 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual-Temporal LSTM with Hybrid Attention for Airline Passenger Load Factor Forecasting: Integrating Intra-Flight and Inter-Flight Booking Dynamics
May 12, 2026Accurate short-term demand forecasting is crucial to airline revenue management, yet most existing systems fail to meet this need because current models treat booking data as a single temporal dimension, either the accumulation of bookings for a specific flight or the historical booking profile of the same route. This unidimensional view discards information carried by the other temporal stream and forecasting absolute passenger counts introduces a further operational fragility when change in planned aircraft type alters total seat capacity. This study addresses both limitations. A dual-stream Long Short-Term Memory (LSTM) integrated with attention framework is proposed that simultaneously processes two complementary input sequences: a horizontal sequence capturing intra-flight booking accumulation over the days preceding departure, and a vertical sequence capturing inter-flight booking patterns at fixed days-before-departure offsets across historical flights. Multiple dual-stream architectural variants, combining self-attention, cross-attention, and hybrid attention with concatenation, residual, and gated fusion strategies, are developed and evaluated. Experiments on real-world reservation data from the national airline of Bangladesh, Biman Bangladesh Airlines (BBA), demonstrate that the proposed hybrid model achieves a Mean Absolute Error of 2.8167 and a coefficient of determination ($R^{2}$) of 0.9495, outperforming single-stream baselines, tree-based models, and three prior dual-LSTM architectures applied to the same data. Validation across four flight category pairs; domestic versus international, direct versus transit, high versus low frequency, and short versus mid versus long haul confirms that the model generalizes across operationally diverse route types. Biman Bangladesh Airlines (BBA) has officially integrated this methodology into its operations.
Few-Shot Learning Pipeline for Monkeypox Skin Disease Classification Using CNN Feature Extractors
May 06, 2026Despite the strong performance of Convolutional Neural Networks (CNNs) in disease classification, their effectiveness often depends on access to large annotated datasets, which is an impractical requirement for emerging or rare conditions such as Monkeypox. To overcome this limitation, we propose a few-shot learning (FSL) framework that employs SimpleShot, a lightweight, non-parametric, inductive classifier, for Monkeypox and pox-like skin disease recognition from limited labeled examples. The proposed pipeline passes the skin lesion images through a frozen, pretrained CNN backbone to obtain feature embeddings, which are then classified via SimpleShot using nearest-centroid comparisons in a normalized embedding space. We systematically benchmark six widely used CNN backbones as feature extractors under consistent experimental settings, enabling fair comparison. Experiments on three publicly available datasets (MSLD v1.0, MSID, and MSLD v2.0) are conducted across 2-way, 4-way, and 6-way tasks with 1-shot, 5-shot, and 10-shot configurations. Among all models, MobileNetV2_100 consistently achieves the highest accuracy. In addition, we present a cross-dataset evaluation for Monkeypox classification, revealing that binary Mpox-vs-Others transfer remains comparatively stable while multi-class performance degrades significantly under domain shift. Together, these results demonstrate the practical utility of combining inductive FSL methods with lightweight CNN backbones and highlight the importance of domain robustness for reliable real-world clinical deployment.
A Domain-Adapted Lightweight Ensemble for Resource-Efficient Few-Shot Plant Disease Classification
Dec 15, 2025Accurate and timely identification of plant leaf diseases is essential for resilient and sustainable agriculture, yet most deep learning approaches rely on large annotated datasets and computationally intensive models that are unsuitable for data-scarce and resource-constrained environments. To address these challenges we present a few-shot learning approach within a lightweight yet efficient framework that combines domain-adapted MobileNetV2 and MobileNetV3 models as feature extractors, along with a feature fusion technique to generate robust feature representation. For the classification task, the fused features are passed through a Bi-LSTM classifier enhanced with attention mechanisms to capture sequential dependencies and focus on the most relevant features, thereby achieving optimal classification performance even in complex, real-world environments with noisy or cluttered backgrounds. The proposed framework was evaluated across multiple experimental setups, including both laboratory-controlled and field-captured datasets. On tomato leaf diseases from the PlantVillage dataset, it consistently improved performance across 1 to 15 shot scenarios, reaching 98.23+-0.33% at 15 shot, closely approaching the 99.98% SOTA benchmark achieved by a Transductive LSTM with attention, while remaining lightweight and mobile-friendly. Under real-world conditions using field images from the Dhan Shomadhan dataset, it maintained robust performance, reaching 69.28+-1.49% at 15-shot and demonstrating strong resilience to complex backgrounds. Notably, it also outperformed the previous SOTA accuracy of 96.0% on six diseases from PlantVillage, achieving 99.72% with only 15-shot learning. With a compact model size of approximately 40 MB and inference complexity of approximately 1.12 GFLOPs, this work establishes a scalable, mobile-ready foundation for precise plant disease diagnostics in data-scarce regions.
SCReedSolo: A Secure and Robust LSB Image Steganography Framework with Randomized Symmetric Encryption and Reed-Solomon Coding
Mar 16, 2025



Image steganography is an information-hiding technique that involves the surreptitious concealment of covert informational content within digital images. In this paper, we introduce ${\rm SCR{\small EED}S{\small OLO}}$, a novel framework for concealing arbitrary binary data within images. Our approach synergistically leverages Random Shuffling, Fernet Symmetric Encryption, and Reed-Solomon Error Correction Codes to encode the secret payload, which is then discretely embedded into the carrier image using LSB (Least Significant Bit) Steganography. The combination of these methods addresses the vulnerability vectors of both security and resilience against bit-level corruption in the resultant stego-images. We show that our framework achieves a data payload of 3 bits per pixel for an RGB image, and mathematically assess the probability of successful transmission for the amalgamated $n$ message bits and $k$ error correction bits. Additionally, we find that ${\rm SCR{\small EED}S{\small OLO}}$ yields good results upon being evaluated with multiple performance metrics, successfully eludes detection by various passive steganalysis tools, and is immune to simple active steganalysis attacks. Our code and data are available at https://github.com/Starscream-11813/SCReedSolo-Steganography.
AttResDU-Net: Medical Image Segmentation Using Attention-based Residual Double U-Net
Jun 25, 2023Manually inspecting polyps from a colonoscopy for colorectal cancer or performing a biopsy on skin lesions for skin cancer are time-consuming, laborious, and complex procedures. Automatic medical image segmentation aims to expedite this diagnosis process. However, numerous challenges exist due to significant variations in the appearance and sizes of objects with no distinct boundaries. This paper proposes an attention-based residual Double U-Net architecture (AttResDU-Net) that improves on the existing medical image segmentation networks. Inspired by the Double U-Net, this architecture incorporates attention gates on the skip connections and residual connections in the convolutional blocks. The attention gates allow the model to retain more relevant spatial information by suppressing irrelevant feature representation from the down-sampling path for which the model learns to focus on target regions of varying shapes and sizes. Moreover, the residual connections help to train deeper models by ensuring better gradient flow. We conducted experiments on three datasets: CVC Clinic-DB, ISIC 2018, and the 2018 Data Science Bowl datasets and achieved Dice Coefficient scores of 94.35%, 91.68% and 92.45% respectively. Our results suggest that AttResDU-Net can be facilitated as a reliable method for automatic medical image segmentation in practice.
Interpretable Multi Labeled Bengali Toxic Comments Classification using Deep Learning
Apr 08, 2023



This paper presents a deep learning-based pipeline for categorizing Bengali toxic comments, in which at first a binary classification model is used to determine whether a comment is toxic or not, and then a multi-label classifier is employed to determine which toxicity type the comment belongs to. For this purpose, we have prepared a manually labeled dataset consisting of 16,073 instances among which 8,488 are Toxic and any toxic comment may correspond to one or more of the six toxic categories - vulgar, hate, religious, threat, troll, and insult simultaneously. Long Short Term Memory (LSTM) with BERT Embedding achieved 89.42% accuracy for the binary classification task while as a multi-label classifier, a combination of Convolutional Neural Network and Bi-directional Long Short Term Memory (CNN-BiLSTM) with attention mechanism achieved 78.92% accuracy and 0.86 as weighted F1-score. To explain the predictions and interpret the word feature importance during classification by the proposed models, we utilized Local Interpretable Model-Agnostic Explanations (LIME) framework. We have made our dataset public and can be accessed at - https://github.com/deepu099cse/Multi-Labeled-Bengali-Toxic-Comments-Classification
Huruf: An Application for Arabic Handwritten Character Recognition Using Deep Learning
Dec 24, 2022



Handwriting Recognition has been a field of great interest in the Artificial Intelligence domain. Due to its broad use cases in real life, research has been conducted widely on it. Prominent work has been done in this field focusing mainly on Latin characters. However, the domain of Arabic handwritten character recognition is still relatively unexplored. The inherent cursive nature of the Arabic characters and variations in writing styles across individuals makes the task even more challenging. We identified some probable reasons behind this and proposed a lightweight Convolutional Neural Network-based architecture for recognizing Arabic characters and digits. The proposed pipeline consists of a total of 18 layers containing four layers each for convolution, pooling, batch normalization, dropout, and finally one Global average pooling and a Dense layer. Furthermore, we thoroughly investigated the different choices of hyperparameters such as the choice of the optimizer, kernel initializer, activation function, etc. Evaluating the proposed architecture on the publicly available 'Arabic Handwritten Character Dataset (AHCD)' and 'Modified Arabic handwritten digits Database (MadBase)' datasets, the proposed model respectively achieved an accuracy of 96.93% and 99.35% which is comparable to the state-of-the-art and makes it a suitable solution for real-life end-level applications.
Performance Analysis of YOLO-based Architectures for Vehicle Detection from Traffic Images in Bangladesh
Dec 24, 2022



The task of locating and classifying different types of vehicles has become a vital element in numerous applications of automation and intelligent systems ranging from traffic surveillance to vehicle identification and many more. In recent times, Deep Learning models have been dominating the field of vehicle detection. Yet, Bangladeshi vehicle detection has remained a relatively unexplored area. One of the main goals of vehicle detection is its real-time application, where `You Only Look Once' (YOLO) models have proven to be the most effective architecture. In this work, intending to find the best-suited YOLO architecture for fast and accurate vehicle detection from traffic images in Bangladesh, we have conducted a performance analysis of different variants of the YOLO-based architectures such as YOLOV3, YOLOV5s, and YOLOV5x. The models were trained on a dataset containing 7390 images belonging to 21 types of vehicles comprising samples from the DhakaAI dataset, the Poribohon-BD dataset, and our self-collected images. After thorough quantitative and qualitative analysis, we found the YOLOV5x variant to be the best-suited model, performing better than YOLOv3 and YOLOv5s models respectively by 7 & 4 percent in mAP, and 12 & 8.5 percent in terms of Accuracy.
Land Cover and Land Use Detection using Semi-Supervised Learning
Dec 21, 2022Semi-supervised learning (SSL) has made significant strides in the field of remote sensing. Finding a large number of labeled datasets for SSL methods is uncommon, and manually labeling datasets is expensive and time-consuming. Furthermore, accurately identifying remote sensing satellite images is more complicated than it is for conventional images. Class-imbalanced datasets are another prevalent phenomenon, and models trained on these become biased towards the majority classes. This becomes a critical issue with an SSL model's subpar performance. We aim to address the issue of labeling unlabeled data and also solve the model bias problem due to imbalanced datasets while achieving better accuracy. To accomplish this, we create "artificial" labels and train a model to have reasonable accuracy. We iteratively redistribute the classes through resampling using a distribution alignment technique. We use a variety of class imbalanced satellite image datasets: EuroSAT, UCM, and WHU-RS19. On UCM balanced dataset, our method outperforms previous methods MSMatch and FixMatch by 1.21% and 0.6%, respectively. For imbalanced EuroSAT, our method outperforms MSMatch and FixMatch by 1.08% and 1%, respectively. Our approach significantly lessens the requirement for labeled data, consistently outperforms alternative approaches, and resolves the issue of model bias caused by class imbalance in datasets.
Multiple Object Tracking in Recent Times: A Literature Review
Sep 11, 2022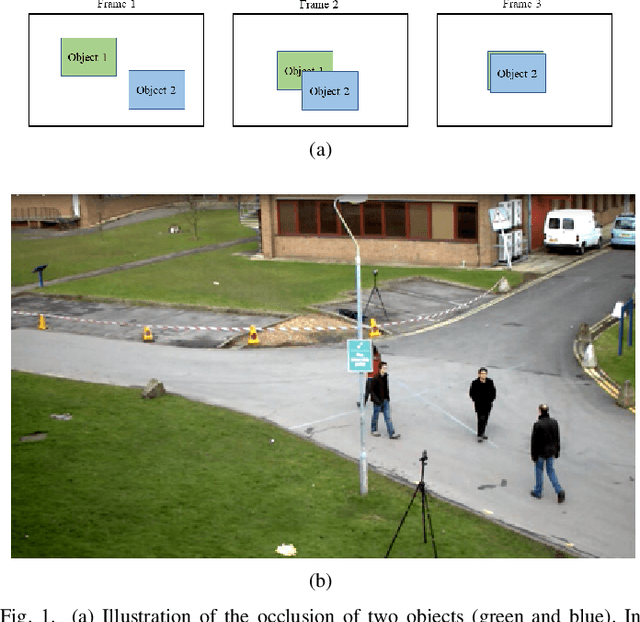
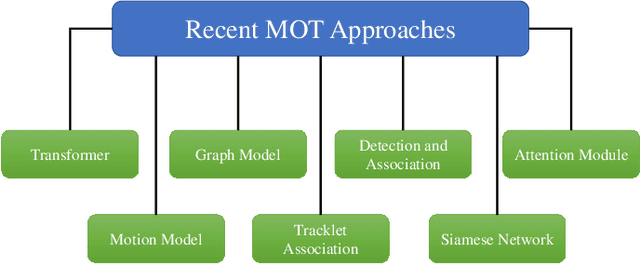
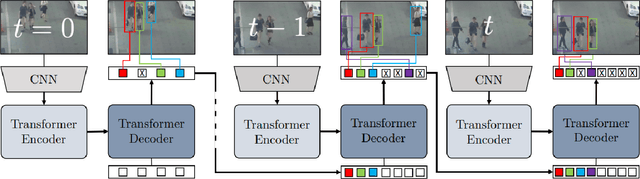
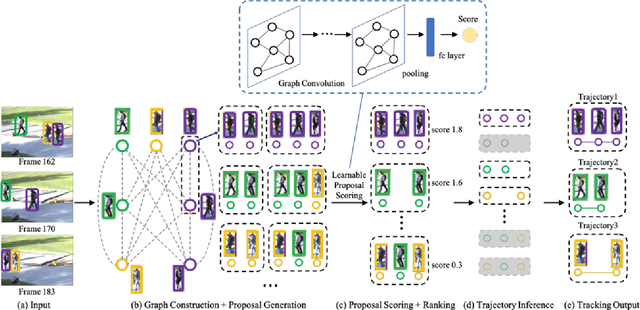
Multiple object tracking gained a lot of interest from researchers in recent years, and it has become one of the trending problems in computer vision, especially with the recent advancement of autonomous driving. MOT is one of the critical vision tasks for different issues like occlusion in crowded scenes, similar appearance, small object detection difficulty, ID switching, etc. To tackle these challenges, as researchers tried to utilize the attention mechanism of transformer, interrelation of tracklets with graph convolutional neural network, appearance similarity of objects in different frames with the siamese network, they also tried simple IOU matching based CNN network, motion prediction with LSTM. To take these scattered techniques under an umbrella, we have studied more than a hundred papers published over the last three years and have tried to extract the techniques that are more focused on by researchers in recent times to solve the problems of MOT. We have enlisted numerous applications, possibilities, and how MOT can be related to real life. Our review has tried to show the different perspectives of techniques that researchers used overtimes and give some future direction for the potential researchers. Moreover, we have included popular benchmark datasets and metrics in this review.