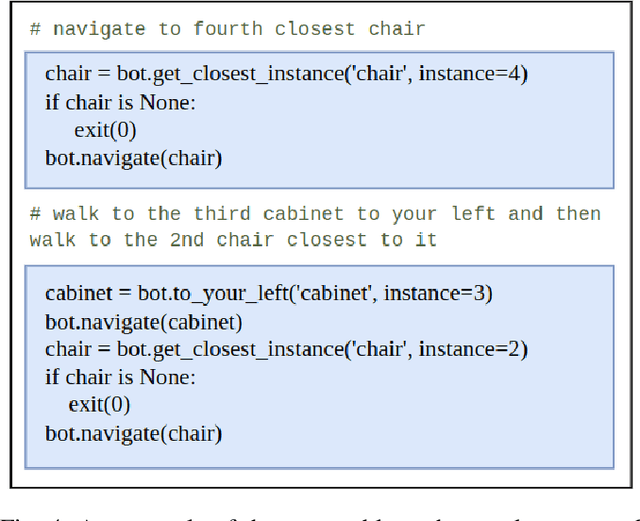

Humans have a natural ability to perform semantic associations with the surrounding objects in the environment. This allows them to create a mental map of the environment which helps them to navigate on-demand when given a linguistic instruction. A natural goal in Vision Language Navigation (VLN) research is to impart autonomous agents with similar capabilities. Recently introduced VL Maps \cite{huang23vlmaps} take a step towards this goal by creating a semantic spatial map representation of the environment without any labelled data. However, their representations are limited for practical applicability as they do not distinguish between different instances of the same object. In this work, we address this limitation by integrating instance-level information into spatial map representation using a community detection algorithm and by utilizing word ontology learned by large language models (LLMs) to perform open-set semantic associations in the mapping representation. The resulting map representation improves the navigation performance by two-fold (233\%) on realistic language commands with instance-specific descriptions compared to VL Maps. We validate the practicality and effectiveness of our approach through extensive qualitative and quantitative experiments.
Concept-aware Training Improves In-context Learning Ability of Language Models
May 23, 2023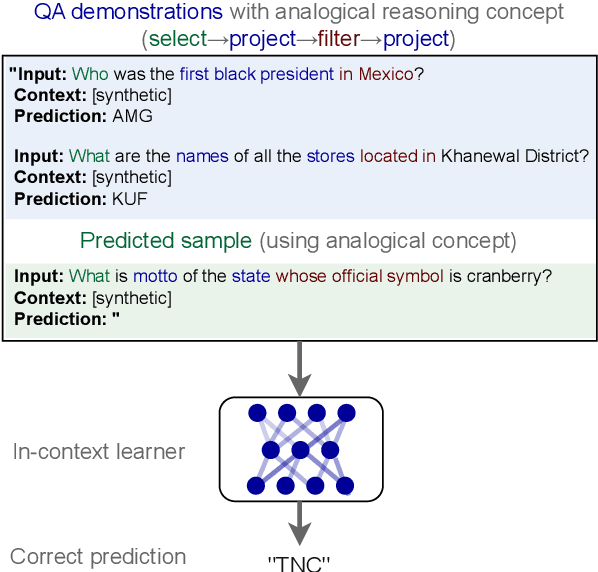
Many recent language models (LMs) of Transformers family exhibit so-called in-context learning (ICL) ability, manifested in the LMs' ability to modulate their function by a task described in a natural language input. Previous work curating these models assumes that ICL emerges from vast over-parametrization or the scale of multi-task training. However, a complementary branch of recent theoretical work attributes ICL emergence to specific properties of training data and creates functional in-context learners in small-scale, synthetic settings. Inspired by recent findings on data properties driving the emergence of ICL, we propose a method to create LMs able to better utilize the in-context information, by constructing training scenarios where it is beneficial for the LM to capture the analogical reasoning concepts. We measure that data sampling of Concept-aware Training (CoAT) consistently improves models' reasoning ability. As a result, the in-context learners trained with CoAT on only two datasets of a single (QA) task perform comparably to larger models trained on 1600+ tasks.
Counterspeeches up my sleeve! Intent Distribution Learning and Persistent Fusion for Intent-Conditioned Counterspeech Generation
May 23, 2023
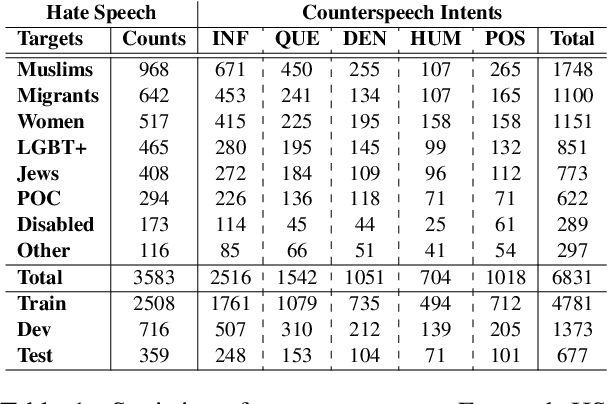

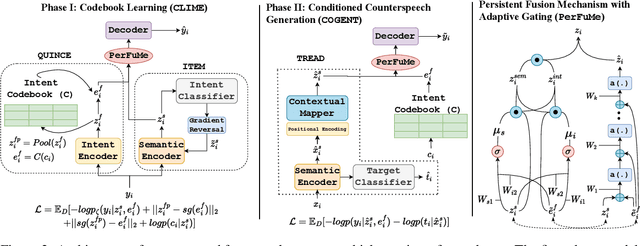
Counterspeech has been demonstrated to be an efficacious approach for combating hate speech. While various conventional and controlled approaches have been studied in recent years to generate counterspeech, a counterspeech with a certain intent may not be sufficient in every scenario. Due to the complex and multifaceted nature of hate speech, utilizing multiple forms of counter-narratives with varying intents may be advantageous in different circumstances. In this paper, we explore intent-conditioned counterspeech generation. At first, we develop IntentCONAN, a diversified intent-specific counterspeech dataset with 6831 counterspeeches conditioned on five intents, i.e., informative, denouncing, question, positive, and humour. Subsequently, we propose QUARC, a two-stage framework for intent-conditioned counterspeech generation. QUARC leverages vector-quantized representations learned for each intent category along with PerFuMe, a novel fusion module to incorporate intent-specific information into the model. Our evaluation demonstrates that QUARC outperforms several baselines by an average of 10% across evaluation metrics. An extensive human evaluation supplements our hypothesis of better and more appropriate responses than comparative systems.
Continual Dialogue State Tracking via Example-Guided Question Answering
May 23, 2023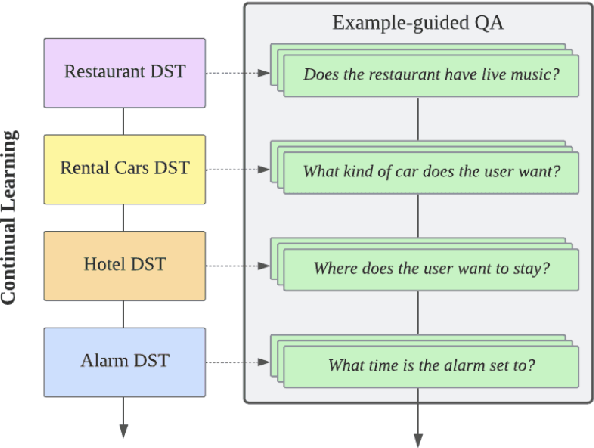
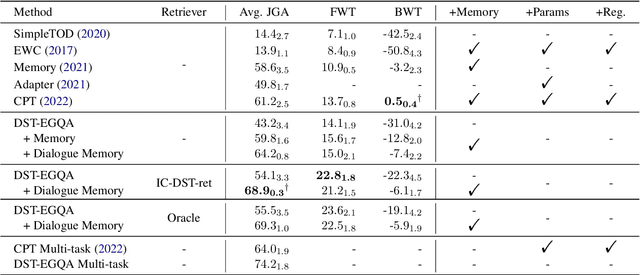
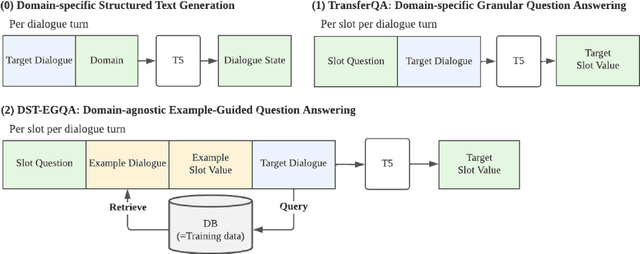

Dialogue systems are frequently updated to accommodate new services, but naively updating them by continually training with data for new services in diminishing performance on previously learnt services. Motivated by the insight that dialogue state tracking (DST), a crucial component of dialogue systems that estimates the user's goal as a conversation proceeds, is a simple natural language understanding task, we propose reformulating it as a bundle of granular example-guided question answering tasks to minimize the task shift between services and thus benefit continual learning. Our approach alleviates service-specific memorization and teaches a model to contextualize the given question and example to extract the necessary information from the conversation. We find that a model with just 60M parameters can achieve a significant boost by learning to learn from in-context examples retrieved by a retriever trained to identify turns with similar dialogue state changes. Combining our method with dialogue-level memory replay, our approach attains state of the art performance on DST continual learning metrics without relying on any complex regularization or parameter expansion methods.
Polyglot or Not? Measuring Multilingual Encyclopedic Knowledge Retrieval from Foundation Language Models
May 23, 2023In this work, we evaluate the capacity for foundation models to retrieve encyclopedic knowledge across a wide range of languages, topics, and contexts. To support this effort, we 1) produce a new dataset containing 303k factual associations in 20 different languages, 2) formulate a new counterfactual knowledge assessment, Polyglot or Not, and 3) benchmark 5 foundation models in a multilingual setting and a diverse set of 20 models in an English-only setting. We observed significant accuracy differences in models of interest, with Meta's LLaMA topping both the multilingual and English-only assessments. Error analysis reveals a significant deficiency in LLaMA's ability to retrieve facts in languages written in the Cyrillic script and gaps in its understanding of facts based on the location and gender of entailed subjects. Ultimately, we argue that the promise of utilizing foundation language models as bonafide polyglots is greatly diminished when they are tasked with retrieving information in languages other than English. Supporting code (https://github.com/daniel-furman/Polyglot-or-Not) and dataset (https://huggingface.co/datasets/Polyglot-or-Not/Fact-Completion) are openly released.
Beyond Shared Vocabulary: Increasing Representational Word Similarities across Languages for Multilingual Machine Translation
May 23, 2023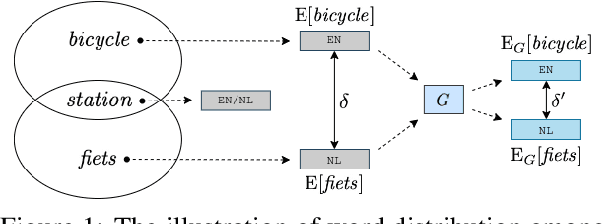
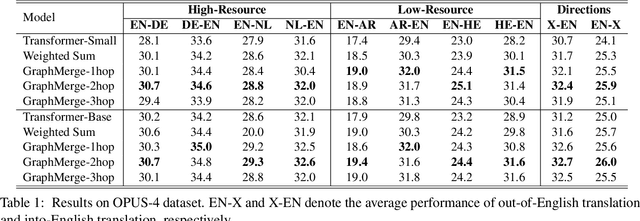
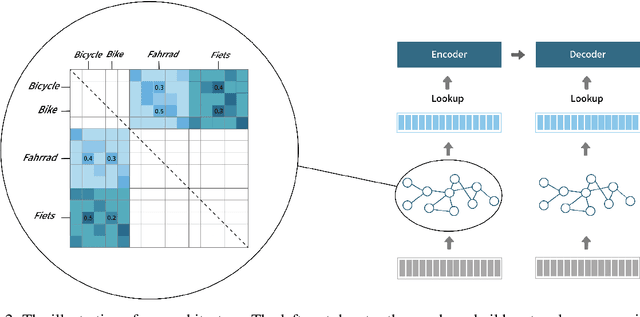
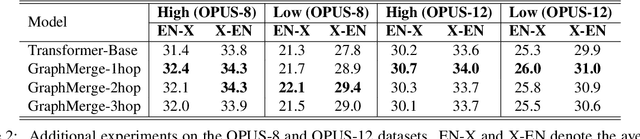
Using a shared vocabulary is common practice in Multilingual Neural Machine Translation (MNMT). In addition to its simple design, shared tokens play an important role in positive knowledge transfer, which manifests naturally when the shared tokens refer to similar meanings across languages. However, natural flaws exist in such a design as well: 1) when languages use different writing systems, transfer is inhibited, and 2) even if languages use similar writing systems, shared tokens may have completely different meanings in different languages, increasing ambiguity. In this paper, we propose a re-parameterized method for building embeddings to alleviate the first problem. More specifically, we define word-level information transfer pathways via word equivalence classes and rely on graph networks to fuse word embeddings across languages. Our experiments demonstrate the advantages of our approach: 1) the semantics of embeddings are better aligned across languages, 2) our method achieves significant BLEU improvements on high- and low-resource MNMT, and 3) only less than 1.0\% additional trainable parameters are required with a limited increase in computational costs.
Do All Languages Cost the Same? Tokenization in the Era of Commercial Language Models
May 23, 2023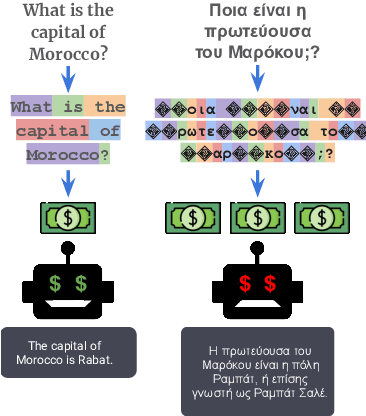
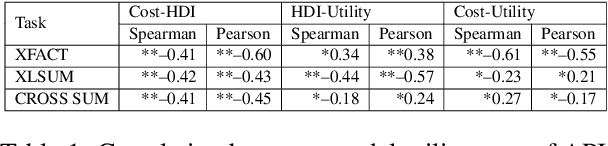
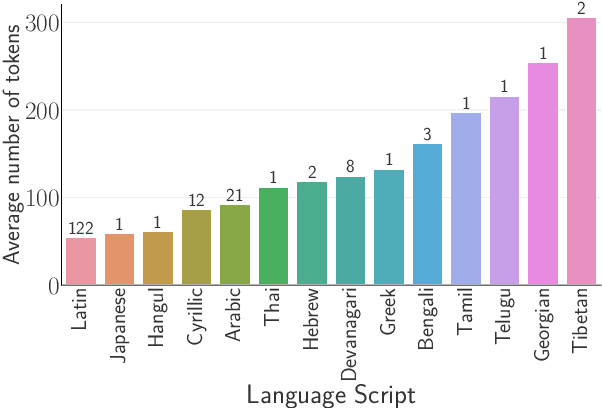

Language models have graduated from being research prototypes to commercialized products offered as web APIs, and recent works have highlighted the multilingual capabilities of these products. The API vendors charge their users based on usage, more specifically on the number of ``tokens'' processed or generated by the underlying language models. What constitutes a token, however, is training data and model dependent with a large variance in the number of tokens required to convey the same information in different languages. In this work, we analyze the effect of this non-uniformity on the fairness of an API's pricing policy across languages. We conduct a systematic analysis of the cost and utility of OpenAI's language model API on multilingual benchmarks in 22 typologically diverse languages. We show evidence that speakers of a large number of the supported languages are overcharged while obtaining poorer results. These speakers tend to also come from regions where the APIs are less affordable to begin with. Through these analyses, we aim to increase transparency around language model APIs' pricing policies and encourage the vendors to make them more equitable.
Interpretation of Time-Series Deep Models: A Survey
May 23, 2023
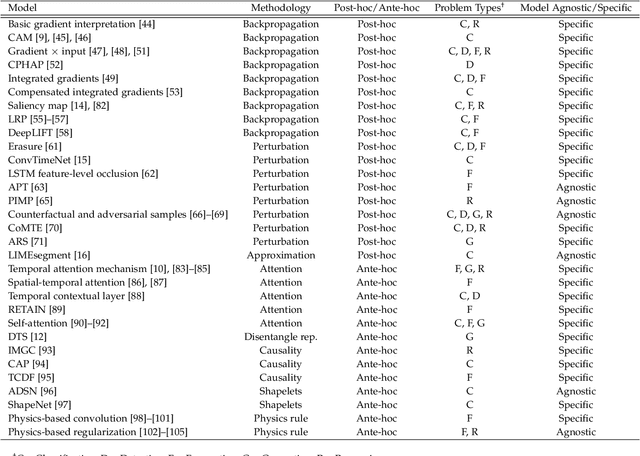
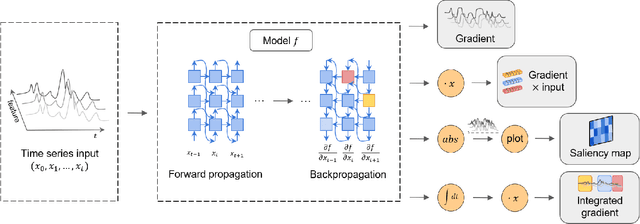
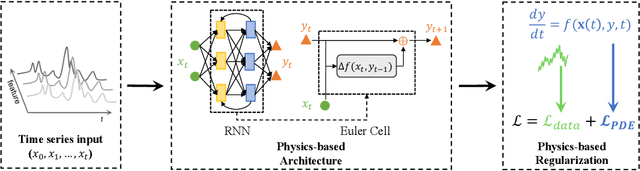
Deep learning models developed for time-series associated tasks have become more widely researched nowadays. However, due to the unintuitive nature of time-series data, the interpretability problem -- where we understand what is under the hood of these models -- becomes crucial. The advancement of similar studies in computer vision has given rise to many post-hoc methods, which can also shed light on how to explain time-series models. In this paper, we present a wide range of post-hoc interpretation methods for time-series models based on backpropagation, perturbation, and approximation. We also want to bring focus onto inherently interpretable models, a novel category of interpretation where human-understandable information is designed within the models. Furthermore, we introduce some common evaluation metrics used for the explanations, and propose several directions of future researches on the time-series interpretability problem. As a highlight, our work summarizes not only the well-established interpretation methods, but also a handful of fairly recent and under-developed techniques, which we hope to capture their essence and spark future endeavours to innovate and improvise.