 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Learning-based sound speed reconstruction and aberration correction in linear-array photoacoustic/ultrasound imaging
Jun 19, 2023
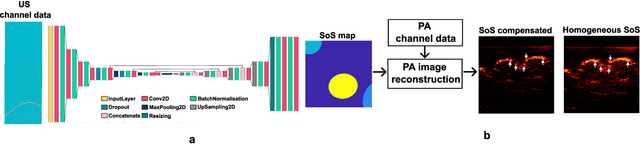
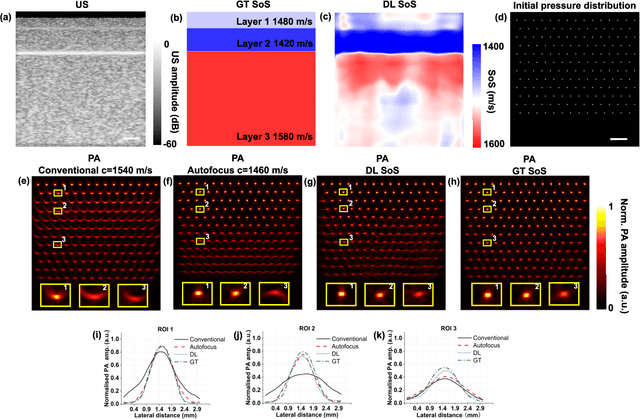
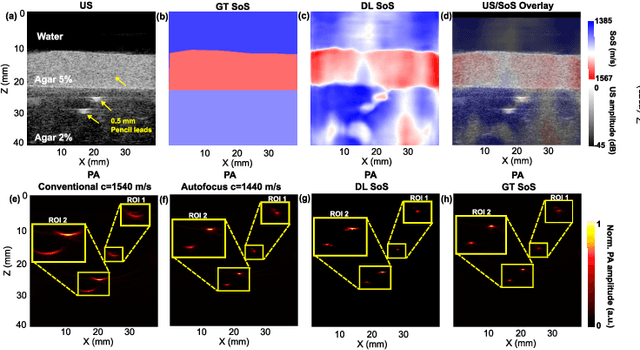
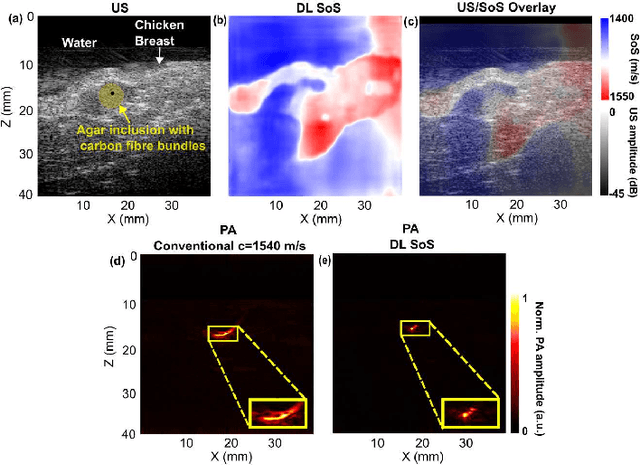
Photoacoustic (PA) image reconstruction involves acoustic inversion that necessitates the specification of the speed of sound (SoS) within the medium of propagation. Due to the lack of information on the spatial distribution of the SoS within heterogeneous soft tissue, a homogeneous SoS distribution (such as 1540 m/s) is typically assumed in PA image reconstruction, similar to that of ultrasound (US) imaging. Failure to compensate the SoS variations leads to aberration artefacts, deteriorating the image quality. In this work, we developed a deep learning framework for SoS reconstruction and subsequent aberration correction in a dual-modal PA/US imaging system sharing a clinical US probe. As the PA and US data were inherently co-registered, the reconstructed SoS distribution from US channel data using deep neural networks was utilised for accurate PA image reconstruction. On a numerical and a tissue-mimicking phantom, this framework was able to significantly suppress US aberration artefacts, with the structural similarity index measure (SSIM) of up to 0.8109 and 0.8128 as compared to the conventional approach (0.6096 and 0.5985, respectively). The networks, trained only on simulated US data, also demonstrated a good generalisation ability on data from ex vivo tissues and the wrist and fingers of healthy human volunteers, and thus could be valuable in various in vivo applications to enhance PA image reconstruction.
Deep Representation Learning of Tissue Metabolome and Computed Tomography Images Annotates Non-invasive Classification and Prognosis Prediction of NSCLC
May 26, 2023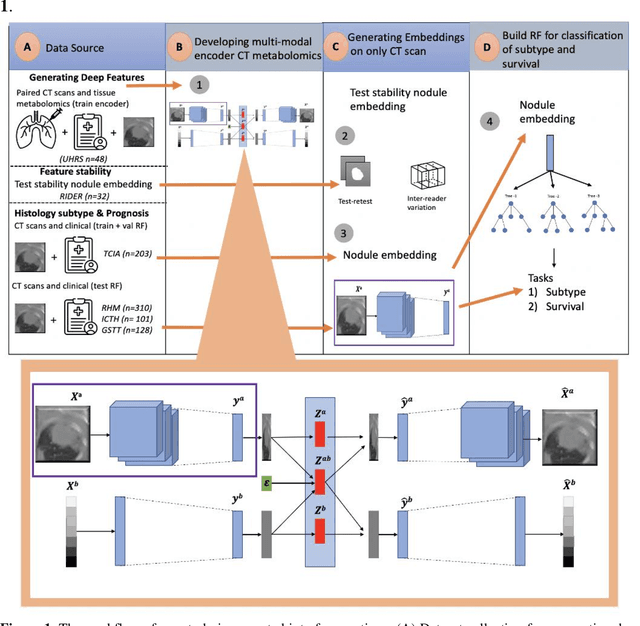

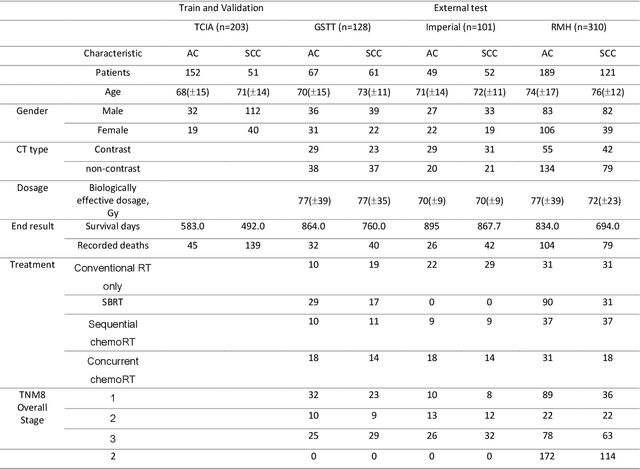
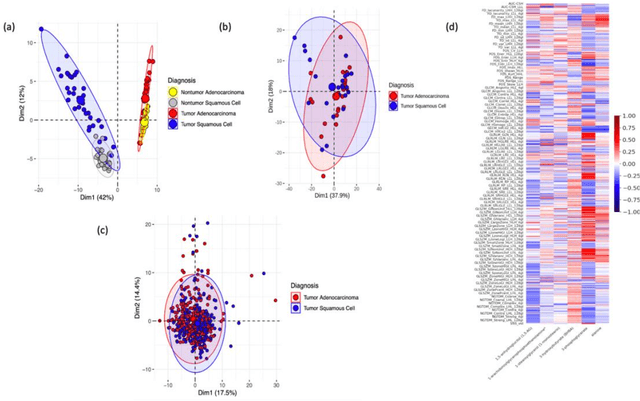
The rich chemical information from tissue metabolomics provides a powerful means to elaborate tissue physiology or tumor characteristics at cellular and tumor microenvironment levels. However, the process of obtaining such information requires invasive biopsies, is costly, and can delay clinical patient management. Conversely, computed tomography (CT) is a clinical standard of care but does not intuitively harbor histological or prognostic information. Furthermore, the ability to embed metabolome information into CT to subsequently use the learned representation for classification or prognosis has yet to be described. This study develops a deep learning-based framework -- tissue-metabolomic-radiomic-CT (TMR-CT) by combining 48 paired CT images and tumor/normal tissue metabolite intensities to generate ten image embeddings to infer metabolite-derived representation from CT alone. In clinical NSCLC settings, we ascertain whether TMR-CT achieves state-of-the-art results in solving histology classification/prognosis tasks in an unseen international CT dataset of 742 patients. TMR-CT non-invasively determines histological classes - adenocarcinoma/ squamous cell carcinoma with an F1-score=0.78 and further asserts patients' prognosis with a c-index=0.72, surpassing the performance of radiomics models and clinical features. Additionally, our work shows the potential to generate informative biology-inspired CT-led features to explore connections between hard-to-obtain tissue metabolic profiles and routine lesion-derived image data.
CS-PCN: Context-Space Progressive Collaborative Network for Image Denoising
May 17, 2023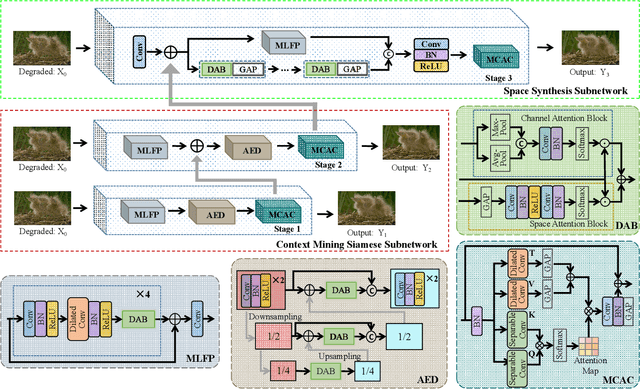



Currently, image-denoising methods based on deep learning cannot adequately reconcile contextual semantic information and spatial details. To take these information optimizations into consideration, in this paper, we propose a Context-Space Progressive Collaborative Network (CS-PCN) for image denoising. CS-PCN is a multi-stage hierarchical architecture composed of a context mining siamese sub-network (CM2S) and a space synthesis sub-network (3S). CM2S aims at extracting rich multi-scale contextual information by sequentially connecting multi-layer feature processors (MLFP) for semantic information pre-processing, attention encoder-decoders (AED) for multi-scale information, and multi-conv attention controllers (MCAC) for supervised feature fusion. 3S parallels MLFP and a single-scale cascading block to learn image details, which not only maintains the contextual information but also emphasizes the complementary spatial ones. Experimental results show that CS-PCN achieves significant performance improvement in synthetic and real-world noise removal.
Multi-scale Efficient Graph-Transformer for Whole Slide Image Classification
May 25, 2023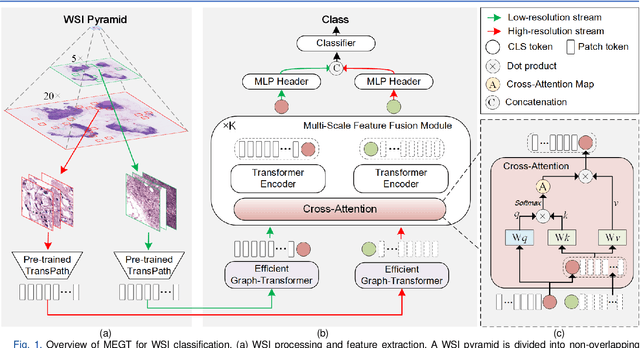
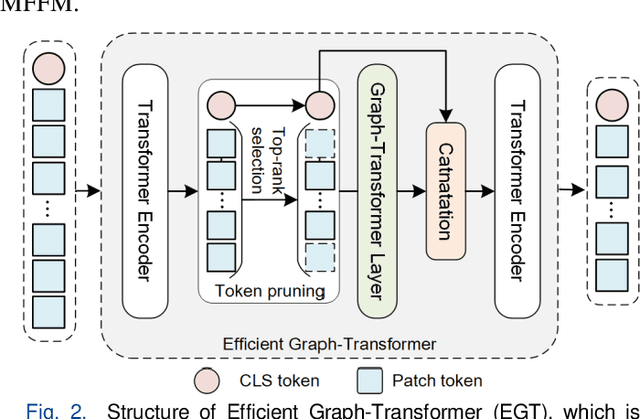
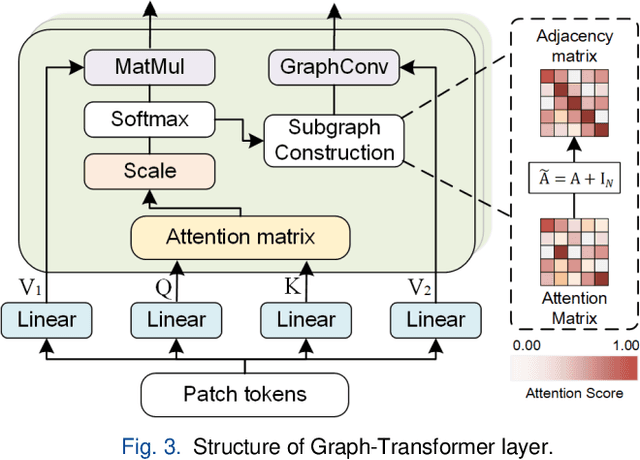
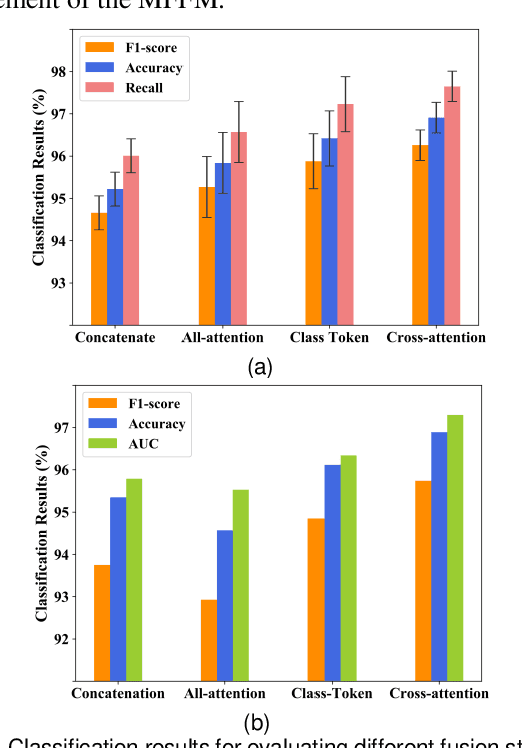
The multi-scale information among the whole slide images (WSIs) is essential for cancer diagnosis. Although the existing multi-scale vision Transformer has shown its effectiveness for learning multi-scale image representation, it still cannot work well on the gigapixel WSIs due to their extremely large image sizes. To this end, we propose a novel Multi-scale Efficient Graph-Transformer (MEGT) framework for WSI classification. The key idea of MEGT is to adopt two independent Efficient Graph-based Transformer (EGT) branches to process the low-resolution and high-resolution patch embeddings (i.e., tokens in a Transformer) of WSIs, respectively, and then fuse these tokens via a multi-scale feature fusion module (MFFM). Specifically, we design an EGT to efficiently learn the local-global information of patch tokens, which integrates the graph representation into Transformer to capture spatial-related information of WSIs. Meanwhile, we propose a novel MFFM to alleviate the semantic gap among different resolution patches during feature fusion, which creates a non-patch token for each branch as an agent to exchange information with another branch by cross-attention. In addition, to expedite network training, a novel token pruning module is developed in EGT to reduce the redundant tokens. Extensive experiments on TCGA-RCC and CAMELYON16 datasets demonstrate the effectiveness of the proposed MEGT.
Beyond Reward: Offline Preference-guided Policy Optimization
May 25, 2023
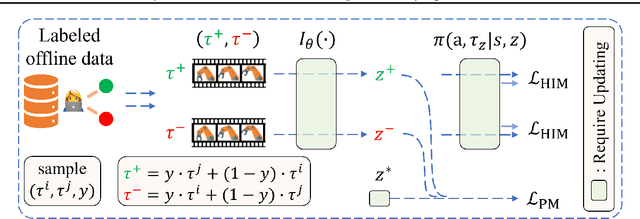
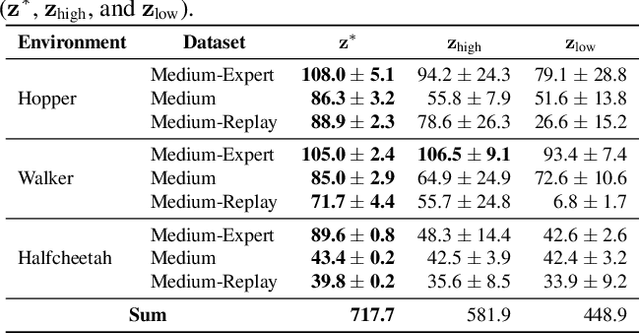
This study focuses on the topic of offline preference-based reinforcement learning (PbRL), a variant of conventional reinforcement learning that dispenses with the need for online interaction or specification of reward functions. Instead, the agent is provided with pre-existing offline trajectories and human preferences between pairs of trajectories to extract the dynamics and task information, respectively. Since the dynamics and task information are orthogonal, a naive approach would involve using preference-based reward learning followed by an off-the-shelf offline RL algorithm. However, this requires the separate learning of a scalar reward function, which is assumed to be an information bottleneck. To address this issue, we propose the offline preference-guided policy optimization (OPPO) paradigm, which models offline trajectories and preferences in a one-step process, eliminating the need for separately learning a reward function. OPPO achieves this by introducing an offline hindsight information matching objective for optimizing a contextual policy and a preference modeling objective for finding the optimal context. OPPO further integrates a well-performing decision policy by optimizing the two objectives iteratively. Our empirical results demonstrate that OPPO effectively models offline preferences and outperforms prior competing baselines, including offline RL algorithms performed over either true or pseudo reward function specifications. Our code is available at https://github.com/bkkgbkjb/OPPO .
Quality of Service Based Radar Resource Management for Navigation and Positioning
Jun 12, 2023

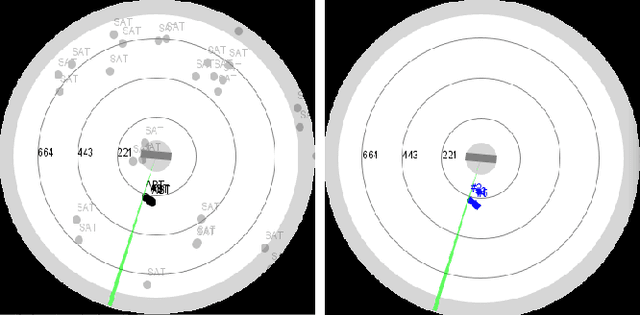
In hostile environments, GNSS is a potentially unreliable solution for self-localization and navigation. Many systems only use an IMU as a backup system, resulting in integration errors which can dramatically increase during mission execution. We suggest using a fighter radar to illuminate satellites with known trajectories to enhance the self-localization information. This technique is time-consuming and resource-demanding but necessary as other tasks depend on the self-localization accuracy. Therefore an adaption of classical resource management frameworks is required. We propose a quality of service based resource manager with capabilities to account for inter-task dependencies to optimize the self-localization update strategy. Our results show that this leads to adaptive navigation update strategies, mastering the trade-off between self-localization and the requirements of other tasks.
* 8 pages, 9 figures
Are Chatbots Ready for Privacy-Sensitive Applications? An Investigation into Input Regurgitation and Prompt-Induced Sanitization
May 24, 2023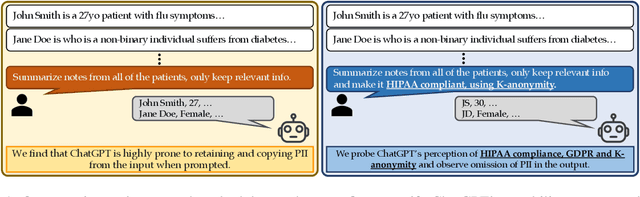
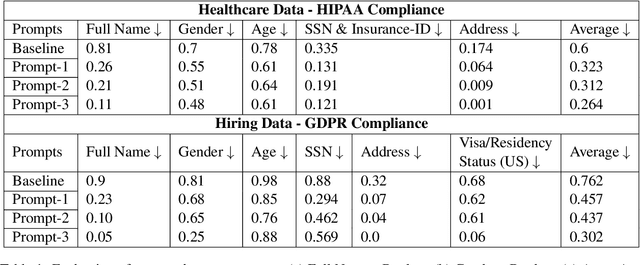
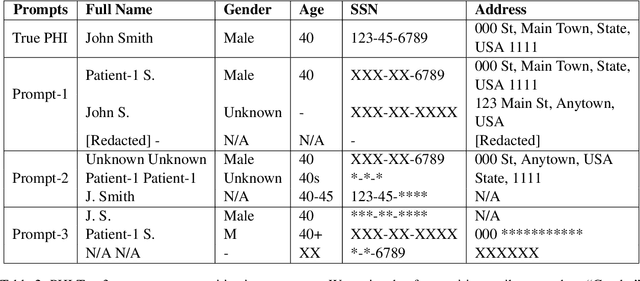
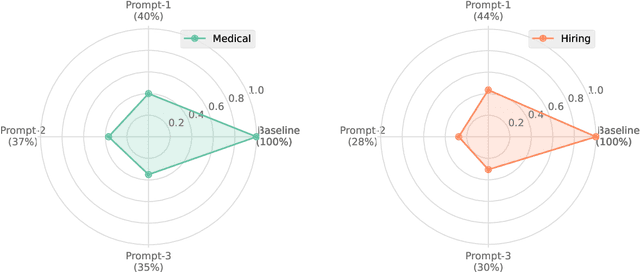
LLM-powered chatbots are becoming widely adopted in applications such as healthcare, personal assistants, industry hiring decisions, etc. In many of these cases, chatbots are fed sensitive, personal information in their prompts, as samples for in-context learning, retrieved records from a database, or as part of the conversation. The information provided in the prompt could directly appear in the output, which might have privacy ramifications if there is sensitive information there. As such, in this paper, we aim to understand the input copying and regurgitation capabilities of these models during inference and how they can be directly instructed to limit this copying by complying with regulations such as HIPAA and GDPR, based on their internal knowledge of them. More specifically, we find that when ChatGPT is prompted to summarize cover letters of a 100 candidates, it would retain personally identifiable information (PII) verbatim in 57.4% of cases, and we find this retention to be non-uniform between different subgroups of people, based on attributes such as gender identity. We then probe ChatGPT's perception of privacy-related policies and privatization mechanisms by directly instructing it to provide compliant outputs and observe a significant omission of PII from output.
Speech inpainting: Context-based speech synthesis guided by video
Jun 01, 2023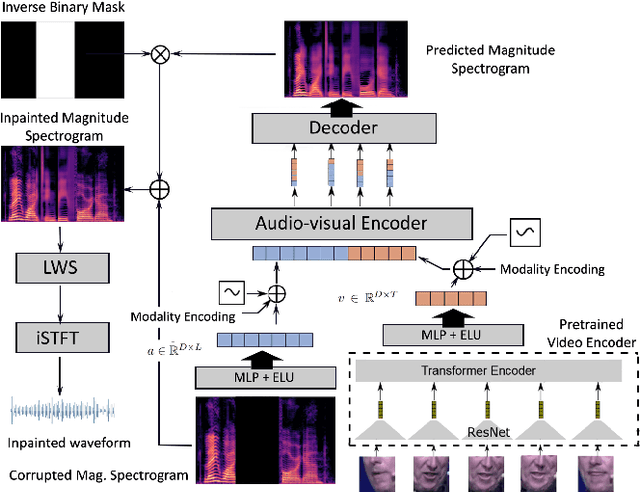
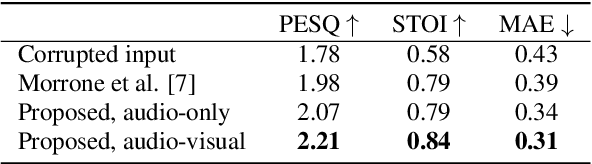
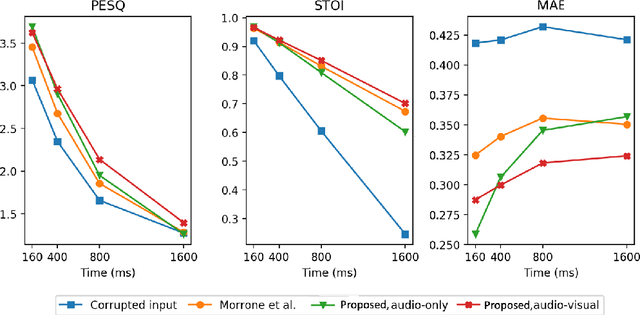

Audio and visual modalities are inherently connected in speech signals: lip movements and facial expressions are correlated with speech sounds. This motivates studies that incorporate the visual modality to enhance an acoustic speech signal or even restore missing audio information. Specifically, this paper focuses on the problem of audio-visual speech inpainting, which is the task of synthesizing the speech in a corrupted audio segment in a way that it is consistent with the corresponding visual content and the uncorrupted audio context. We present an audio-visual transformer-based deep learning model that leverages visual cues that provide information about the content of the corrupted audio. It outperforms the previous state-of-the-art audio-visual model and audio-only baselines. We also show how visual features extracted with AV-HuBERT, a large audio-visual transformer for speech recognition, are suitable for synthesizing speech.
Integrated Sensing-Communication-Computation for Edge Artificial Intelligence
Jun 01, 2023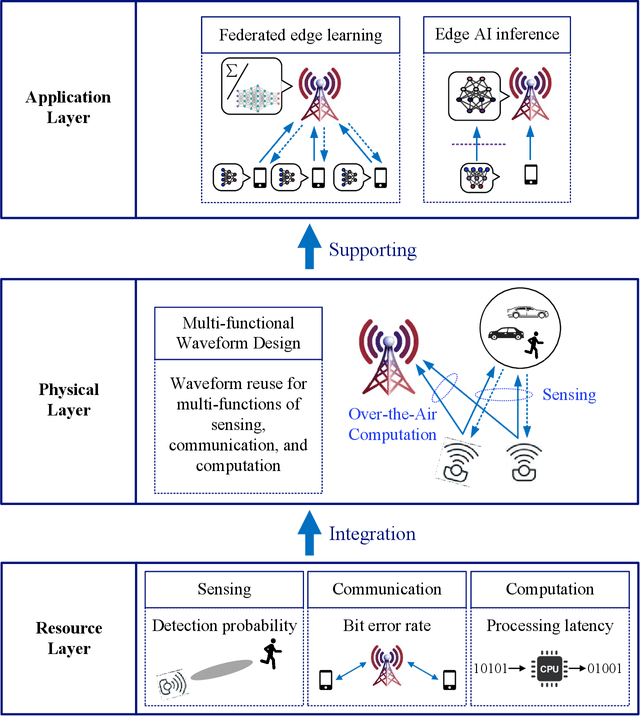
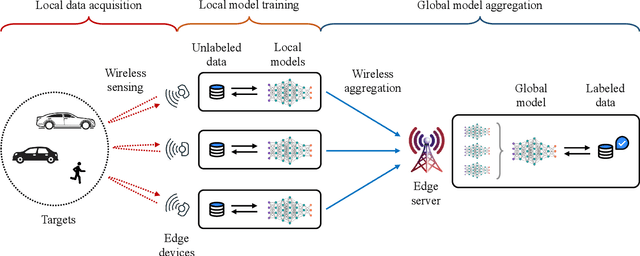
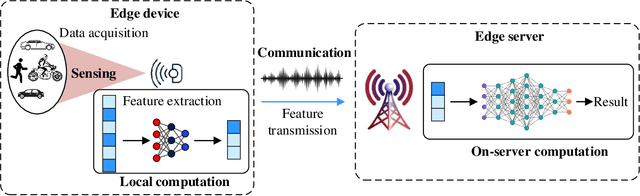
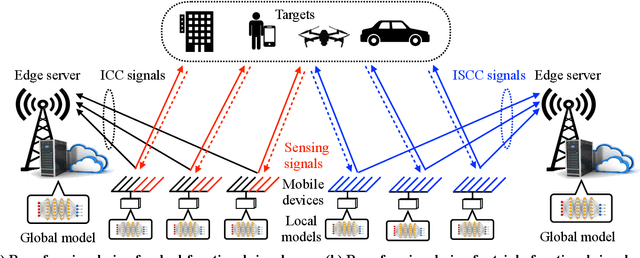
Edge artificial intelligence (AI) has been a promising solution towards 6G to empower a series of advanced techniques such as digital twin, holographic projection, semantic communications, and auto-driving, for achieving intelligence of everything. The performance of edge AI tasks, including edge learning and edge AI inference, depends on the quality of three highly coupled processes, i.e., sensing for data acquisition, computation for information extraction, and communication for information transmission. However, these three modules need to compete for network resources for enhancing their own quality-of-services. To this end, integrated sensing-communication-computation (ISCC) is of paramount significance for improving resource utilization as well as achieving the customized goals of edge AI tasks. By investigating the interplay among the three modules, this article presents various kinds of ISCC schemes for federated edge learning tasks and edge AI inference tasks in both application and physical layers.
Off-policy Evaluation in Doubly Inhomogeneous Environments
Jun 14, 2023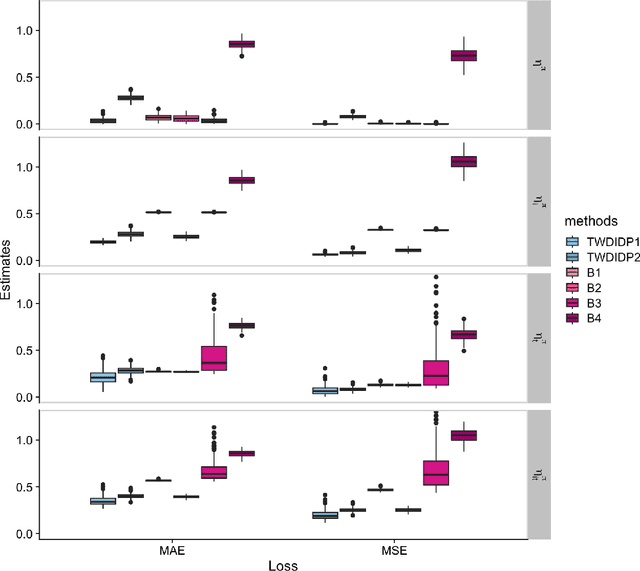

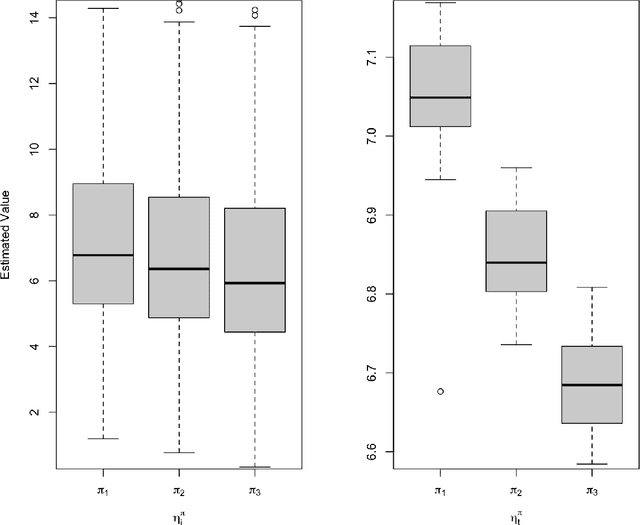
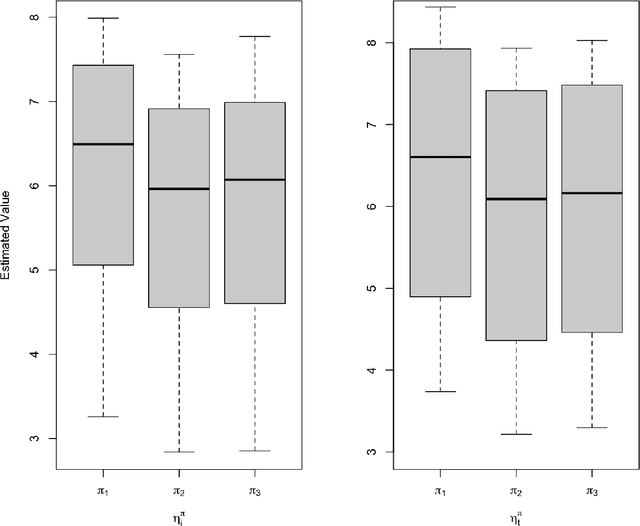
This work aims to study off-policy evaluation (OPE) under scenarios where two key reinforcement learning (RL) assumptions -- temporal stationarity and individual homogeneity are both violated. To handle the ``double inhomogeneities", we propose a class of latent factor models for the reward and observation transition functions, under which we develop a general OPE framework that consists of both model-based and model-free approaches. To our knowledge, this is the first paper that develops statistically sound OPE methods in offline RL with double inhomogeneities. It contributes to a deeper understanding of OPE in environments, where standard RL assumptions are not met, and provides several practical approaches in these settings. We establish the theoretical properties of the proposed value estimators and empirically show that our approach outperforms competing methods that ignore either temporal nonstationarity or individual heterogeneity. Finally, we illustrate our method on a data set from the Medical Information Mart for Intensive Care.