 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Novel deep learning methods for 3D flow field segmentation and classification
May 10, 2023
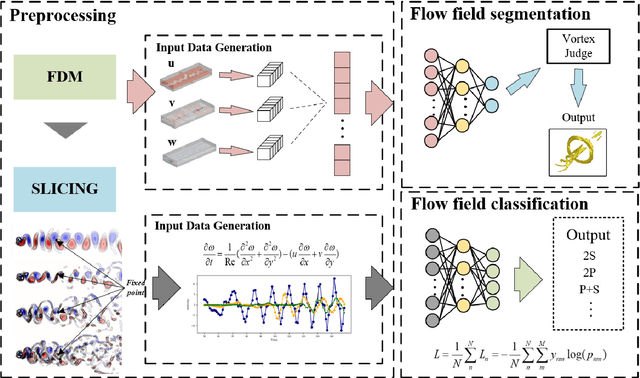
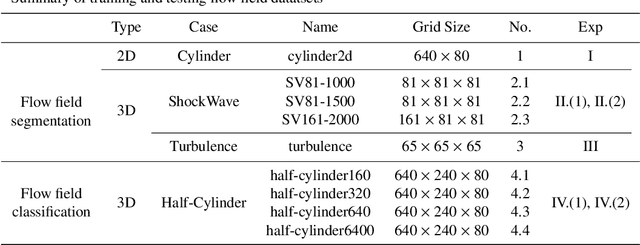
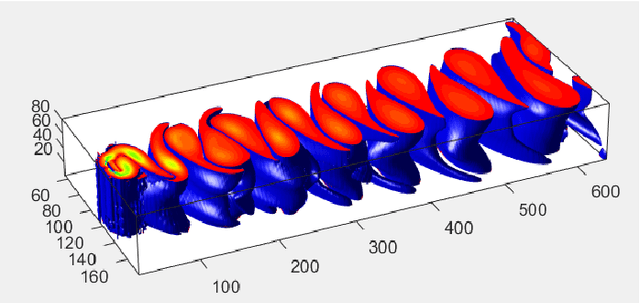
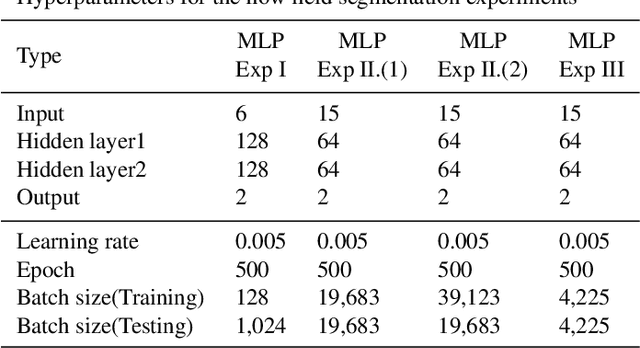
Flow field segmentation and classification help researchers to understand vortex structure and thus turbulent flow. Existing deep learning methods mainly based on global information and focused on 2D circumstance. Based on flow field theory, we propose novel flow field segmentation and classification deep learning methods in three-dimensional space. We construct segmentation criterion based on local velocity information and classification criterion based on the relationship between local vorticity and vortex wake, to identify vortex structure in 3D flow field, and further classify the type of vortex wakes accurately and rapidly. Simulation experiment results showed that, compared with existing methods, our segmentation method can identify the vortex area more accurately, while the time consumption is reduced more than 50\%; our classification method can reduce the time consumption by more than 90\% while maintaining the same classification accuracy level.
SPAC-Net: Synthetic Pose-aware Animal ControlNet for Enhanced Pose Estimation
May 31, 2023

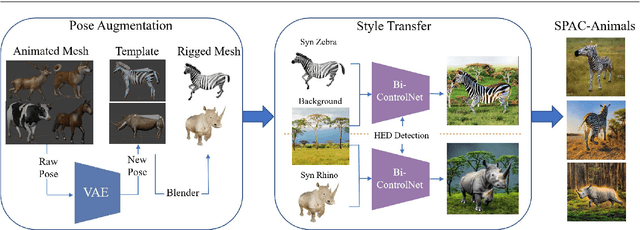
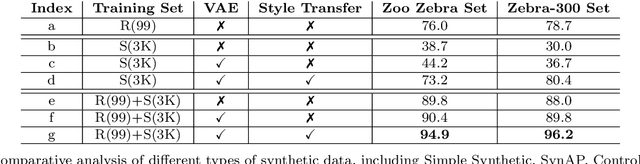
Animal pose estimation has become a crucial area of research, but the scarcity of annotated data is a significant challenge in developing accurate models. Synthetic data has emerged as a promising alternative, but it frequently exhibits domain discrepancies with real data. Style transfer algorithms have been proposed to address this issue, but they suffer from insufficient spatial correspondence, leading to the loss of label information. In this work, we present a new approach called Synthetic Pose-aware Animal ControlNet (SPAC-Net), which incorporates ControlNet into the previously proposed Prior-Aware Synthetic animal data generation (PASyn) pipeline. We leverage the plausible pose data generated by the Variational Auto-Encoder (VAE)-based data generation pipeline as input for the ControlNet Holistically-nested Edge Detection (HED) boundary task model to generate synthetic data with pose labels that are closer to real data, making it possible to train a high-precision pose estimation network without the need for real data. In addition, we propose the Bi-ControlNet structure to separately detect the HED boundary of animals and backgrounds, improving the precision and stability of the generated data. Using the SPAC-Net pipeline, we generate synthetic zebra and rhino images and test them on the AP10K real dataset, demonstrating superior performance compared to using only real images or synthetic data generated by other methods. Our work demonstrates the potential for synthetic data to overcome the challenge of limited annotated data in animal pose estimation.
Mobile-Env: A Universal Platform for Training and Evaluation of Mobile Interaction
May 14, 2023

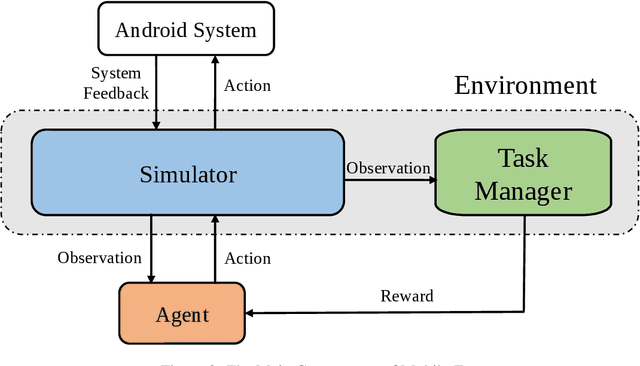
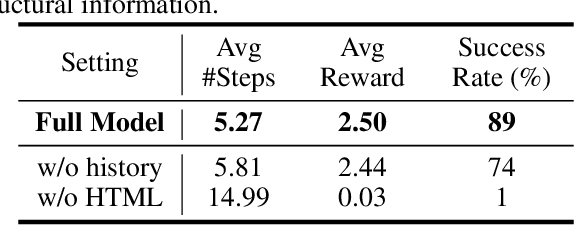
The interaction platform plays a crucial role in the recent advancement of the control and decision domains like game playing and embodied intelligence. However, there is still a lack of a satisfactory platform for the information user interface (InfoUI) interaction. The proposed InfoUI comprises not only the plain text information, but the multimodal contents and a few spatial structures with styles as well. To help the research of InfoUI interaction, a novel platform Mobile-Env is presented in this paper. The Mobile-Env platform is designed to be flexible, adaptable, and easily-extended. Based on Mobile-Env, an InfoUI task set is then built for a demonstration and evaluation. An agent based on the large-scale language model (LLM) is tested on the task set. The experiment results demonstrate the great potential of the LLM to do text understanding and matching and, meanwhile, reveal the necessity of a better mechanism of interaction feedback and exploration. Several new discussions are conducted as well. A demo video is available at https://youtu.be/gKV6KZYwxGY. The code repository is available at https://github.com/X-LANCE/Mobile-Env. The proposed WikiHow task set is made public at https://huggingface.co/datasets/zdy023/WikiHow-taskset.
DiffBlender: Scalable and Composable Multimodal Text-to-Image Diffusion Models
May 24, 2023

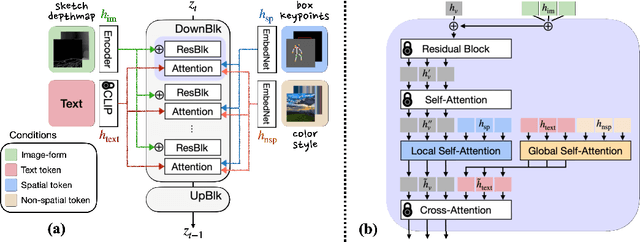
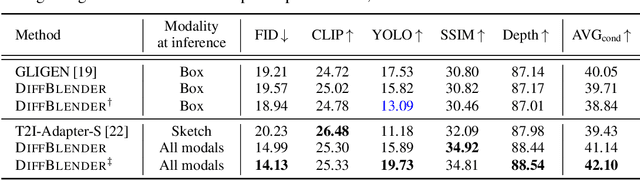
The recent progress in diffusion-based text-to-image generation models has significantly expanded generative capabilities via conditioning the text descriptions. However, since relying solely on text prompts is still restrictive for fine-grained customization, we aim to extend the boundaries of conditional generation to incorporate diverse types of modalities, e.g., sketch, box, and style embedding, simultaneously. We thus design a multimodal text-to-image diffusion model, coined as DiffBlender, that achieves the aforementioned goal in a single model by training only a few small hypernetworks. DiffBlender facilitates a convenient scaling of input modalities, without altering the parameters of an existing large-scale generative model to retain its well-established knowledge. Furthermore, our study sets new standards for multimodal generation by conducting quantitative and qualitative comparisons with existing approaches. By diversifying the channels of conditioning modalities, DiffBlender faithfully reflects the provided information or, in its absence, creates imaginative generation.
Unsupervised Semantic Correspondence Using Stable Diffusion
May 24, 2023
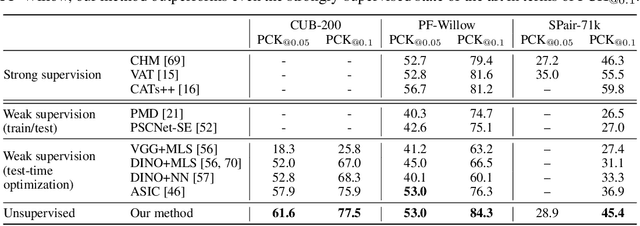

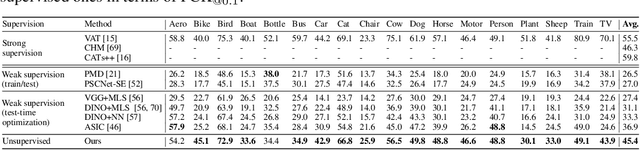
Text-to-image diffusion models are now capable of generating images that are often indistinguishable from real images. To generate such images, these models must understand the semantics of the objects they are asked to generate. In this work we show that, without any training, one can leverage this semantic knowledge within diffusion models to find semantic correspondences -- locations in multiple images that have the same semantic meaning. Specifically, given an image, we optimize the prompt embeddings of these models for maximum attention on the regions of interest. These optimized embeddings capture semantic information about the location, which can then be transferred to another image. By doing so we obtain results on par with the strongly supervised state of the art on the PF-Willow dataset and significantly outperform (20.9% relative for the SPair-71k dataset) any existing weakly or unsupervised method on PF-Willow, CUB-200 and SPair-71k datasets.
Think Before You Act: Decision Transformers with Internal Working Memory
May 24, 2023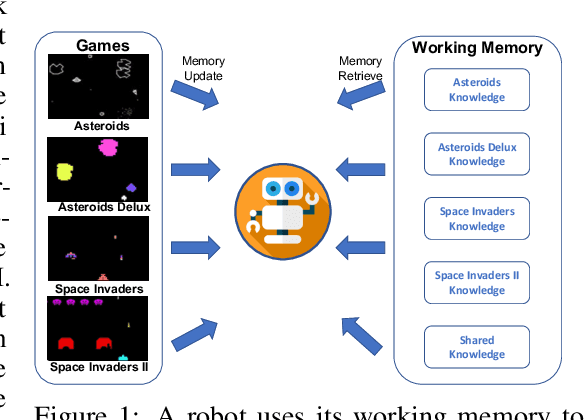
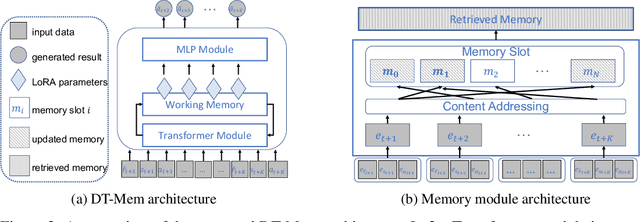

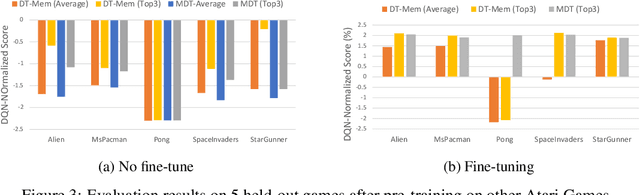
Large language model (LLM)-based decision-making agents have shown the ability to generalize across multiple tasks. However, their performance relies on massive data and compute. We argue that this inefficiency stems from the forgetting phenomenon, in which a model memorizes its behaviors in parameters throughout training. As a result, training on a new task may deteriorate the model's performance on previous tasks. In contrast to LLMs' implicit memory mechanism, the human brain utilizes distributed memory storage, which helps manage and organize multiple skills efficiently, mitigating the forgetting phenomenon. Thus inspired, we propose an internal working memory module to store, blend, and retrieve information for different downstream tasks. Evaluation results show that the proposed method improves training efficiency and generalization in both Atari games and meta-world object manipulation tasks. Moreover, we demonstrate that memory fine-tuning further enhances the adaptability of the proposed architecture.
Towards Foundation Models for Relational Databases [Vision Paper]
May 24, 2023![Figure 1 for Towards Foundation Models for Relational Databases [Vision Paper]](/_next/image?url=https%3A%2F%2Fd3i71xaburhd42.cloudfront.net%2Fe3154ffced7e2279f42b6a13c00f621f6d41c213%2F2-Figure1-1.png&w=640&q=75)
![Figure 2 for Towards Foundation Models for Relational Databases [Vision Paper]](/_next/image?url=https%3A%2F%2Fd3i71xaburhd42.cloudfront.net%2Fe3154ffced7e2279f42b6a13c00f621f6d41c213%2F4-Table1-1.png&w=640&q=75)
Tabular representation learning has recently gained a lot of attention. However, existing approaches only learn a representation from a single table, and thus ignore the potential to learn from the full structure of relational databases, including neighboring tables that can contain important information for a contextualized representation. Moreover, current models are significantly limited in scale, which prevents that they learn from large databases. In this paper, we thus introduce our vision of relational representation learning, that can not only learn from the full relational structure, but also can scale to larger database sizes that are commonly found in real-world. Moreover, we also discuss opportunities and challenges we see along the way to enable this vision and present initial very promising results. Overall, we argue that this direction can lead to foundation models for relational databases that are today only available for text and images.
On the road to more accurate mobile cellular traffic predictions
May 24, 2023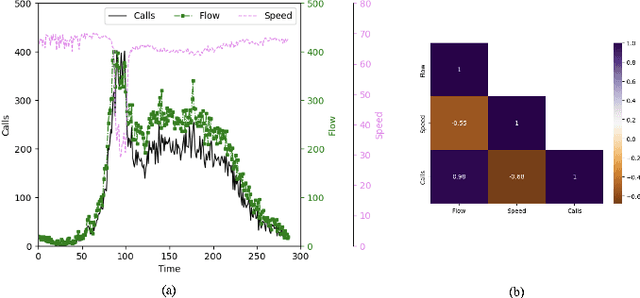
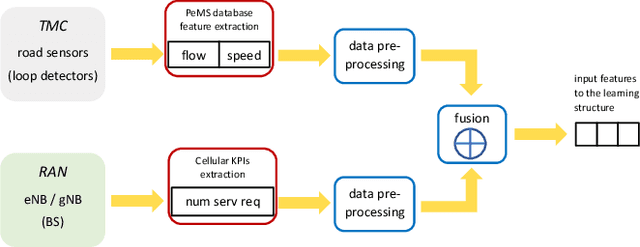
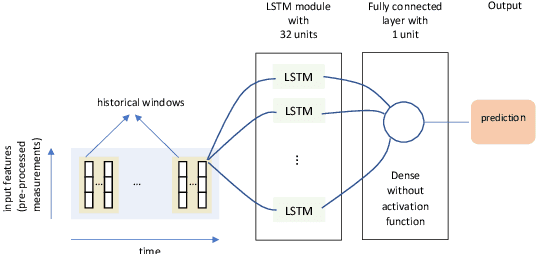
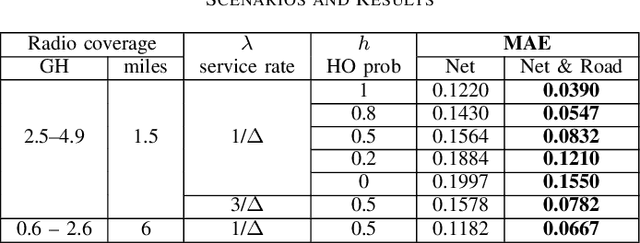
The main contribution reported in the paper is a novel paradigm through which mobile cellular traffic forecasting is made substantially more accurate. Specifically, by incorporating freely available road metrics we characterise the data generation process and spatial dependencies. Therefore, this provides a means for improving the forecasting estimates. We employ highway flow and average speed variables together with a cellular network traffic metric in a light learning structure to predict the short-term future load on a cell covering a segment of a highway. This is in sharp contrast to prior art that mainly studies urban scenarios (with pedestrian and limited vehicular speeds) and develops machine learning approaches that use exclusively network metrics and meta information to make mid-term and long-term predictions. The learning structure can be used at a cell or edge level, and can find application in both federated and centralised learning.
AMELI: Enhancing Multimodal Entity Linking with Fine-Grained Attributes
May 24, 2023
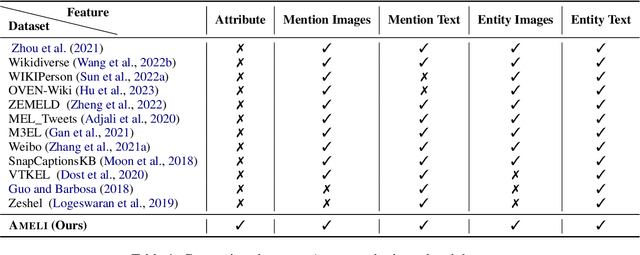

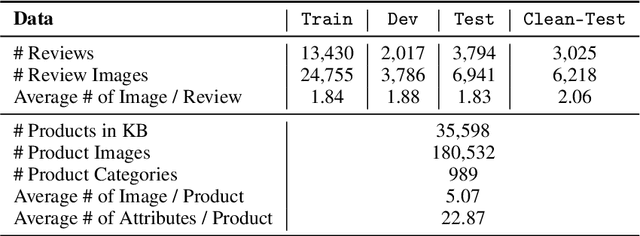
We propose attribute-aware multimodal entity linking, where the input is a mention described with a text and image, and the goal is to predict the corresponding target entity from a multimodal knowledge base (KB) where each entity is also described with a text description, a visual image and a set of attributes and values. To support this research, we construct AMELI, a large-scale dataset consisting of 18,472 reviews and 35,598 products. To establish baseline performance on AMELI, we experiment with the current state-of-the-art multimodal entity linking approaches and our enhanced attribute-aware model and demonstrate the importance of incorporating the attribute information into the entity linking process. To be best of our knowledge, we are the first to build benchmark dataset and solutions for the attribute-aware multimodal entity linking task. Datasets and codes will be made publicly available.
Measuring and Modeling Physical Intrinsic Motivation
May 24, 2023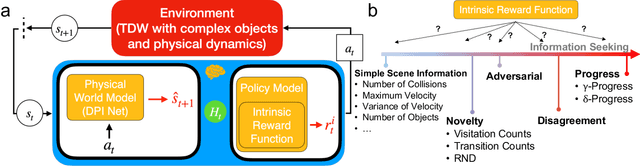
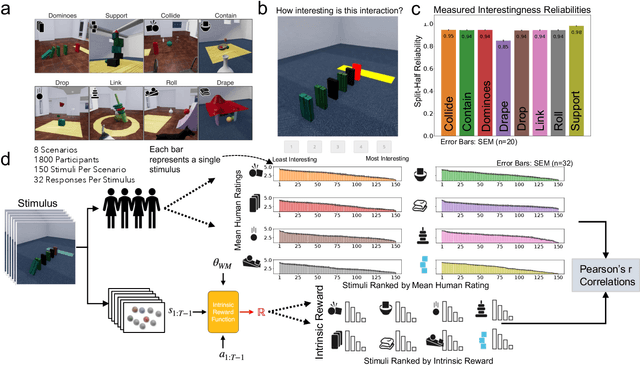
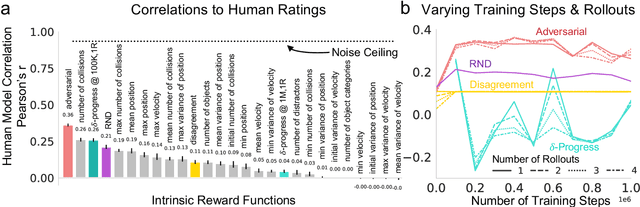
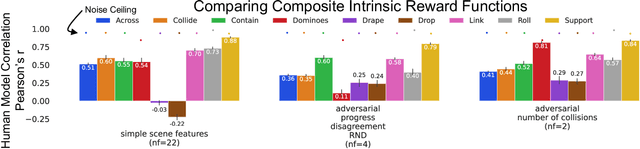
Humans are interactive agents driven to seek out situations with interesting physical dynamics. Here we formalize the functional form of physical intrinsic motivation. We first collect ratings of how interesting humans find a variety of physics scenarios. We then model human interestingness responses by implementing various hypotheses of intrinsic motivation including models that rely on simple scene features to models that depend on forward physics prediction. We find that the single best predictor of human responses is adversarial reward, a model derived from physical prediction loss. We also find that simple scene feature models do not generalize their prediction of human responses across all scenarios. Finally, linearly combining the adversarial model with the number of collisions in a scene leads to the greatest improvement in predictivity of human responses, suggesting humans are driven towards scenarios that result in high information gain and physical activity.