 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Intrinsically motivated graph exploration using network theories of human curiosity
Jul 13, 2023
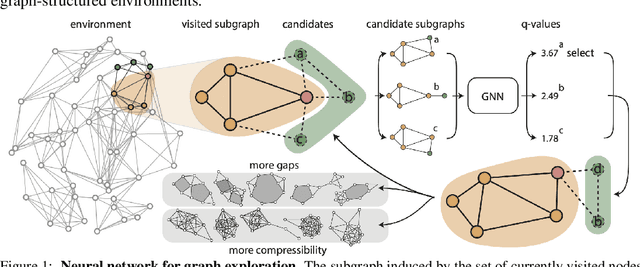
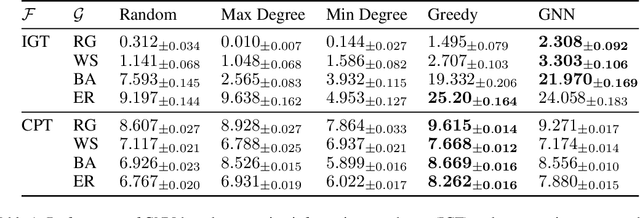
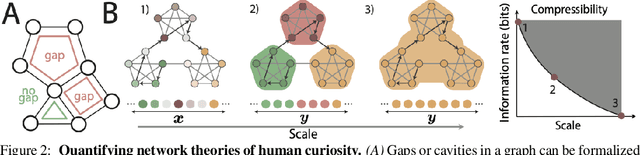
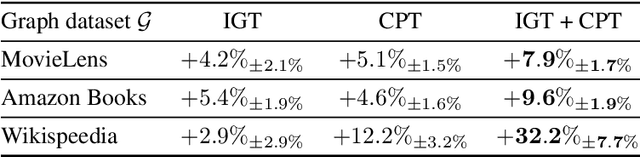
Intrinsically motivated exploration has proven useful for reinforcement learning, even without additional extrinsic rewards. When the environment is naturally represented as a graph, how to guide exploration best remains an open question. In this work, we propose a novel approach for exploring graph-structured data motivated by two theories of human curiosity: the information gap theory and the compression progress theory. The theories view curiosity as an intrinsic motivation to optimize for topological features of subgraphs induced by the visited nodes in the environment. We use these proposed features as rewards for graph neural-network-based reinforcement learning. On multiple classes of synthetically generated graphs, we find that trained agents generalize to larger environments and to longer exploratory walks than are seen during training. Our method computes more efficiently than the greedy evaluation of the relevant topological properties. The proposed intrinsic motivations bear particular relevance for recommender systems. We demonstrate that curiosity-based recommendations are more predictive of human behavior than PageRank centrality for several real-world graph datasets, including MovieLens, Amazon Books, and Wikispeedia.
Domain-Agnostic Tuning-Encoder for Fast Personalization of Text-To-Image Models
Jul 13, 2023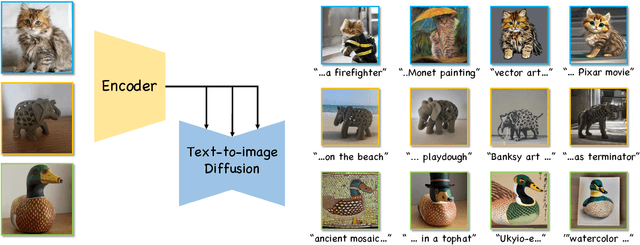
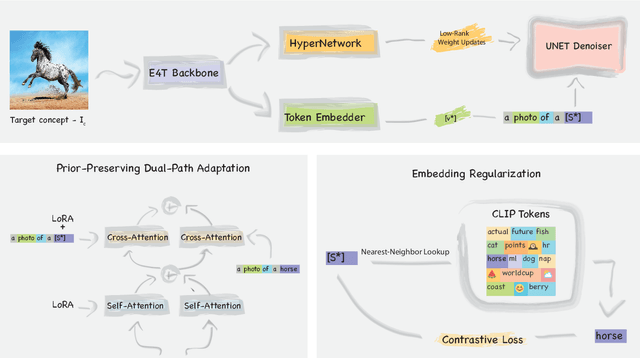


Text-to-image (T2I) personalization allows users to guide the creative image generation process by combining their own visual concepts in natural language prompts. Recently, encoder-based techniques have emerged as a new effective approach for T2I personalization, reducing the need for multiple images and long training times. However, most existing encoders are limited to a single-class domain, which hinders their ability to handle diverse concepts. In this work, we propose a domain-agnostic method that does not require any specialized dataset or prior information about the personalized concepts. We introduce a novel contrastive-based regularization technique to maintain high fidelity to the target concept characteristics while keeping the predicted embeddings close to editable regions of the latent space, by pushing the predicted tokens toward their nearest existing CLIP tokens. Our experimental results demonstrate the effectiveness of our approach and show how the learned tokens are more semantic than tokens predicted by unregularized models. This leads to a better representation that achieves state-of-the-art performance while being more flexible than previous methods.
Deepfake Video Detection Using Generative Convolutional Vision Transformer
Jul 13, 2023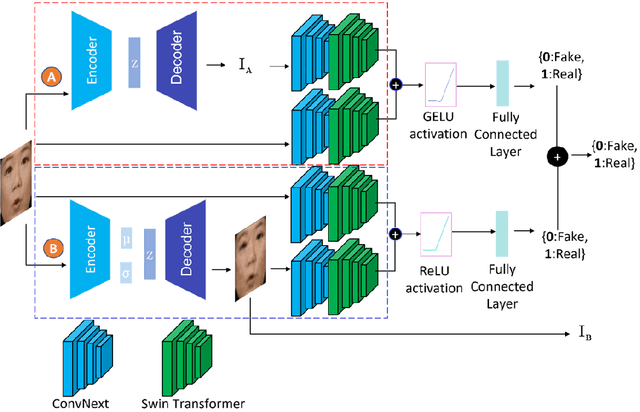
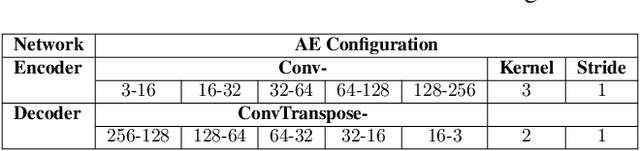

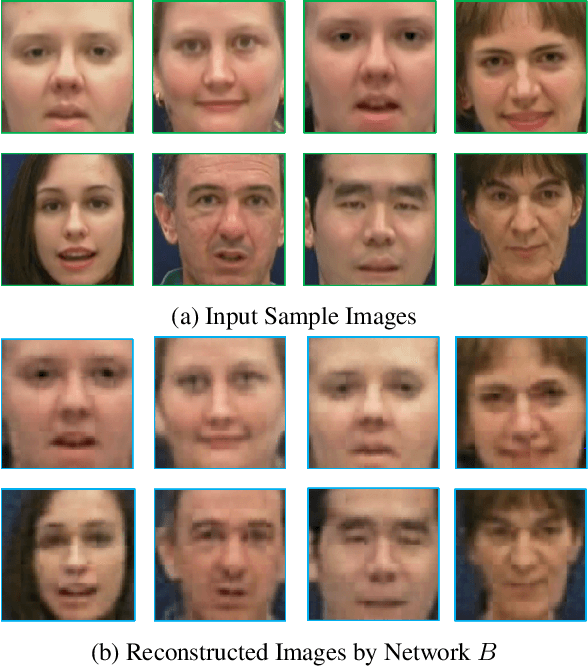
Deepfakes have raised significant concerns due to their potential to spread false information and compromise digital media integrity. In this work, we propose a Generative Convolutional Vision Transformer (GenConViT) for deepfake video detection. Our model combines ConvNeXt and Swin Transformer models for feature extraction, and it utilizes Autoencoder and Variational Autoencoder to learn from the latent data distribution. By learning from the visual artifacts and latent data distribution, GenConViT achieves improved performance in detecting a wide range of deepfake videos. The model is trained and evaluated on DFDC, FF++, DeepfakeTIMIT, and Celeb-DF v2 datasets, achieving high classification accuracy, F1 scores, and AUC values. The proposed GenConViT model demonstrates robust performance in deepfake video detection, with an average accuracy of 95.8% and an AUC value of 99.3% across the tested datasets. Our proposed model addresses the challenge of generalizability in deepfake detection by leveraging visual and latent features and providing an effective solution for identifying a wide range of fake videos while preserving media integrity. The code for GenConViT is available at https://github.com/erprogs/GenConViT.
Generating Benchmarks for Factuality Evaluation of Language Models
Jul 13, 2023

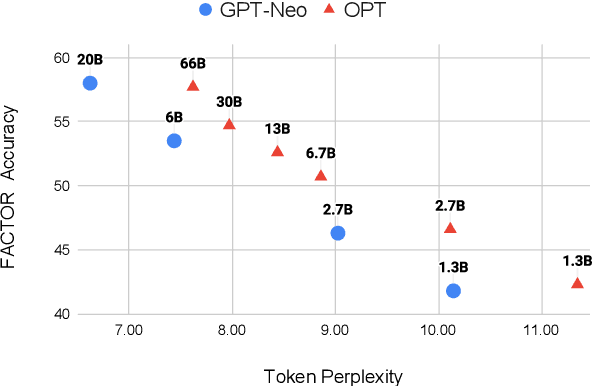
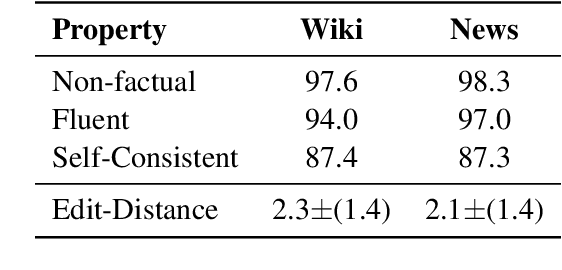
Before deploying a language model (LM) within a given domain, it is important to measure its tendency to generate factually incorrect information in that domain. Existing factual generation evaluation methods focus on facts sampled from the LM itself, and thus do not control the set of evaluated facts and might under-represent rare and unlikely facts. We propose FACTOR: Factual Assessment via Corpus TransfORmation, a scalable approach for evaluating LM factuality. FACTOR automatically transforms a factual corpus of interest into a benchmark evaluating an LM's propensity to generate true facts from the corpus vs. similar but incorrect statements. We use our framework to create two benchmarks: Wiki-FACTOR and News-FACTOR. We show that: (i) our benchmark scores increase with model size and improve when the LM is augmented with retrieval; (ii) benchmark score correlates with perplexity, but the two metrics do not always agree on model ranking; and (iii) when perplexity and benchmark score disagree, the latter better reflects factuality in open-ended generation, as measured by human annotators. We make our data and code publicly available in https://github.com/AI21Labs/factor.
Can Pre-Trained Text-to-Image Models Generate Visual Goals for Reinforcement Learning?
Jul 15, 2023Pre-trained text-to-image generative models can produce diverse, semantically rich, and realistic images from natural language descriptions. Compared with language, images usually convey information with more details and less ambiguity. In this study, we propose Learning from the Void (LfVoid), a method that leverages the power of pre-trained text-to-image models and advanced image editing techniques to guide robot learning. Given natural language instructions, LfVoid can edit the original observations to obtain goal images, such as "wiping" a stain off a table. Subsequently, LfVoid trains an ensembled goal discriminator on the generated image to provide reward signals for a reinforcement learning agent, guiding it to achieve the goal. The ability of LfVoid to learn with zero in-domain training on expert demonstrations or true goal observations (the void) is attributed to the utilization of knowledge from web-scale generative models. We evaluate LfVoid across three simulated tasks and validate its feasibility in the corresponding real-world scenarios. In addition, we offer insights into the key considerations for the effective integration of visual generative models into robot learning workflows. We posit that our work represents an initial step towards the broader application of pre-trained visual generative models in the robotics field. Our project page: https://lfvoid-rl.github.io/.
MUVF-YOLOX: A Multi-modal Ultrasound Video Fusion Network for Renal Tumor Diagnosis
Jul 15, 2023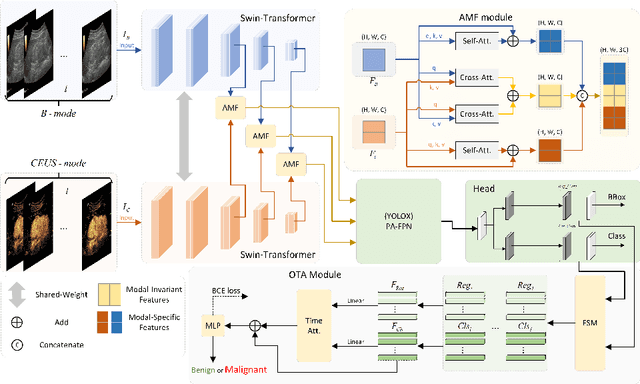
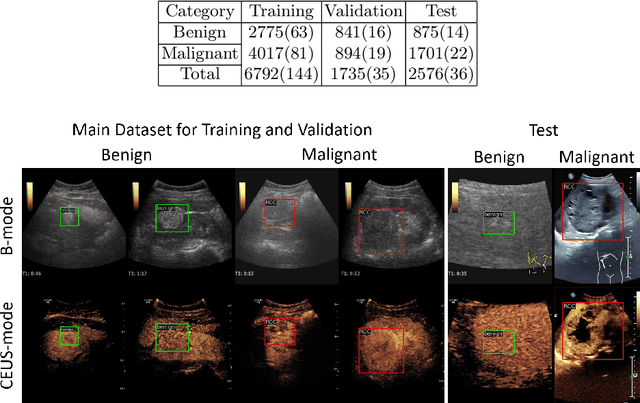
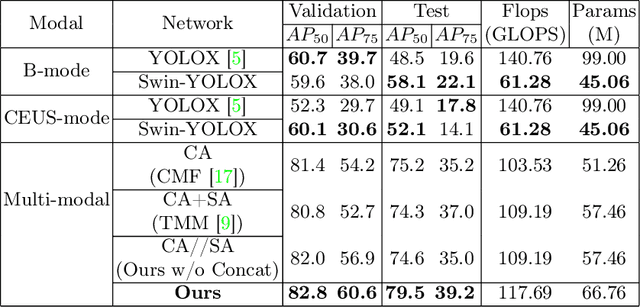
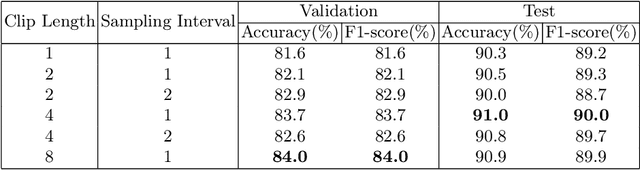
Early diagnosis of renal cancer can greatly improve the survival rate of patients. Contrast-enhanced ultrasound (CEUS) is a cost-effective and non-invasive imaging technique and has become more and more frequently used for renal tumor diagnosis. However, the classification of benign and malignant renal tumors can still be very challenging due to the highly heterogeneous appearance of cancer and imaging artifacts. Our aim is to detect and classify renal tumors by integrating B-mode and CEUS-mode ultrasound videos. To this end, we propose a novel multi-modal ultrasound video fusion network that can effectively perform multi-modal feature fusion and video classification for renal tumor diagnosis. The attention-based multi-modal fusion module uses cross-attention and self-attention to extract modality-invariant features and modality-specific features in parallel. In addition, we design an object-level temporal aggregation (OTA) module that can automatically filter low-quality features and efficiently integrate temporal information from multiple frames to improve the accuracy of tumor diagnosis. Experimental results on a multicenter dataset show that the proposed framework outperforms the single-modal models and the competing methods. Furthermore, our OTA module achieves higher classification accuracy than the frame-level predictions. Our code is available at \url{https://github.com/JeunyuLi/MUAF}.
Prompt Tuning on Graph-augmented Low-resource Text Classification
Jul 15, 2023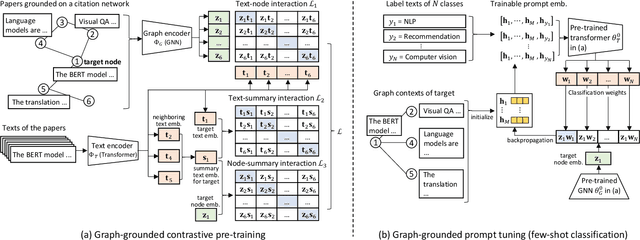
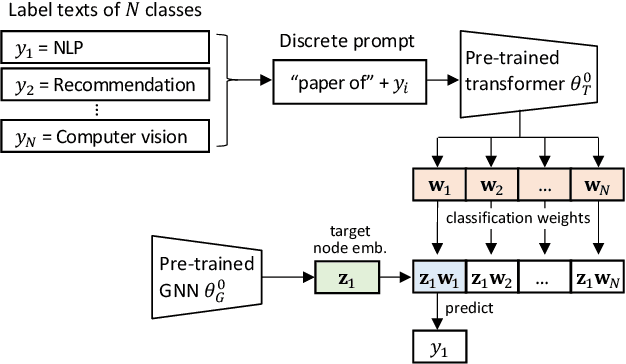
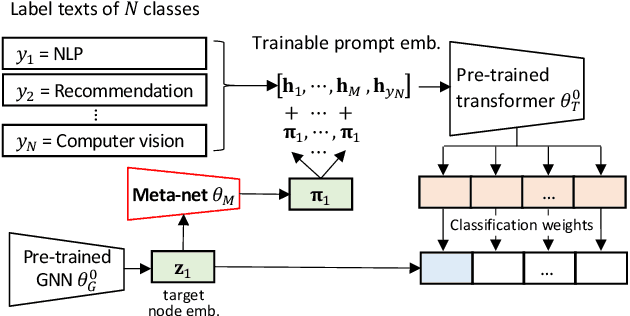
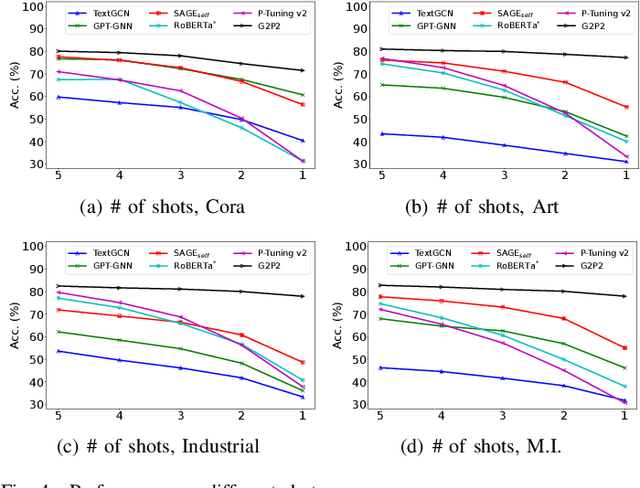
Text classification is a fundamental problem in information retrieval with many real-world applications, such as predicting the topics of online articles and the categories of e-commerce product descriptions. However, low-resource text classification, with no or few labeled samples, presents a serious concern for supervised learning. Meanwhile, many text data are inherently grounded on a network structure, such as a hyperlink/citation network for online articles, and a user-item purchase network for e-commerce products. These graph structures capture rich semantic relationships, which can potentially augment low-resource text classification. In this paper, we propose a novel model called Graph-Grounded Pre-training and Prompting (G2P2) to address low-resource text classification in a two-pronged approach. During pre-training, we propose three graph interaction-based contrastive strategies to jointly pre-train a graph-text model; during downstream classification, we explore handcrafted discrete prompts and continuous prompt tuning for the jointly pre-trained model to achieve zero- and few-shot classification, respectively. Besides, for generalizing continuous prompts to unseen classes, we propose conditional prompt tuning on graphs (G2P2$^*$). Extensive experiments on four real-world datasets demonstrate the strength of G2P2 in zero- and few-shot low-resource text classification tasks, and illustrate the advantage of G2P2$^*$ in dealing with unseen classes.
MGit: A Model Versioning and Management System
Jul 14, 2023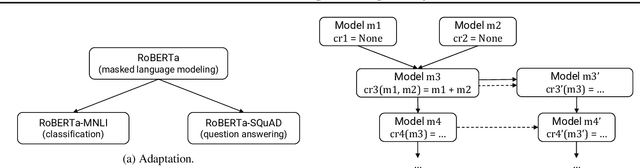

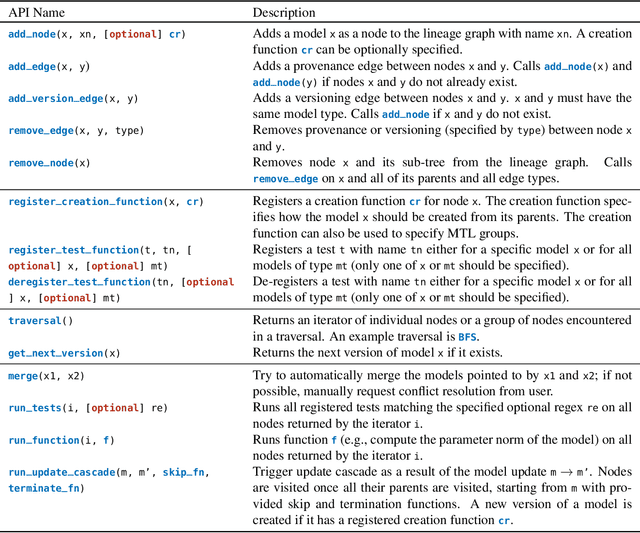
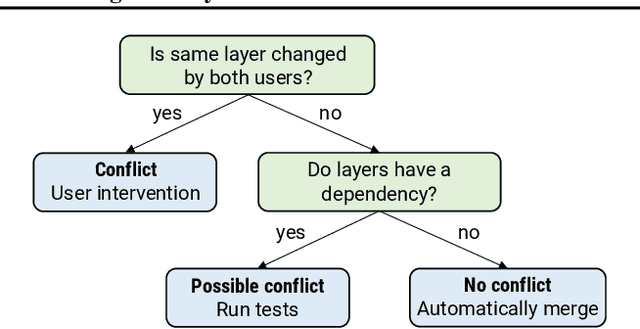
Models derived from other models are extremely common in machine learning (ML) today. For example, transfer learning is used to create task-specific models from "pre-trained" models through finetuning. This has led to an ecosystem where models are related to each other, sharing structure and often even parameter values. However, it is hard to manage these model derivatives: the storage overhead of storing all derived models quickly becomes onerous, prompting users to get rid of intermediate models that might be useful for further analysis. Additionally, undesired behaviors in models are hard to track down (e.g., is a bug inherited from an upstream model?). In this paper, we propose a model versioning and management system called MGit that makes it easier to store, test, update, and collaborate on model derivatives. MGit introduces a lineage graph that records provenance and versioning information between models, optimizations to efficiently store model parameters, as well as abstractions over this lineage graph that facilitate relevant testing, updating and collaboration functionality. MGit is able to reduce the lineage graph's storage footprint by up to 7x and automatically update downstream models in response to updates to upstream models.
Graph Positional and Structural Encoder
Jul 14, 2023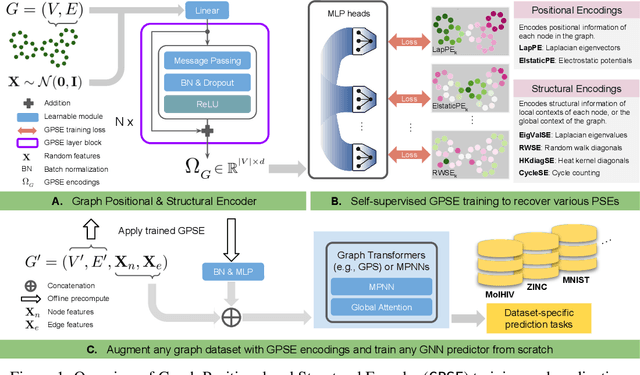
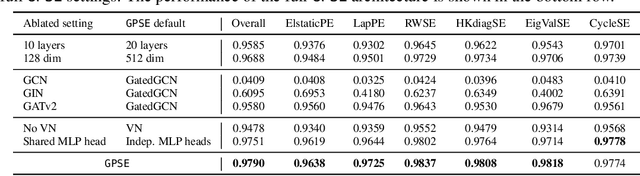
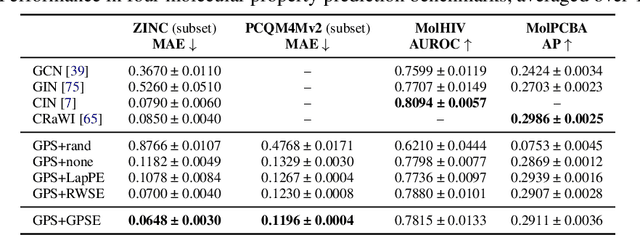
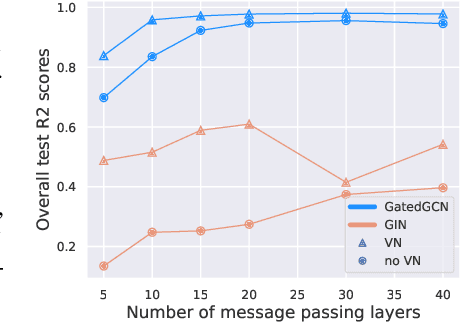
Positional and structural encodings (PSE) enable better identifiability of nodes within a graph, as in general graphs lack a canonical node ordering. This renders PSEs essential tools for empowering modern GNNs, and in particular graph Transformers. However, designing PSEs that work optimally for a variety of graph prediction tasks is a challenging and unsolved problem. Here, we present the graph positional and structural encoder (GPSE), a first-ever attempt to train a graph encoder that captures rich PSE representations for augmenting any GNN. GPSE can effectively learn a common latent representation for multiple PSEs, and is highly transferable. The encoder trained on a particular graph dataset can be used effectively on datasets drawn from significantly different distributions and even modalities. We show that across a wide range of benchmarks, GPSE-enhanced models can significantly improve the performance in certain tasks, while performing on par with those that employ explicitly computed PSEs in other cases. Our results pave the way for the development of large pre-trained models for extracting graph positional and structural information and highlight their potential as a viable alternative to explicitly computed PSEs as well as to existing self-supervised pre-training approaches.
H$_2$O: Heavy-Hitter Oracle for Efficient Generative Inference of Large Language Models
Jul 19, 2023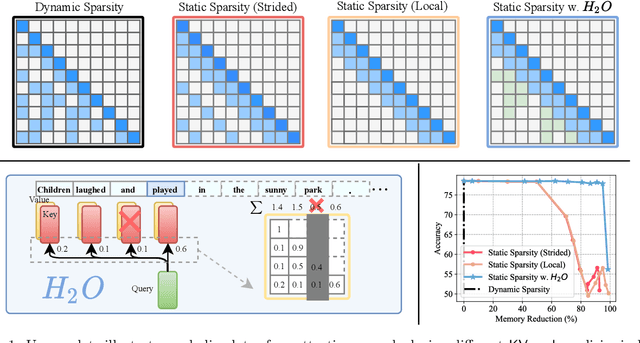
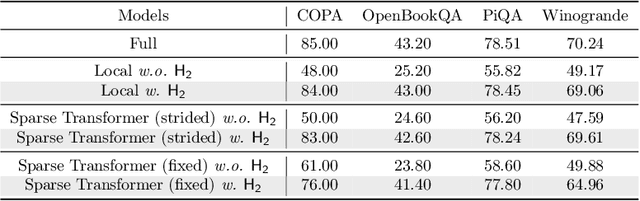
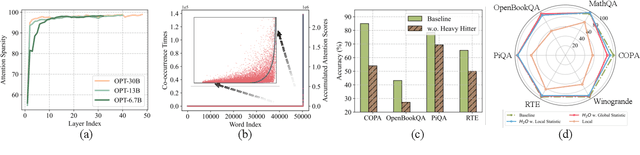

Large Language Models (LLMs), despite their recent impressive accomplishments, are notably cost-prohibitive to deploy, particularly for applications involving long-content generation, such as dialogue systems and story writing. Often, a large amount of transient state information, referred to as the KV cache, is stored in GPU memory in addition to model parameters, scaling linearly with the sequence length and batch size. In this paper, we introduce a novel approach for implementing the KV cache which significantly reduces its memory footprint. Our approach is based on the noteworthy observation that a small portion of tokens contributes most of the value when computing attention scores. We call these tokens Heavy Hitters (H$_2$). Through a comprehensive investigation, we find that (i) the emergence of H$_2$ is natural and strongly correlates with the frequent co-occurrence of tokens in the text, and (ii) removing them results in significant performance degradation. Based on these insights, we propose Heavy Hitter Oracle (H$_2$O), a KV cache eviction policy that dynamically retains a balance of recent and H$_2$ tokens. We formulate the KV cache eviction as a dynamic submodular problem and prove (under mild assumptions) a theoretical guarantee for our novel eviction algorithm which could help guide future work. We validate the accuracy of our algorithm with OPT, LLaMA, and GPT-NeoX across a wide range of tasks. Our implementation of H$_2$O with 20% heavy hitters improves the throughput over three leading inference systems DeepSpeed Zero-Inference, Hugging Face Accelerate, and FlexGen by up to 29$\times$, 29$\times$, and 3$\times$ on OPT-6.7B and OPT-30B. With the same batch size, H2O can reduce the latency by up to 1.9$\times$. The code is available at https://github.com/FMInference/H2O.