 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Beyond First Impressions: Integrating Joint Multi-modal Cues for Comprehensive 3D Representation
Aug 06, 2023
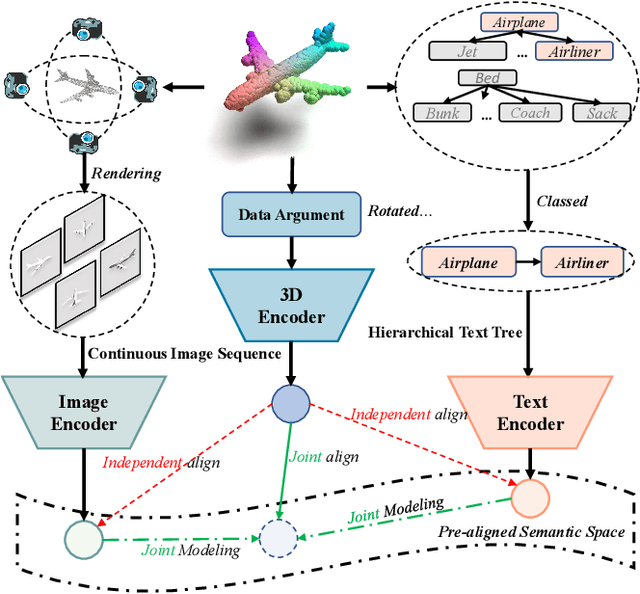
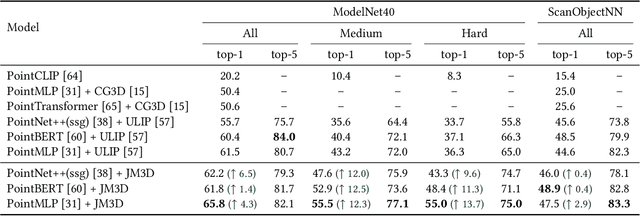
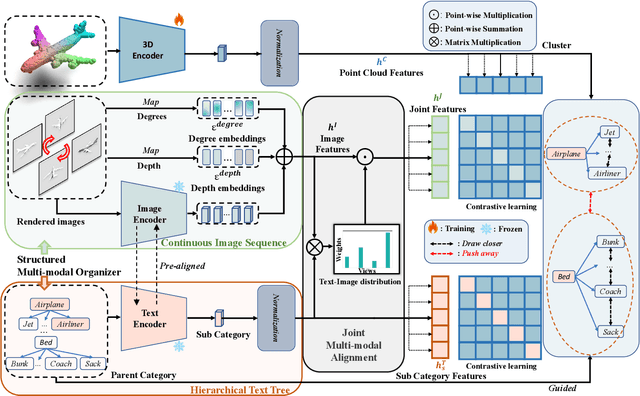
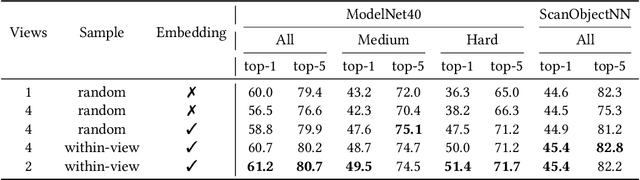
In recent years, 3D representation learning has turned to 2D vision-language pre-trained models to overcome data scarcity challenges. However, existing methods simply transfer 2D alignment strategies, aligning 3D representations with single-view 2D images and coarse-grained parent category text. These approaches introduce information degradation and insufficient synergy issues, leading to performance loss. Information degradation arises from overlooking the fact that a 3D representation should be equivalent to a series of multi-view images and more fine-grained subcategory text. Insufficient synergy neglects the idea that a robust 3D representation should align with the joint vision-language space, rather than independently aligning with each modality. In this paper, we propose a multi-view joint modality modeling approach, termed JM3D, to obtain a unified representation for point cloud, text, and image. Specifically, a novel Structured Multimodal Organizer (SMO) is proposed to address the information degradation issue, which introduces contiguous multi-view images and hierarchical text to enrich the representation of vision and language modalities. A Joint Multi-modal Alignment (JMA) is designed to tackle the insufficient synergy problem, which models the joint modality by incorporating language knowledge into the visual modality. Extensive experiments on ModelNet40 and ScanObjectNN demonstrate the effectiveness of our proposed method, JM3D, which achieves state-of-the-art performance in zero-shot 3D classification. JM3D outperforms ULIP by approximately 4.3% on PointMLP and achieves an improvement of up to 6.5% accuracy on PointNet++ in top-1 accuracy for zero-shot 3D classification on ModelNet40. The source code and trained models for all our experiments are publicly available at https://github.com/Mr-Neko/JM3D.
AST-MHSA : Code Summarization using Multi-Head Self-Attention
Aug 10, 2023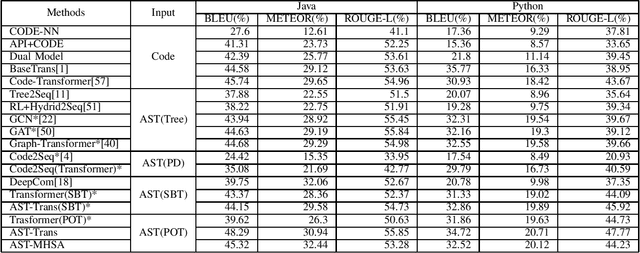
Code summarization aims to generate concise natural language descriptions for source code. The prevailing approaches adopt transformer-based encoder-decoder architectures, where the Abstract Syntax Tree (AST) of the source code is utilized for encoding structural information. However, ASTs are much longer than the corresponding source code, and existing methods ignore this size constraint by directly feeding the entire linearized AST into the encoders. This simplistic approach makes it challenging to extract truly valuable dependency relations from the overlong input sequence and leads to significant computational overhead due to self-attention applied to all nodes in the AST. To address this issue effectively and efficiently, we present a model, AST-MHSA that uses multi-head attention to extract the important semantic information from the AST. The model consists of two main components: an encoder and a decoder. The encoder takes as input the abstract syntax tree (AST) of the code and generates a sequence of hidden states. The decoder then takes these hidden states as input and generates a natural language summary of the code. The multi-head attention mechanism allows the model to learn different representations of the input code, which can be combined to generate a more comprehensive summary. The model is trained on a dataset of code and summaries, and the parameters of the model are optimized to minimize the loss between the generated summaries and the ground-truth summaries.
PatchContrast: Self-Supervised Pre-training for 3D Object Detection
Aug 14, 2023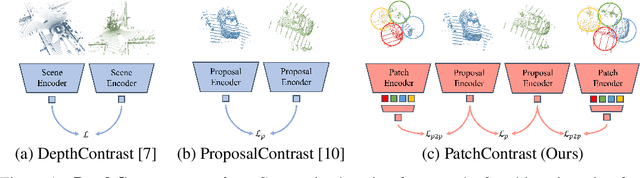
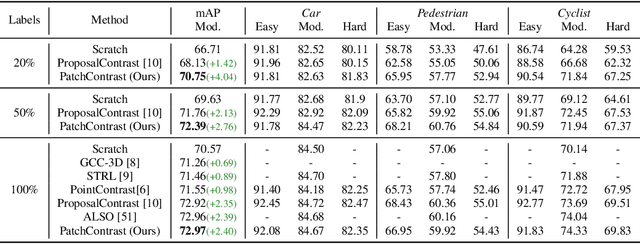
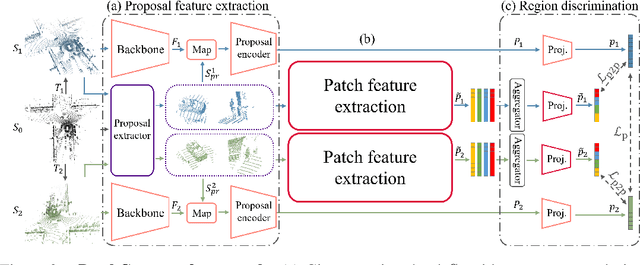
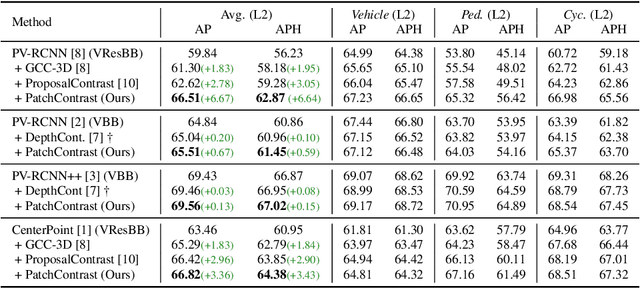
Accurately detecting objects in the environment is a key challenge for autonomous vehicles. However, obtaining annotated data for detection is expensive and time-consuming. We introduce PatchContrast, a novel self-supervised point cloud pre-training framework for 3D object detection. We propose to utilize two levels of abstraction to learn discriminative representation from unlabeled data: proposal-level and patch-level. The proposal-level aims at localizing objects in relation to their surroundings, whereas the patch-level adds information about the internal connections between the object's components, hence distinguishing between different objects based on their individual components. We demonstrate how these levels can be integrated into self-supervised pre-training for various backbones to enhance the downstream 3D detection task. We show that our method outperforms existing state-of-the-art models on three commonly-used 3D detection datasets.
HPFormer: Hyperspectral image prompt object tracking
Aug 14, 2023
Hyperspectral imagery contains abundant spectral information beyond the visible RGB bands, providing rich discriminative details about objects in a scene. Leveraging such data has the potential to enhance visual tracking performance. While prior hyperspectral trackers employ CNN or hybrid CNN-Transformer architectures, we propose a novel approach HPFormer on Transformers to capitalize on their powerful representation learning capabilities. The core of HPFormer is a Hyperspectral Hybrid Attention (HHA) module which unifies feature extraction and fusion within one component through token interactions. Additionally, a Transform Band Module (TBM) is introduced to selectively aggregate spatial details and spectral signatures from the full hyperspectral input for injecting informative target representations. Extensive experiments demonstrate state-of-the-art performance of HPFormer on benchmark NIR and VIS tracking datasets. Our work provides new insights into harnessing the strengths of transformers and hyperspectral fusion to advance robust object tracking.
Hierarchical State Abstraction Based on Structural Information Principles
Apr 24, 2023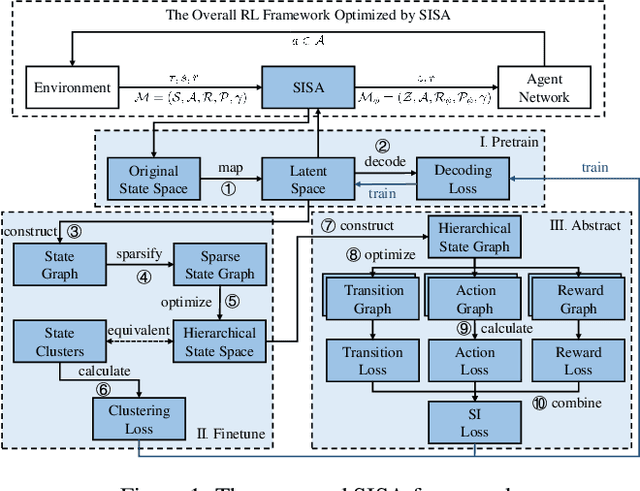

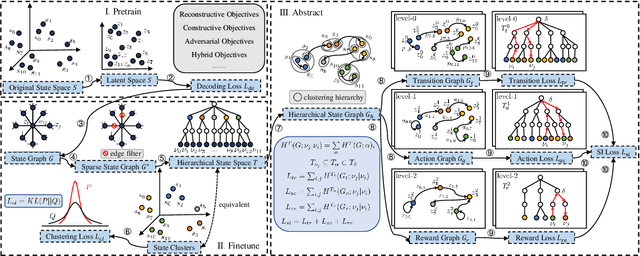
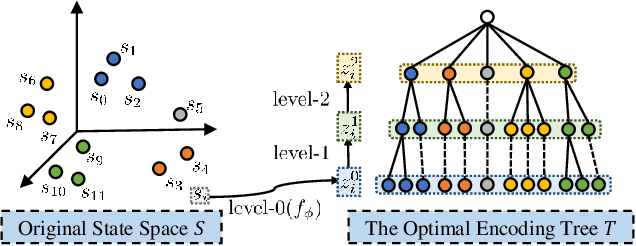
State abstraction optimizes decision-making by ignoring irrelevant environmental information in reinforcement learning with rich observations. Nevertheless, recent approaches focus on adequate representational capacities resulting in essential information loss, affecting their performances on challenging tasks. In this article, we propose a novel mathematical Structural Information principles-based State Abstraction framework, namely SISA, from the information-theoretic perspective. Specifically, an unsupervised, adaptive hierarchical state clustering method without requiring manual assistance is presented, and meanwhile, an optimal encoding tree is generated. On each non-root tree node, a new aggregation function and condition structural entropy are designed to achieve hierarchical state abstraction and compensate for sampling-induced essential information loss in state abstraction. Empirical evaluations on a visual gridworld domain and six continuous control benchmarks demonstrate that, compared with five SOTA state abstraction approaches, SISA significantly improves mean episode reward and sample efficiency up to 18.98 and 44.44%, respectively. Besides, we experimentally show that SISA is a general framework that can be flexibly integrated with different representation-learning objectives to improve their performances further.
MV-ROPE: Multi-view Constraints for Robust Category-level Object Pose and Size Estimation
Aug 17, 2023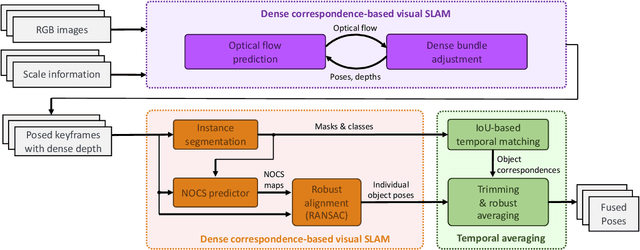
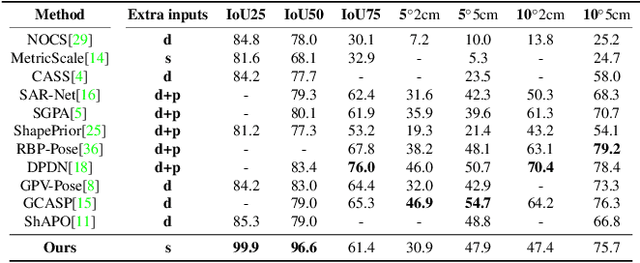
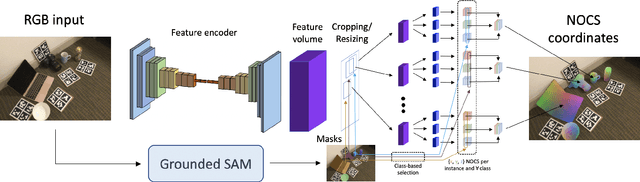

We propose a novel framework for RGB-based category-level 6D object pose and size estimation. Our approach relies on the prediction of normalized object coordinate space (NOCS), which serves as an efficient and effective object canonical representation that can be extracted from RGB images. Unlike previous approaches that heavily relied on additional depth readings as input, our novelty lies in leveraging multi-view information, which is commonly available in practical scenarios where a moving camera continuously observes the environment. By introducing multi-view constraints, we can obtain accurate camera pose and depth estimation from a monocular dense SLAM framework. Additionally, by incorporating constraints on the camera relative pose, we can apply trimming strategies and robust pose averaging on the multi-view object poses, resulting in more accurate and robust estimations of category-level object poses even in the absence of direct depth readings. Furthermore, we introduce a novel NOCS prediction network that significantly improves performance. Our experimental results demonstrate the strong performance of our proposed method, even comparable to state-of-the-art RGB-D methods across public dataset sequences. Additionally, we showcase the generalization ability of our method by evaluating it on self-collected datasets.
BOTT: Box Only Transformer Tracker for 3D Object Tracking
Aug 17, 2023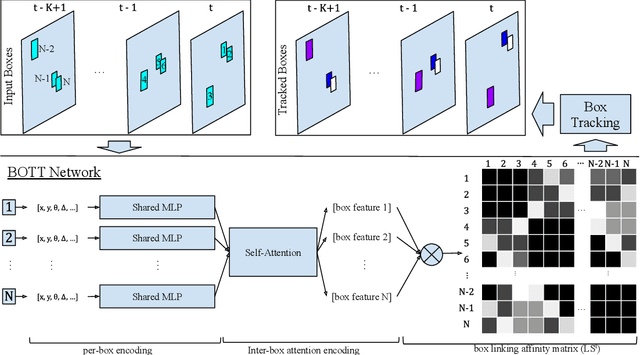
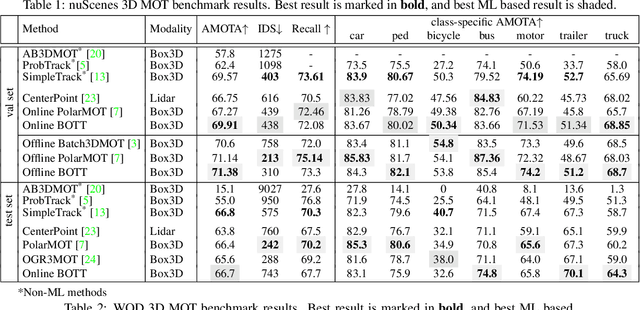
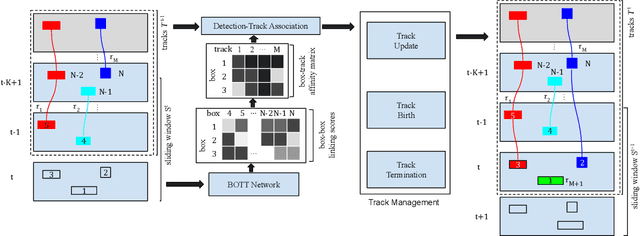
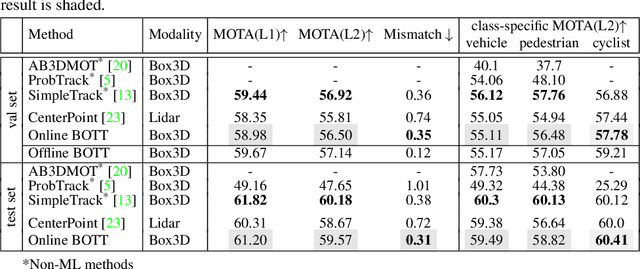
Tracking 3D objects is an important task in autonomous driving. Classical Kalman Filtering based methods are still the most popular solutions. However, these methods require handcrafted designs in motion modeling and can not benefit from the growing data amounts. In this paper, Box Only Transformer Tracker (BOTT) is proposed to learn to link 3D boxes of the same object from the different frames, by taking all the 3D boxes in a time window as input. Specifically, transformer self-attention is applied to exchange information between all the boxes to learn global-informative box embeddings. The similarity between these learned embeddings can be used to link the boxes of the same object. BOTT can be used for both online and offline tracking modes seamlessly. Its simplicity enables us to significantly reduce engineering efforts required by traditional Kalman Filtering based methods. Experiments show BOTT achieves competitive performance on two largest 3D MOT benchmarks: 69.9 and 66.7 AMOTA on nuScenes validation and test splits, respectively, 56.45 and 59.57 MOTA L2 on Waymo Open Dataset validation and test splits, respectively. This work suggests that tracking 3D objects by learning features directly from 3D boxes using transformers is a simple yet effective way.
Forensic Data Analytics for Anomaly Detection in Evolving Networks
Aug 17, 2023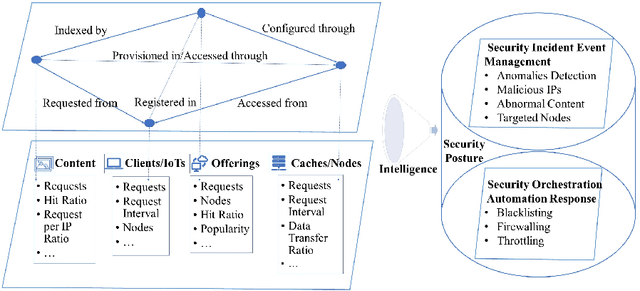
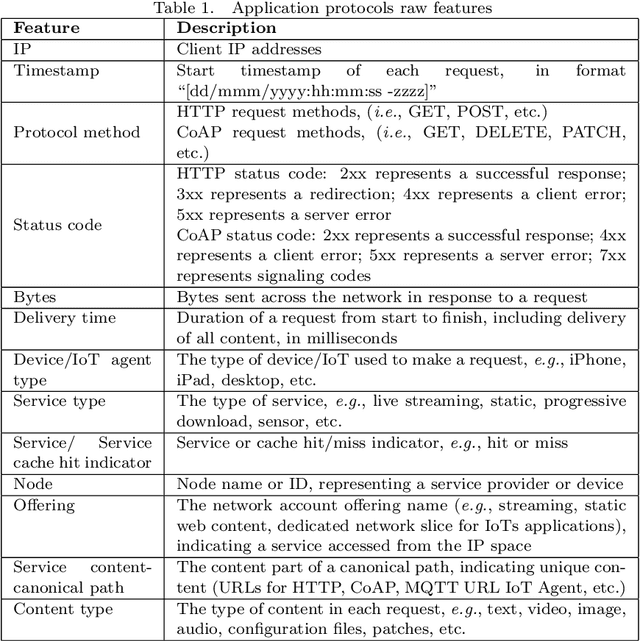
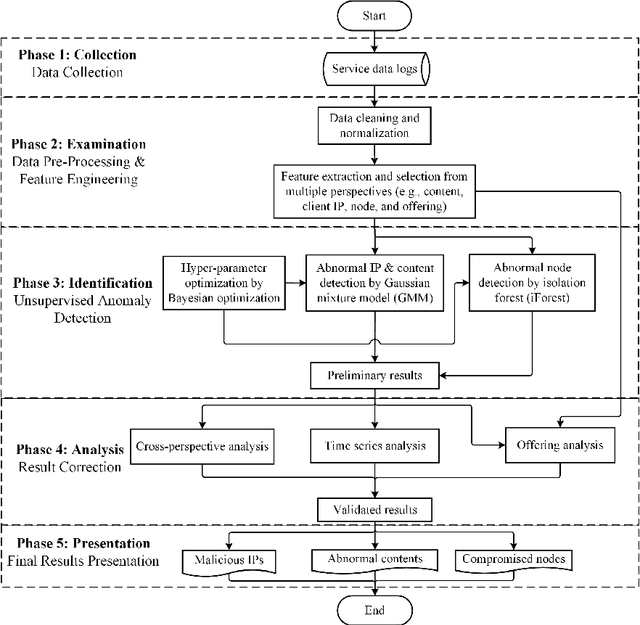
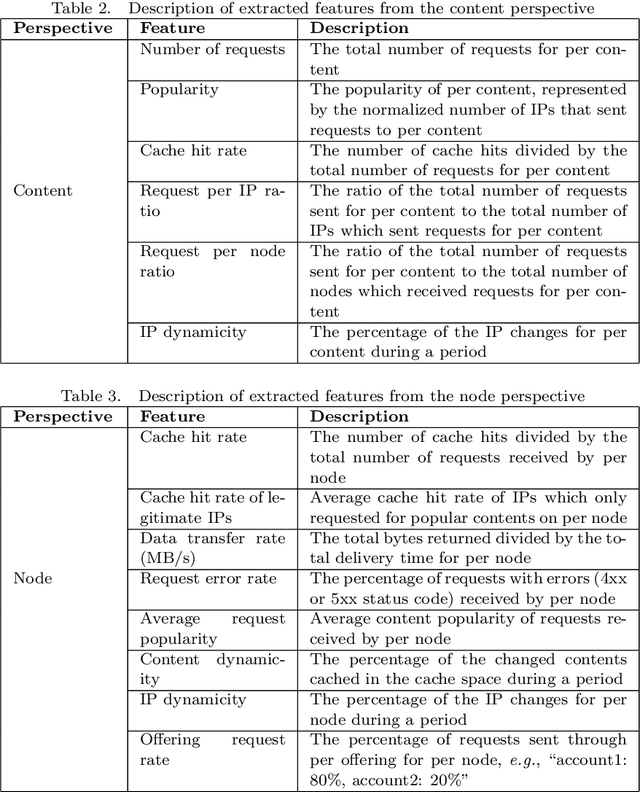
In the prevailing convergence of traditional infrastructure-based deployment (i.e., Telco and industry operational networks) towards evolving deployments enabled by 5G and virtualization, there is a keen interest in elaborating effective security controls to protect these deployments in-depth. By considering key enabling technologies like 5G and virtualization, evolving networks are democratized, facilitating the establishment of point presences integrating different business models ranging from media, dynamic web content, gaming, and a plethora of IoT use cases. Despite the increasing services provided by evolving networks, many cybercrimes and attacks have been launched in evolving networks to perform malicious activities. Due to the limitations of traditional security artifacts (e.g., firewalls and intrusion detection systems), the research on digital forensic data analytics has attracted more attention. Digital forensic analytics enables people to derive detailed information and comprehensive conclusions from different perspectives of cybercrimes to assist in convicting criminals and preventing future crimes. This chapter presents a digital analytics framework for network anomaly detection, including multi-perspective feature engineering, unsupervised anomaly detection, and comprehensive result correction procedures. Experiments on real-world evolving network data show the effectiveness of the proposed forensic data analytics solution.
Real-Time Construction Algorithm of Co-Occurrence Network Based on Inverted Index
Aug 17, 2023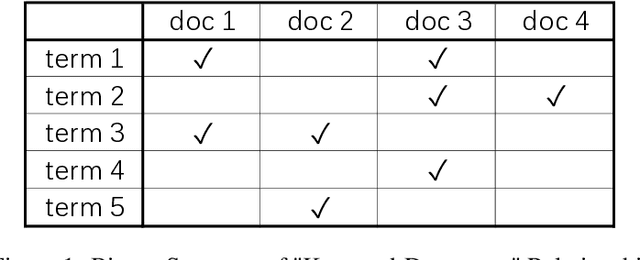
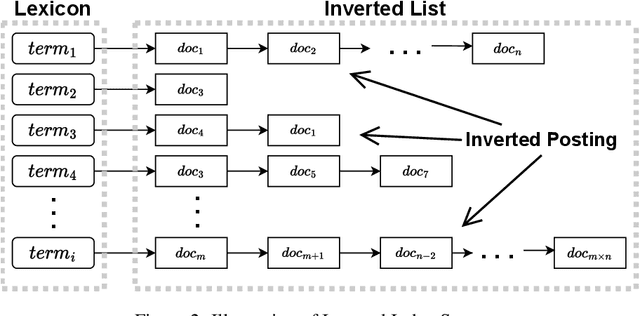
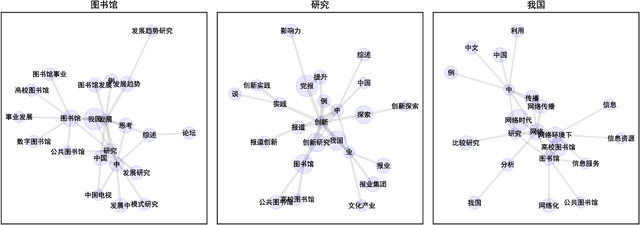
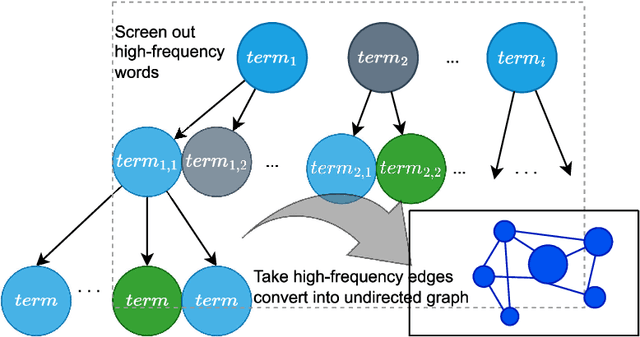
Co-occurrence networks are an important method in the field of natural language processing and text mining for discovering semantic relationships within texts. However, the traditional traversal algorithm for constructing co-occurrence networks has high time complexity and space complexity when dealing with large-scale text data. In this paper, we propose an optimized algorithm based on inverted indexing and breadth-first search to improve the efficiency of co-occurrence network construction and reduce memory consumption. Firstly, the traditional traversal algorithm is analyzed, and its performance issues in constructing co-occurrence networks are identified. Then, the detailed implementation process of the optimized algorithm is presented. Subsequently, the CSL large-scale Chinese scientific literature dataset is used for experimental validation, comparing the performance of the traditional traversal algorithm and the optimized algorithm in terms of running time and memory usage. Finally, using non-parametric test methods, the optimized algorithm is proven to have significantly better performance than the traditional traversal algorithm. The research in this paper provides an effective method for the rapid construction of co-occurrence networks, contributing to the further development of the Information Organization fields.
Multiclass Online Learnability under Bandit Feedback
Aug 08, 2023We study online multiclass classification under bandit feedback. We extend the results of (daniely2013price) by showing that the finiteness of the Bandit Littlestone dimension is necessary and sufficient for bandit online multiclass learnability even when the label space is unbounded. Our result complements the recent work by (hanneke2023multiclass) who show that the Littlestone dimension characterizes online multiclass learnability in the full-information setting when the label space is unbounded.