 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeech inpainting: Context-based speech synthesis guided by video
Jun 01, 2023



Audio and visual modalities are inherently connected in speech signals: lip movements and facial expressions are correlated with speech sounds. This motivates studies that incorporate the visual modality to enhance an acoustic speech signal or even restore missing audio information. Specifically, this paper focuses on the problem of audio-visual speech inpainting, which is the task of synthesizing the speech in a corrupted audio segment in a way that it is consistent with the corresponding visual content and the uncorrupted audio context. We present an audio-visual transformer-based deep learning model that leverages visual cues that provide information about the content of the corrupted audio. It outperforms the previous state-of-the-art audio-visual model and audio-only baselines. We also show how visual features extracted with AV-HuBERT, a large audio-visual transformer for speech recognition, are suitable for synthesizing speech.
Audio-Visual Speech Inpainting with Deep Learning
Oct 09, 2020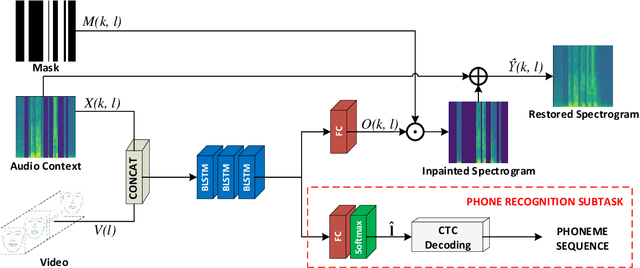
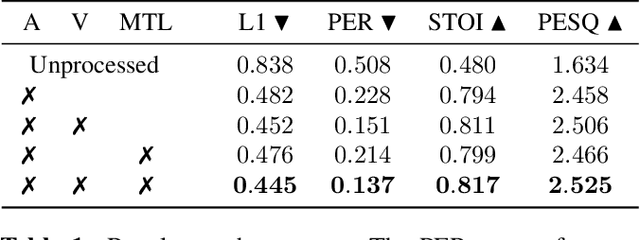
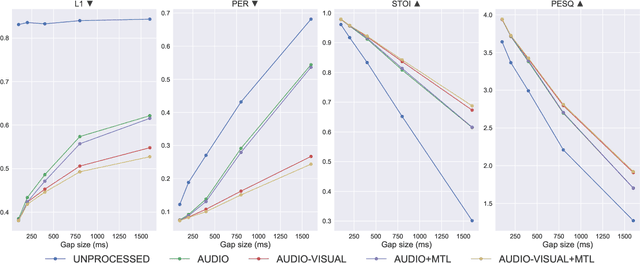
In this paper, we present a deep-learning-based framework for audio-visual speech inpainting, i.e., the task of restoring the missing parts of an acoustic speech signal from reliable audio context and uncorrupted visual information. Recent work focuses solely on audio-only methods and generally aims at inpainting music signals, which show highly different structure than speech. Instead, we inpaint speech signals with gaps ranging from 100 ms to 1600 ms to investigate the contribution that vision can provide for gaps of different duration. We also experiment with a multi-task learning approach where a phone recognition task is learned together with speech inpainting. Results show that the performance of audio-only speech inpainting approaches degrades rapidly when gaps get large, while the proposed audio-visual approach is able to plausibly restore missing information. In addition, we show that multi-task learning is effective, although the largest contribution to performance comes from vision.
An Overview of Deep-Learning-Based Audio-Visual Speech Enhancement and Separation
Aug 21, 2020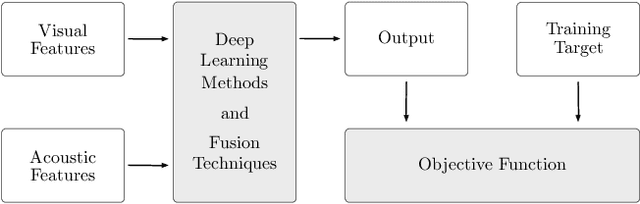
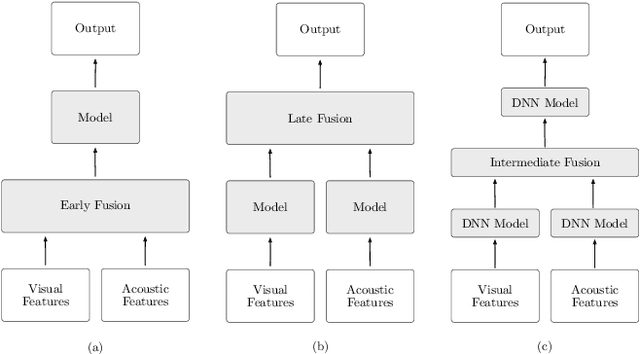
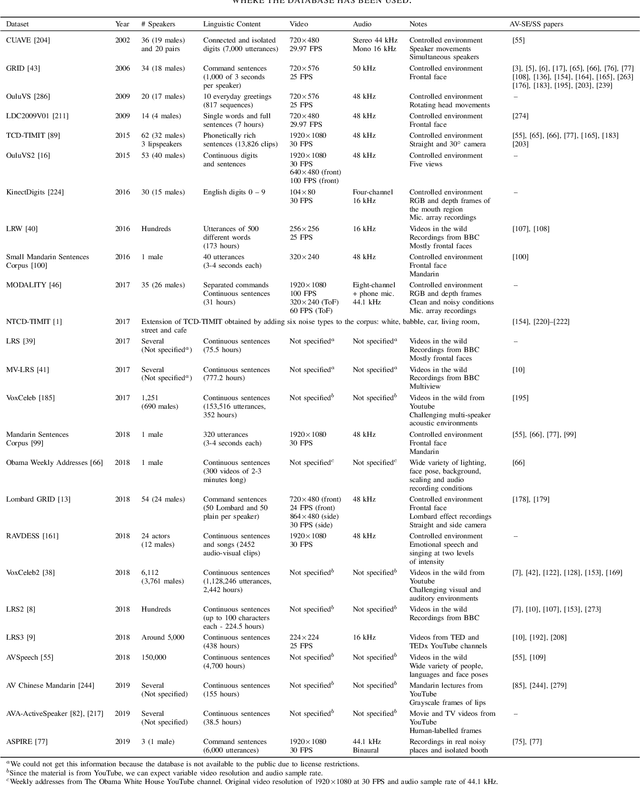
Speech enhancement and speech separation are two related tasks, whose purpose is to extract either one or more target speech signals, respectively, from a mixture of sounds generated by several sources. Traditionally, these tasks have been tackled using signal processing and machine learning techniques applied to the available acoustic signals. More recently, visual information from the target speakers, such as lip movements and facial expressions, has been introduced to speech enhancement and speech separation systems, because the visual aspect of speech is essentially unaffected by the acoustic environment. In order to efficiently fuse acoustic and visual information, researchers have exploited the flexibility of data-driven approaches, specifically deep learning, achieving state-of-the-art performance. The ceaseless proposal of a large number of techniques to extract features and fuse multimodal information has highlighted the need for an overview that comprehensively describes and discusses audio-visual speech enhancement and separation based on deep learning. In this paper, we provide a systematic survey of this research topic, focusing on the main elements that characterise the systems in the literature: visual features; acoustic features; deep learning methods; fusion techniques; training targets and objective functions. We also survey commonly employed audio-visual speech datasets, given their central role in the development of data-driven approaches, and evaluation methods, because they are generally used to compare different systems and determine their performance. In addition, we review deep-learning-based methods for speech reconstruction from silent videos and audio-visual sound source separation for non-speech signals, since these methods can be more or less directly applied to audio-visual speech enhancement and separation.
Vocoder-Based Speech Synthesis from Silent Videos
Apr 06, 2020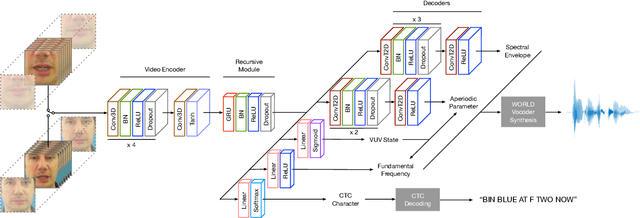
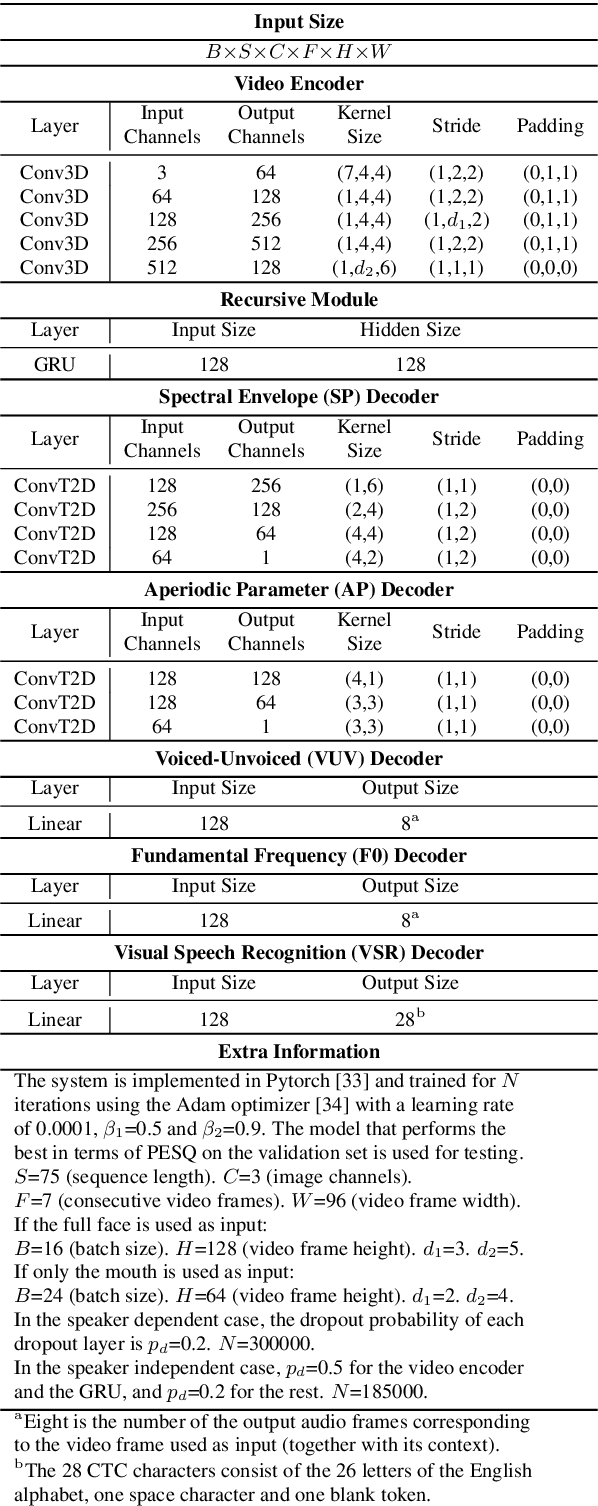

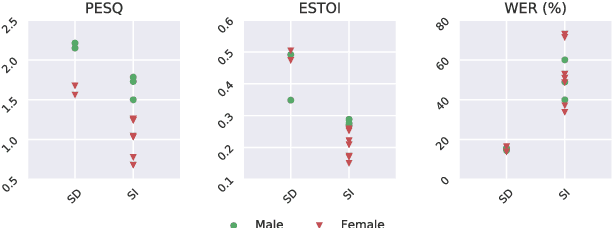
Both acoustic and visual information influence human perception of speech. For this reason, the lack of audio in a video sequence determines an extremely low speech intelligibility for untrained lip readers. In this paper, we present a way to synthesise speech from the silent video of a talker using deep learning. The system learns a mapping function from raw video frames to acoustic features and reconstructs the speech with a vocoder synthesis algorithm. To improve speech reconstruction performance, our model is also trained to predict text information in a multi-task learning fashion and it is able to simultaneously reconstruct and recognise speech in real time. The results in terms of estimated speech quality and intelligibility show the effectiveness of our method, which exhibits an improvement over existing video-to-speech approaches.
Deep-Learning-Based Audio-Visual Speech Enhancement in Presence of Lombard Effect
May 29, 2019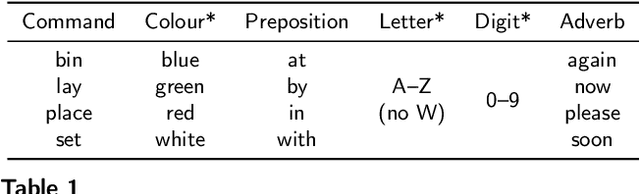
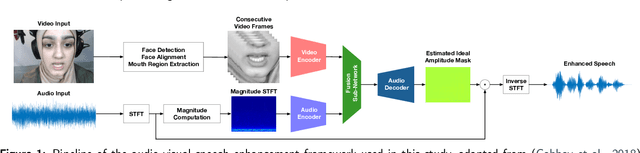
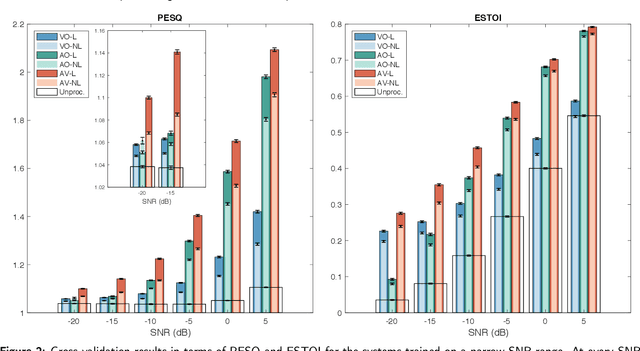
When speaking in presence of background noise, humans reflexively change their way of speaking in order to improve the intelligibility of their speech. This reflex is known as Lombard effect. Collecting speech in Lombard conditions is usually hard and costly. For this reason, speech enhancement systems are generally trained and evaluated on speech recorded in quiet to which noise is artificially added. Since these systems are often used in situations where Lombard speech occurs, in this work we perform an analysis of the impact that Lombard effect has on audio, visual and audio-visual speech enhancement, focusing on deep-learning-based systems, since they represent the current state of the art in the field. We conduct several experiments using an audio-visual Lombard speech corpus consisting of utterances spoken by 54 different talkers. The results show that training deep-learning-based models with Lombard speech is beneficial in terms of both estimated speech quality and estimated speech intelligibility at low signal to noise ratios, where the visual modality can play an important role in acoustically challenging situations. We also find that a performance difference between genders exists due to the distinct Lombard speech exhibited by males and females, and we analyse it in relation with acoustic and visual features. Furthermore, listening tests conducted with audio-visual stimuli show that the speech quality of the signals processed with systems trained using Lombard speech is statistically significantly better than the one obtained using systems trained with non-Lombard speech at a signal to noise ratio of -5 dB. Regarding speech intelligibility, we find a general tendency of the benefit in training the systems with Lombard speech.
Effects of Lombard Reflex on the Performance of Deep-Learning-Based Audio-Visual Speech Enhancement Systems
Nov 15, 2018
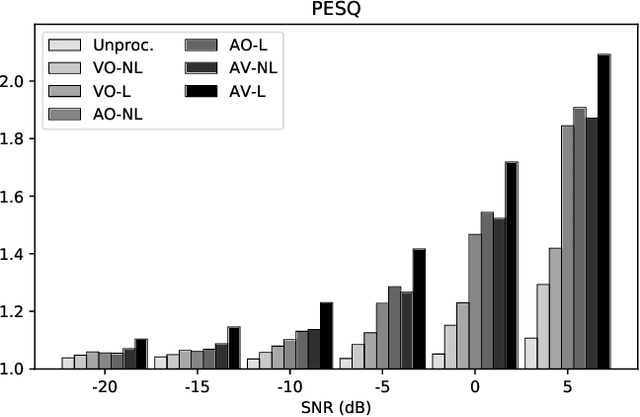

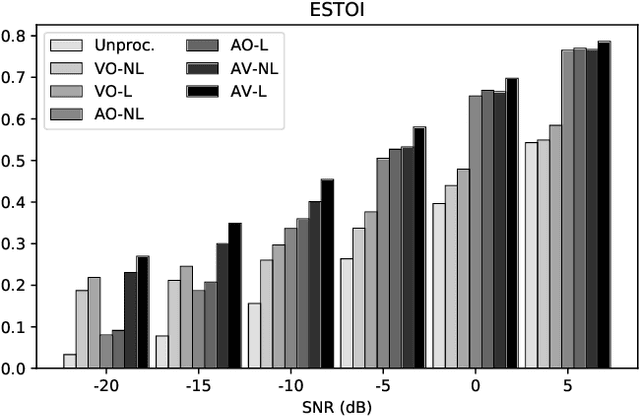
Humans tend to change their way of speaking when they are immersed in a noisy environment, a reflex known as Lombard effect. Current speech enhancement systems based on deep learning do not usually take into account this change in the speaking style, because they are trained with neutral (non-Lombard) speech utterances recorded under quiet conditions to which noise is artificially added. In this paper, we investigate the effects that the Lombard reflex has on the performance of audio-visual speech enhancement systems based on deep learning. The results show that a gap in the performance of as much as approximately 5 dB between the systems trained on neutral speech and the ones trained on Lombard speech exists. This indicates the benefit of taking into account the mismatch between neutral and Lombard speech in the design of audio-visual speech enhancement systems.
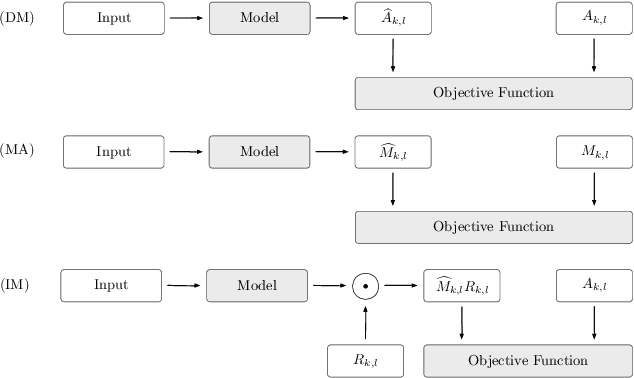
On Training Targets and Objective Functions for Deep-Learning-Based Audio-Visual Speech Enhancement
Nov 15, 2018
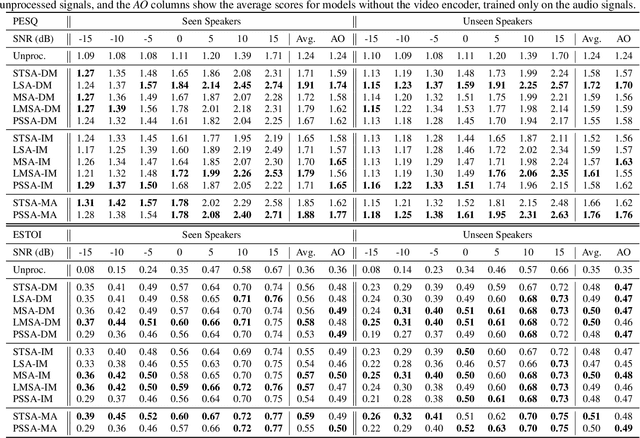
Audio-visual speech enhancement (AV-SE) is the task of improving speech quality and intelligibility in a noisy environment using audio and visual information from a talker. Recently, deep learning techniques have been adopted to solve the AV-SE task in a supervised manner. In this context, the choice of the target, i.e. the quantity to be estimated, and the objective function, which quantifies the quality of this estimate, to be used for training is critical for the performance. This work is the first that presents an experimental study of a range of different targets and objective functions used to train a deep-learning-based AV-SE system. The results show that the approaches that directly estimate a mask perform the best overall in terms of estimated speech quality and intelligibility, although the model that directly estimates the log magnitude spectrum performs as good in terms of estimated speech quality.
Conditional Generative Adversarial Networks for Speech Enhancement and Noise-Robust Speaker Verification
Sep 07, 2017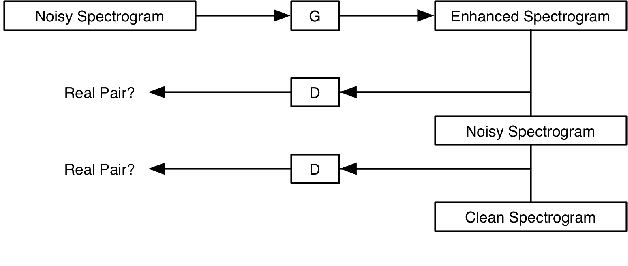
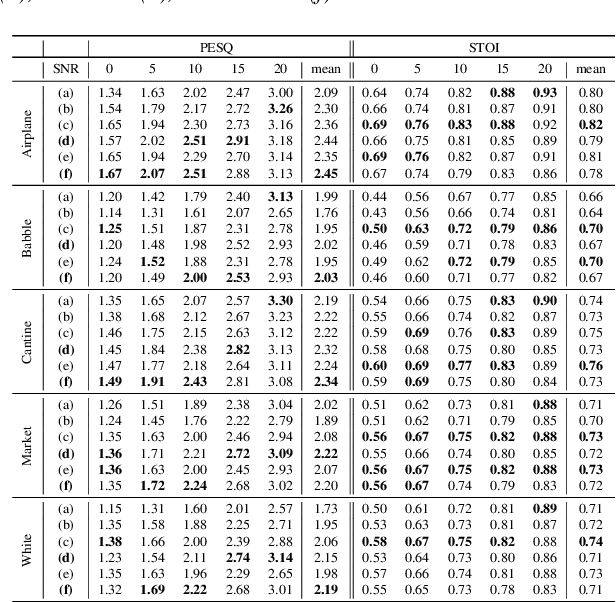

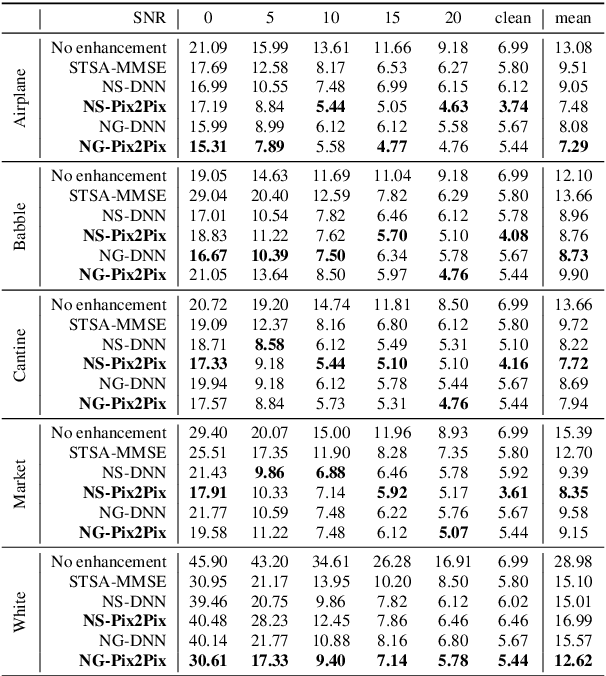
Improving speech system performance in noisy environments remains a challenging task, and speech enhancement (SE) is one of the effective techniques to solve the problem. Motivated by the promising results of generative adversarial networks (GANs) in a variety of image processing tasks, we explore the potential of conditional GANs (cGANs) for SE, and in particular, we make use of the image processing framework proposed by Isola et al. [1] to learn a mapping from the spectrogram of noisy speech to an enhanced counterpart. The SE cGAN consists of two networks, trained in an adversarial manner: a generator that tries to enhance the input noisy spectrogram, and a discriminator that tries to distinguish between enhanced spectrograms provided by the generator and clean ones from the database using the noisy spectrogram as a condition. We evaluate the performance of the cGAN method in terms of perceptual evaluation of speech quality (PESQ), short-time objective intelligibility (STOI), and equal error rate (EER) of speaker verification (an example application). Experimental results show that the cGAN method overall outperforms the classical short-time spectral amplitude minimum mean square error (STSA-MMSE) SE algorithm, and is comparable to a deep neural network-based SE approach (DNN-SE).