 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
MultiVENT: Multilingual Videos of Events with Aligned Natural Text
Jul 06, 2023


Everyday news coverage has shifted from traditional broadcasts towards a wide range of presentation formats such as first-hand, unedited video footage. Datasets that reflect the diverse array of multimodal, multilingual news sources available online could be used to teach models to benefit from this shift, but existing news video datasets focus on traditional news broadcasts produced for English-speaking audiences. We address this limitation by constructing MultiVENT, a dataset of multilingual, event-centric videos grounded in text documents across five target languages. MultiVENT includes both news broadcast videos and non-professional event footage, which we use to analyze the state of online news videos and how they can be leveraged to build robust, factually accurate models. Finally, we provide a model for complex, multilingual video retrieval to serve as a baseline for information retrieval using MultiVENT.
A Synthetic Electrocardiogram (ECG) Image Generation Toolbox to Facilitate Deep Learning-Based Scanned ECG Digitization
Jul 14, 2023

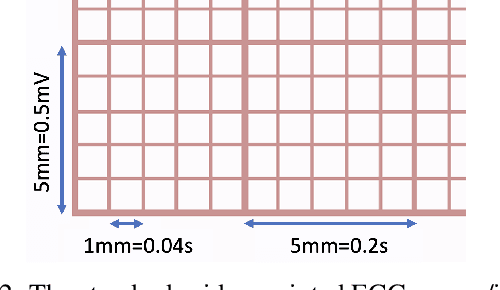
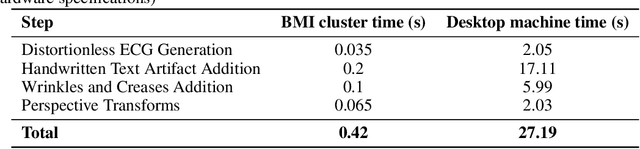
The electrocardiogram (ECG) is an accurate and widely available tool for diagnosing cardiovascular diseases. ECGs have been recorded in printed formats for decades and their digitization holds great potential for training machine learning (ML) models in algorithmic ECG diagnosis. Physical ECG archives are at risk of deterioration and scanning printed ECGs alone is insufficient, as ML models require ECG time-series data. Therefore, the digitization and conversion of paper ECG archives into time-series data is of utmost importance. Deep learning models for image processing show promise in this regard. However, the scarcity of ECG archives with reference time-series is a challenge. Data augmentation techniques utilizing \textit{digital twins} present a potential solution. We introduce a novel method for generating synthetic ECG images on standard paper-like ECG backgrounds with realistic artifacts. Distortions including handwritten text artifacts, wrinkles, creases and perspective transforms are applied to the generated images, without personally identifiable information. As a use case, we generated an ECG image dataset of 21,801 records from the 12-lead PhysioNet PTB-XL ECG time-series dataset. A deep ECG image digitization model was built and trained on the synthetic dataset, and was employed to convert the synthetic images to time-series data for evaluation. The signal-to-noise ratio (SNR) was calculated to assess the image digitization quality vs the ground truth ECG time-series. The results show an average signal recovery SNR of 27$\pm$2.8\,dB, demonstrating the significance of the proposed synthetic ECG image dataset for training deep learning models. The codebase is available as an open-access toolbox for ECG research.
Limited-Memory Greedy Quasi-Newton Method with Non-asymptotic Superlinear Convergence Rate
Jun 27, 2023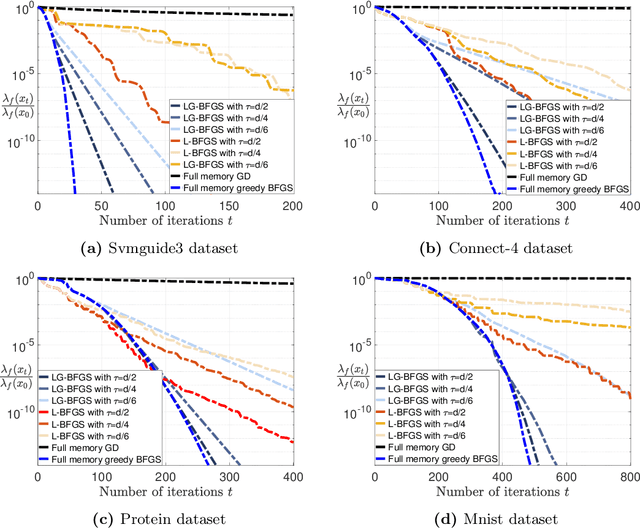

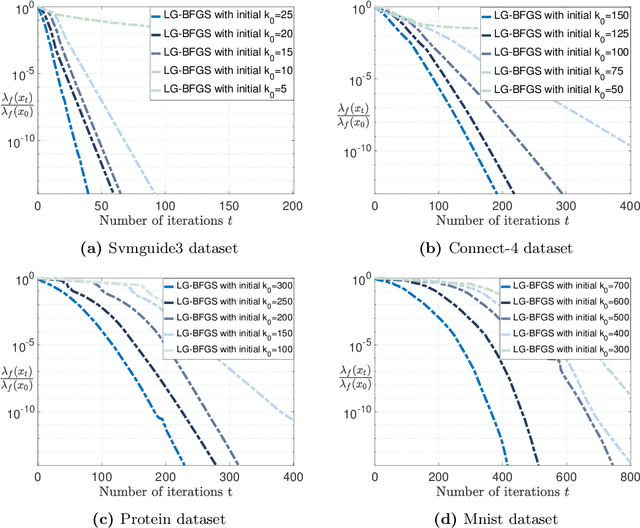
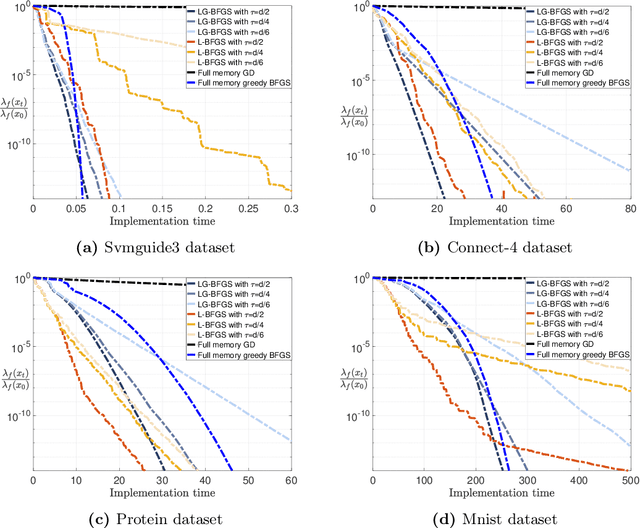
Non-asymptotic convergence analysis of quasi-Newton methods has gained attention with a landmark result establishing an explicit superlinear rate of O$((1/\sqrt{t})^t)$. The methods that obtain this rate, however, exhibit a well-known drawback: they require the storage of the previous Hessian approximation matrix or instead storing all past curvature information to form the current Hessian inverse approximation. Limited-memory variants of quasi-Newton methods such as the celebrated L-BFGS alleviate this issue by leveraging a limited window of past curvature information to construct the Hessian inverse approximation. As a result, their per iteration complexity and storage requirement is O$(\tau d)$ where $\tau \le d$ is the size of the window and $d$ is the problem dimension reducing the O$(d^2)$ computational cost and memory requirement of standard quasi-Newton methods. However, to the best of our knowledge, there is no result showing a non-asymptotic superlinear convergence rate for any limited-memory quasi-Newton method. In this work, we close this gap by presenting a limited-memory greedy BFGS (LG-BFGS) method that achieves an explicit non-asymptotic superlinear rate. We incorporate displacement aggregation, i.e., decorrelating projection, in post-processing gradient variations, together with a basis vector selection scheme on variable variations, which greedily maximizes a progress measure of the Hessian estimate to the true Hessian. Their combination allows past curvature information to remain in a sparse subspace while yielding a valid representation of the full history. Interestingly, our established non-asymptotic superlinear convergence rate demonstrates a trade-off between the convergence speed and memory requirement, which to our knowledge, is the first of its kind. Numerical results corroborate our theoretical findings and demonstrate the effectiveness of our method.
Prioritized Trajectory Replay: A Replay Memory for Data-driven Reinforcement Learning
Jun 27, 2023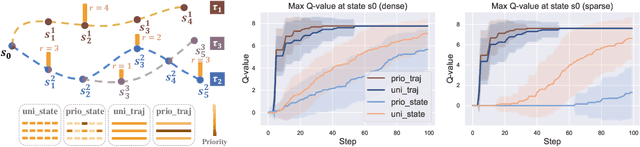
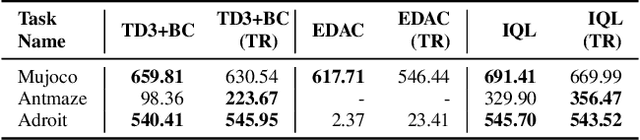
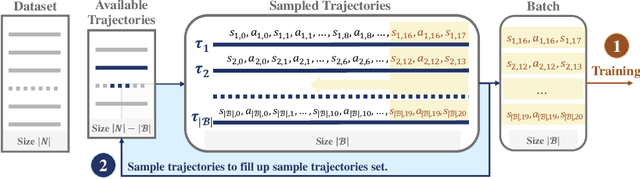
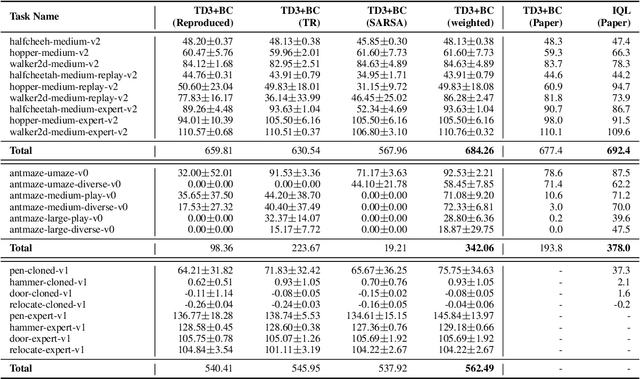
In recent years, data-driven reinforcement learning (RL), also known as offline RL, have gained significant attention. However, the role of data sampling techniques in offline RL has been overlooked despite its potential to enhance online RL performance. Recent research suggests applying sampling techniques directly to state-transitions does not consistently improve performance in offline RL. Therefore, in this study, we propose a memory technique, (Prioritized) Trajectory Replay (TR/PTR), which extends the sampling perspective to trajectories for more comprehensive information extraction from limited data. TR enhances learning efficiency by backward sampling of trajectories that optimizes the use of subsequent state information. Building on TR, we build the weighted critic target to avoid sampling unseen actions in offline training, and Prioritized Trajectory Replay (PTR) that enables more efficient trajectory sampling, prioritized by various trajectory priority metrics. We demonstrate the benefits of integrating TR and PTR with existing offline RL algorithms on D4RL. In summary, our research emphasizes the significance of trajectory-based data sampling techniques in enhancing the efficiency and performance of offline RL algorithms.
Learning Content-enhanced Mask Transformer for Domain Generalized Urban-Scene Segmentation
Jul 01, 2023
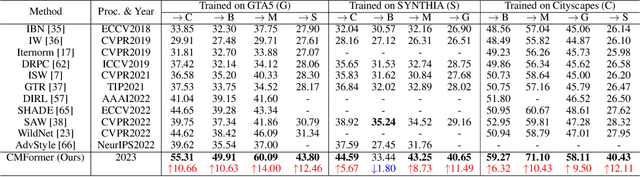
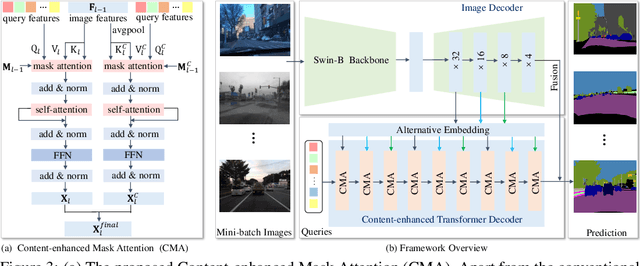

Domain-generalized urban-scene semantic segmentation (USSS) aims to learn generalized semantic predictions across diverse urban-scene styles. Unlike domain gap challenges, USSS is unique in that the semantic categories are often similar in different urban scenes, while the styles can vary significantly due to changes in urban landscapes, weather conditions, lighting, and other factors. Existing approaches typically rely on convolutional neural networks (CNNs) to learn the content of urban scenes. In this paper, we propose a Content-enhanced Mask TransFormer (CMFormer) for domain-generalized USSS. The main idea is to enhance the focus of the fundamental component, the mask attention mechanism, in Transformer segmentation models on content information. To achieve this, we introduce a novel content-enhanced mask attention mechanism. It learns mask queries from both the image feature and its down-sampled counterpart, as lower-resolution image features usually contain more robust content information and are less sensitive to style variations. These features are fused into a Transformer decoder and integrated into a multi-resolution content-enhanced mask attention learning scheme. Extensive experiments conducted on various domain-generalized urban-scene segmentation datasets demonstrate that the proposed CMFormer significantly outperforms existing CNN-based methods for domain-generalized semantic segmentation, achieving improvements of up to 14.00\% in terms of mIoU (mean intersection over union). The source code for CMFormer will be made available at this \href{https://github.com/BiQiWHU/domain-generalized-urban-scene-segmentation}{repository}.
Systematic analysis of the impact of label noise correction on ML Fairness
Jun 28, 2023Arbitrary, inconsistent, or faulty decision-making raises serious concerns, and preventing unfair models is an increasingly important challenge in Machine Learning. Data often reflect past discriminatory behavior, and models trained on such data may reflect bias on sensitive attributes, such as gender, race, or age. One approach to developing fair models is to preprocess the training data to remove the underlying biases while preserving the relevant information, for example, by correcting biased labels. While multiple label noise correction methods are available, the information about their behavior in identifying discrimination is very limited. In this work, we develop an empirical methodology to systematically evaluate the effectiveness of label noise correction techniques in ensuring the fairness of models trained on biased datasets. Our methodology involves manipulating the amount of label noise and can be used with fairness benchmarks but also with standard ML datasets. We apply the methodology to analyze six label noise correction methods according to several fairness metrics on standard OpenML datasets. Our results suggest that the Hybrid Label Noise Correction method achieves the best trade-off between predictive performance and fairness. Clustering-Based Correction can reduce discrimination the most, however, at the cost of lower predictive performance.
AFPN: Asymptotic Feature Pyramid Network for Object Detection
Jun 28, 2023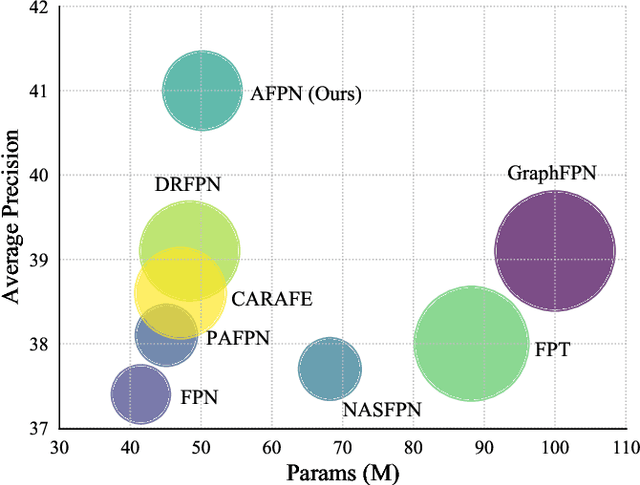
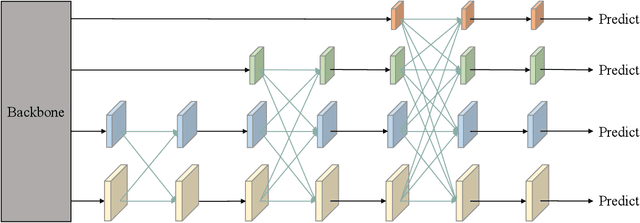
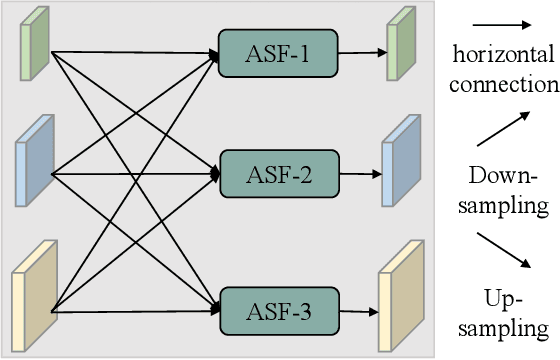
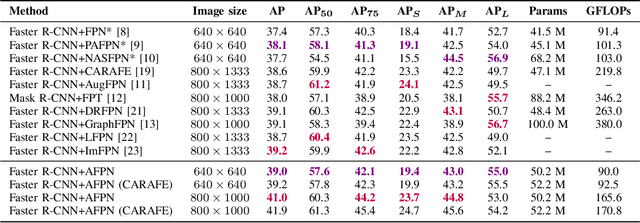
Multi-scale features are of great importance in encoding objects with scale variance in object detection tasks. A common strategy for multi-scale feature extraction is adopting the classic top-down and bottom-up feature pyramid networks. However, these approaches suffer from the loss or degradation of feature information, impairing the fusion effect of non-adjacent levels. This paper proposes an asymptotic feature pyramid network (AFPN) to support direct interaction at non-adjacent levels. AFPN is initiated by fusing two adjacent low-level features and asymptotically incorporates higher-level features into the fusion process. In this way, the larger semantic gap between non-adjacent levels can be avoided. Given the potential for multi-object information conflicts to arise during feature fusion at each spatial location, adaptive spatial fusion operation is further utilized to mitigate these inconsistencies. We incorporate the proposed AFPN into both two-stage and one-stage object detection frameworks and evaluate with the MS-COCO 2017 validation and test datasets. Experimental evaluation shows that our method achieves more competitive results than other state-of-the-art feature pyramid networks. The code is available at \href{https://github.com/gyyang23/AFPN}{https://github.com/gyyang23/AFPN}.
Compressed Sensing Radar Detectors based on Weighted LASSO
Jun 30, 2023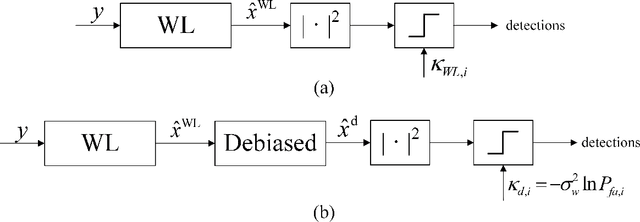
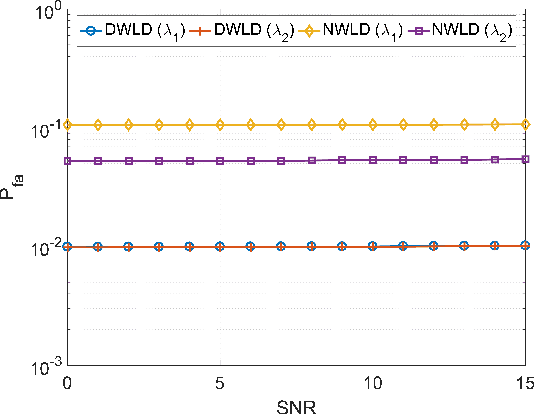
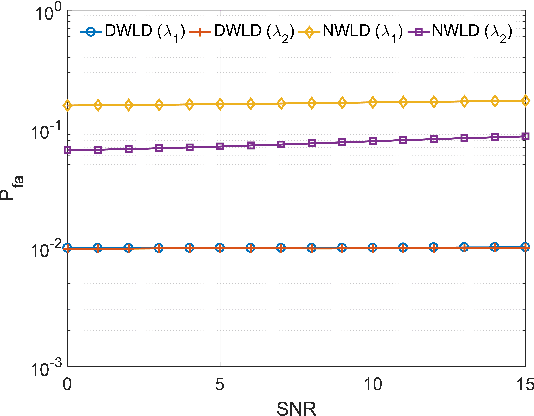
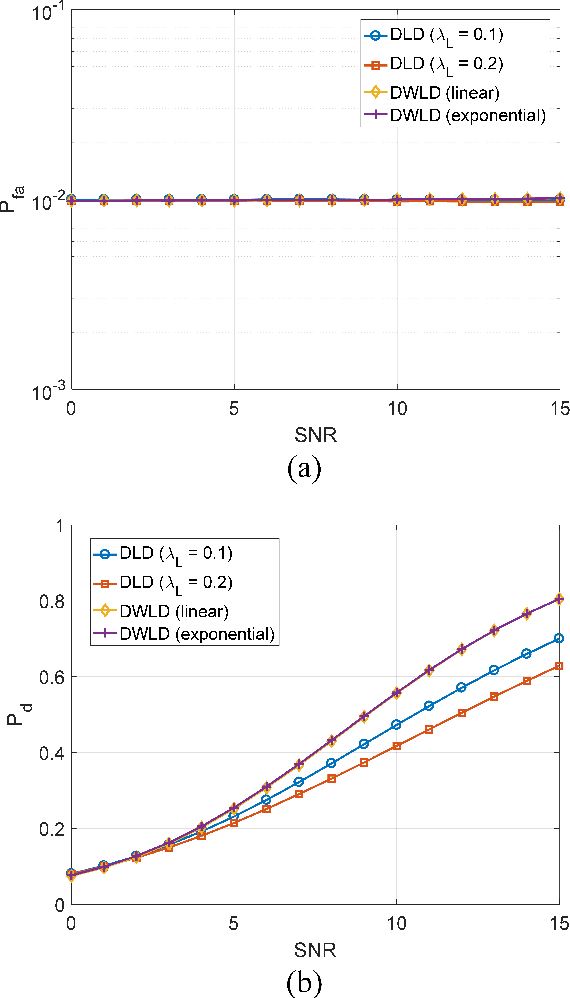
The compressed sensing (CS) model can represent the signal recovery process of a large number of radar systems. The detection problem of such radar systems has been studied in many pieces of literature through the technology of debiased least absolute shrinkage and selection operator (LASSO). While naive LASSO treats all the entries equally, there are many applications in which prior information varies depending on each entry. Weighted LASSO, in which the weights of the regularization terms are tuned depending on the entry-dependent prior, is proven to be more effective with the prior information by many researchers. In the present paper, existing results obtained by methods of statistical mechanics are utilized to derive the debiased weighted LASSO estimator for randomly constructed row-orthogonal measurement matrices. Based on this estimator, we construct a detector, termed the debiased weighted LASSO detector (DWLD), for CS radar systems and prove its advantages. The threshold of this detector can be calculated by false alarm rate, which yields better detection performance than the naive weighted LASSO detector (NWLD) under the Neyman-Pearson principle. The improvement of the detection performance brought by tuning weights is demonstrated by numerical experiments. With the same false alarm rate, the detection probability of DWLD is obviously higher than those of NWLD and the debiased (non-weighted) LASSO detector (DLD).
Improving the Efficiency of Human-in-the-Loop Systems: Adding Artificial to Human Experts
Jul 07, 2023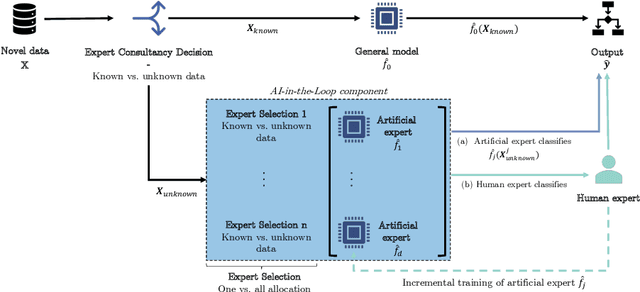
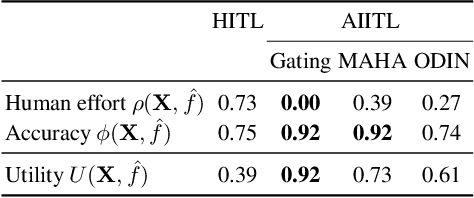
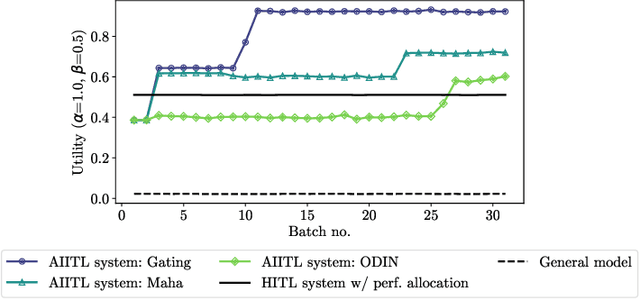
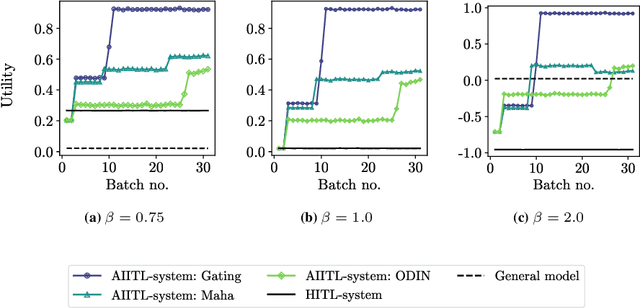
Information systems increasingly leverage artificial intelligence (AI) and machine learning (ML) to generate value from vast amounts of data. However, ML models are imperfect and can generate incorrect classifications. Hence, human-in-the-loop (HITL) extensions to ML models add a human review for instances that are difficult to classify. This study argues that continuously relying on human experts to handle difficult model classifications leads to a strong increase in human effort, which strains limited resources. To address this issue, we propose a hybrid system that creates artificial experts that learn to classify data instances from unknown classes previously reviewed by human experts. Our hybrid system assesses which artificial expert is suitable for classifying an instance from an unknown class and automatically assigns it. Over time, this reduces human effort and increases the efficiency of the system. Our experiments demonstrate that our approach outperforms traditional HITL systems for several benchmarks on image classification.
AutoDecoding Latent 3D Diffusion Models
Jul 07, 2023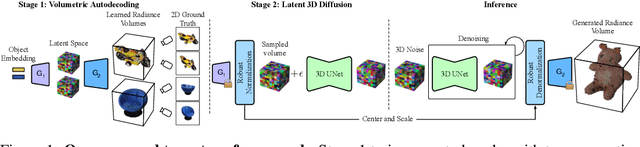
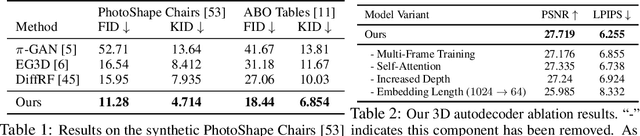

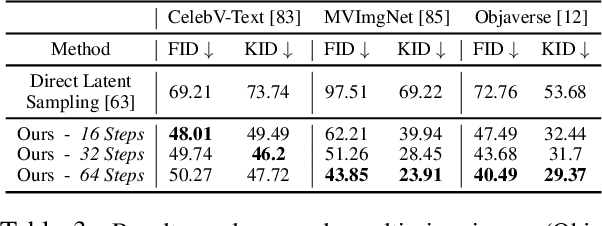
We present a novel approach to the generation of static and articulated 3D assets that has a 3D autodecoder at its core. The 3D autodecoder framework embeds properties learned from the target dataset in the latent space, which can then be decoded into a volumetric representation for rendering view-consistent appearance and geometry. We then identify the appropriate intermediate volumetric latent space, and introduce robust normalization and de-normalization operations to learn a 3D diffusion from 2D images or monocular videos of rigid or articulated objects. Our approach is flexible enough to use either existing camera supervision or no camera information at all -- instead efficiently learning it during training. Our evaluations demonstrate that our generation results outperform state-of-the-art alternatives on various benchmark datasets and metrics, including multi-view image datasets of synthetic objects, real in-the-wild videos of moving people, and a large-scale, real video dataset of static objects.