 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating the performance of Retrieval-Augmented Generation and fine-tuning for the development of AI-driven knowledge-based systems
Mar 12, 2024



The development of generative large language models (G-LLM) opened up new opportunities for the development of new types of knowledge-based systems similar to ChatGPT, Bing, or Gemini. Fine-tuning (FN) and Retrieval-Augmented Generation (RAG) are the techniques that can be used to implement domain adaptation for the development of G-LLM-based knowledge systems. In our study, using ROUGE, BLEU, METEOR scores, and cosine similarity, we compare and examine the performance of RAG and FN for the GPT-J-6B, OPT-6.7B, LlaMA, LlaMA-2 language models. Based on measurements shown on different datasets, we demonstrate that RAG-based constructions are more efficient than models produced with FN. We point out that connecting RAG and FN is not trivial, because connecting FN models with RAG can cause a decrease in performance. Furthermore, we outline a simple RAG-based architecture which, on average, outperforms the FN models by 16% in terms of the ROGUE score, 15% in the case of the BLEU score, and 53% based on the cosine similarity. This shows the significant advantage of RAG over FN in terms of hallucination, which is not offset by the fact that the average 8% better METEOR score of FN models indicates greater creativity compared to RAG.
A multimodal deep learning architecture for smoking detection with a small data approach
Sep 19, 2023Introduction: Covert tobacco advertisements often raise regulatory measures. This paper presents that artificial intelligence, particularly deep learning, has great potential for detecting hidden advertising and allows unbiased, reproducible, and fair quantification of tobacco-related media content. Methods: We propose an integrated text and image processing model based on deep learning, generative methods, and human reinforcement, which can detect smoking cases in both textual and visual formats, even with little available training data. Results: Our model can achieve 74\% accuracy for images and 98\% for text. Furthermore, our system integrates the possibility of expert intervention in the form of human reinforcement. Conclusions: Using the pre-trained multimodal, image, and text processing models available through deep learning makes it possible to detect smoking in different media even with few training data.
A Cloud-based Machine Learning Pipeline for the Efficient Extraction of Insights from Customer Reviews
Jun 18, 2023The efficiency of natural language processing has improved dramatically with the advent of machine learning models, particularly neural network-based solutions. However, some tasks are still challenging, especially when considering specific domains. In this paper, we present a cloud-based system that can extract insights from customer reviews using machine learning methods integrated into a pipeline. For topic modeling, our composite model uses transformer-based neural networks designed for natural language processing, vector embedding-based keyword extraction, and clustering. The elements of our model have been integrated and further developed to meet better the requirements of efficient information extraction, topic modeling of the extracted information, and user needs. Furthermore, our system can achieve better results than this task's existing topic modeling and keyword extraction solutions. Our approach is validated and compared with other state-of-the-art methods using publicly available datasets for benchmarking.
A stochastic approach to handle knapsack problems in the creation of ensembles
Apr 17, 2020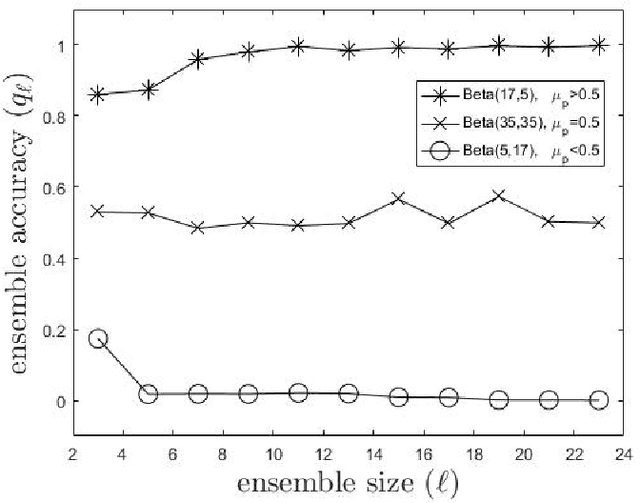
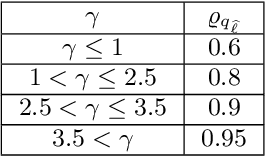
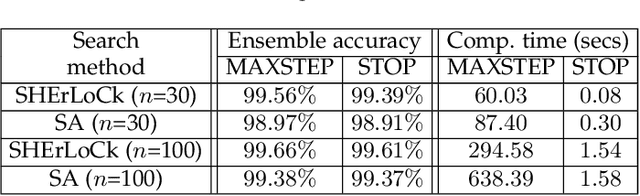
Ensemble-based methods are highly popular approaches that increase the accuracy of a decision by aggregating the opinions of individual voters. The common point is to maximize accuracy; however, a natural limitation occurs if incremental costs are also assigned to the individual voters. Consequently, we investigate creating ensembles under an additional constraint on the total cost of the members. This task can be formulated as a knapsack problem, where the energy is the ensemble accuracy formed by some aggregation rules. However, the generally applied aggregation rules lead to a nonseparable energy function, which takes the common solution tools -- such as dynamic programming -- out of action. We introduce a novel stochastic approach that considers the energy as the joint probability function of the member accuracies. This type of knowledge can be efficiently incorporated in a stochastic search process as a stopping rule, since we have the information on the expected accuracy or, alternatively, the probability of finding more accurate ensembles. Experimental analyses of the created ensembles of pattern classifiers and object detectors confirm the efficiency of our approach. Moreover, we propose a novel stochastic search strategy that better fits the energy, compared with general approaches such as simulated annealing.
Optimizing Majority Voting Based Systems Under a Resource Constraint for Multiclass Problems
Apr 08, 2019Ensemble-based approaches are very effective in various fields in raising the accuracy of its individual members, when some voting rule is applied for aggregating the individual decisions. In this paper, we investigate how to find and characterize the ensembles having the highest accuracy if the total cost of the ensemble members is bounded. This question leads to Knapsack problem with non-linear and non-separable objective function in binary and multiclass classification if the majority voting is chosen for the aggregation. As the conventional solving methods cannot be applied for this task, a novel stochastic approach was introduced in the binary case where the energy function is discussed as the joint probability function of the member accuracy. We show some theoretical results with respect to the expected ensemble accuracy and its variance in the multiclass classification problem which can help us to solve the Knapsack problem.
A Two-phase Decision Support Framework for the Automatic Screening of Digital Fundus Images
Nov 01, 2014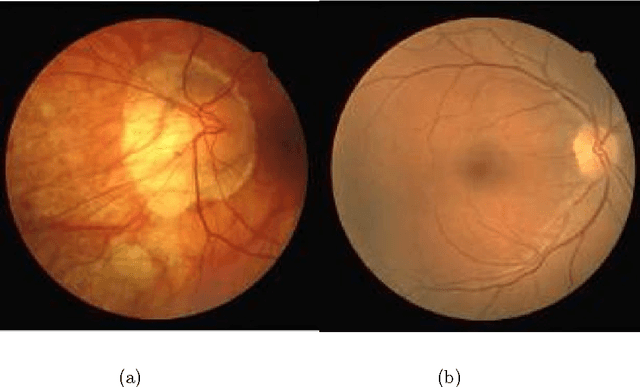
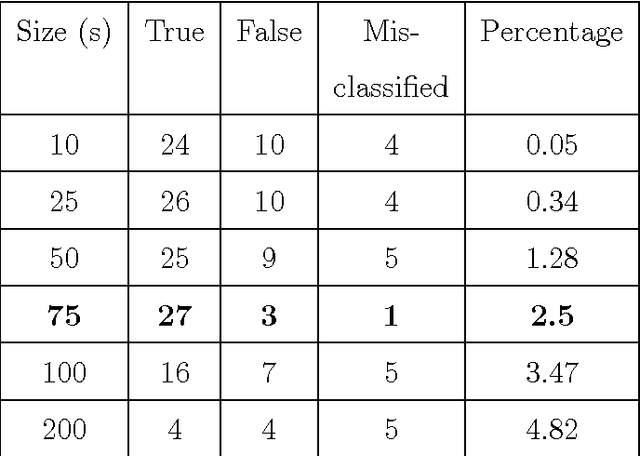

In this paper we give a brief review on the present status of automated detection systems describe for the screening of diabetic retinopathy. We further detail an enhanced detection procedure that consists of two steps. First, a pre-screening algorithm is considered to classify the input digital fundus images based on the severity of abnormalities. If an image is found to be seriously abnormal, it will not be analysed further with robust lesion detector algorithms. As a further improvement, we introduce a novel feature extraction approach based on clinical observations. The second step of the proposed method detects regions of interest with possible lesions on the images that previously passed the pre-screening step. These regions will serve as input to the specific lesion detectors for detailed analysis. This procedure can increase the computational performance of a screening system. Experimental results show that both two steps of the proposed approach are capable to efficiently exclude a large amount of data from further processing, thus, to decrease the computational burden of the automatic screening system.
An Ensemble-based System for Microaneurysm Detection and Diabetic Retinopathy Grading
Oct 30, 2014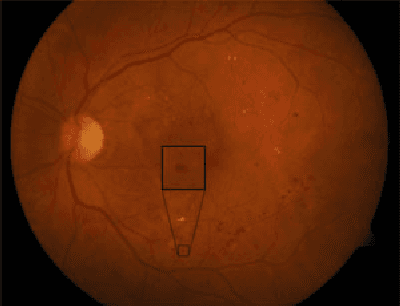
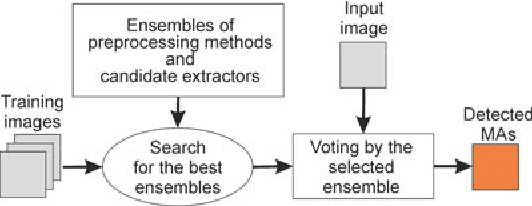

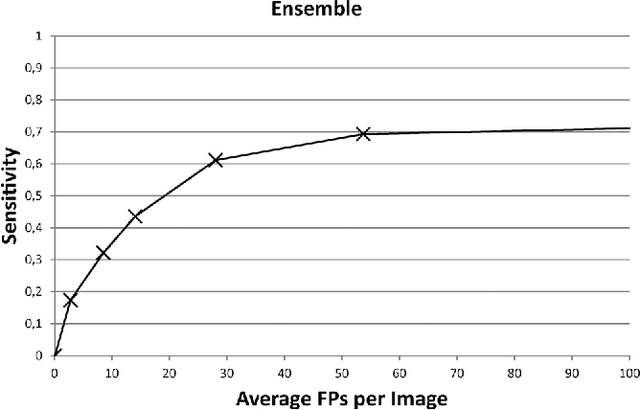
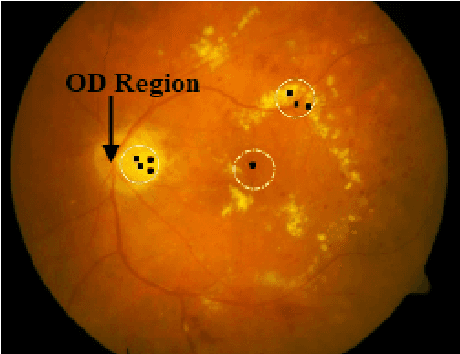
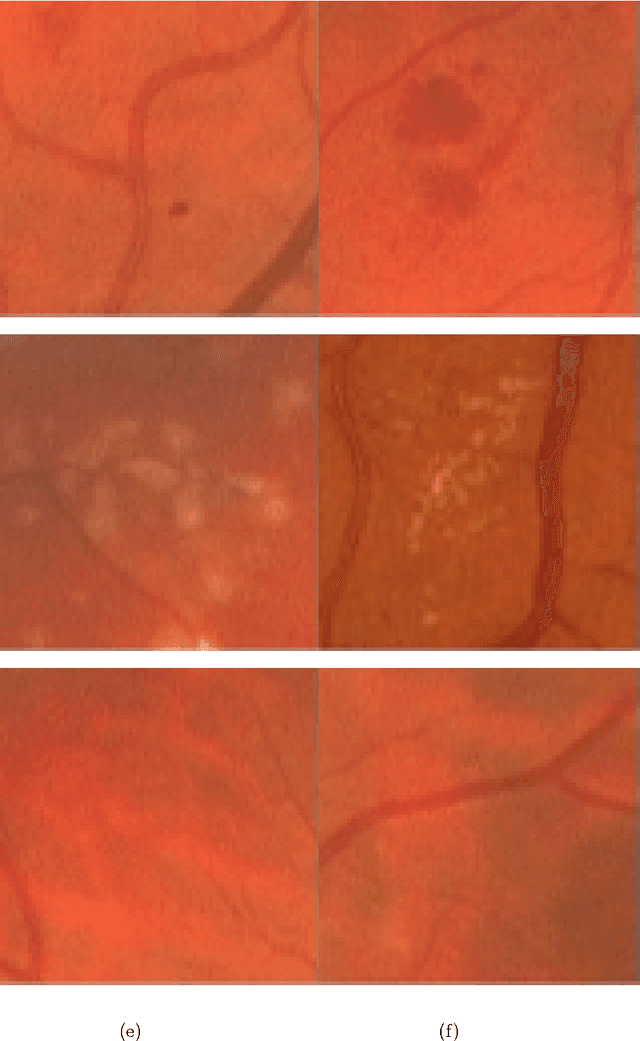
Reliable microaneurysm detection in digital fundus images is still an open issue in medical image processing. We propose an ensemble-based framework to improve microaneurysm detection. Unlike the well-known approach of considering the output of multiple classifiers, we propose a combination of internal components of microaneurysm detectors, namely preprocessing methods and candidate extractors. We have evaluated our approach for microaneurysm detection in an online competition, where this algorithm is currently ranked as first and also on two other databases. Since microaneurysm detection is decisive in diabetic retinopathy grading, we also tested the proposed method for this task on the publicly available Messidor database, where a promising AUC 0.90 with 0.01 uncertainty is achieved in a 'DR/non-DR'-type classification based on the presence or absence of the microaneurysms.
An ensemble-based system for automatic screening of diabetic retinopathy
Oct 30, 2014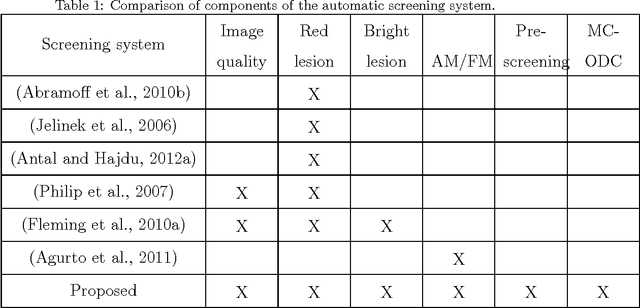
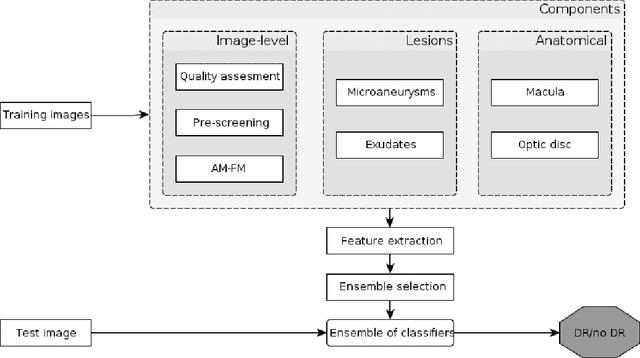

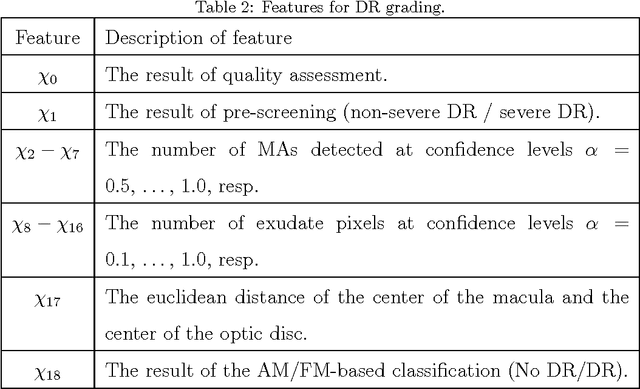
In this paper, an ensemble-based method for the screening of diabetic retinopathy (DR) is proposed. This approach is based on features extracted from the output of several retinal image processing algorithms, such as image-level (quality assessment, pre-screening, AM/FM), lesion-specific (microaneurysms, exudates) and anatomical (macula, optic disc) components. The actual decision about the presence of the disease is then made by an ensemble of machine learning classifiers. We have tested our approach on the publicly available Messidor database, where 90% sensitivity, 91% specificity and 90% accuracy and 0.989 AUC are achieved in a disease/no-disease setting. These results are highly competitive in this field and suggest that retinal image processing is a valid approach for automatic DR screening.
An Unsupervised Ensemble-based Markov Random Field Approach to Microscope Cell Image Segmentation
Oct 27, 2014
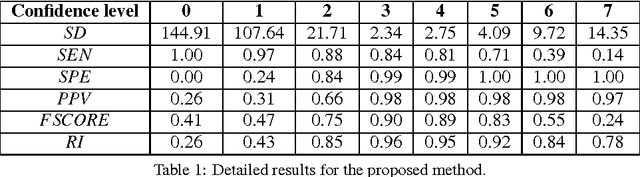

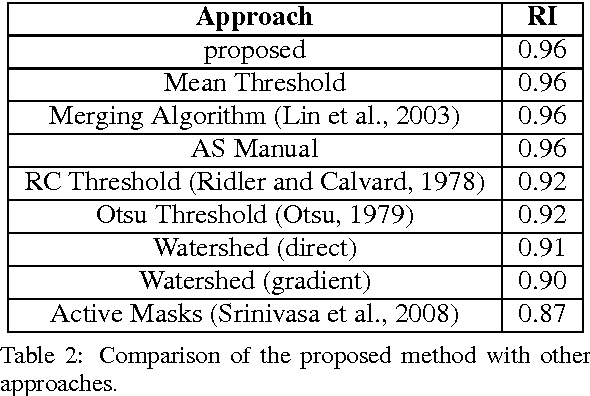
In this paper, we propose an approach to the unsupervised segmentation of images using Markov Random Field. The proposed approach is based on the idea of Bit Plane Slicing. We use the planes as initial labellings for an ensemble of segmentations. With pixelwise voting, a robust segmentation approach can be achieved, which we demonstrate on microscope cell images. We tested our approach on a publicly available database, where it proven to be competitive with other methods and manual segmentation.