 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMMORRF: Multimodal Multilingual Modularized Reciprocal Rank Fusion
Mar 26, 2025


Videos inherently contain multiple modalities, including visual events, text overlays, sounds, and speech, all of which are important for retrieval. However, state-of-the-art multimodal language models like VAST and LanguageBind are built on vision-language models (VLMs), and thus overly prioritize visual signals. Retrieval benchmarks further reinforce this bias by focusing on visual queries and neglecting other modalities. We create a search system MMMORRF that extracts text and features from both visual and audio modalities and integrates them with a novel modality-aware weighted reciprocal rank fusion. MMMORRF is both effective and efficient, demonstrating practicality in searching videos based on users' information needs instead of visual descriptive queries. We evaluate MMMORRF on MultiVENT 2.0 and TVR, two multimodal benchmarks designed for more targeted information needs, and find that it improves nDCG@20 by 81% over leading multimodal encoders and 37% over single-modality retrieval, demonstrating the value of integrating diverse modalities.
MultiVENT 2.0: A Massive Multilingual Benchmark for Event-Centric Video Retrieval
Oct 15, 2024Efficiently retrieving and synthesizing information from large-scale multimodal collections has become a critical challenge. However, existing video retrieval datasets suffer from scope limitations, primarily focusing on matching descriptive but vague queries with small collections of professionally edited, English-centric videos. To address this gap, we introduce $\textbf{MultiVENT 2.0}$, a large-scale, multilingual event-centric video retrieval benchmark featuring a collection of more than 218,000 news videos and 3,906 queries targeting specific world events. These queries specifically target information found in the visual content, audio, embedded text, and text metadata of the videos, requiring systems leverage all these sources to succeed at the task. Preliminary results show that state-of-the-art vision-language models struggle significantly with this task, and while alternative approaches show promise, they are still insufficient to adequately address this problem. These findings underscore the need for more robust multimodal retrieval systems, as effective video retrieval is a crucial step towards multimodal content understanding and generation tasks.
Grounding Partially-Defined Events in Multimodal Data
Oct 07, 2024



How are we able to learn about complex current events just from short snippets of video? While natural language enables straightforward ways to represent under-specified, partially observable events, visual data does not facilitate analogous methods and, consequently, introduces unique challenges in event understanding. With the growing prevalence of vision-capable AI agents, these systems must be able to model events from collections of unstructured video data. To tackle robust event modeling in multimodal settings, we introduce a multimodal formulation for partially-defined events and cast the extraction of these events as a three-stage span retrieval task. We propose a corresponding benchmark for this task, MultiVENT-G, that consists of 14.5 hours of densely annotated current event videos and 1,168 text documents, containing 22.8K labeled event-centric entities. We propose a collection of LLM-driven approaches to the task of multimodal event analysis, and evaluate them on MultiVENT-G. Results illustrate the challenges that abstract event understanding poses and demonstrates promise in event-centric video-language systems.
MultiVENT: Multilingual Videos of Events with Aligned Natural Text
Jul 06, 2023Everyday news coverage has shifted from traditional broadcasts towards a wide range of presentation formats such as first-hand, unedited video footage. Datasets that reflect the diverse array of multimodal, multilingual news sources available online could be used to teach models to benefit from this shift, but existing news video datasets focus on traditional news broadcasts produced for English-speaking audiences. We address this limitation by constructing MultiVENT, a dataset of multilingual, event-centric videos grounded in text documents across five target languages. MultiVENT includes both news broadcast videos and non-professional event footage, which we use to analyze the state of online news videos and how they can be leveraged to build robust, factually accurate models. Finally, we provide a model for complex, multilingual video retrieval to serve as a baseline for information retrieval using MultiVENT.
Robust Open-Vocabulary Translation from Visual Text Representations
Apr 16, 2021
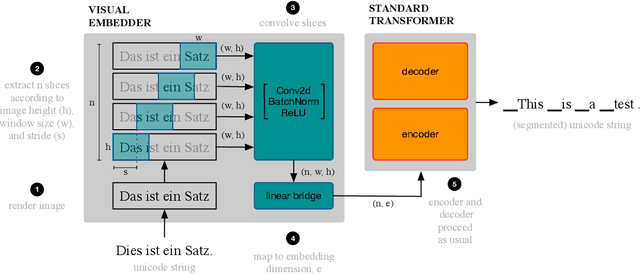
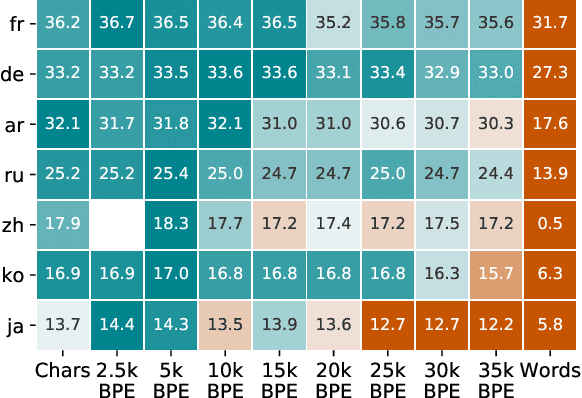
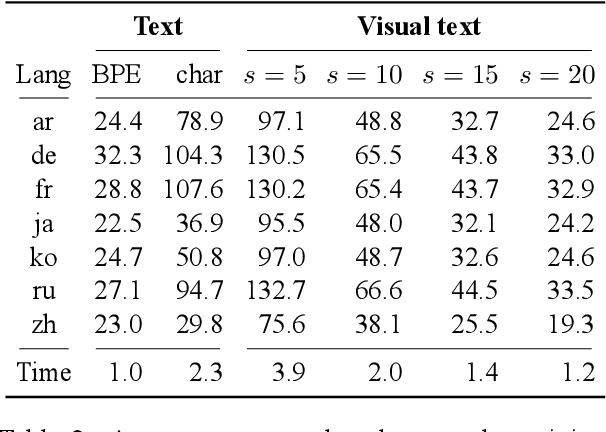
Machine translation models have discrete vocabularies and commonly use subword segmentation techniques to achieve an 'open-vocabulary.' This approach relies on consistent and correct underlying unicode sequences, and makes models susceptible to degradation from common types of noise and variation. Motivated by the robustness of human language processing, we propose the use of visual text representations, which dispense with a finite set of text embeddings in favor of continuous vocabularies created by processing visually rendered text. We show that models using visual text representations approach or match performance of text baselines on clean TED datasets. More importantly, models with visual embeddings demonstrate significant robustness to varied types of noise, achieving e.g., 25.9 BLEU on a character permuted German--English task where subword models degrade to 1.9.