 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A Cloud-based Machine Learning Pipeline for the Efficient Extraction of Insights from Customer Reviews
Jun 13, 2023
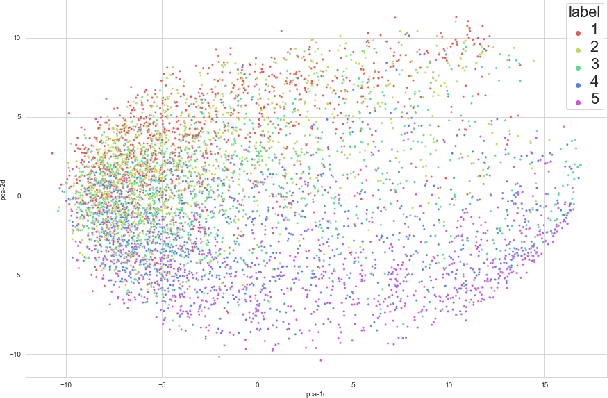
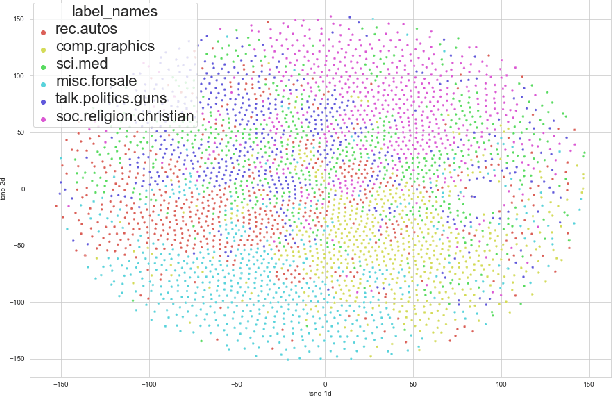
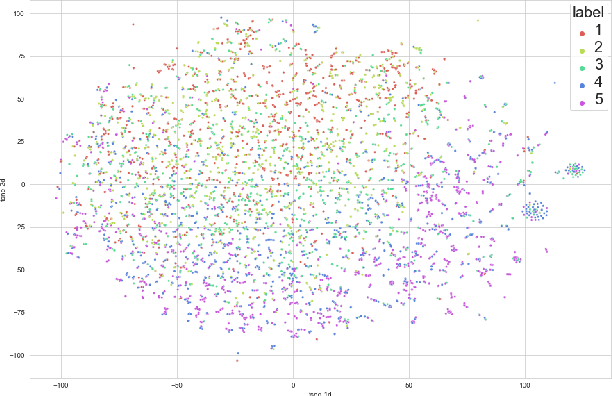

The efficiency of natural language processing has improved dramatically with the advent of machine learning models, particularly neural network-based solutions. However, some tasks are still challenging, especially when considering specific domains. In this paper, we present a cloud-based system that can extract insights from customer reviews using machine learning methods integrated into a pipeline. For topic modeling, our composite model uses transformer-based neural networks designed for natural language processing, vector embedding-based keyword extraction, and clustering. The elements of our model have been integrated and further developed to meet better the requirements of efficient information extraction, topic modeling of the extracted information, and user needs. Furthermore, our system can achieve better results than this task's existing topic modeling and keyword extraction solutions. Our approach is validated and compared with other state-of-the-art methods using publicly available datasets for benchmarking.
Multi-task Collaborative Pre-training and Individual-adaptive-tokens Fine-tuning: A Unified Framework for Brain Representation Learning
Jun 20, 2023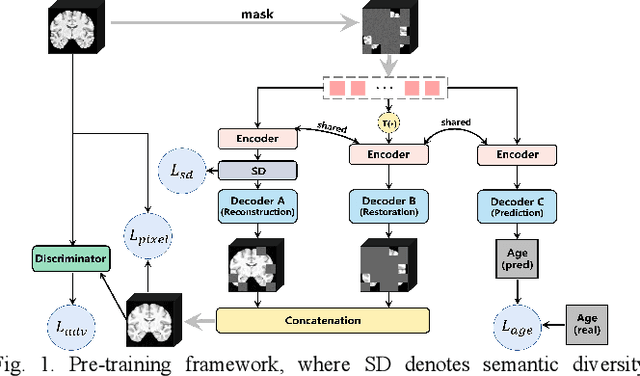
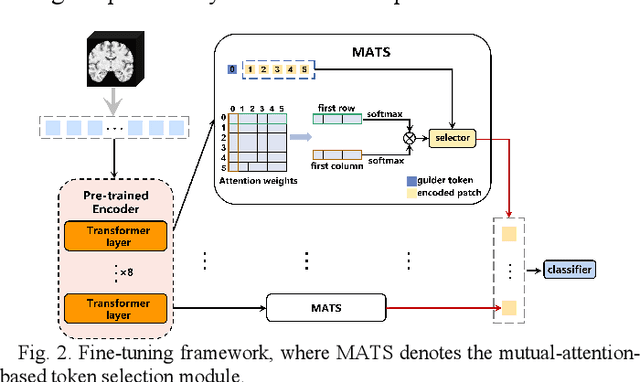
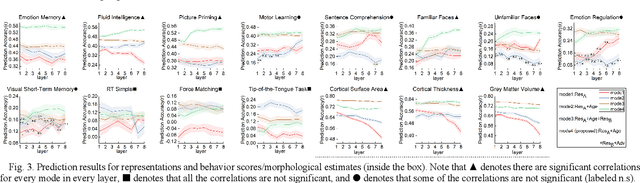
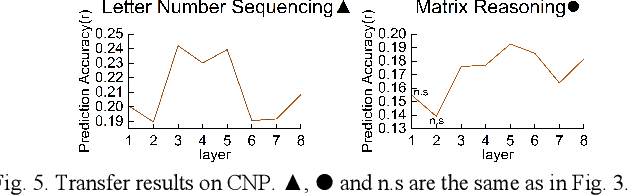
Structural magnetic resonance imaging (sMRI) provides accurate estimates of the brain's structural organization and learning invariant brain representations from sMRI is an enduring issue in neuroscience. Previous deep representation learning models ignore the fact that the brain, as the core of human cognitive activity, is distinct from other organs whose primary attribute is anatomy. Therefore, capturing the semantic structure that dominates interindividual cognitive variability is key to accurately representing the brain. Given that this high-level semantic information is subtle, distributed, and interdependently latent in the brain structure, sMRI-based models need to capture fine-grained details and understand how they relate to the overall global structure. However, existing models are optimized by simple objectives, making features collapse into homogeneity and worsening simultaneous representation of fine-grained information and holistic semantics, causing a lack of biological plausibility and interpretation of cognition. Here, we propose MCIAT, a unified framework that combines Multi-task Collaborative pre-training and Individual-Adaptive-Tokens fine-tuning. Specifically, we first synthesize restorative learning, age prediction auxiliary learning and adversarial learning as a joint proxy task for deep semantic representation learning. Then, a mutual-attention-based token selection method is proposed to highlight discriminative features. The proposed MCIAT achieves state-of-the-art diagnosis performance on the ADHD-200 dataset compared with several sMRI-based approaches and shows superior generalization on the MCIC and OASIS datasets. Moreover, we studied 12 behavioral tasks and found significant associations between cognitive functions and MCIAT-established representations, which verifies the interpretability of our proposed framework.
A Framework for Fast and Stable Representations of Multiparameter Persistent Homology Decompositions
Jun 19, 2023
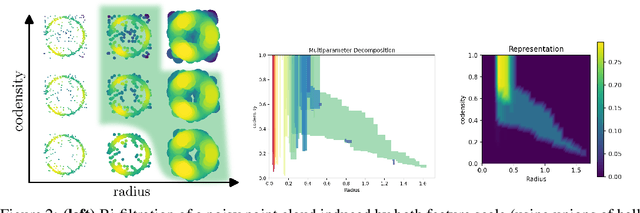
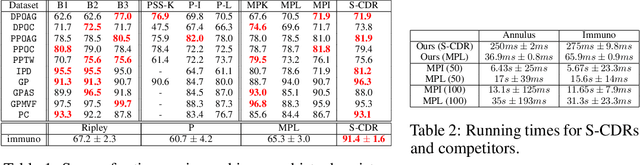
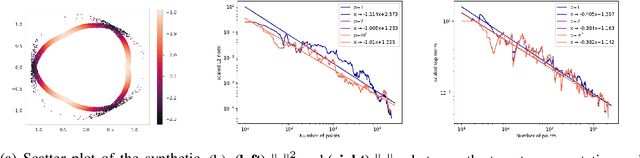
Topological data analysis (TDA) is an area of data science that focuses on using invariants from algebraic topology to provide multiscale shape descriptors for geometric data sets such as point clouds. One of the most important such descriptors is {\em persistent homology}, which encodes the change in shape as a filtration parameter changes; a typical parameter is the feature scale. For many data sets, it is useful to simultaneously vary multiple filtration parameters, for example feature scale and density. While the theoretical properties of single parameter persistent homology are well understood, less is known about the multiparameter case. In particular, a central question is the problem of representing multiparameter persistent homology by elements of a vector space for integration with standard machine learning algorithms. Existing approaches to this problem either ignore most of the multiparameter information to reduce to the one-parameter case or are heuristic and potentially unstable in the face of noise. In this article, we introduce a new general representation framework that leverages recent results on {\em decompositions} of multiparameter persistent homology. This framework is rich in information, fast to compute, and encompasses previous approaches. Moreover, we establish theoretical stability guarantees under this framework as well as efficient algorithms for practical computation, making this framework an applicable and versatile tool for analyzing geometric and point cloud data. We validate our stability results and algorithms with numerical experiments that demonstrate statistical convergence, prediction accuracy, and fast running times on several real data sets.
Temporal Data Meets LLM -- Explainable Financial Time Series Forecasting
Jun 19, 2023
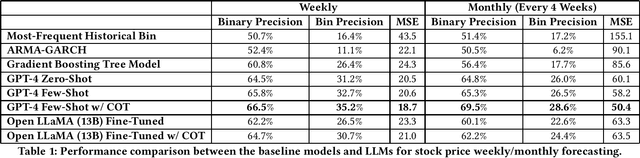


This paper presents a novel study on harnessing Large Language Models' (LLMs) outstanding knowledge and reasoning abilities for explainable financial time series forecasting. The application of machine learning models to financial time series comes with several challenges, including the difficulty in cross-sequence reasoning and inference, the hurdle of incorporating multi-modal signals from historical news, financial knowledge graphs, etc., and the issue of interpreting and explaining the model results. In this paper, we focus on NASDAQ-100 stocks, making use of publicly accessible historical stock price data, company metadata, and historical economic/financial news. We conduct experiments to illustrate the potential of LLMs in offering a unified solution to the aforementioned challenges. Our experiments include trying zero-shot/few-shot inference with GPT-4 and instruction-based fine-tuning with a public LLM model Open LLaMA. We demonstrate our approach outperforms a few baselines, including the widely applied classic ARMA-GARCH model and a gradient-boosting tree model. Through the performance comparison results and a few examples, we find LLMs can make a well-thought decision by reasoning over information from both textual news and price time series and extracting insights, leveraging cross-sequence information, and utilizing the inherent knowledge embedded within the LLM. Additionally, we show that a publicly available LLM such as Open-LLaMA, after fine-tuning, can comprehend the instruction to generate explainable forecasts and achieve reasonable performance, albeit relatively inferior in comparison to GPT-4.
FHA-Kitchens: A Novel Dataset for Fine-Grained Hand Action Recognition in Kitchen Scenes
Jun 19, 2023
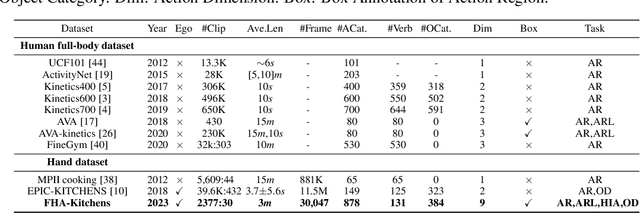


A typical task in the field of video understanding is hand action recognition, which has a wide range of applications. Existing works either mainly focus on full-body actions, or the defined action categories are relatively coarse-grained. In this paper, we propose FHA-Kitchens, a novel dataset of fine-grained hand actions in kitchen scenes. In particular, we focus on human hand interaction regions and perform deep excavation to further refine hand action information and interaction regions. Our FHA-Kitchens dataset consists of 2,377 video clips and 30,047 images collected from 8 different types of dishes, and all hand interaction regions in each image are labeled with high-quality fine-grained action classes and bounding boxes. We represent the action information in each hand interaction region as a triplet, resulting in a total of 878 action triplets. Based on the constructed dataset, we benchmark representative action recognition and detection models on the following three tracks: (1) supervised learning for hand interaction region and object detection, (2) supervised learning for fine-grained hand action recognition, and (3) intra- and inter-class domain generalization for hand interaction region detection. The experimental results offer compelling empirical evidence that highlights the challenges inherent in fine-grained hand action recognition, while also shedding light on potential avenues for future research, particularly in relation to pre-training strategy, model design, and domain generalization. The dataset will be released at https://github.com/tingZ123/FHA-Kitchens.
Variational Information Pursuit for Interpretable Predictions
Feb 06, 2023

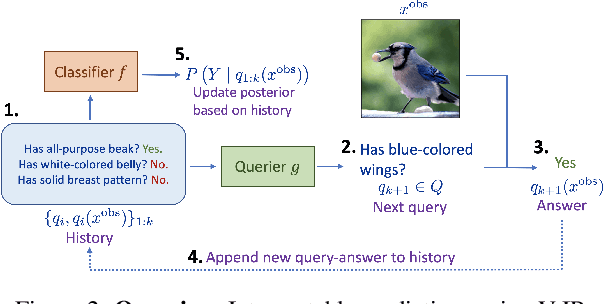
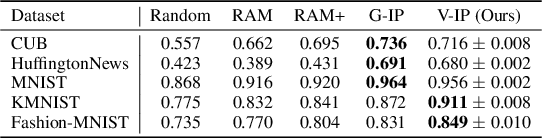
There is a growing interest in the machine learning community in developing predictive algorithms that are "interpretable by design". Towards this end, recent work proposes to make interpretable decisions by sequentially asking interpretable queries about data until a prediction can be made with high confidence based on the answers obtained (the history). To promote short query-answer chains, a greedy procedure called Information Pursuit (IP) is used, which adaptively chooses queries in order of information gain. Generative models are employed to learn the distribution of query-answers and labels, which is in turn used to estimate the most informative query. However, learning and inference with a full generative model of the data is often intractable for complex tasks. In this work, we propose Variational Information Pursuit (V-IP), a variational characterization of IP which bypasses the need for learning generative models. V-IP is based on finding a query selection strategy and a classifier that minimizes the expected cross-entropy between true and predicted labels. We then demonstrate that the IP strategy is the optimal solution to this problem. Therefore, instead of learning generative models, we can use our optimal strategy to directly pick the most informative query given any history. We then develop a practical algorithm by defining a finite-dimensional parameterization of our strategy and classifier using deep networks and train them end-to-end using our objective. Empirically, V-IP is 10-100x faster than IP on different Vision and NLP tasks with competitive performance. Moreover, V-IP finds much shorter query chains when compared to reinforcement learning which is typically used in sequential-decision-making problems. Finally, we demonstrate the utility of V-IP on challenging tasks like medical diagnosis where the performance is far superior to the generative modelling approach.
Information-Theoretic Study of Time-Domain Energy-Saving Techniques in Radio Access
Mar 31, 2023Reduction of wireless network energy consumption is becoming increasingly important to reduce environmental footprint and operational costs. A key concept to achieve it is the use of lean transmission techniques that dynamically (de)activate hardware resources as a function of the load. In this paper, we propose a pioneering information-theoretic study of time-domain energy-saving techniques, relying on a practical hardware power consumption model of sleep and active modes. By minimizing the power consumption under a quality of service constraint (rate, latency), we propose simple yet powerful techniques to allocate power and choose which resources to activate or to put in sleep mode. Power consumption scaling regimes are identified. We show that a ``rush-to-sleep" approach (maximal power in fewest symbols followed by sleep) is only optimal in a high noise regime. It is shown how consumption can be made linear with the load and achieve massive energy reduction (factor of 10) at low-to-medium load. The trade-off between energy efficiency (EE) and spectral efficiency (SE) is also characterized, followed by a multi-user study based on time division multiple access (TDMA).
Can Pre-trained Vision and Language Models Answer Visual Information-Seeking Questions?
Feb 23, 2023

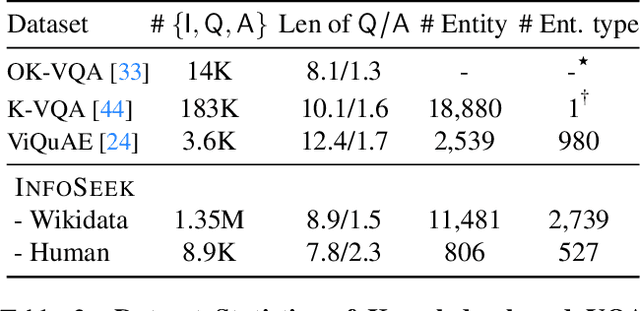

Large language models have demonstrated an emergent capability in answering knowledge intensive questions. With recent progress on web-scale visual and language pre-training, do these models also understand how to answer visual information seeking questions? To answer this question, we present InfoSeek, a Visual Question Answering dataset that focuses on asking information-seeking questions, where the information can not be answered by common sense knowledge. We perform a multi-stage human annotation to collect a natural distribution of high-quality visual information seeking question-answer pairs. We also construct a large-scale, automatically collected dataset by combining existing visual entity recognition datasets and Wikidata, which provides over one million examples for model fine-tuning and validation. Based on InfoSeek, we analyzed various pre-trained Visual QA systems to gain insights into the characteristics of different pre-trained models. Our analysis shows that it is challenging for the state-of-the-art multi-modal pre-trained models to answer visual information seeking questions, but this capability is improved through fine-tuning on the automated InfoSeek dataset. We hope our analysis paves the way to understand and develop the next generation of multi-modal pre-training.
AI-Generated Image Detection using a Cross-Attention Enhanced Dual-Stream Network
Jun 12, 2023

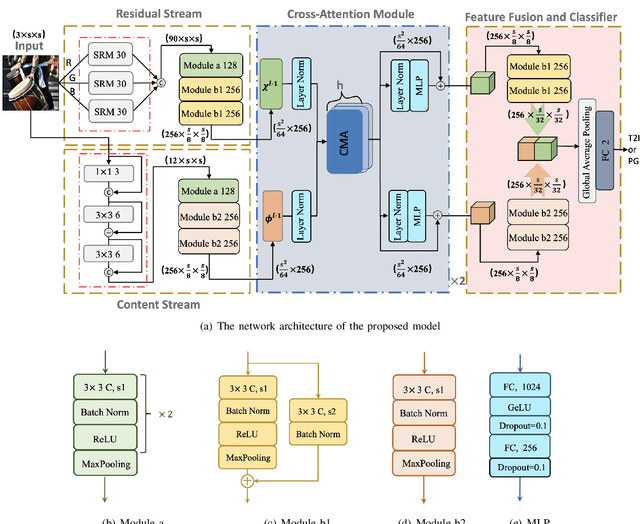

With the rapid evolution of AI Generated Content (AIGC), forged images produced through this technology are inherently more deceptive and require less human intervention compared to traditional Computer-generated Graphics (CG). However, owing to the disparities between CG and AIGC, conventional CG detection methods tend to be inadequate in identifying AIGC-produced images. To address this issue, our research concentrates on the text-to-image generation process in AIGC. Initially, we first assemble two text-to-image databases utilizing two distinct AI systems, DALLE2 and DreamStudio. Aiming to holistically capture the inherent anomalies produced by AIGC, we develope a robust dual-stream network comprised of a residual stream and a content stream. The former employs the Spatial Rich Model (SRM) to meticulously extract various texture information from images, while the latter seeks to capture additional forged traces in low frequency, thereby extracting complementary information that the residual stream may overlook. To enhance the information exchange between these two streams, we incorporate a cross multi-head attention mechanism. Numerous comparative experiments are performed on both databases, and the results show that our detection method consistently outperforms traditional CG detection techniques across a range of image resolutions. Moreover, our method exhibits superior performance through a series of robustness tests and cross-database experiments. When applied to widely recognized traditional CG benchmarks such as SPL2018 and DsTok, our approach significantly exceeds the capabilities of other existing methods in the field of CG detection.
Improving Spherical Image Resampling through Viewport-Adaptivity
Jun 23, 2023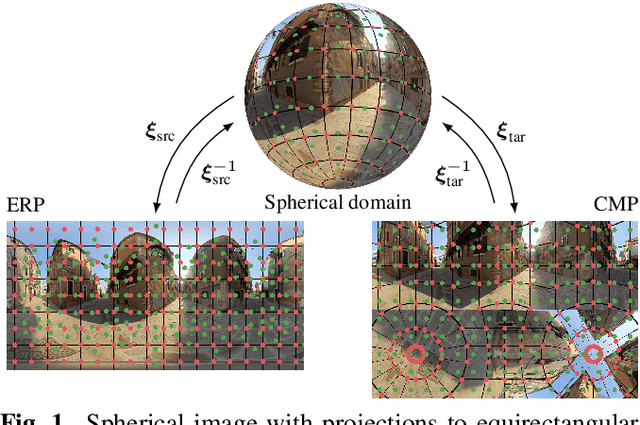
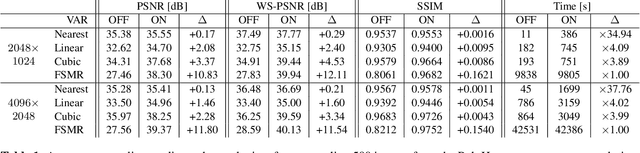
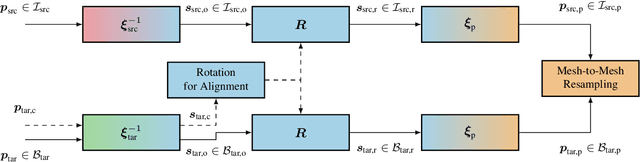
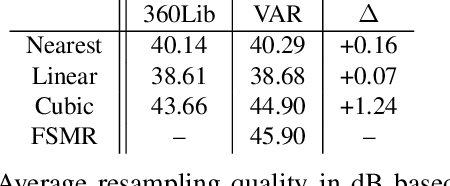
The conversion between different spherical image and video projection formats requires highly accurate resampling techniques in order to minimize the inevitable loss of information. Suitable resampling algorithms such as nearest neighbor, linear or cubic resampling are readily available. However, no generally applicable resampling technique exploits the special properties of spherical images so far. Thus, we propose a novel viewport-adaptive resampling (VAR) technique that takes the spherical characteristics of the underlying resampling problem into account. VAR can be applied to any mesh-to-mesh capable resampling algorithm and shows significant gains across all tested techniques. In combination with frequency-selective resampling, VAR outperforms conventional cubic resampling by more than 2 dB in terms of WS-PSNR. A visual inspection and the evaluation of further metrics such as PSNR and SSIM support the positive results.