 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Active Learning for the Search of Small-molecule Protein Binders
May 02, 2024



Despite substantial progress in machine learning for scientific discovery in recent years, truly de novo design of small molecules which exhibit a property of interest remains a significant challenge. We introduce LambdaZero, a generative active learning approach to search for synthesizable molecules. Powered by deep reinforcement learning, LambdaZero learns to search over the vast space of molecules to discover candidates with a desired property. We apply LambdaZero with molecular docking to design novel small molecules that inhibit the enzyme soluble Epoxide Hydrolase 2 (sEH), while enforcing constraints on synthesizability and drug-likeliness. LambdaZero provides an exponential speedup in terms of the number of calls to the expensive molecular docking oracle, and LambdaZero de novo designed molecules reach docking scores that would otherwise require the virtual screening of a hundred billion molecules. Importantly, LambdaZero discovers novel scaffolds of synthesizable, drug-like inhibitors for sEH. In in vitro experimental validation, a series of ligands from a generated quinazoline-based scaffold were synthesized, and the lead inhibitor N-(4,6-di(pyrrolidin-1-yl)quinazolin-2-yl)-N-methylbenzamide (UM0152893) displayed sub-micromolar enzyme inhibition of sEH.
Graph Positional and Structural Encoder
Jul 14, 2023



Positional and structural encodings (PSE) enable better identifiability of nodes within a graph, as in general graphs lack a canonical node ordering. This renders PSEs essential tools for empowering modern GNNs, and in particular graph Transformers. However, designing PSEs that work optimally for a variety of graph prediction tasks is a challenging and unsolved problem. Here, we present the graph positional and structural encoder (GPSE), a first-ever attempt to train a graph encoder that captures rich PSE representations for augmenting any GNN. GPSE can effectively learn a common latent representation for multiple PSEs, and is highly transferable. The encoder trained on a particular graph dataset can be used effectively on datasets drawn from significantly different distributions and even modalities. We show that across a wide range of benchmarks, GPSE-enhanced models can significantly improve the performance in certain tasks, while performing on par with those that employ explicitly computed PSEs in other cases. Our results pave the way for the development of large pre-trained models for extracting graph positional and structural information and highlight their potential as a viable alternative to explicitly computed PSEs as well as to existing self-supervised pre-training approaches.
Attending to Graph Transformers
Feb 08, 2023Recently, transformer architectures for graphs emerged as an alternative to established techniques for machine learning with graphs, such as graph neural networks. So far, they have shown promising empirical results, e.g., on molecular prediction datasets, often attributed to their ability to circumvent graph neural networks' shortcomings, such as over-smoothing and over-squashing. Here, we derive a taxonomy of graph transformer architectures, bringing some order to this emerging field. We overview their theoretical properties, survey structural and positional encodings, and discuss extensions for important graph classes, e.g., 3D molecular graphs. Empirically, we probe how well graph transformers can recover various graph properties, how well they can deal with heterophilic graphs, and to what extent they prevent over-squashing. Further, we outline open challenges and research direction to stimulate future work. Our code is available at https://github.com/luis-mueller/probing-graph-transformers.
GPS++: Reviving the Art of Message Passing for Molecular Property Prediction
Feb 06, 2023



We present GPS++, a hybrid Message Passing Neural Network / Graph Transformer model for molecular property prediction. Our model integrates a well-tuned local message passing component and biased global attention with other key ideas from prior literature to achieve state-of-the-art results on large-scale molecular dataset PCQM4Mv2. Through a thorough ablation study we highlight the impact of individual components and, contrary to expectations set by recent trends, find that nearly all of the model's performance can be maintained without any use of global self-attention. We also show that our approach is significantly more accurate than prior art when 3D positional information is not available.
GPS++: An Optimised Hybrid MPNN/Transformer for Molecular Property Prediction
Dec 06, 2022



This technical report presents GPS++, the first-place solution to the Open Graph Benchmark Large-Scale Challenge (OGB-LSC 2022) for the PCQM4Mv2 molecular property prediction task. Our approach implements several key principles from the prior literature. At its core our GPS++ method is a hybrid MPNN/Transformer model that incorporates 3D atom positions and an auxiliary denoising task. The effectiveness of GPS++ is demonstrated by achieving 0.0719 mean absolute error on the independent test-challenge PCQM4Mv2 split. Thanks to Graphcore IPU acceleration, GPS++ scales to deep architectures (16 layers), training at 3 minutes per epoch, and large ensemble (112 models), completing the final predictions in 1 hour 32 minutes, well under the 4 hour inference budget allocated. Our implementation is publicly available at: https://github.com/graphcore/ogb-lsc-pcqm4mv2.
Long Range Graph Benchmark
Jun 16, 2022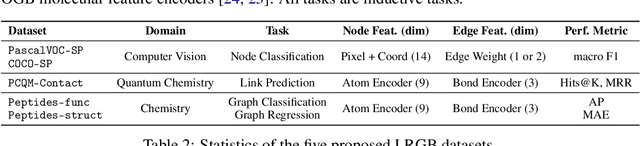
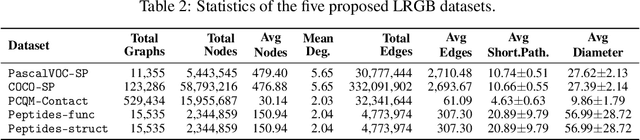

Graph Neural Networks (GNNs) that are based on the message passing (MP) paradigm exchange information between 1-hop neighbors to build node representations at each layer. In principle, such networks are not able to capture long-range interactions (LRI) that may be desired or necessary for learning a given task on graphs. Recently, there has been an increasing interest in development of Transformer-based methods for graphs that can consider full node connectivity beyond the original sparse structure, thus enabling the modeling of LRI. However, MP-GNNs that simply rely on 1-hop message passing often fare better in several existing graph benchmarks when combined with positional feature representations, among other innovations, hence limiting the perceived utility and ranking of Transformer-like architectures. Here, we present the Long Range Graph Benchmark (LRGB) with 5 graph learning datasets: PascalVOC-SP, COCO-SP, PCQM-Contact, Peptides-func and Peptides-struct that arguably require LRI reasoning to achieve strong performance in a given task. We benchmark both baseline GNNs and Graph Transformer networks to verify that the models which capture long-range dependencies perform significantly better on these tasks. Therefore, these datasets are suitable for benchmarking and exploration of MP-GNNs and Graph Transformer architectures that are intended to capture LRI.
Taxonomy of Benchmarks in Graph Representation Learning
Jun 15, 2022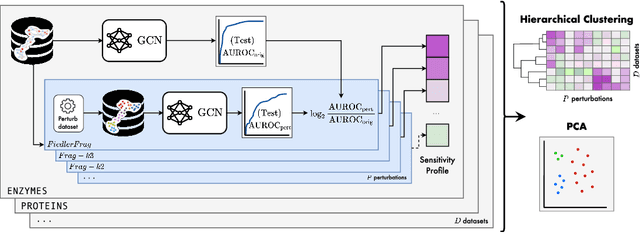
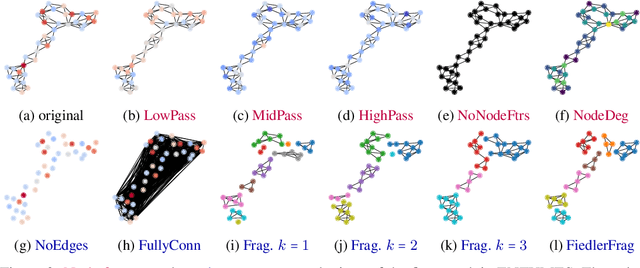
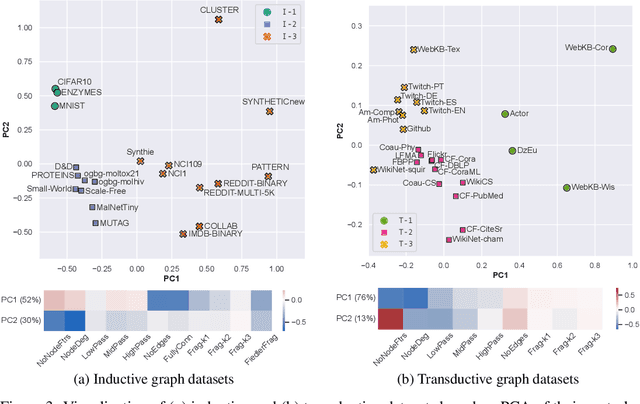
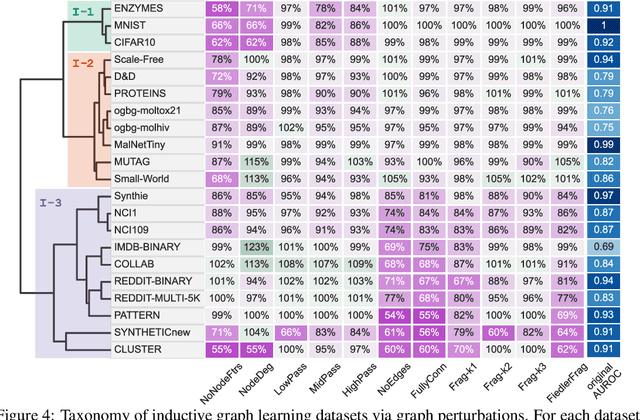
Graph Neural Networks (GNNs) extend the success of neural networks to graph-structured data by accounting for their intrinsic geometry. While extensive research has been done on developing GNN models with superior performance according to a collection of graph representation learning benchmarks, it is currently not well understood what aspects of a given model are probed by them. For example, to what extent do they test the ability of a model to leverage graph structure vs. node features? Here, we develop a principled approach to taxonomize benchmarking datasets according to a $\textit{sensitivity profile}$ that is based on how much GNN performance changes due to a collection of graph perturbations. Our data-driven analysis provides a deeper understanding of which benchmarking data characteristics are leveraged by GNNs. Consequently, our taxonomy can aid in selection and development of adequate graph benchmarks, and better informed evaluation of future GNN methods. Finally, our approach and implementation in $\texttt{GTaxoGym}$ package are extendable to multiple graph prediction task types and future datasets.
Recipe for a General, Powerful, Scalable Graph Transformer
May 25, 2022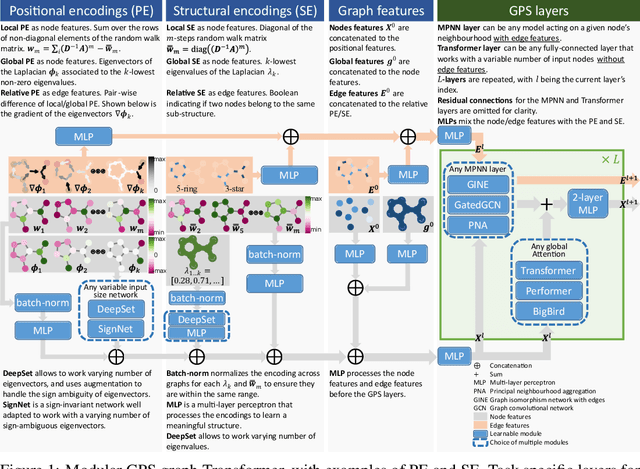
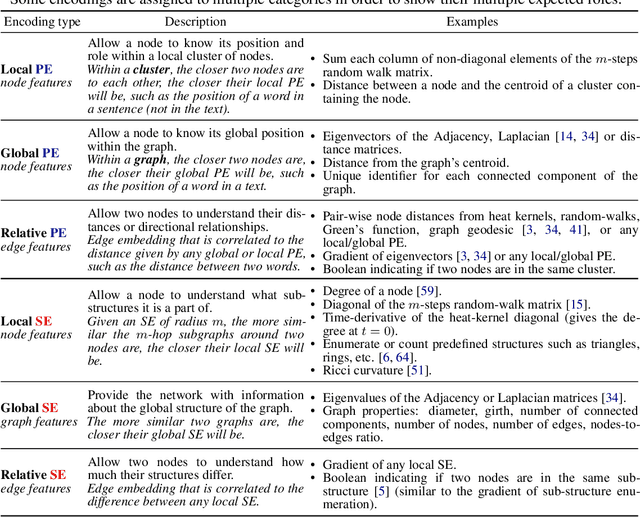
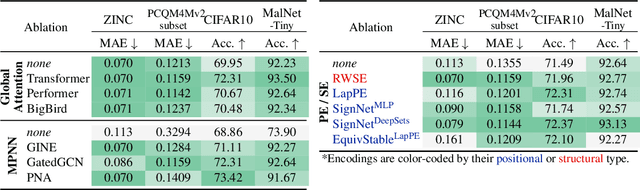
We propose a recipe on how to build a general, powerful, scalable (GPS) graph Transformer with linear complexity and state-of-the-art results on a diverse set of benchmarks. Graph Transformers (GTs) have gained popularity in the field of graph representation learning with a variety of recent publications but they lack a common foundation about what constitutes a good positional or structural encoding, and what differentiates them. In this paper, we summarize the different types of encodings with a clearer definition and categorize them as being $\textit{local}$, $\textit{global}$ or $\textit{relative}$. Further, GTs remain constrained to small graphs with few hundred nodes, and we propose the first architecture with a complexity linear to the number of nodes and edges $O(N+E)$ by decoupling the local real-edge aggregation from the fully-connected Transformer. We argue that this decoupling does not negatively affect the expressivity, with our architecture being a universal function approximator for graphs. Our GPS recipe consists of choosing 3 main ingredients: (i) positional/structural encoding, (ii) local message-passing mechanism, and (iii) global attention mechanism. We build and open-source a modular framework $\textit{GraphGPS}$ that supports multiple types of encodings and that provides efficiency and scalability both in small and large graphs. We test our architecture on 11 benchmarks and show very competitive results on all of them, show-casing the empirical benefits gained by the modularity and the combination of different strategies.
Towards a Taxonomy of Graph Learning Datasets
Oct 27, 2021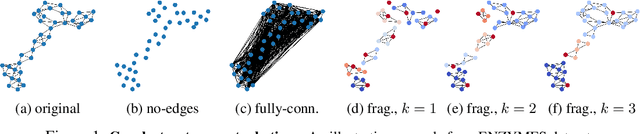
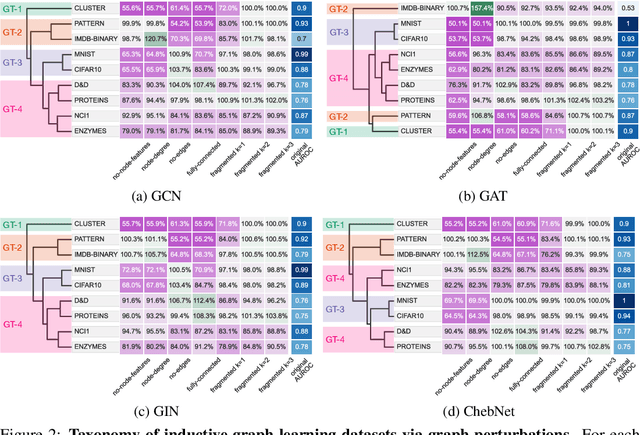
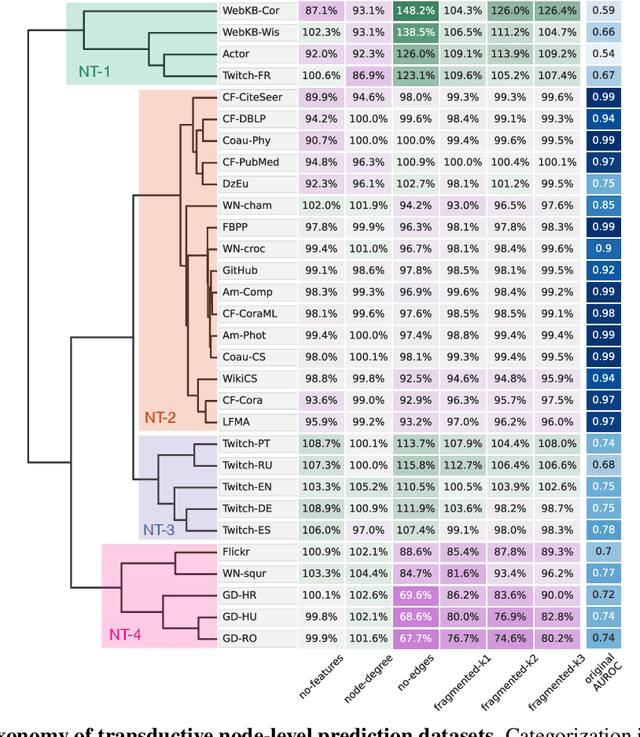
Graph neural networks (GNNs) have attracted much attention due to their ability to leverage the intrinsic geometries of the underlying data. Although many different types of GNN models have been developed, with many benchmarking procedures to demonstrate the superiority of one GNN model over the others, there is a lack of systematic understanding of the underlying benchmarking datasets, and what aspects of the model are being tested. Here, we provide a principled approach to taxonomize graph benchmarking datasets by carefully designing a collection of graph perturbations to probe the essential data characteristics that GNN models leverage to perform predictions. Our data-driven taxonomization of graph datasets provides a new understanding of critical dataset characteristics that will enable better model evaluation and the development of more specialized GNN models.
Hierarchical graph neural nets can capture long-range interactions
Aug 15, 2021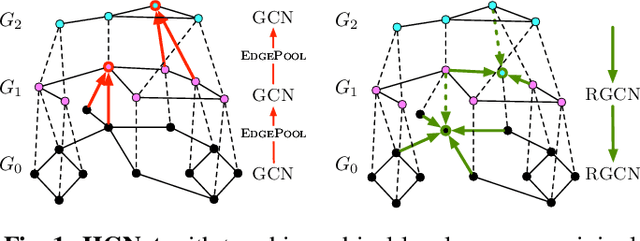
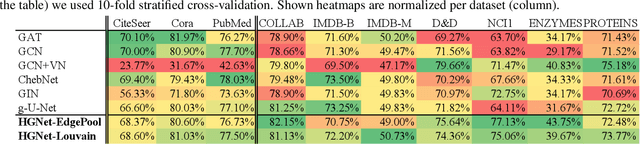
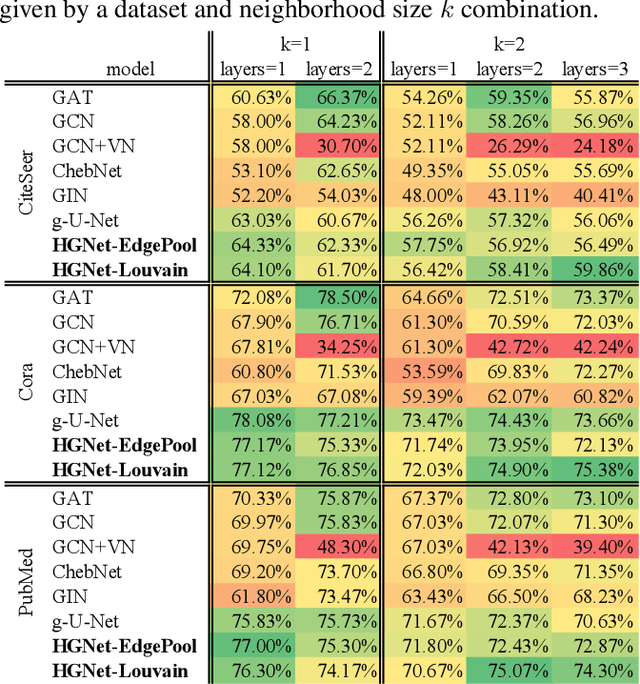
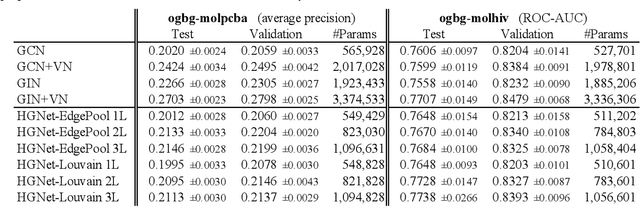
Graph neural networks (GNNs) based on message passing between neighboring nodes are known to be insufficient for capturing long-range interactions in graphs. In this project we study hierarchical message passing models that leverage a multi-resolution representation of a given graph. This facilitates learning of features that span large receptive fields without loss of local information, an aspect not studied in preceding work on hierarchical GNNs. We introduce Hierarchical Graph Net (HGNet), which for any two connected nodes guarantees existence of message-passing paths of at most logarithmic length w.r.t. the input graph size. Yet, under mild assumptions, its internal hierarchy maintains asymptotic size equivalent to that of the input graph. We observe that our HGNet outperforms conventional stacking of GCN layers particularly in molecular property prediction benchmarks. Finally, we propose two benchmarking tasks designed to elucidate capability of GNNs to leverage long-range interactions in graphs.