 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Output-Constrained Lossy Source Coding With Application to Rate-Distortion-Perception Theory
Mar 21, 2024
The distortion-rate function of output-constrained lossy source coding with limited common randomness is analyzed for the special case of squared error distortion measure. An explicit expression is obtained when both source and reconstruction distributions are Gaussian. This further leads to a partial characterization of the information-theoretic limit of quadratic Gaussian rate-distortion-perception coding with the perception measure given by Kullback-Leibler divergence or squared quadratic Wasserstein distance.
Theoretical Unification of the Fractured Aspects of Information
Feb 26, 2024The article has as its main objective the identification of fundamental epistemological obstacles in the study of information related to unnecessary methodological assumptions and the demystification of popular beliefs in the fundamental divisions of the aspects of information that can be understood as Bachelardian rupture of epistemological obstacles. These general considerations are preceded by an overview of the motivations for the study of information and the role of the concept of information in the conceptualization of intelligence, complexity, and consciousness justifying the need for a sufficiently general perspective in the study of information, and are followed at the end of the article by a brief exposition of an example of a possible application in the development of the unified theory of information free from unnecessary divisions and claims of superiority of the existing preferences in methodology. The reference to Gaston Bachelard and his ideas of epistemological obstacles and epistemological ruptures seems highly appropriate for the reflection on the development of information study, in particular in the context of obstacles such as the absence of semantics of information, negligence of its structural analysis, separation of its digital and analog forms, and misguided use of mathematics.
Knowledge-Enhanced Recommendation with User-Centric Subgraph Network
Mar 21, 2024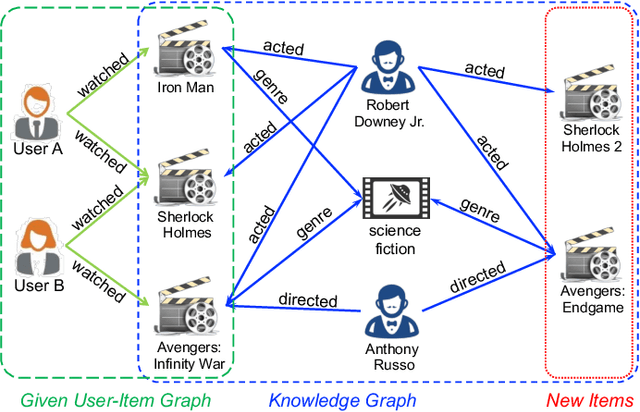
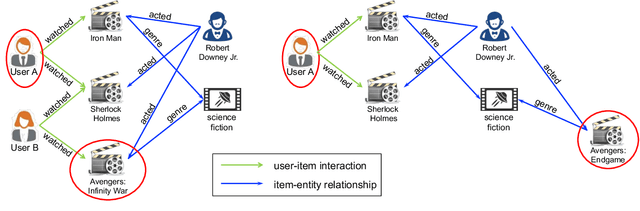
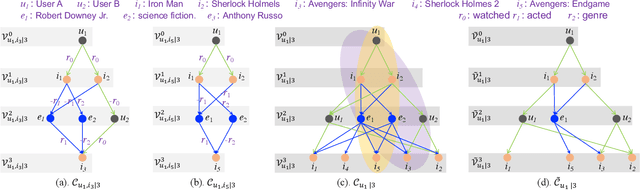
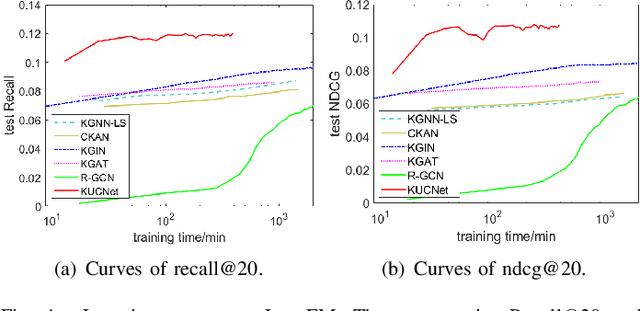
Recommendation systems, as widely implemented nowadays on various platforms, recommend relevant items to users based on their preferences. The classical methods which rely on user-item interaction matrices has limitations, especially in scenarios where there is a lack of interaction data for new items. Knowledge graph (KG)-based recommendation systems have emerged as a promising solution. However, most KG-based methods adopt node embeddings, which do not provide personalized recommendations for different users and cannot generalize well to the new items. To address these limitations, we propose Knowledge-enhanced User-Centric subgraph Network (KUCNet), a subgraph learning approach with graph neural network (GNN) for effective recommendation. KUCNet constructs a U-I subgraph for each user-item pair that captures both the historical information of user-item interactions and the side information provided in KG. An attention-based GNN is designed to encode the U-I subgraphs for recommendation. Considering efficiency, the pruned user-centric computation graph is further introduced such that multiple U-I subgraphs can be simultaneously computed and that the size can be pruned by Personalized PageRank. Our proposed method achieves accurate, efficient, and interpretable recommendations especially for new items. Experimental results demonstrate the superiority of KUCNet over state-of-the-art KG-based and collaborative filtering (CF)-based methods.
Side Information-Driven Session-based Recommendation: A Survey
Feb 27, 2024The session-based recommendation (SBR) garners increasing attention due to its ability to predict anonymous user intents within limited interactions. Emerging efforts incorporate various kinds of side information into their methods for enhancing task performance. In this survey, we thoroughly review the side information-driven session-based recommendation from a data-centric perspective. Our survey commences with an illustration of the motivation and necessity behind this research topic. This is followed by a detailed exploration of various benchmarks rich in side information, pivotal for advancing research in this field. Moreover, we delve into how these diverse types of side information enhance SBR, underscoring their characteristics and utility. A systematic review of research progress is then presented, offering an analysis of the most recent and representative developments within this topic. Finally, we present the future prospects of this vibrant topic.
Emotion Recognition from the perspective of Activity Recognition
Mar 24, 2024Applications of an efficient emotion recognition system can be found in several domains such as medicine, driver fatigue surveillance, social robotics, and human-computer interaction. Appraising human emotional states, behaviors, and reactions displayed in real-world settings can be accomplished using latent continuous dimensions. Continuous dimensional models of human affect, such as those based on valence and arousal are more accurate in describing a broad range of spontaneous everyday emotions than more traditional models of discrete stereotypical emotion categories (e.g. happiness, surprise). Most of the prior work on estimating valence and arousal considers laboratory settings and acted data. But, for emotion recognition systems to be deployed and integrated into real-world mobile and computing devices, we need to consider data collected in the world. Action recognition is a domain of Computer Vision that involves capturing complementary information on appearance from still frames and motion between frames. In this paper, we treat emotion recognition from the perspective of action recognition by exploring the application of deep learning architectures specifically designed for action recognition, for continuous affect recognition. We propose a novel three-stream end-to-end deep learning regression pipeline with an attention mechanism, which is an ensemble design based on sub-modules of multiple state-of-the-art action recognition systems. The pipeline constitutes a novel data pre-processing approach with a spatial self-attention mechanism to extract keyframes. The optical flow of high-attention regions of the face is extracted to capture temporal context. AFEW-VA in-the-wild dataset has been used to conduct comparative experiments. Quantitative analysis shows that the proposed model outperforms multiple standard baselines of both emotion recognition and action recognition models.
Towards Human-Like Machine Comprehension: Few-Shot Relational Learning in Visually-Rich Documents
Mar 23, 2024Key-value relations are prevalent in Visually-Rich Documents (VRDs), often depicted in distinct spatial regions accompanied by specific color and font styles. These non-textual cues serve as important indicators that greatly enhance human comprehension and acquisition of such relation triplets. However, current document AI approaches often fail to consider this valuable prior information related to visual and spatial features, resulting in suboptimal performance, particularly when dealing with limited examples. To address this limitation, our research focuses on few-shot relational learning, specifically targeting the extraction of key-value relation triplets in VRDs. Given the absence of a suitable dataset for this task, we introduce two new few-shot benchmarks built upon existing supervised benchmark datasets. Furthermore, we propose a variational approach that incorporates relational 2D-spatial priors and prototypical rectification techniques. This approach aims to generate relation representations that are more aware of the spatial context and unseen relation in a manner similar to human perception. Experimental results demonstrate the effectiveness of our proposed method by showcasing its ability to outperform existing methods. This study also opens up new possibilities for practical applications.
Gaussian in the Wild: 3D Gaussian Splatting for Unconstrained Image Collections
Mar 23, 2024Novel view synthesis from unconstrained in-the-wild images remains a meaningful but challenging task. The photometric variation and transient occluders in those unconstrained images make it difficult to reconstruct the original scene accurately. Previous approaches tackle the problem by introducing a global appearance feature in Neural Radiance Fields (NeRF). However, in the real world, the unique appearance of each tiny point in a scene is determined by its independent intrinsic material attributes and the varying environmental impacts it receives. Inspired by this fact, we propose Gaussian in the wild (GS-W), a method that uses 3D Gaussian points to reconstruct the scene and introduces separated intrinsic and dynamic appearance feature for each point, capturing the unchanged scene appearance along with dynamic variation like illumination and weather. Additionally, an adaptive sampling strategy is presented to allow each Gaussian point to focus on the local and detailed information more effectively. We also reduce the impact of transient occluders using a 2D visibility map. More experiments have demonstrated better reconstruction quality and details of GS-W compared to previous methods, with a $1000\times$ increase in rendering speed.
Block Orthogonal Sparse Superposition Codes for $ \sf{L}^3 $ Communications: Low Error Rate, Low Latency, and Low Power Consumption
Mar 23, 2024Block orthogonal sparse superposition (BOSS) code is a class of joint coded modulation methods, which can closely achieve the finite-blocklength capacity with a low-complexity decoder at a few coding rates under Gaussian channels. However, for fading channels, the code performance degrades considerably because coded symbols experience different channel fading effects. In this paper, we put forth novel joint demodulation and decoding methods for BOSS codes under fading channels. For a fast fading channel, we present a minimum mean square error approximate maximum a posteriori (MMSE-A-MAP) algorithm for the joint demodulation and decoding when channel state information is available at the receiver (CSIR). We also propose a joint demodulation and decoding method without using CSIR for a block fading channel scenario. We refer to this as the non-coherent sphere decoding (NSD) algorithm. Simulation results demonstrate that BOSS codes with MMSE-A-MAP decoding outperform CRC-aided polar codes, while NSD decoding achieves comparable performance to quasi-maximum likelihood decoding with significantly reduced complexity. Both decoding algorithms are suitable for parallelization, satisfying low-latency constraints. Additionally, real-time simulations on a software-defined radio testbed validate the feasibility of using BOSS codes for low-power transmission.
S2LIC: Learned Image Compression with the SwinV2 Block, Adaptive Channel-wise and Global-inter Attention Context
Mar 21, 2024
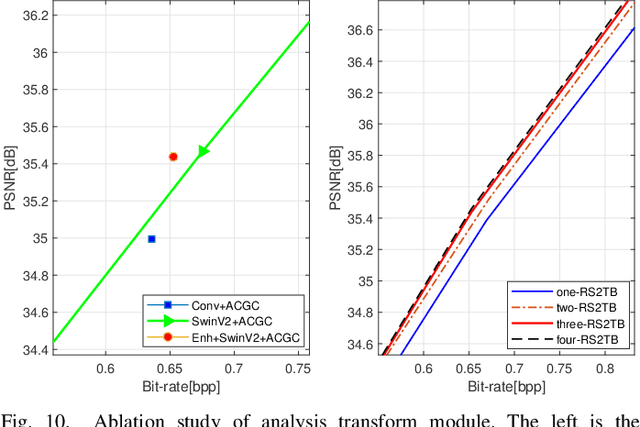


Recently, deep learning technology has been successfully applied in the field of image compression, leading to superior rate-distortion performance. It is crucial to design an effective and efficient entropy model to estimate the probability distribution of the latent representation. However, the majority of entropy models primarily focus on one-dimensional correlation processing between channel and spatial information. In this paper, we propose an Adaptive Channel-wise and Global-inter attention Context (ACGC) entropy model, which can efficiently achieve dual feature aggregation in both inter-slice and intraslice contexts. Specifically, we divide the latent representation into different slices and then apply the ACGC model in a parallel checkerboard context to achieve faster decoding speed and higher rate-distortion performance. In order to capture redundant global features across different slices, we utilize deformable attention in adaptive global-inter attention to dynamically refine the attention weights based on the actual spatial relationships and context. Furthermore, in the main transformation structure, we propose a high-performance S2LIC model. We introduce the residual SwinV2 Transformer model to capture global feature information and utilize a dense block network as the feature enhancement module to improve the nonlinear representation of the image within the transformation structure. Experimental results demonstrate that our method achieves faster encoding and decoding speeds and outperforms VTM-17.1 and some recent learned image compression methods in both PSNR and MS-SSIM metrics.
Less but Better: Enabling Generalized Zero-shot Learning Towards Unseen Domains by Intrinsic Learning from Redundant LLM Semantics
Mar 21, 2024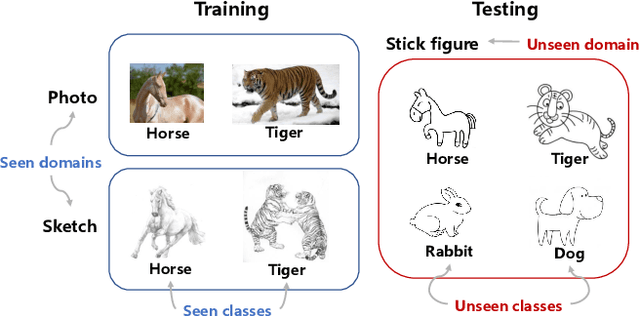
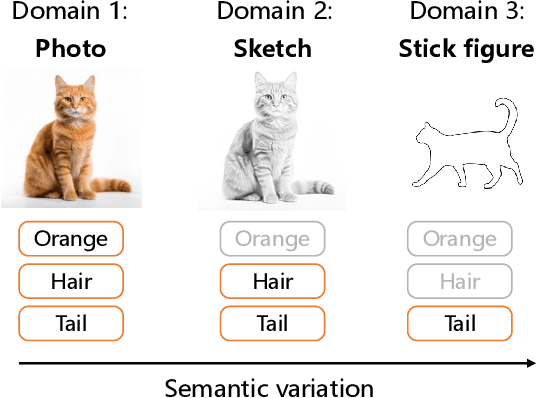
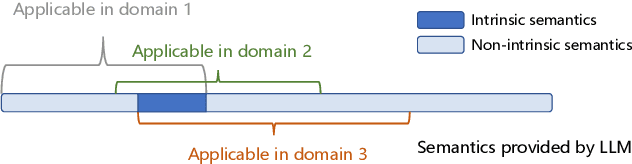
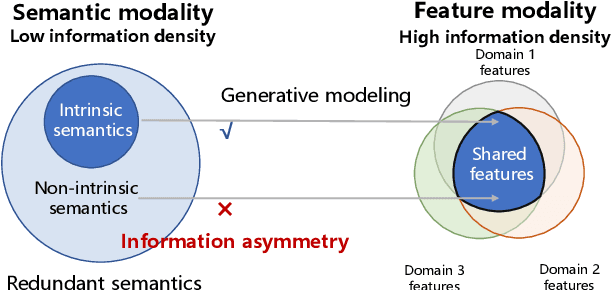
Generalized zero-shot learning (GZSL) focuses on recognizing seen and unseen classes against domain shift problem (DSP) where data of unseen classes may be misclassified as seen classes. However, existing GZSL is still limited to seen domains. In the current work, we pioneer cross-domain GZSL (CDGZSL) which addresses GZSL towards unseen domains. Different from existing GZSL methods which alleviate DSP by generating features of unseen classes with semantics, CDGZSL needs to construct a common feature space across domains and acquire the corresponding intrinsic semantics shared among domains to transfer from seen to unseen domains. Considering the information asymmetry problem caused by redundant class semantics annotated with large language models (LLMs), we present Meta Domain Alignment Semantic Refinement (MDASR). Technically, MDASR consists of two parts: Inter-class Similarity Alignment (ISA), which eliminates the non-intrinsic semantics not shared across all domains under the guidance of inter-class feature relationships, and Unseen-class Meta Generation (UMG), which preserves intrinsic semantics to maintain connectivity between seen and unseen classes by simulating feature generation. MDASR effectively aligns the redundant semantic space with the common feature space, mitigating the information asymmetry in CDGZSL. The effectiveness of MDASR is demonstrated on the Office-Home and Mini-DomainNet, and we have shared the LLM-based semantics for these datasets as the benchmark.