 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Pure Exploration in Bandits with Linear Constraints
Jun 22, 2023
We address the problem of identifying the optimal policy with a fixed confidence level in a multi-armed bandit setup, when \emph{the arms are subject to linear constraints}. Unlike the standard best-arm identification problem which is well studied, the optimal policy in this case may not be deterministic and could mix between several arms. This changes the geometry of the problem which we characterize via an information-theoretic lower bound. We introduce two asymptotically optimal algorithms for this setting, one based on the Track-and-Stop method and the other based on a game-theoretic approach. Both these algorithms try to track an optimal allocation based on the lower bound and computed by a weighted projection onto the boundary of a normal cone. Finally, we provide empirical results that validate our bounds and visualize how constraints change the hardness of the problem.
Sum-Rate Maximization of RSMA-based Aerial Communications with Energy Harvesting: A Reinforcement Learning Approach
Jun 22, 2023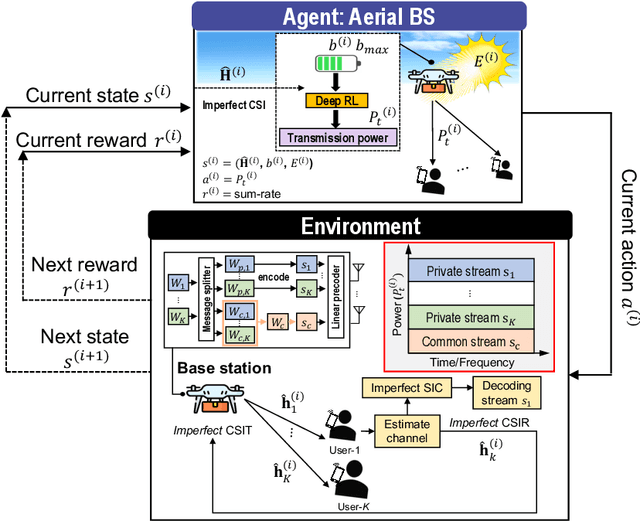
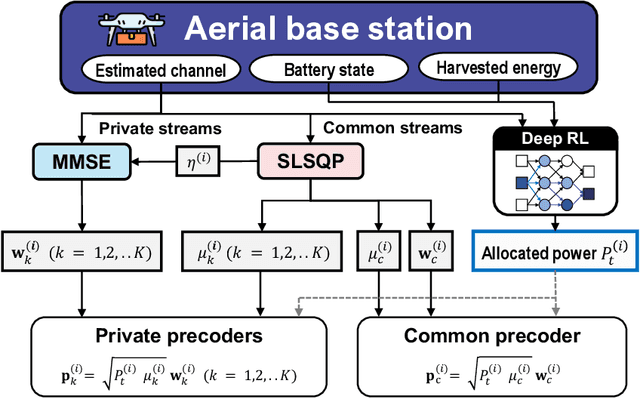
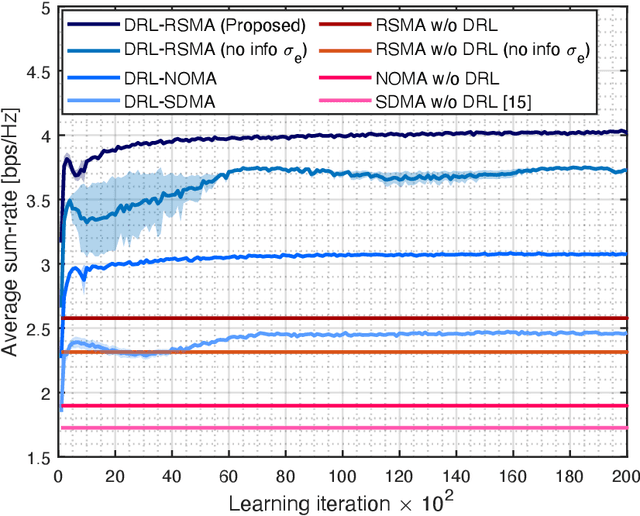
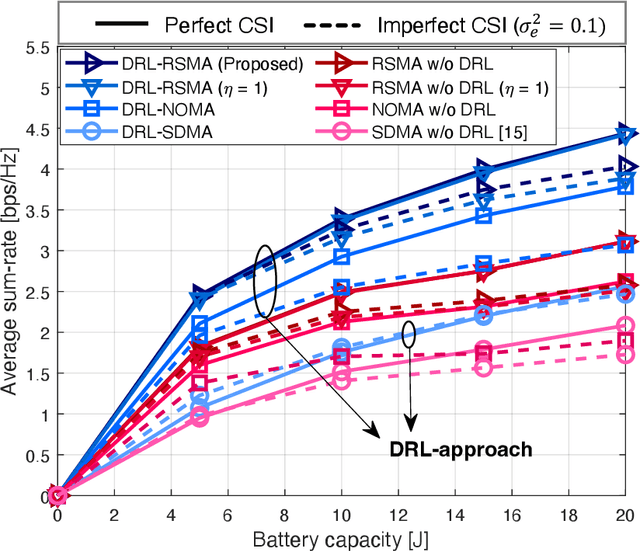
In this letter, we investigate a joint power and beamforming design problem for rate-splitting multiple access (RSMA)-based aerial communications with energy harvesting, where a self-sustainable aerial base station serves multiple users by utilizing the harvested energy. Considering maximizing the sum-rate from the long-term perspective, we utilize a deep reinforcement learning (DRL) approach, namely the soft actor-critic algorithm, to restrict the maximum transmission power at each time based on the stochastic property of the channel environment, harvested energy, and battery power information. Moreover, for designing precoders and power allocation among all the private/common streams of the RSMA, we employ sequential least squares programming (SLSQP) using the Han-Powell quasi-Newton method to maximize the sum-rate for the given transmission power via DRL. Numerical results show the superiority of the proposed scheme over several baseline methods in terms of the average sum-rate performance.
Sample Complexity for Quadratic Bandits: Hessian Dependent Bounds and Optimal Algorithms
Jun 22, 2023In stochastic zeroth-order optimization, a problem of practical relevance is understanding how to fully exploit the local geometry of the underlying objective function. We consider a fundamental setting in which the objective function is quadratic, and provide the first tight characterization of the optimal Hessian-dependent sample complexity. Our contribution is twofold. First, from an information-theoretic point of view, we prove tight lower bounds on Hessian-dependent complexities by introducing a concept called energy allocation, which captures the interaction between the searching algorithm and the geometry of objective functions. A matching upper bound is obtained by solving the optimal energy spectrum. Then, algorithmically, we show the existence of a Hessian-independent algorithm that universally achieves the asymptotic optimal sample complexities for all Hessian instances. The optimal sample complexities achieved by our algorithm remain valid for heavy-tailed noise distributions, which are enabled by a truncation method.
Finding the Missing-half: Graph Complementary Learning for Homophily-prone and Heterophily-prone Graphs
Jun 13, 2023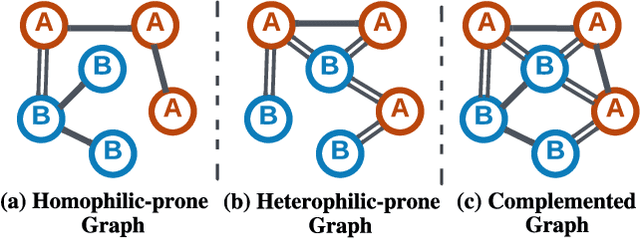
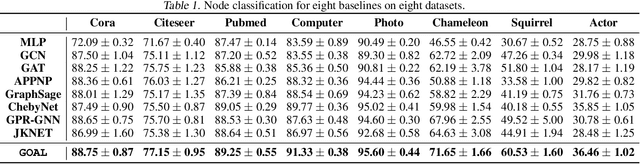
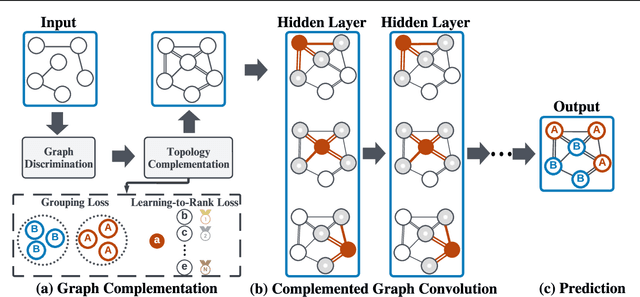
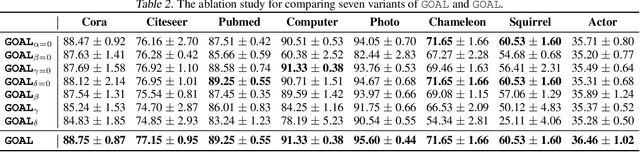
Real-world graphs generally have only one kind of tendency in their connections. These connections are either homophily-prone or heterophily-prone. While graphs with homophily-prone edges tend to connect nodes with the same class (i.e., intra-class nodes), heterophily-prone edges tend to build relationships between nodes with different classes (i.e., inter-class nodes). Existing GNNs only take the original graph during training. The problem with this approach is that it forgets to take into consideration the ``missing-half" structural information, that is, heterophily-prone topology for homophily-prone graphs and homophily-prone topology for heterophily-prone graphs. In our paper, we introduce Graph cOmplementAry Learning, namely GOAL, which consists of two components: graph complementation and complemented graph convolution. The first component finds the missing-half structural information for a given graph to complement it. The complemented graph has two sets of graphs including both homophily- and heterophily-prone topology. In the latter component, to handle complemented graphs, we design a new graph convolution from the perspective of optimisation. The experiment results show that GOAL consistently outperforms all baselines in eight real-world datasets.
Is RLHF More Difficult than Standard RL?
Jun 25, 2023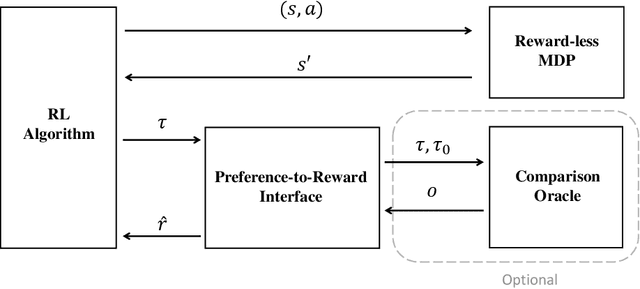
Reinforcement learning from Human Feedback (RLHF) learns from preference signals, while standard Reinforcement Learning (RL) directly learns from reward signals. Preferences arguably contain less information than rewards, which makes preference-based RL seemingly more difficult. This paper theoretically proves that, for a wide range of preference models, we can solve preference-based RL directly using existing algorithms and techniques for reward-based RL, with small or no extra costs. Specifically, (1) for preferences that are drawn from reward-based probabilistic models, we reduce the problem to robust reward-based RL that can tolerate small errors in rewards; (2) for general arbitrary preferences where the objective is to find the von Neumann winner, we reduce the problem to multiagent reward-based RL which finds Nash equilibria for factored Markov games under a restricted set of policies. The latter case can be further reduce to adversarial MDP when preferences only depend on the final state. We instantiate all reward-based RL subroutines by concrete provable algorithms, and apply our theory to a large class of models including tabular MDPs and MDPs with generic function approximation. We further provide guarantees when K-wise comparisons are available.
AttResDU-Net: Medical Image Segmentation Using Attention-based Residual Double U-Net
Jun 25, 2023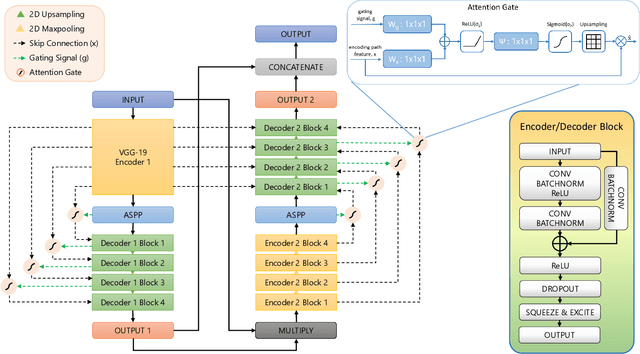
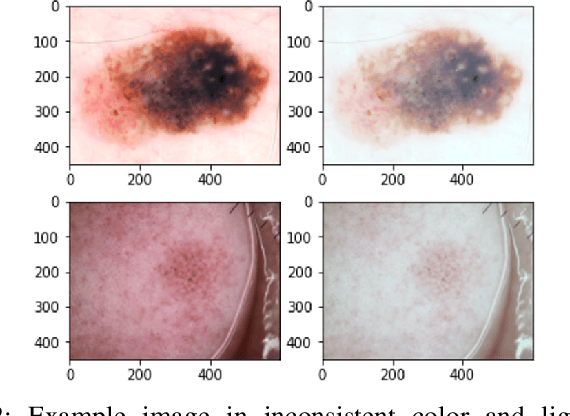
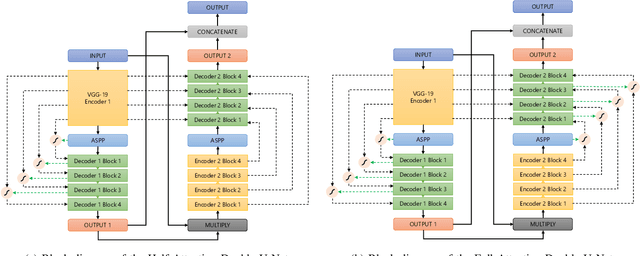

Manually inspecting polyps from a colonoscopy for colorectal cancer or performing a biopsy on skin lesions for skin cancer are time-consuming, laborious, and complex procedures. Automatic medical image segmentation aims to expedite this diagnosis process. However, numerous challenges exist due to significant variations in the appearance and sizes of objects with no distinct boundaries. This paper proposes an attention-based residual Double U-Net architecture (AttResDU-Net) that improves on the existing medical image segmentation networks. Inspired by the Double U-Net, this architecture incorporates attention gates on the skip connections and residual connections in the convolutional blocks. The attention gates allow the model to retain more relevant spatial information by suppressing irrelevant feature representation from the down-sampling path for which the model learns to focus on target regions of varying shapes and sizes. Moreover, the residual connections help to train deeper models by ensuring better gradient flow. We conducted experiments on three datasets: CVC Clinic-DB, ISIC 2018, and the 2018 Data Science Bowl datasets and achieved Dice Coefficient scores of 94.35%, 91.68% and 92.45% respectively. Our results suggest that AttResDU-Net can be facilitated as a reliable method for automatic medical image segmentation in practice.
Hyp-OW: Exploiting Hierarchical Structure Learning with Hyperbolic Distance Enhances Open World Object Detection
Jun 25, 2023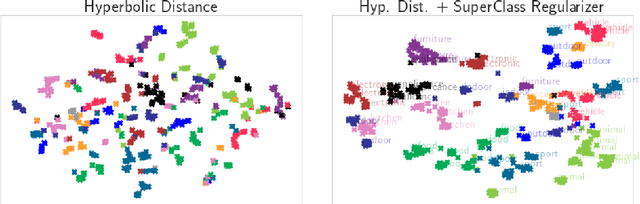
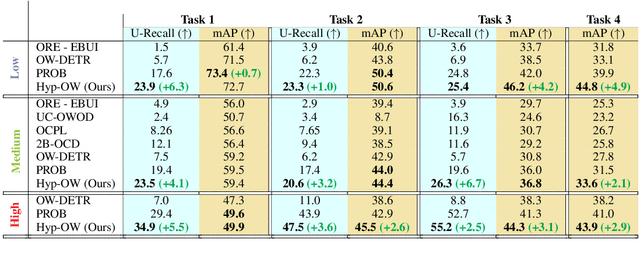
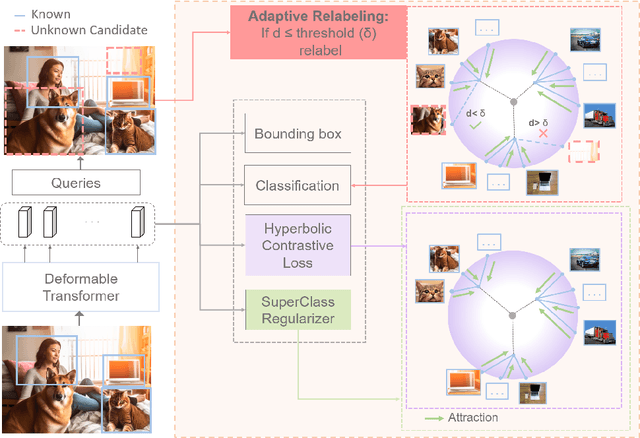

Open World Object Detection (OWOD) is a challenging and realistic task that extends beyond the scope of standard Object Detection task. It involves detecting both known and unknown objects while integrating learned knowledge for future tasks. However, the level of 'unknownness' varies significantly depending on the context. For example, a tree is typically considered part of the background in a self-driving scene, but it may be significant in a household context. We argue that this external or contextual information should already be embedded within the known classes. In other words, there should be a semantic or latent structure relationship between the known and unknown items to be discovered. Motivated by this observation, we propose Hyp-OW, a method that learns and models hierarchical representation of known items through a SuperClass Regularizer. Leveraging this learned representation allows us to effectively detect unknown objects using a Similarity Distance-based Relabeling module. Extensive experiments on benchmark datasets demonstrate the effectiveness of Hyp-OW achieving improvement in both known and unknown detection (up to 6 points). These findings are particularly pronounced in our newly designed benchmark, where a strong hierarchical structure exists between known and unknown objects.
A serial dual-channel library occupancy detection system based on Faster RCNN
Jun 28, 2023
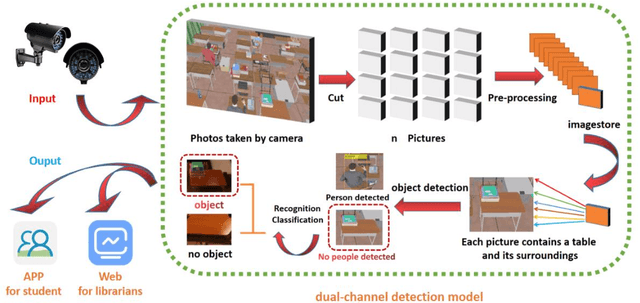
The phenomenon of seat occupancy in university libraries is a prevalent issue. However, existing solutions, such as software-based seat reservations and sensors-based occupancy detection, have proven to be inadequate in effectively addressing this problem. In this study, we propose a novel approach: a serial dual-channel object detection model based on Faster RCNN. Furthermore, we develop a user-friendly Web interface and mobile APP to create a computer vision-based platform for library seat occupancy detection. To construct our dataset, we combine real-world data collec-tion with UE5 virtual reality. The results of our tests also demonstrate that the utilization of per-sonalized virtual dataset significantly enhances the performance of the convolutional neural net-work (CNN) in dedicated scenarios. The serial dual-channel detection model comprises three es-sential steps. Firstly, we employ Faster RCNN algorithm to determine whether a seat is occupied by an individual. Subsequently, we utilize an object classification algorithm based on transfer learning, to classify and identify images of unoccupied seats. This eliminates the need for manual judgment regarding whether a person is suspected of occupying a seat. Lastly, the Web interface and APP provide seat information to librarians and students respectively, enabling comprehensive services. By leveraging deep learning methodologies, this research effectively addresses the issue of seat occupancy in library systems. It significantly enhances the accuracy of seat occupancy recognition, reduces the computational resources required for training CNNs, and greatly improves the effi-ciency of library seat management.
Weighted structure tensor total variation for image denoising
Jun 18, 2023
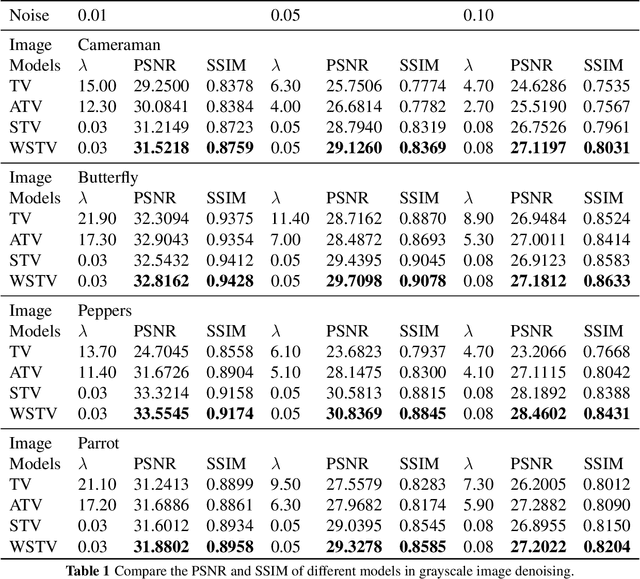

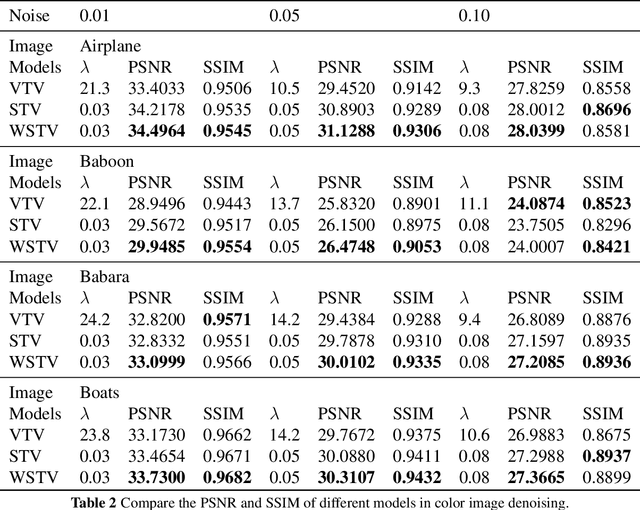
Based on the variational framework of the image denoising problem, we introduce a novel image denoising regularizer that combines anisotropic total variation model (ATV) and structure tensor total variation model (STV) in this paper. The model can effectively capture the first-order information of the image and maintain local features during the denoising process by applying the matrix weighting operator proposed in the ATV model to the patch-based Jacobian matrix in the STV model. Denoising experiments on grayscale and RGB color images demonstrate that the suggested model can produce better restoration quality in comparison to other well-known methods based on total-variation-based models and the STV model.
Error Feedback Can Accurately Compress Preconditioners
Jun 14, 2023
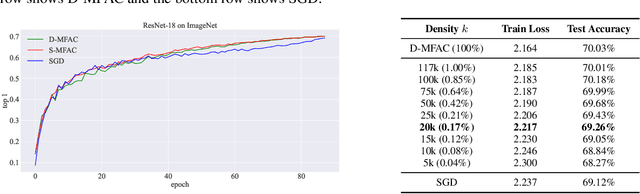

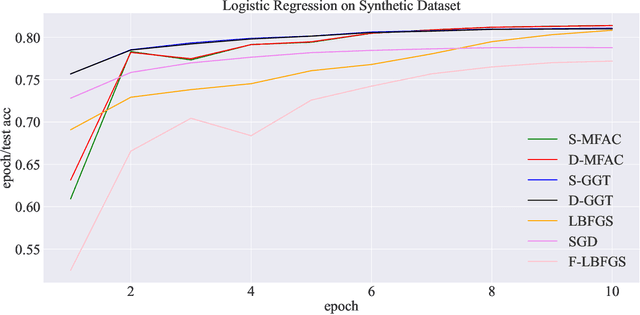
Leveraging second-order information at the scale of deep networks is one of the main lines of approach for improving the performance of current optimizers for deep learning. Yet, existing approaches for accurate full-matrix preconditioning, such as Full-Matrix Adagrad (GGT) or Matrix-Free Approximate Curvature (M-FAC) suffer from massive storage costs when applied even to medium-scale models, as they must store a sliding window of gradients, whose memory requirements are multiplicative in the model dimension. In this paper, we address this issue via an efficient and simple-to-implement error-feedback technique that can be applied to compress preconditioners by up to two orders of magnitude in practice, without loss of convergence. Specifically, our approach compresses the gradient information via sparsification or low-rank compression \emph{before} it is fed into the preconditioner, feeding the compression error back into future iterations. Extensive experiments on deep neural networks for vision show that this approach can compress full-matrix preconditioners by up to two orders of magnitude without impact on accuracy, effectively removing the memory overhead of full-matrix preconditioning for implementations of full-matrix Adagrad (GGT) and natural gradient (M-FAC). Our code is available at https://github.com/IST-DASLab/EFCP.