 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Spike timing reshapes robustness against attacks in spiking neural networks
Jun 09, 2023
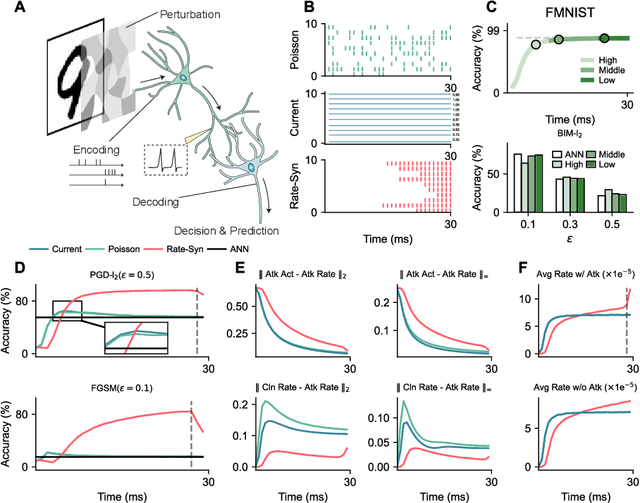
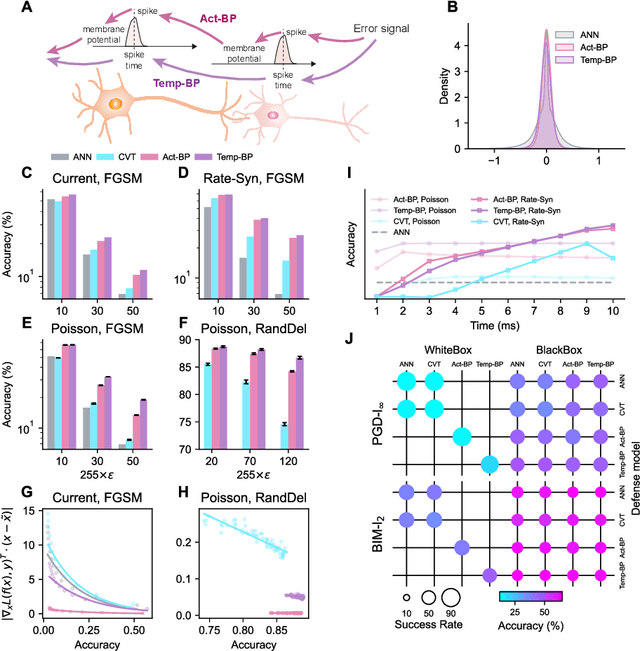
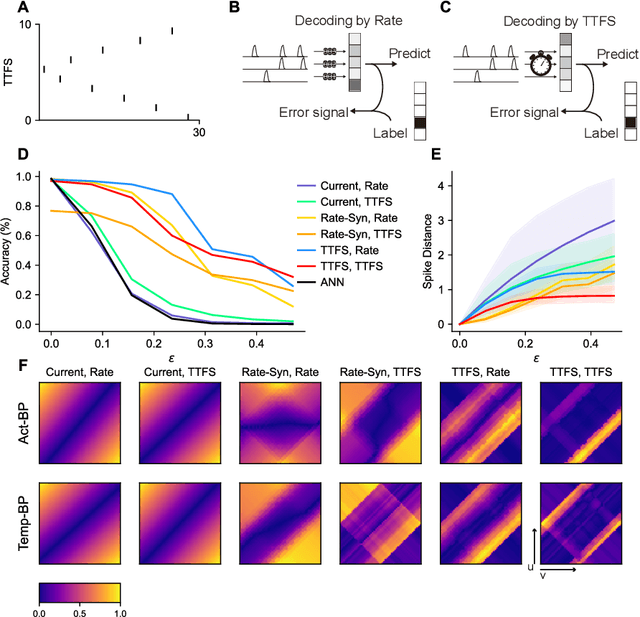
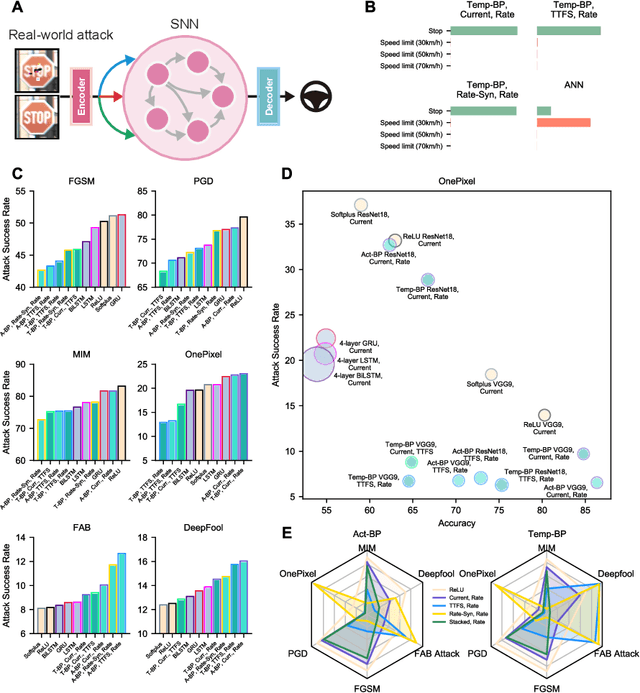
The success of deep learning in the past decade is partially shrouded in the shadow of adversarial attacks. In contrast, the brain is far more robust at complex cognitive tasks. Utilizing the advantage that neurons in the brain communicate via spikes, spiking neural networks (SNNs) are emerging as a new type of neural network model, boosting the frontier of theoretical investigation and empirical application of artificial neural networks and deep learning. Neuroscience research proposes that the precise timing of neural spikes plays an important role in the information coding and sensory processing of the biological brain. However, the role of spike timing in SNNs is less considered and far from understood. Here we systematically explored the timing mechanism of spike coding in SNNs, focusing on the robustness of the system against various types of attacks. We found that SNNs can achieve higher robustness improvement using the coding principle of precise spike timing in neural encoding and decoding, facilitated by different learning rules. Our results suggest that the utility of spike timing coding in SNNs could improve the robustness against attacks, providing a new approach to reliable coding principles for developing next-generation brain-inspired deep learning.
Communication-Efficient Zeroth-Order Distributed Online Optimization: Algorithm, Theory, and Applications
Jun 09, 2023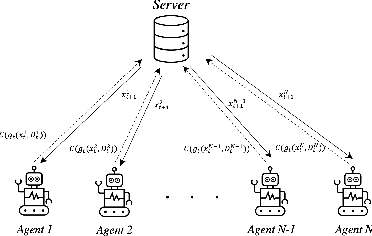
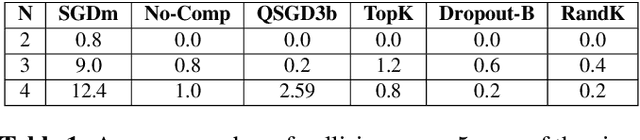
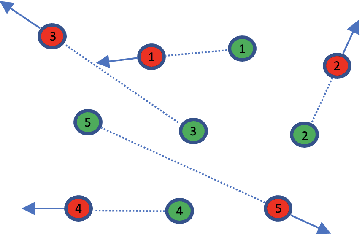
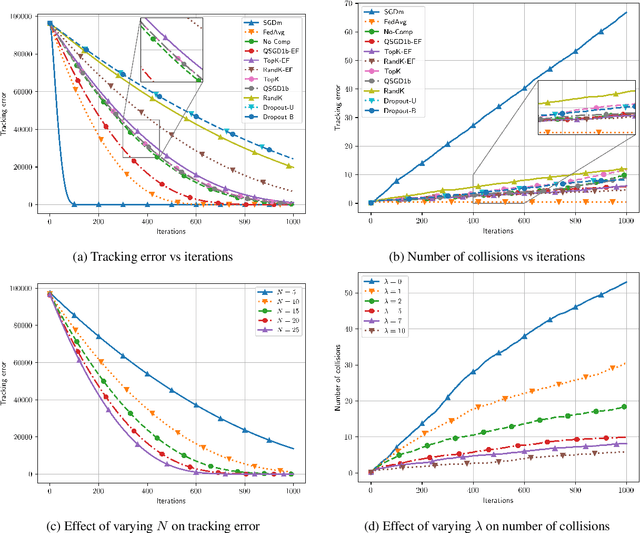
This paper focuses on a multi-agent zeroth-order online optimization problem in a federated learning setting for target tracking. The agents only sense their current distances to their targets and aim to maintain a minimum safe distance from each other to prevent collisions. The coordination among the agents and dissemination of collision-prevention information is managed by a central server using the federated learning paradigm. The proposed formulation leads to an instance of distributed online nonconvex optimization problem that is solved via a group of communication-constrained agents. To deal with the communication limitations of the agents, an error feedback-based compression scheme is utilized for agent-to-server communication. The proposed algorithm is analyzed theoretically for the general class of distributed online nonconvex optimization problems. We provide non-asymptotic convergence rates that show the dominant term is independent of the characteristics of the compression scheme. Our theoretical results feature a new approach that employs significantly more relaxed assumptions in comparison to standard literature. The performance of the proposed solution is further analyzed numerically in terms of tracking errors and collisions between agents in two relevant applications.
Distributed Consensus Algorithm for Decision-Making in Multi-agent Multi-armed Bandit
Jun 09, 2023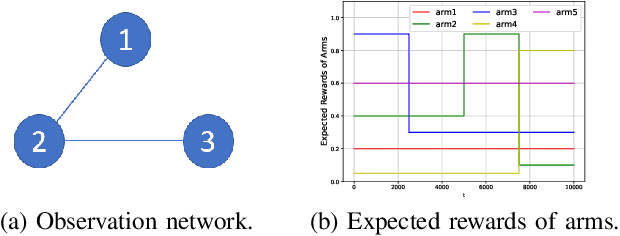
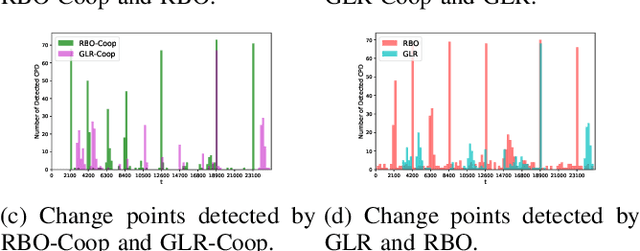
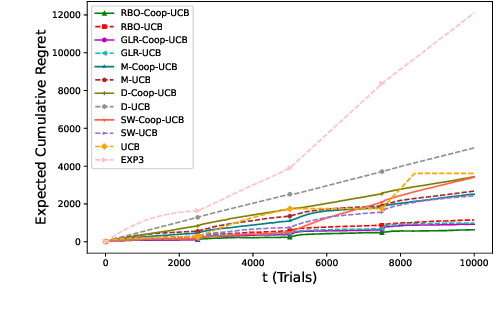
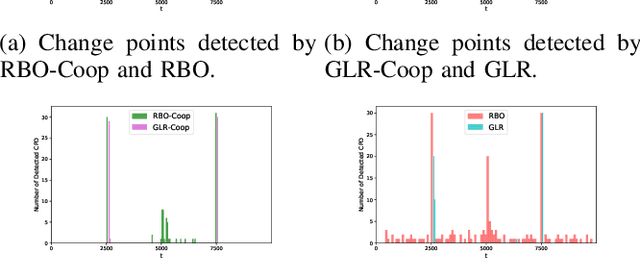
We study a structured multi-agent multi-armed bandit (MAMAB) problem in a dynamic environment. A graph reflects the information-sharing structure among agents, and the arms' reward distributions are piecewise-stationary with several unknown change points. The agents face the identical piecewise-stationary MAB problem. The goal is to develop a decision-making policy for the agents that minimizes the regret, which is the expected total loss of not playing the optimal arm at each time step. Our proposed solution, Restarted Bayesian Online Change Point Detection in Cooperative Upper Confidence Bound Algorithm (RBO-Coop-UCB), involves an efficient multi-agent UCB algorithm as its core enhanced with a Bayesian change point detector. We also develop a simple restart decision cooperation that improves decision-making. Theoretically, we establish that the expected group regret of RBO-Coop-UCB is upper bounded by $\mathcal{O}(KNM\log T + K\sqrt{MT\log T})$, where K is the number of agents, M is the number of arms, and T is the number of time steps. Numerical experiments on synthetic and real-world datasets demonstrate that our proposed method outperforms the state-of-the-art algorithms.
Data Augmentation for Seizure Prediction with Generative Diffusion Model
Jun 14, 2023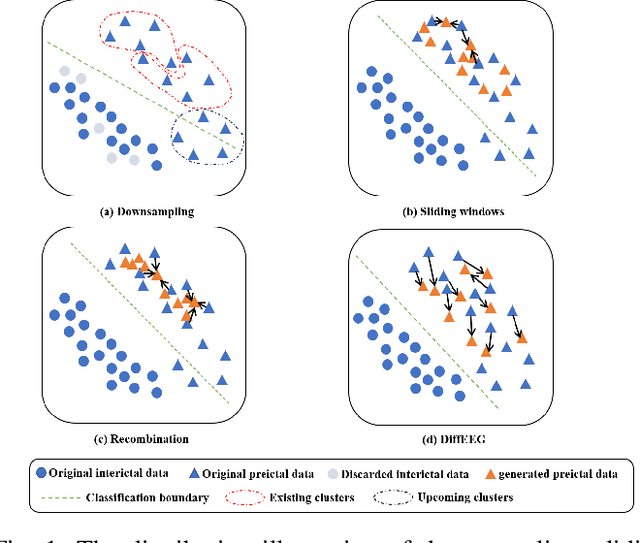
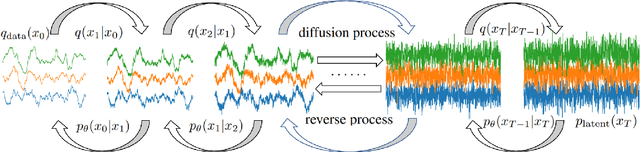
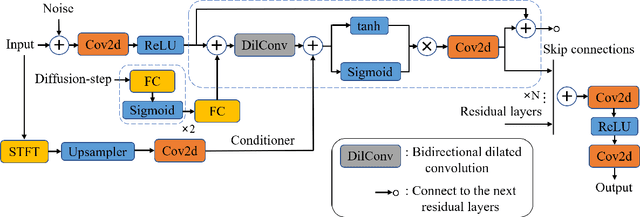
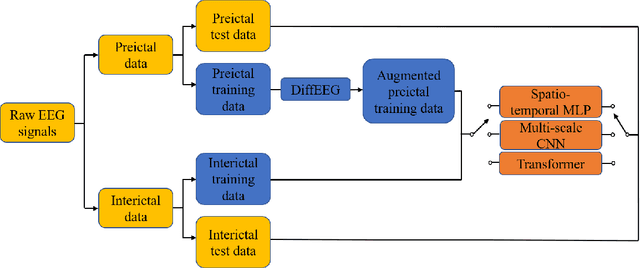
Objective: Seizure prediction is of great importance to improve the life of patients. The focal point is to distinguish preictal states from interictal ones. With the development of machine learning, seizure prediction methods have achieved significant progress. However, the severe imbalance problem between preictal and interictal data still poses a great challenge, restricting the performance of classifiers. Data augmentation is an intuitive way to solve this problem. Existing data augmentation methods generate samples by overlapping or recombining data. The distribution of generated samples is limited by original data, because such transformations cannot fully explore the feature space and offer new information. As the epileptic EEG representation varies among seizures, these generated samples cannot provide enough diversity to achieve high performance on a new seizure. As a consequence, we propose a novel data augmentation method with diffusion model called DiffEEG. Methods: Diffusion models are a class of generative models that consist of two processes. Specifically, in the diffusion process, the model adds noise to the input EEG sample step by step and converts the noisy sample into output random noise, exploring the distribution of data by minimizing the loss between the output and the noise added. In the denoised process, the model samples the synthetic data by removing the noise gradually, diffusing the data distribution to outward areas and narrowing the distance between different clusters. Results: We compared DiffEEG with existing methods, and integrated them into three representative classifiers. The experiments indicate that DiffEEG could further improve the performance and shows superiority to existing methods. Conclusion: This paper proposes a novel and effective method to solve the imbalanced problem and demonstrates the effectiveness and generality of our method.
Input-Aware Dynamic Timestep Spiking Neural Networks for Efficient In-Memory Computing
May 27, 2023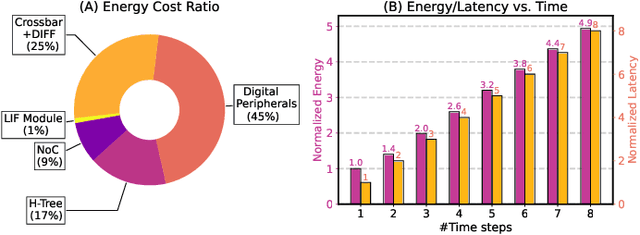
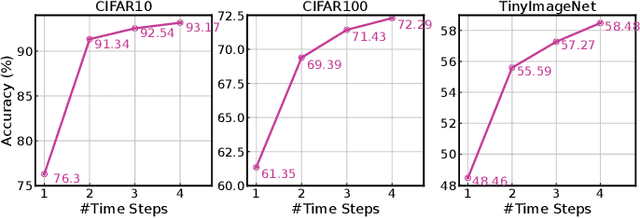
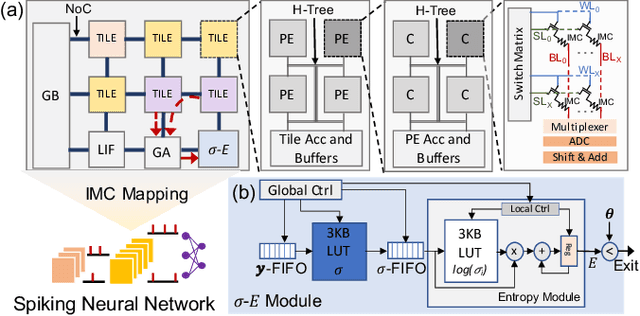
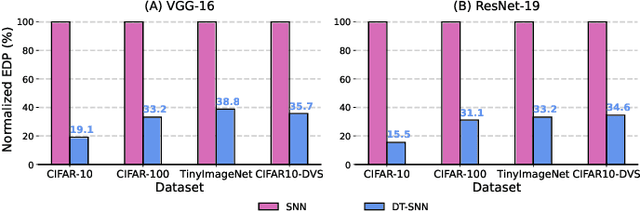
Spiking Neural Networks (SNNs) have recently attracted widespread research interest as an efficient alternative to traditional Artificial Neural Networks (ANNs) because of their capability to process sparse and binary spike information and avoid expensive multiplication operations. Although the efficiency of SNNs can be realized on the In-Memory Computing (IMC) architecture, we show that the energy cost and latency of SNNs scale linearly with the number of timesteps used on IMC hardware. Therefore, in order to maximize the efficiency of SNNs, we propose input-aware Dynamic Timestep SNN (DT-SNN), a novel algorithmic solution to dynamically determine the number of timesteps during inference on an input-dependent basis. By calculating the entropy of the accumulated output after each timestep, we can compare it to a predefined threshold and decide if the information processed at the current timestep is sufficient for a confident prediction. We deploy DT-SNN on an IMC architecture and show that it incurs negligible computational overhead. We demonstrate that our method only uses 1.46 average timesteps to achieve the accuracy of a 4-timestep static SNN while reducing the energy-delay-product by 80%.
CCDWT-GAN: Generative Adversarial Networks Based on Color Channel Using Discrete Wavelet Transform for Document Image Binarization
May 27, 2023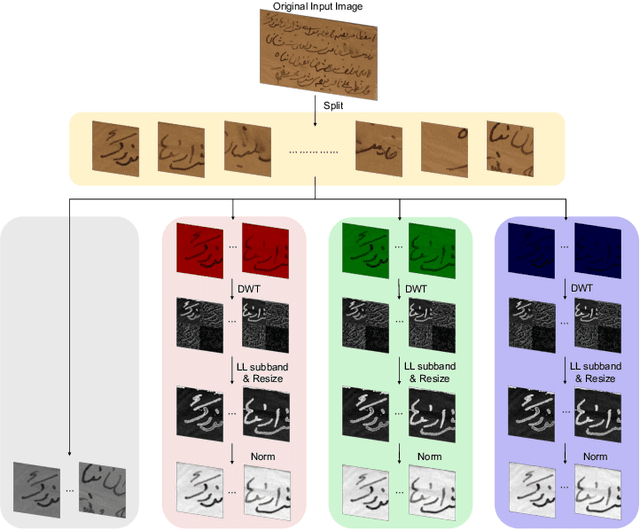
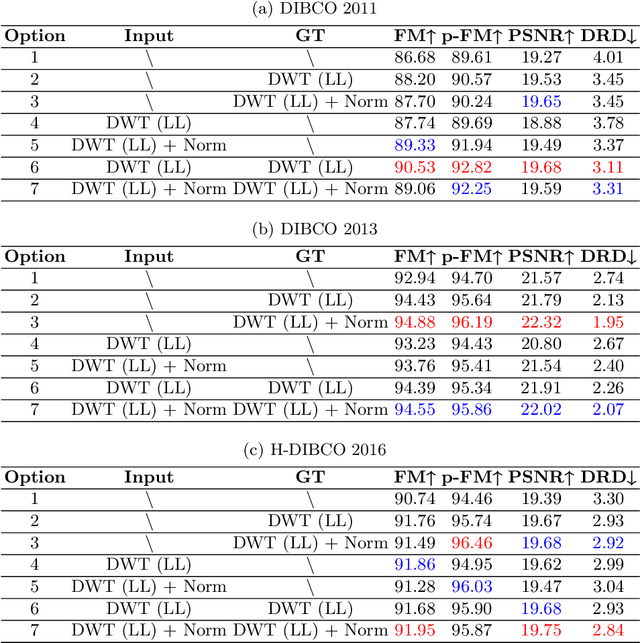
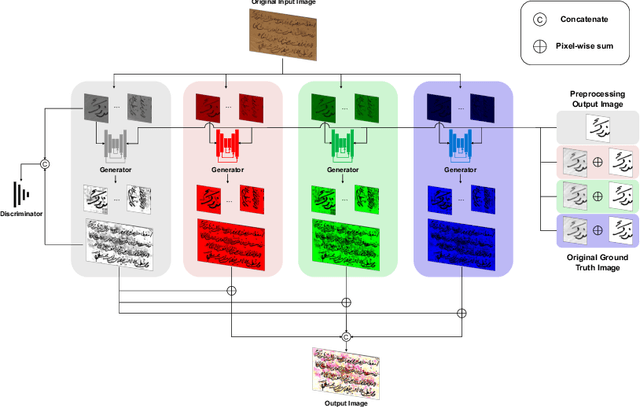
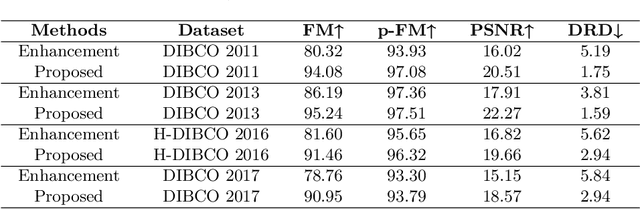
To efficiently extract the textual information from color degraded document images is an important research topic. Long-term imperfect preservation of ancient documents has led to various types of degradation such as page staining, paper yellowing, and ink bleeding; these degradations badly impact the image processing for information extraction. In this paper, we present CCDWT-GAN, a generative adversarial network (GAN) that utilizes the discrete wavelet transform (DWT) on RGB (red, green, blue) channel splited images. The proposed method comprises three stages: image preprocessing, image enhancement, and image binarization. This work conducts comparative experiments in the image preprocessing stage to determine the optimal selection of DWT with normalization. Additionally, we perform an ablation study on the results of the image enhancement stage and the image binarization stage to validate their positive effect on the model performance. This work compares the performance of the proposed method with other state-of-the-art (SOTA) methods on DIBCO and H-DIBCO ((Handwritten) Document Image Binarization Competition) datasets. The experimental results demonstrate that CCDWT-GAN achieves a top two performance on multiple benchmark datasets, and outperforms other SOTA methods.
EXACT: Extensive Attack for Split Learning
May 22, 2023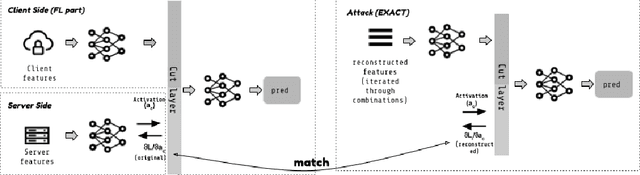

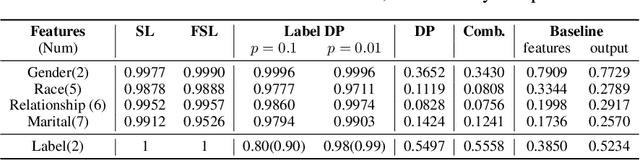
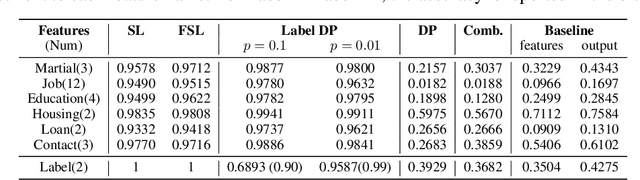
Privacy-Preserving machine learning (PPML) can help us train and deploy models that utilize private information. In particular, on-device Machine Learning allows us to completely avoid sharing information with a third-party server during inference. However, on-device models are typically less accurate when compared to the server counterparts due to the fact that (1) they typically only rely on a small set of on-device features and (2) they need to be small enough to run efficiently on end-user devices. Split Learning (SL) is a promising approach that can overcome these limitations. In SL, a large machine learning model is divided into two parts, with the bigger part residing on the server-side and a smaller part executing on-device, aiming to incorporate the private features. However, end-to-end training of such models requires exchanging gradients at the cut layer, which might encode private features or labels. In this paper, we provide insights into potential privacy risks associated with SL and introduce a novel attack method, EXACT, to reconstruct private information. Furthermore, we also investigate the effectiveness of various mitigation strategies. Our results indicate that the gradients significantly improve the attacker's effectiveness in all three datasets reaching almost 100% reconstruction accuracy for some features. However, a small amount of differential privacy (DP) is quite effective in mitigating this risk without causing significant training degradation.
Logical Entity Representation in Knowledge-Graphs for Differentiable Rule Learning
May 22, 2023
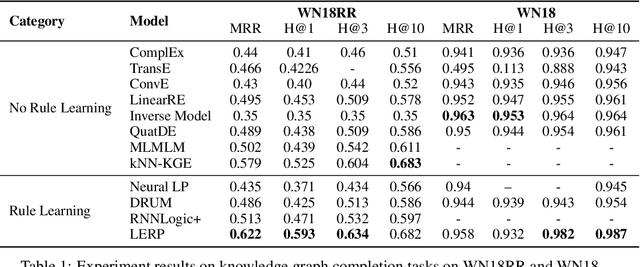
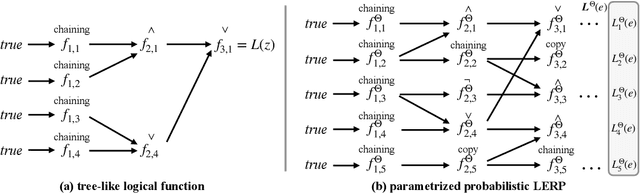
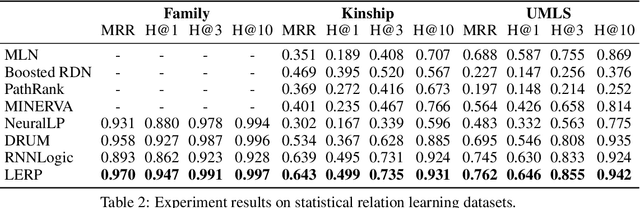
Probabilistic logical rule learning has shown great strength in logical rule mining and knowledge graph completion. It learns logical rules to predict missing edges by reasoning on existing edges in the knowledge graph. However, previous efforts have largely been limited to only modeling chain-like Horn clauses such as $R_1(x,z)\land R_2(z,y)\Rightarrow H(x,y)$. This formulation overlooks additional contextual information from neighboring sub-graphs of entity variables $x$, $y$ and $z$. Intuitively, there is a large gap here, as local sub-graphs have been found to provide important information for knowledge graph completion. Inspired by these observations, we propose Logical Entity RePresentation (LERP) to encode contextual information of entities in the knowledge graph. A LERP is designed as a vector of probabilistic logical functions on the entity's neighboring sub-graph. It is an interpretable representation while allowing for differentiable optimization. We can then incorporate LERP into probabilistic logical rule learning to learn more expressive rules. Empirical results demonstrate that with LERP, our model outperforms other rule learning methods in knowledge graph completion and is comparable or even superior to state-of-the-art black-box methods. Moreover, we find that our model can discover a more expressive family of logical rules. LERP can also be further combined with embedding learning methods like TransE to make it more interpretable.
TART: A plug-and-play Transformer module for task-agnostic reasoning
Jun 13, 2023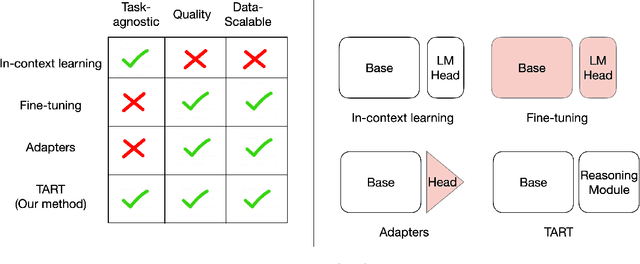

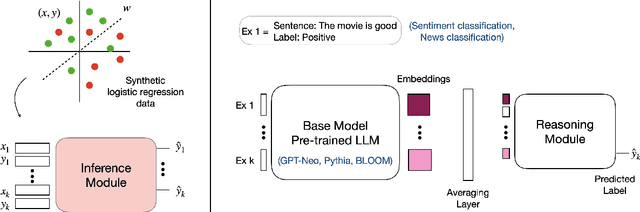
Large language models (LLMs) exhibit in-context learning abilities which enable the same model to perform several tasks without any task-specific training. In contrast, traditional adaptation approaches, such as fine-tuning, modify the underlying models for each specific task. In-context learning, however, consistently underperforms task-specific tuning approaches even when presented with the same examples. While most existing approaches (e.g., prompt engineering) focus on the LLM's learned representations to patch this performance gap, our analysis actually reveal that LLM representations contain sufficient information to make good predictions. As such, we focus on the LLM's reasoning abilities and demonstrate that this performance gap exists due to their inability to perform simple probabilistic reasoning tasks. This raises an intriguing question: Are LLMs actually capable of learning how to reason in a task-agnostic manner? We answer this in the affirmative and propose TART which generically improves an LLM's reasoning abilities using a synthetically trained Transformer-based reasoning module. TART trains this reasoning module in a task-agnostic manner using only synthetic logistic regression tasks and composes it with an arbitrary real-world pre-trained model without any additional training. With a single inference module, TART improves performance across different model families (GPT-Neo, Pythia, BLOOM), model sizes (100M - 6B), tasks (14 NLP binary classification tasks), and even across different modalities (audio and vision). Additionally, on the RAFT Benchmark, TART improves GPT-Neo (125M)'s performance such that it outperforms BLOOM (176B), and is within 4% of GPT-3 (175B). Our code and models are available at https://github.com/HazyResearch/TART .
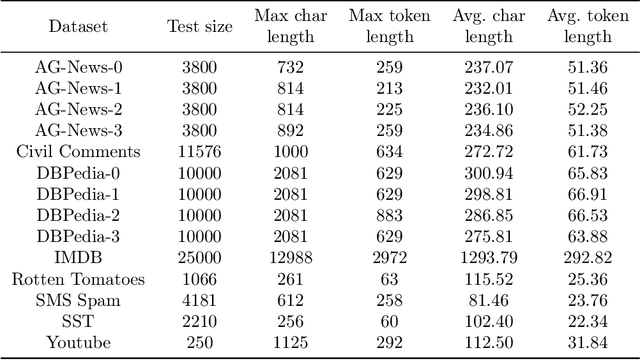
A Novel Driver Distraction Behavior Detection Based on Self-Supervised Learning Framework with Masked Image Modeling
Jun 13, 2023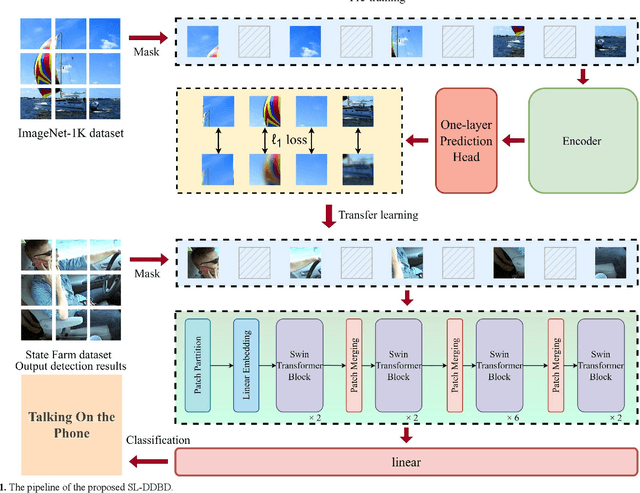
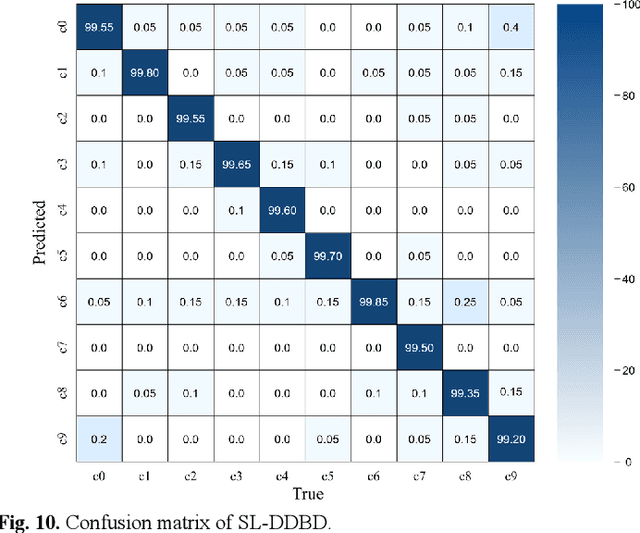
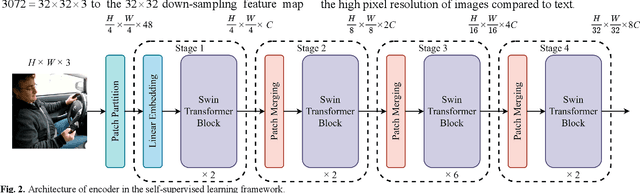
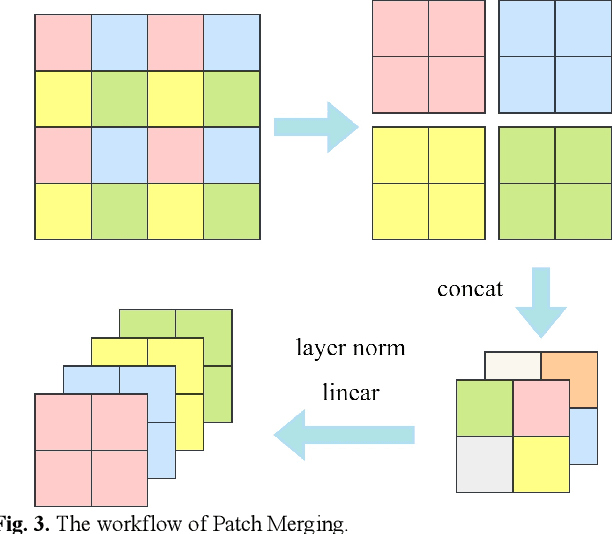
Driver distraction causes a significant number of traffic accidents every year, resulting in economic losses and casualties. Currently, the level of automation in commercial vehicles is far from completely unmanned, and drivers still play an important role in operating and controlling the vehicle. Therefore, driver distraction behavior detection is crucial for road safety. At present, driver distraction detection primarily relies on traditional Convolutional Neural Networks (CNN) and supervised learning methods. However, there are still challenges such as the high cost of labeled datasets, limited ability to capture high-level semantic information, and weak generalization performance. In order to solve these problems, this paper proposes a new self-supervised learning method based on masked image modeling for driver distraction behavior detection. Firstly, a self-supervised learning framework for masked image modeling (MIM) is introduced to solve the serious human and material consumption issues caused by dataset labeling. Secondly, the Swin Transformer is employed as an encoder. Performance is enhanced by reconfiguring the Swin Transformer block and adjusting the distribution of the number of window multi-head self-attention (W-MSA) and shifted window multi-head self-attention (SW-MSA) detection heads across all stages, which leads to model more lightening. Finally, various data augmentation strategies are used along with the best random masking strategy to strengthen the model's recognition and generalization ability. Test results on a large-scale driver distraction behavior dataset show that the self-supervised learning method proposed in this paper achieves an accuracy of 99.60%, approximating the excellent performance of advanced supervised learning methods.