 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Near Optimal Heteroscedastic Regression with Symbiotic Learning
Jun 25, 2023

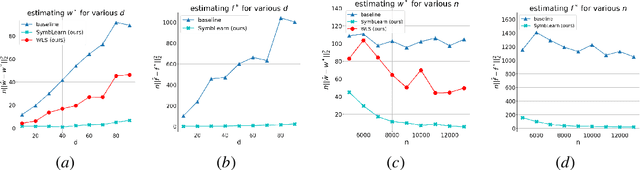
We consider the classical problem of heteroscedastic linear regression, where we are given $n$ samples $(\mathbf{x}_i, y_i) \in \mathbb{R}^d \times \mathbb{R}$ obtained from $y_i = \langle \mathbf{w}^{*}, \mathbf{x}_i \rangle + \epsilon_i \cdot \langle \mathbf{f}^{*}, \mathbf{x}_i \rangle$, where $\mathbf{x}_i \sim N(0,\mathbf{I})$, $\epsilon_i \sim N(0,1)$, and our task is to estimate $\mathbf{w}^{*}$. In addition to the classical applications of heteroscedastic models in fields such as statistics, econometrics, time series analysis etc., it is also particularly relevant in machine learning when data is collected from multiple sources of varying but apriori unknown quality, e.g., large model training. Our work shows that we can estimate $\mathbf{w}^{*}$ in squared norm up to an error of $\tilde{O}\left(\|\mathbf{f}^{*}\|^2 \cdot \left(\frac{1}{n} + \left(\frac{d}{n}\right)^2\right)\right)$ and prove a matching lower bound (up to logarithmic factors). Our result substantially improves upon the previous best known upper bound of $\tilde{O}\left(\|\mathbf{f}^{*}\|^2\cdot \frac{d}{n}\right)$. Our upper bound result is based on a novel analysis of a simple, classical heuristic going back to at least Davidian and Carroll (1987) and constitutes the first non-asymptotic convergence guarantee for this approach. As a byproduct, our analysis also provides improved rates of estimation for both linear regression and phase retrieval with multiplicative noise, which maybe of independent interest. The lower bound result relies on a careful application of LeCam's two point method, adapted to work with heavy tailed random variables where the relevant mutual information quantities are infinite (precluding a direct application of LeCam's method), and could also be of broader interest.
Research on Named Entity Recognition in Improved transformer with R-Drop structure
Jun 14, 2023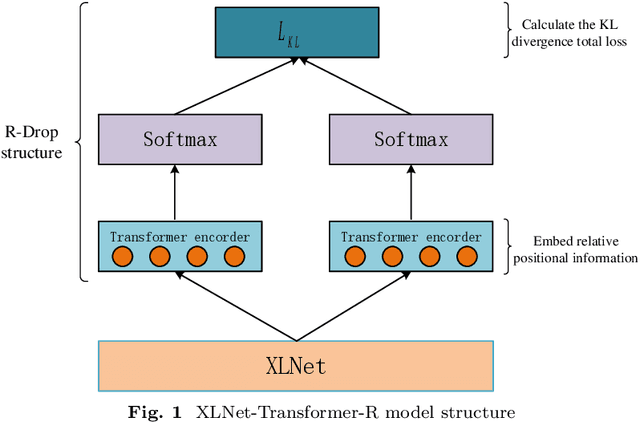
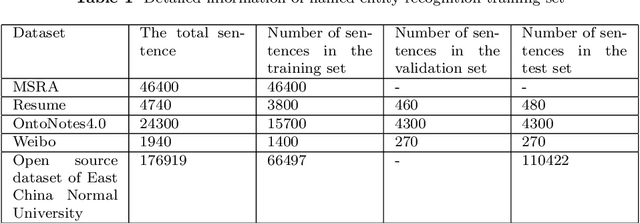

To enhance the generalization ability of the model and improve the effectiveness of the transformer for named entity recognition tasks, the XLNet-Transformer-R model is proposed in this paper. The XLNet pre-trained model and the Transformer encoder with relative positional encodings are combined to enhance the model's ability to process long text and learn contextual information to improve robustness. To prevent overfitting, the R-Drop structure is used to improve the generalization capability and enhance the accuracy of the model in named entity recognition tasks. The model in this paper performs ablation experiments on the MSRA dataset and comparison experiments with other models on four datasets with excellent performance, demonstrating the strategic effectiveness of the XLNet-Transformer-R model.
DataFinder: Scientific Dataset Recommendation from Natural Language Descriptions
Jun 07, 2023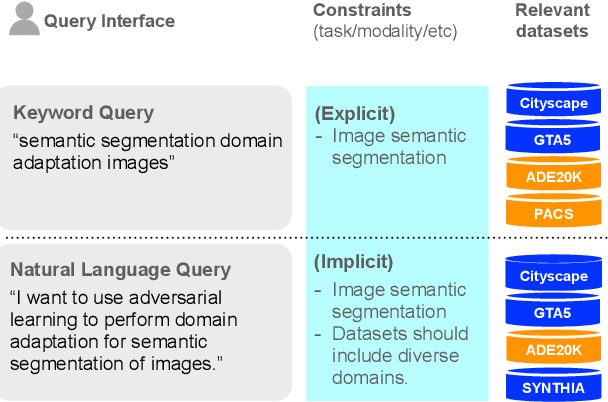
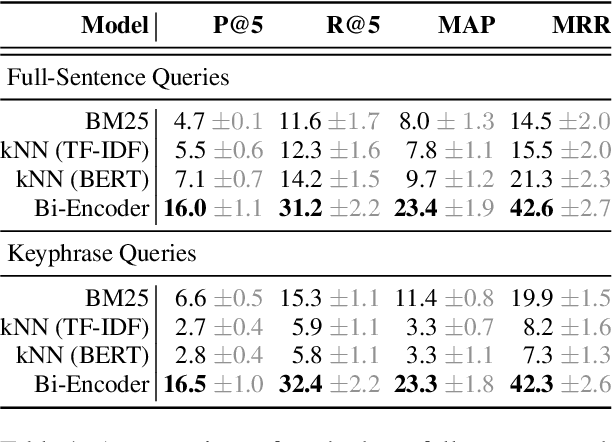
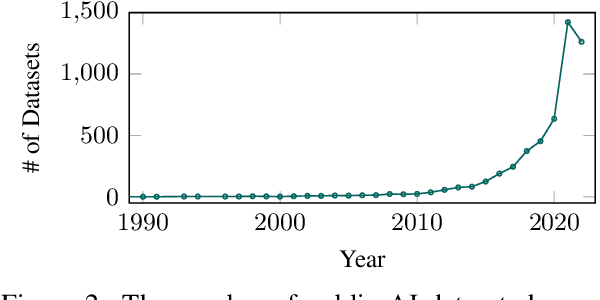
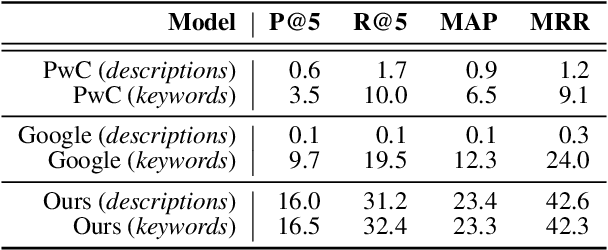
Modern machine learning relies on datasets to develop and validate research ideas. Given the growth of publicly available data, finding the right dataset to use is increasingly difficult. Any research question imposes explicit and implicit constraints on how well a given dataset will enable researchers to answer this question, such as dataset size, modality, and domain. We operationalize the task of recommending datasets given a short natural language description of a research idea, to help people find relevant datasets for their needs. Dataset recommendation poses unique challenges as an information retrieval problem; datasets are hard to directly index for search and there are no corpora readily available for this task. To facilitate this task, we build the DataFinder Dataset which consists of a larger automatically-constructed training set (17.5K queries) and a smaller expert-annotated evaluation set (392 queries). Using this data, we compare various information retrieval algorithms on our test set and present a superior bi-encoder retriever for text-based dataset recommendation. This system, trained on the DataFinder Dataset, finds more relevant search results than existing third-party dataset search engines. To encourage progress on dataset recommendation, we release our dataset and models to the public.
Uncovering solutions from data corrupted by systematic errors: A physics-constrained convolutional neural network approach
Jun 07, 2023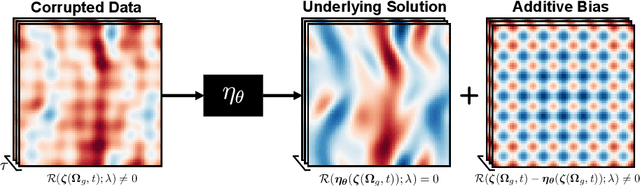
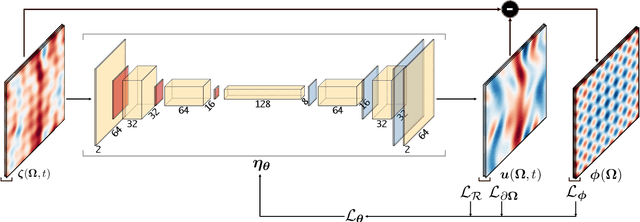
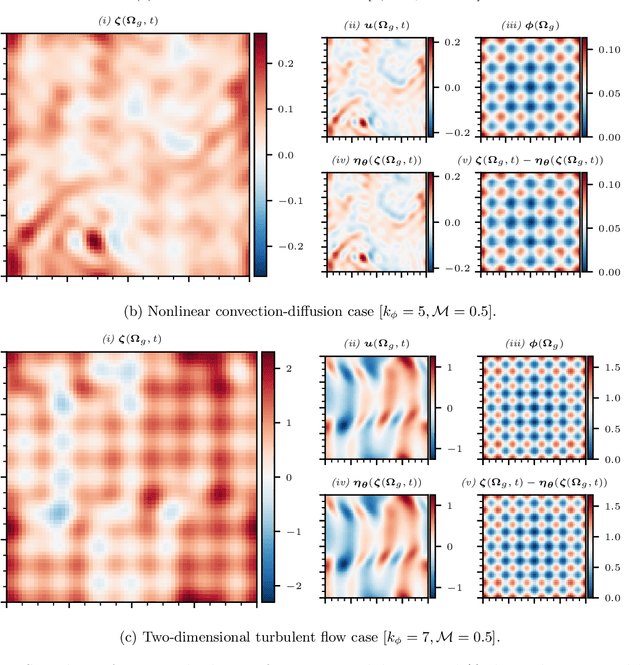
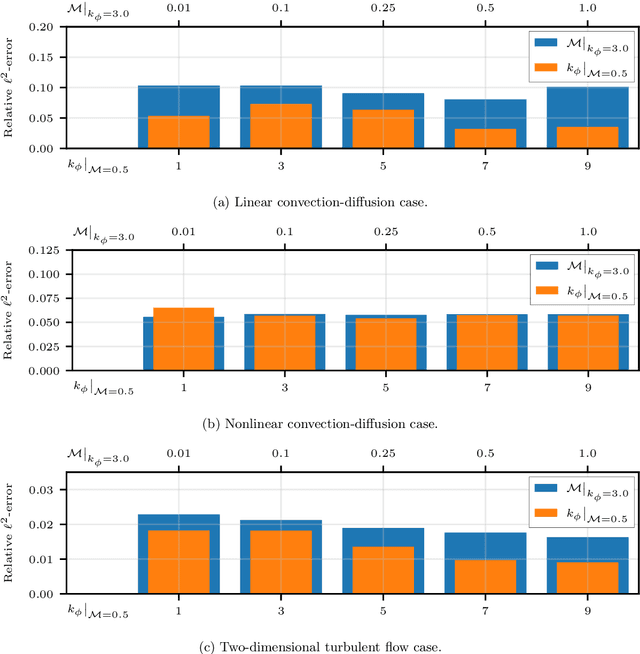
Information on natural phenomena and engineering systems is typically contained in data. Data can be corrupted by systematic errors in models and experiments. In this paper, we propose a tool to uncover the spatiotemporal solution of the underlying physical system by removing the systematic errors from data. The tool is the physics-constrained convolutional neural network (PC-CNN), which combines information from both the systems governing equations and data. We focus on fundamental phenomena that are modelled by partial differential equations, such as linear convection, Burgers equation, and two-dimensional turbulence. First, we formulate the problem, describe the physics-constrained convolutional neural network, and parameterise the systematic error. Second, we uncover the solutions from data corrupted by large multimodal systematic errors. Third, we perform a parametric study for different systematic errors. We show that the method is robust. Fourth, we analyse the physical properties of the uncovered solutions. We show that the solutions inferred from the PC-CNN are physical, in contrast to the data corrupted by systematic errors that does not fulfil the governing equations. This work opens opportunities for removing epistemic errors from models, and systematic errors from measurements.
On the Impact of Knowledge Distillation for Model Interpretability
May 25, 2023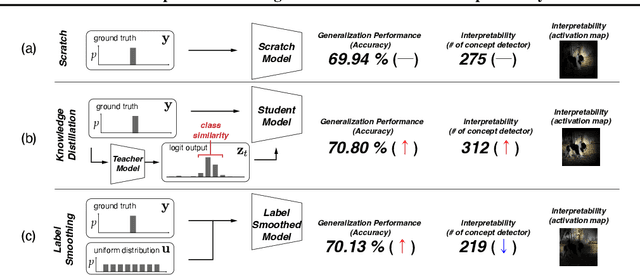
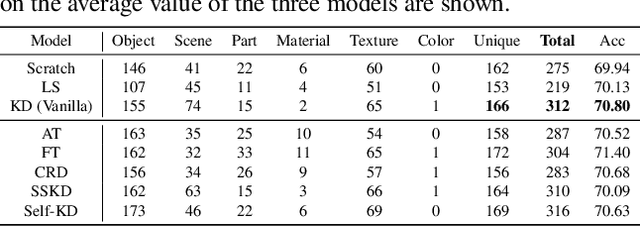
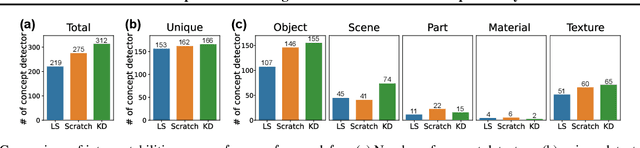

Several recent studies have elucidated why knowledge distillation (KD) improves model performance. However, few have researched the other advantages of KD in addition to its improving model performance. In this study, we have attempted to show that KD enhances the interpretability as well as the accuracy of models. We measured the number of concept detectors identified in network dissection for a quantitative comparison of model interpretability. We attributed the improvement in interpretability to the class-similarity information transferred from the teacher to student models. First, we confirmed the transfer of class-similarity information from the teacher to student model via logit distillation. Then, we analyzed how class-similarity information affects model interpretability in terms of its presence or absence and degree of similarity information. We conducted various quantitative and qualitative experiments and examined the results on different datasets, different KD methods, and according to different measures of interpretability. Our research showed that KD models by large models could be used more reliably in various fields.
Improving (Dis)agreement Detection with Inductive Social Relation Information From Comment-Reply Interactions
Feb 08, 2023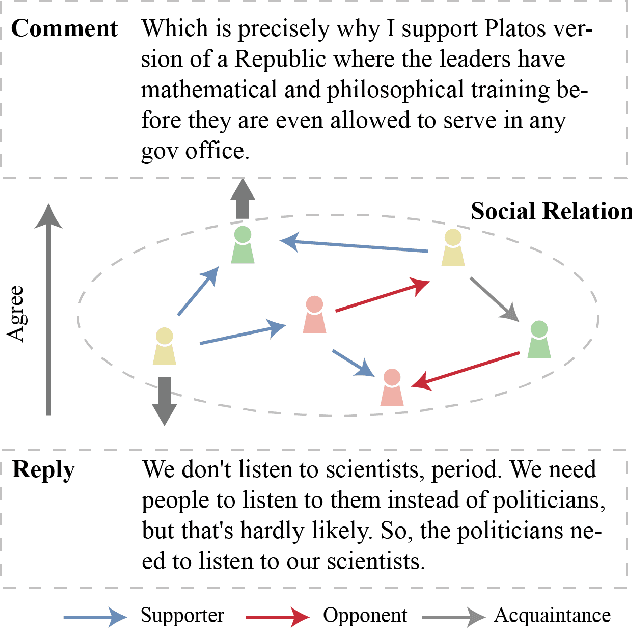
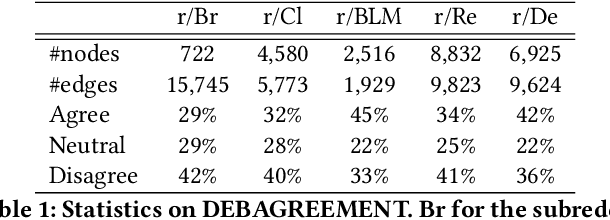
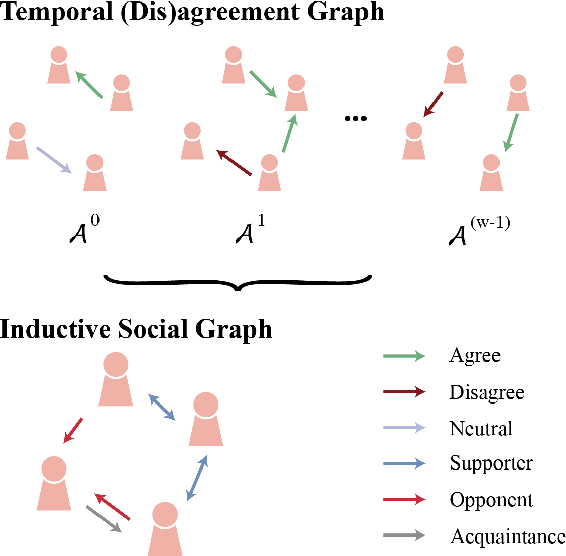
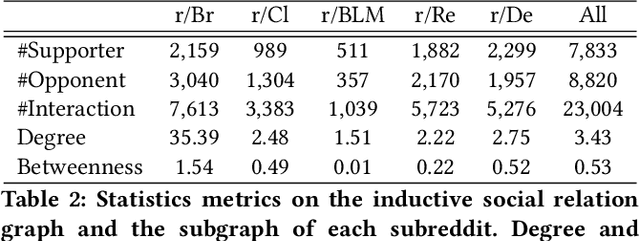
(Dis)agreement detection aims to identify the authors' attitudes or positions (\textit{{agree, disagree, neutral}}) towards a specific text. It is limited for existing methods merely using textual information for identifying (dis)agreements, especially for cross-domain settings. Social relation information can play an assistant role in the (dis)agreement task besides textual information. We propose a novel method to extract such relation information from (dis)agreement data into an inductive social relation graph, merely using the comment-reply pairs without any additional platform-specific information. The inductive social relation globally considers the historical discussion and the relation between authors. Textual information based on a pre-trained language model and social relation information encoded by pre-trained RGCN are jointly considered for (dis)agreement detection. Experimental results show that our model achieves state-of-the-art performance for both the in-domain and cross-domain tasks on the benchmark -- DEBAGREEMENT. We find social relations can boost the performance of the (dis)agreement detection model, especially for the long-token comment-reply pairs, demonstrating the effectiveness of the social relation graph. We also explore the effect of the knowledge graph embedding methods, the information fusing method, and the time interval in constructing the social relation graph, which shows the effectiveness of our model.
Vision Guided MIMO Radar Beamforming for Enhanced Vital Signs Detection in Crowds
Jun 18, 2023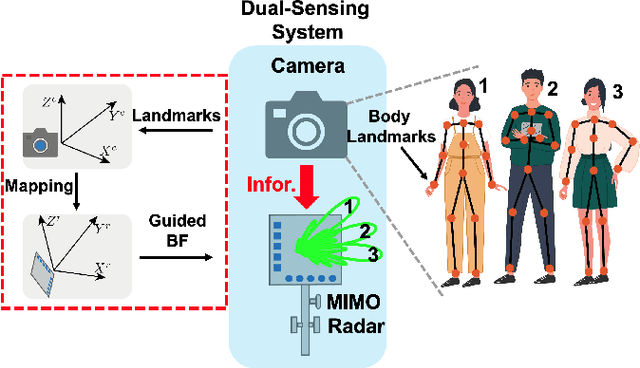
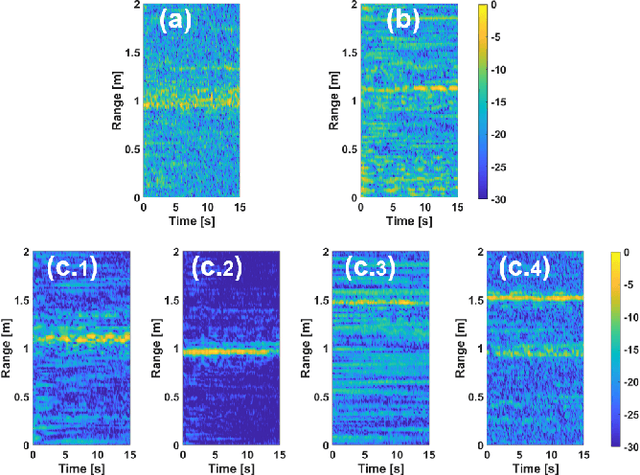
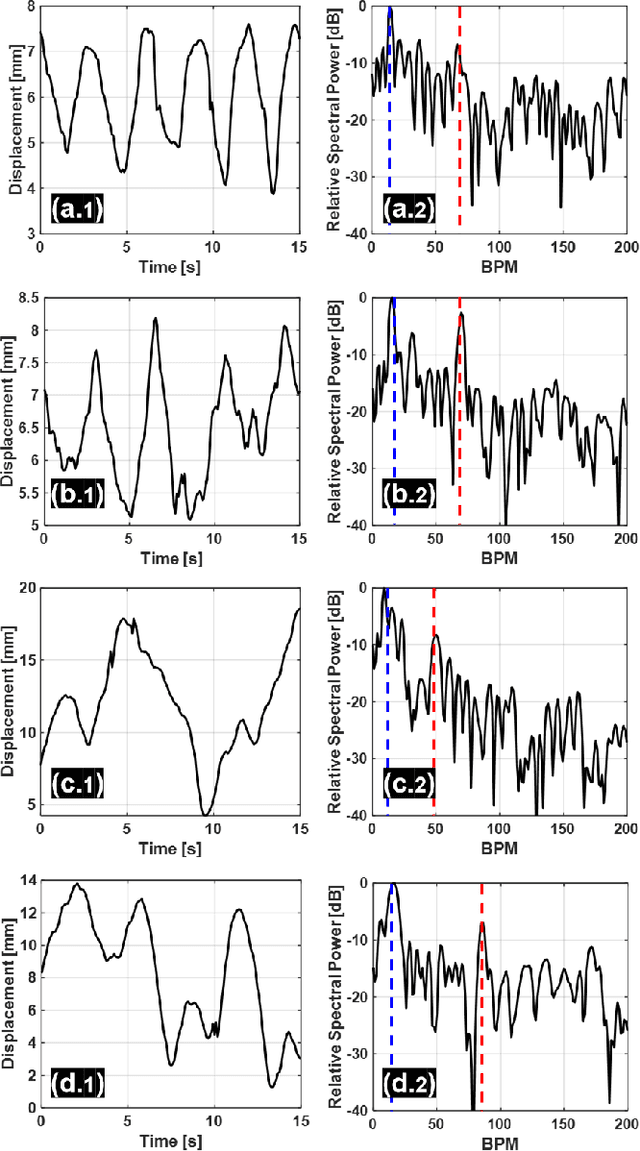
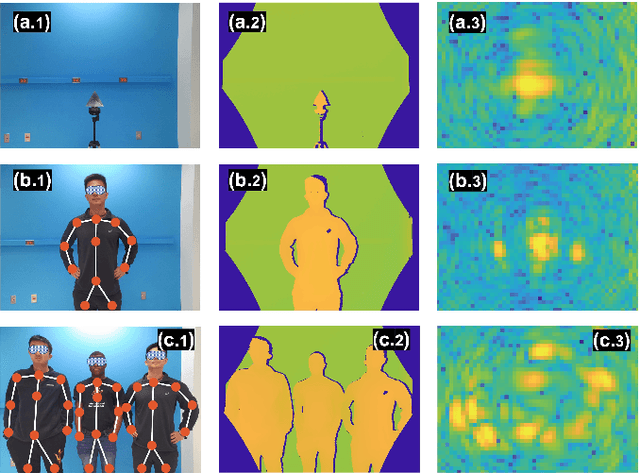
Radar as a remote sensing technology has been used to analyze human activity for decades. Despite all the great features such as motion sensitivity, privacy preservation, penetrability, and more, radar has limited spatial degrees of freedom compared to optical sensors and thus makes it challenging to sense crowded environments without prior information. In this paper, we develop a novel dual-sensing system, in which a vision sensor is leveraged to guide digital beamforming in a multiple-input multiple-output (MIMO) radar. Also, we develop a calibration algorithm to align the two types of sensors and show that the calibrated dual system achieves about two centimeters precision in three-dimensional space within a field of view of $75^\circ$ by $65^\circ$ and for a range of two meters. Finally, we show that the proposed approach is capable of detecting the vital signs simultaneously for a group of closely spaced subjects, sitting and standing, in a cluttered environment, which highlights a promising direction for vital signs detection in realistic environments.
Structure-Sensitive Graph Dictionary Embedding for Graph Classification
Jun 18, 2023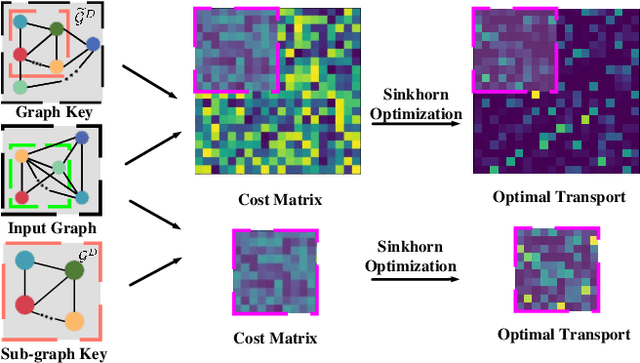
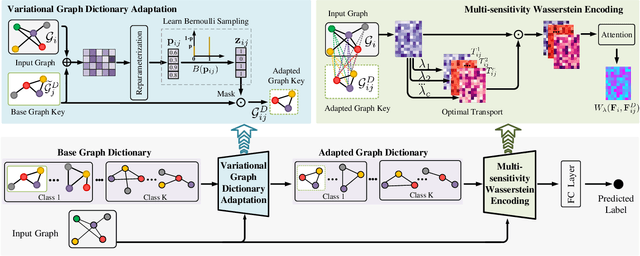
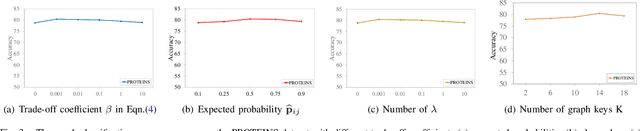

Graph structure expression plays a vital role in distinguishing various graphs. In this work, we propose a Structure-Sensitive Graph Dictionary Embedding (SS-GDE) framework to transform input graphs into the embedding space of a graph dictionary for the graph classification task. Instead of a plain use of a base graph dictionary, we propose the variational graph dictionary adaptation (VGDA) to generate a personalized dictionary (named adapted graph dictionary) for catering to each input graph. In particular, for the adaptation, the Bernoulli sampling is introduced to adjust substructures of base graph keys according to each input, which increases the expression capacity of the base dictionary tremendously. To make cross-graph measurement sensitive as well as stable, multi-sensitivity Wasserstein encoding is proposed to produce the embeddings by designing multi-scale attention on optimal transport. To optimize the framework, we introduce mutual information as the objective, which further deduces to variational inference of the adapted graph dictionary. We perform our SS-GDE on multiple datasets of graph classification, and the experimental results demonstrate the effectiveness and superiority over the state-of-the-art methods.
Knowledge Distillation for Efficient Audio-Visual Video Captioning
Jun 16, 2023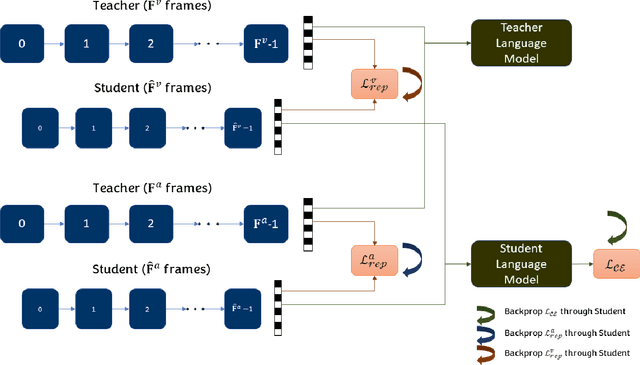
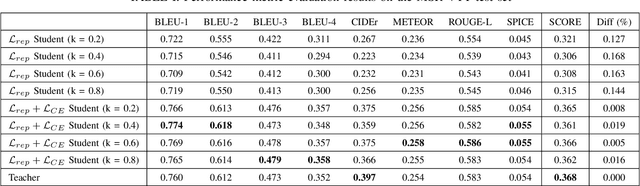
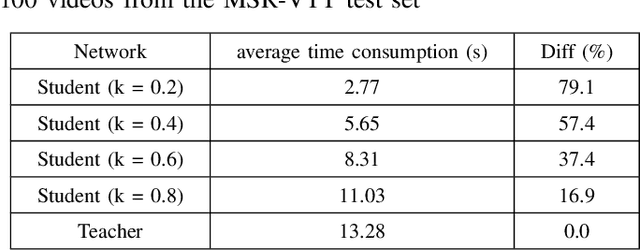
Automatically describing audio-visual content with texts, namely video captioning, has received significant attention due to its potential applications across diverse fields. Deep neural networks are the dominant methods, offering state-of-the-art performance. However, these methods are often undeployable in low-power devices like smartphones due to the large size of the model parameters. In this paper, we propose to exploit simple pooling front-end and down-sampling algorithms with knowledge distillation for audio and visual attributes using a reduced number of audio-visual frames. With the help of knowledge distillation from the teacher model, our proposed method greatly reduces the redundant information in audio-visual streams without losing critical contexts for caption generation. Extensive experimental evaluations on the MSR-VTT dataset demonstrate that our proposed approach significantly reduces the inference time by about 80% with a small sacrifice (less than 0.02%) in captioning accuracy.
Reconfigurable Intelligent Surface Assisted Semantic Communication Systems
Jun 16, 2023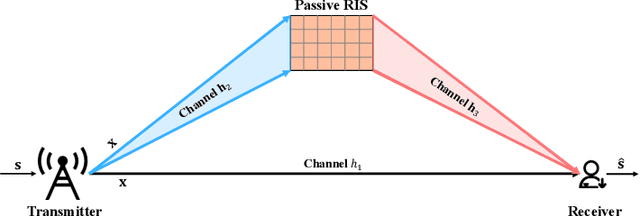
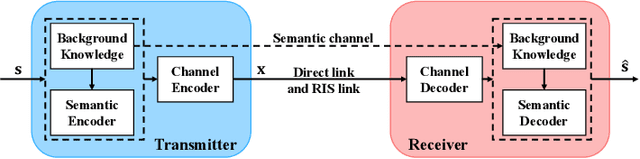
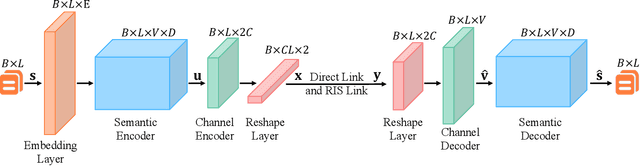
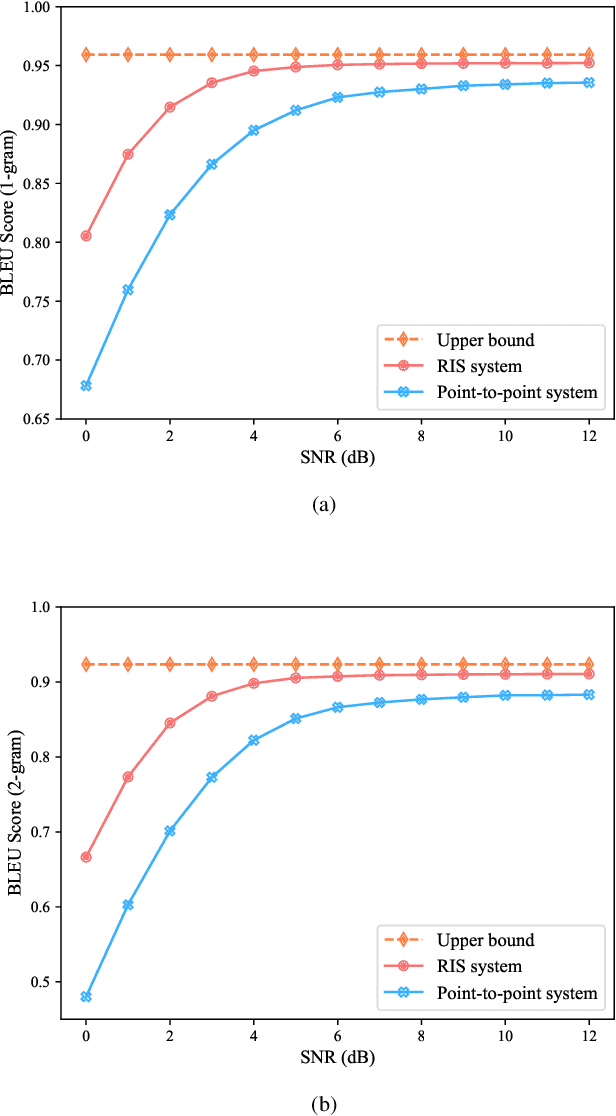
Semantic communication, which focuses on conveying the meaning of information rather than exact bit reconstruction, has gained considerable attention in recent years. Meanwhile, reconfigurable intelligent surface (RIS) is a promising technology that can achieve high spectral and energy efficiency by dynamically reflecting incident signals through programmable passive components. In this paper, we put forth a semantic communication scheme aided by RIS. Using text transmission as an example, experimental results demonstrate that the RIS-assisted semantic communication system outperforms the point-to-point semantic communication system in terms of BLEU scores in Rayleigh fading channels, especially at low signal-to-noise ratio (SNR) regimes. In addition, the RIS-assisted semantic communication system exhibits superior robustness against channel estimation errors compared to its point-to-point counterpart. RIS can improve performance as it provides extra line-of-sight (LoS) paths and enhances signal propagation conditions compared to point-to-point systems.