 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
AI in the Gray: Exploring Moderation Policies in Dialogic Large Language Models vs. Human Answers in Controversial Topics
Aug 28, 2023
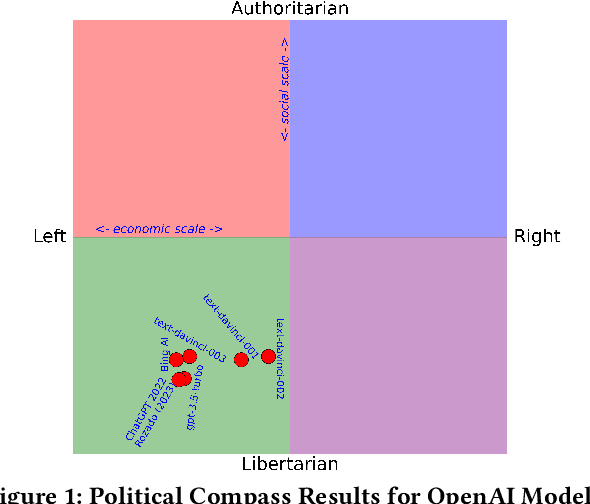

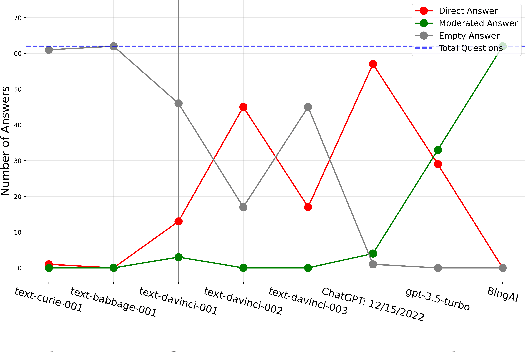

The introduction of ChatGPT and the subsequent improvement of Large Language Models (LLMs) have prompted more and more individuals to turn to the use of ChatBots, both for information and assistance with decision-making. However, the information the user is after is often not formulated by these ChatBots objectively enough to be provided with a definite, globally accepted answer. Controversial topics, such as "religion", "gender identity", "freedom of speech", and "equality", among others, can be a source of conflict as partisan or biased answers can reinforce preconceived notions or promote disinformation. By exposing ChatGPT to such debatable questions, we aim to understand its level of awareness and if existing models are subject to socio-political and/or economic biases. We also aim to explore how AI-generated answers compare to human ones. For exploring this, we use a dataset of a social media platform created for the purpose of debating human-generated claims on polemic subjects among users, dubbed Kialo. Our results show that while previous versions of ChatGPT have had important issues with controversial topics, more recent versions of ChatGPT (gpt-3.5-turbo) are no longer manifesting significant explicit biases in several knowledge areas. In particular, it is well-moderated regarding economic aspects. However, it still maintains degrees of implicit libertarian leaning toward right-winged ideals which suggest the need for increased moderation from the socio-political point of view. In terms of domain knowledge on controversial topics, with the exception of the "Philosophical" category, ChatGPT is performing well in keeping up with the collective human level of knowledge. Finally, we see that sources of Bing AI have slightly more tendency to the center when compared to human answers. All the analyses we make are generalizable to other types of biases and domains.
Adaptive Local Steps Federated Learning with Differential Privacy Driven by Convergence Analysis
Aug 21, 2023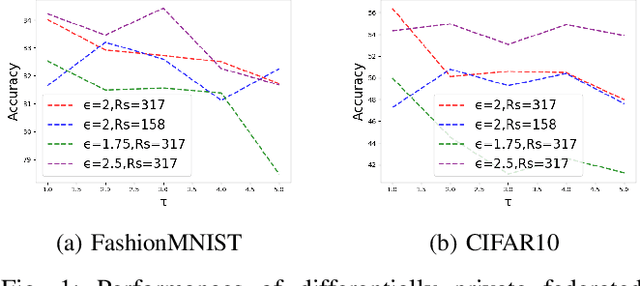
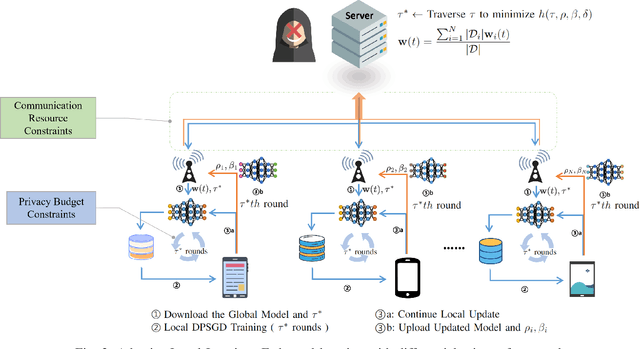
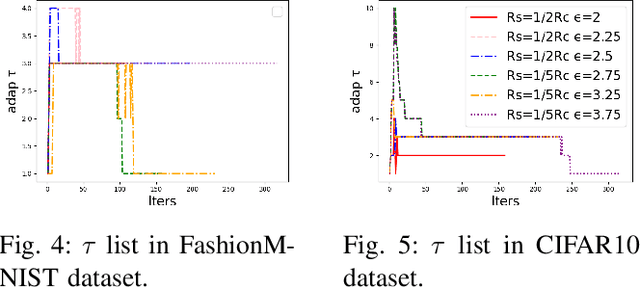
Federated Learning (FL) is a distributed machine learning technique that allows model training among multiple devices or organizations without sharing data. However, while FL ensures that the raw data is not directly accessible to external adversaries, adversaries can still obtain some statistical information about the data through differential attacks. Differential Privacy (DP) has been proposed, which adds noise to the model or gradients to prevent adversaries from inferring private information from the transmitted parameters. We reconsider the framework of differential privacy federated learning in resource-constrained scenarios (privacy budget and communication resources). We analyze the convergence of federated learning with differential privacy (DPFL) on resource-constrained scenarios and propose an Adaptive Local Steps Differential Privacy Federated Learning (ALS-DPFL) algorithm. We experiment our algorithm on the FashionMNIST and Cifar-10 datasets and achieve quite good performance relative to previous work.
DeLELSTM: Decomposition-based Linear Explainable LSTM to Capture Instantaneous and Long-term Effects in Time Series
Aug 26, 2023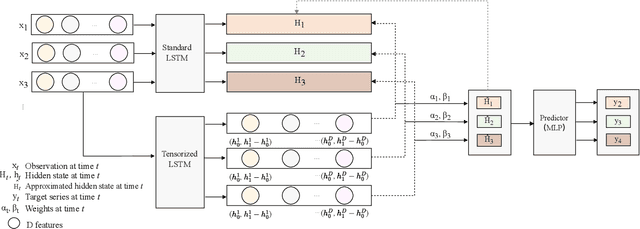


Time series forecasting is prevalent in various real-world applications. Despite the promising results of deep learning models in time series forecasting, especially the Recurrent Neural Networks (RNNs), the explanations of time series models, which are critical in high-stakes applications, have received little attention. In this paper, we propose a Decomposition-based Linear Explainable LSTM (DeLELSTM) to improve the interpretability of LSTM. Conventionally, the interpretability of RNNs only concentrates on the variable importance and time importance. We additionally distinguish between the instantaneous influence of new coming data and the long-term effects of historical data. Specifically, DeLELSTM consists of two components, i.e., standard LSTM and tensorized LSTM. The tensorized LSTM assigns each variable with a unique hidden state making up a matrix $\mathbf{h}_t$, and the standard LSTM models all the variables with a shared hidden state $\mathbf{H}_t$. By decomposing the $\mathbf{H}_t$ into the linear combination of past information $\mathbf{h}_{t-1}$ and the fresh information $\mathbf{h}_{t}-\mathbf{h}_{t-1}$, we can get the instantaneous influence and the long-term effect of each variable. In addition, the advantage of linear regression also makes the explanation transparent and clear. We demonstrate the effectiveness and interpretability of DeLELSTM on three empirical datasets. Extensive experiments show that the proposed method achieves competitive performance against the baseline methods and provides a reliable explanation relative to domain knowledge.
Application of Machine Learning in Melanoma Detection and the Identification of 'Ugly Duckling' and Suspicious Naevi: A Review
Sep 05, 2023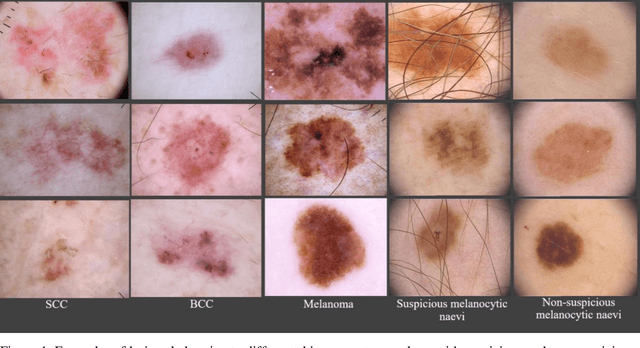

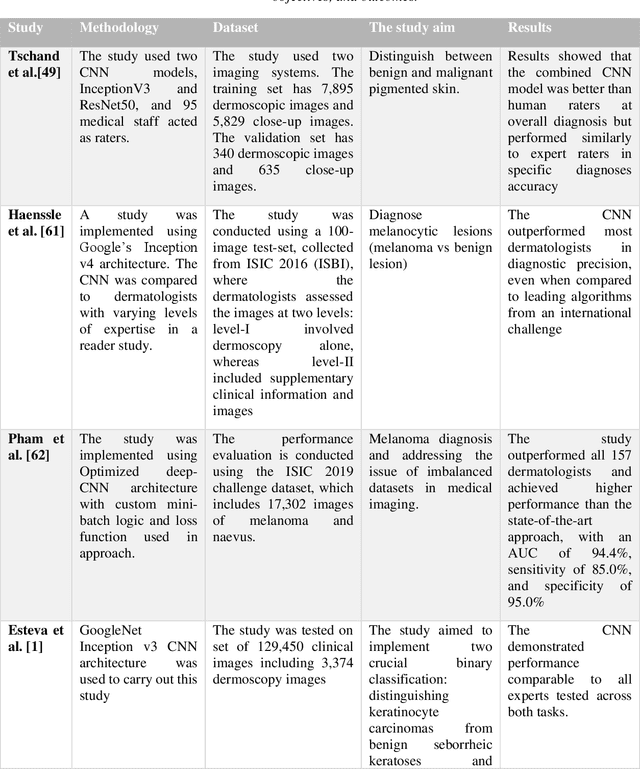
Skin lesions known as naevi exhibit diverse characteristics such as size, shape, and colouration. The concept of an "Ugly Duckling Naevus" comes into play when monitoring for melanoma, referring to a lesion with distinctive features that sets it apart from other lesions in the vicinity. As lesions within the same individual typically share similarities and follow a predictable pattern, an ugly duckling naevus stands out as unusual and may indicate the presence of a cancerous melanoma. Computer-aided diagnosis (CAD) has become a significant player in the research and development field, as it combines machine learning techniques with a variety of patient analysis methods. Its aim is to increase accuracy and simplify decision-making, all while responding to the shortage of specialized professionals. These automated systems are especially important in skin cancer diagnosis where specialist availability is limited. As a result, their use could lead to life-saving benefits and cost reductions within healthcare. Given the drastic change in survival when comparing early stage to late-stage melanoma, early detection is vital for effective treatment and patient outcomes. Machine learning (ML) and deep learning (DL) techniques have gained popularity in skin cancer classification, effectively addressing challenges, and providing results equivalent to that of specialists. This article extensively covers modern Machine Learning and Deep Learning algorithms for detecting melanoma and suspicious naevi. It begins with general information on skin cancer and different types of naevi, then introduces AI, ML, DL, and CAD. The article then discusses the successful applications of various ML techniques like convolutional neural networks (CNN) for melanoma detection compared to dermatologists' performance. Lastly, it examines ML methods for UD naevus detection and identifying suspicious naevi.
Language Models for Novelty Detection in System Call Traces
Sep 05, 2023
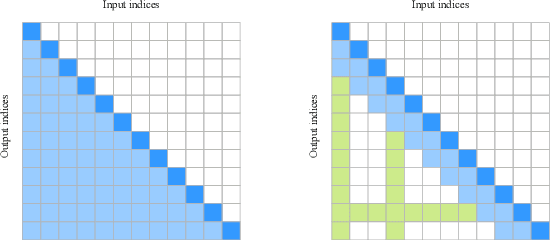
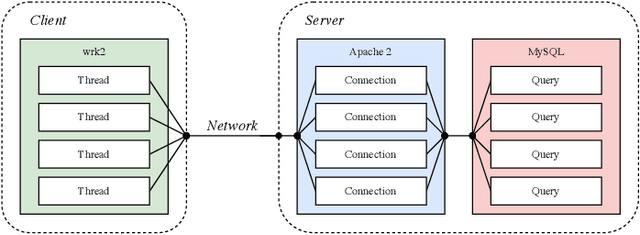
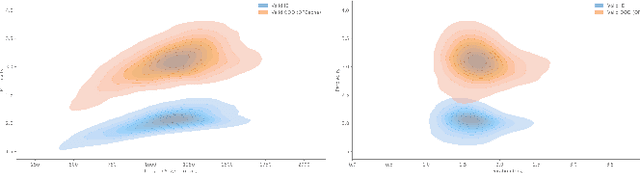
Due to the complexity of modern computer systems, novel and unexpected behaviors frequently occur. Such deviations are either normal occurrences, such as software updates and new user activities, or abnormalities, such as misconfigurations, latency issues, intrusions, and software bugs. Regardless, novel behaviors are of great interest to developers, and there is a genuine need for efficient and effective methods to detect them. Nowadays, researchers consider system calls to be the most fine-grained and accurate source of information to investigate the behavior of computer systems. Accordingly, this paper introduces a novelty detection methodology that relies on a probability distribution over sequences of system calls, which can be seen as a language model. Language models estimate the likelihood of sequences, and since novelties deviate from previously observed behaviors by definition, they would be unlikely under the model. Following the success of neural networks for language models, three architectures are evaluated in this work: the widespread LSTM, the state-of-the-art Transformer, and the lower-complexity Longformer. However, large neural networks typically require an enormous amount of data to be trained effectively, and to the best of our knowledge, no massive modern datasets of kernel traces are publicly available. This paper addresses this limitation by introducing a new open-source dataset of kernel traces comprising over 2 million web requests with seven distinct behaviors. The proposed methodology requires minimal expert hand-crafting and achieves an F-score and AuROC greater than 95% on most novelties while being data- and task-agnostic. The source code and trained models are publicly available on GitHub while the datasets are available on Zenodo.
iLoRE: Dynamic Graph Representation with Instant Long-term Modeling and Re-occurrence Preservation
Sep 05, 2023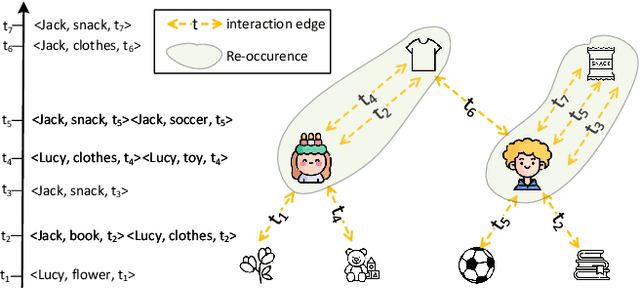

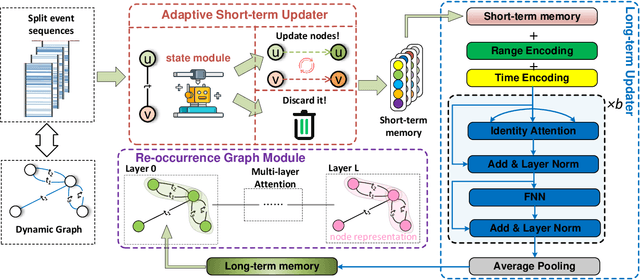
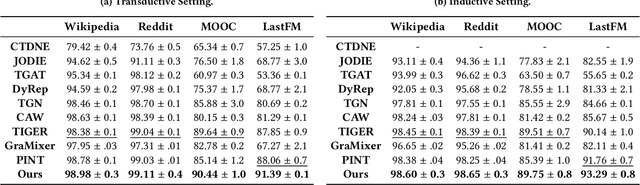
Continuous-time dynamic graph modeling is a crucial task for many real-world applications, such as financial risk management and fraud detection. Though existing dynamic graph modeling methods have achieved satisfactory results, they still suffer from three key limitations, hindering their scalability and further applicability. i) Indiscriminate updating. For incoming edges, existing methods would indiscriminately deal with them, which may lead to more time consumption and unexpected noisy information. ii) Ineffective node-wise long-term modeling. They heavily rely on recurrent neural networks (RNNs) as a backbone, which has been demonstrated to be incapable of fully capturing node-wise long-term dependencies in event sequences. iii) Neglect of re-occurrence patterns. Dynamic graphs involve the repeated occurrence of neighbors that indicates their importance, which is disappointedly neglected by existing methods. In this paper, we present iLoRE, a novel dynamic graph modeling method with instant node-wise Long-term modeling and Re-occurrence preservation. To overcome the indiscriminate updating issue, we introduce the Adaptive Short-term Updater module that will automatically discard the useless or noisy edges, ensuring iLoRE's effectiveness and instant ability. We further propose the Long-term Updater to realize more effective node-wise long-term modeling, where we innovatively propose the Identity Attention mechanism to empower a Transformer-based updater, bypassing the limited effectiveness of typical RNN-dominated designs. Finally, the crucial re-occurrence patterns are also encoded into a graph module for informative representation learning, which will further improve the expressiveness of our method. Our experimental results on real-world datasets demonstrate the effectiveness of our iLoRE for dynamic graph modeling.
The Adversarial Implications of Variable-Time Inference
Sep 05, 2023
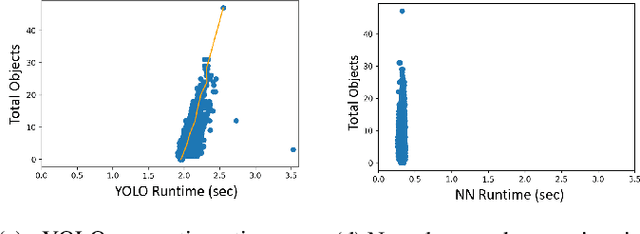
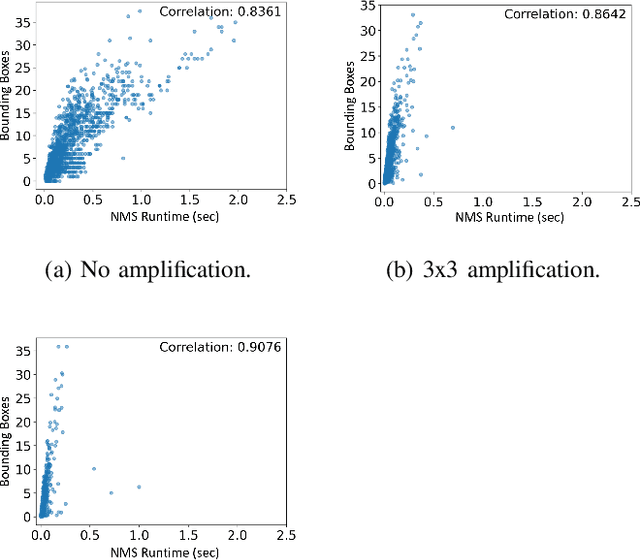
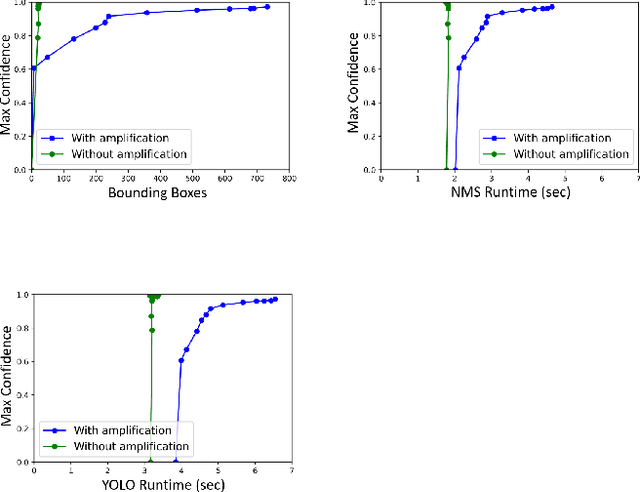
Machine learning (ML) models are known to be vulnerable to a number of attacks that target the integrity of their predictions or the privacy of their training data. To carry out these attacks, a black-box adversary must typically possess the ability to query the model and observe its outputs (e.g., labels). In this work, we demonstrate, for the first time, the ability to enhance such decision-based attacks. To accomplish this, we present an approach that exploits a novel side channel in which the adversary simply measures the execution time of the algorithm used to post-process the predictions of the ML model under attack. The leakage of inference-state elements into algorithmic timing side channels has never been studied before, and we have found that it can contain rich information that facilitates superior timing attacks that significantly outperform attacks based solely on label outputs. In a case study, we investigate leakage from the non-maximum suppression (NMS) algorithm, which plays a crucial role in the operation of object detectors. In our examination of the timing side-channel vulnerabilities associated with this algorithm, we identified the potential to enhance decision-based attacks. We demonstrate attacks against the YOLOv3 detector, leveraging the timing leakage to successfully evade object detection using adversarial examples, and perform dataset inference. Our experiments show that our adversarial examples exhibit superior perturbation quality compared to a decision-based attack. In addition, we present a new threat model in which dataset inference based solely on timing leakage is performed. To address the timing leakage vulnerability inherent in the NMS algorithm, we explore the potential and limitations of implementing constant-time inference passes as a mitigation strategy.
Towards Robust Plant Disease Diagnosis with Hard-sample Re-mining Strategy
Sep 05, 2023With rich annotation information, object detection-based automated plant disease diagnosis systems (e.g., YOLO-based systems) often provide advantages over classification-based systems (e.g., EfficientNet-based), such as the ability to detect disease locations and superior classification performance. One drawback of these detection systems is dealing with unannotated healthy data with no real symptoms present. In practice, healthy plant data appear to be very similar to many disease data. Thus, those models often produce mis-detected boxes on healthy images. In addition, labeling new data for detection models is typically time-consuming. Hard-sample mining (HSM) is a common technique for re-training a model by using the mis-detected boxes as new training samples. However, blindly selecting an arbitrary amount of hard-sample for re-training will result in the degradation of diagnostic performance for other diseases due to the high similarity between disease and healthy data. In this paper, we propose a simple but effective training strategy called hard-sample re-mining (HSReM), which is designed to enhance the diagnostic performance of healthy data and simultaneously improve the performance of disease data by strategically selecting hard-sample training images at an appropriate level. Experiments based on two practical in-field eight-class cucumber and ten-class tomato datasets (42.7K and 35.6K images) show that our HSReM training strategy leads to a substantial improvement in the overall diagnostic performance on large-scale unseen data. Specifically, the object detection model trained using the HSReM strategy not only achieved superior results as compared to the classification-based state-of-the-art EfficientNetV2-Large model and the original object detection model, but also outperformed the model using the HSM strategy.
ChatGPT Assisting Diagnosis of Neuro-ophthalmology Diseases Based on Case Reports
Sep 05, 2023Objective: To evaluate the efficiency of large language models (LLMs) such as ChatGPT to assist in diagnosing neuro-ophthalmic diseases based on detailed case descriptions. Methods: We selected 22 different case reports of neuro-ophthalmic diseases from a publicly available online database. These cases included a wide range of chronic and acute diseases that are commonly seen by neuro-ophthalmic sub-specialists. We inserted the text from each case as a new prompt into both ChatGPT v3.5 and ChatGPT Plus v4.0 and asked for the most probable diagnosis. We then presented the exact information to two neuro-ophthalmologists and recorded their diagnoses followed by comparison to responses from both versions of ChatGPT. Results: ChatGPT v3.5, ChatGPT Plus v4.0, and the two neuro-ophthalmologists were correct in 13 (59%), 18 (82%), 19 (86%), and 19 (86%) out of 22 cases, respectively. The agreement between the various diagnostic sources were as follows: ChatGPT v3.5 and ChatGPT Plus v4.0, 13 (59%); ChatGPT v3.5 and the first neuro-ophthalmologist, 12 (55%); ChatGPT v3.5 and the second neuro-ophthalmologist, 12 (55%); ChatGPT Plus v4.0 and the first neuro-ophthalmologist, 17 (77%); ChatGPT Plus v4.0 and the second neuro-ophthalmologist, 16 (73%); and first and second neuro-ophthalmologists 17 (17%). Conclusions: The accuracy of ChatGPT v3.5 and ChatGPT Plus v4.0 in diagnosing patients with neuro-ophthalmic diseases was 59% and 82%, respectively. With further development, ChatGPT Plus v4.0 may have potential to be used in clinical care settings to assist clinicians in providing quick, accurate diagnoses of patients in neuro-ophthalmology. The applicability of using LLMs like ChatGPT in clinical settings that lack access to subspeciality trained neuro-ophthalmologists deserves further research.
Bayesian-Boosted MetaLoc: Efficient Training and Enhanced Generalization for Indoor Localization
Aug 28, 2023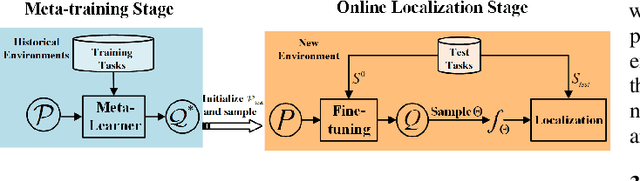
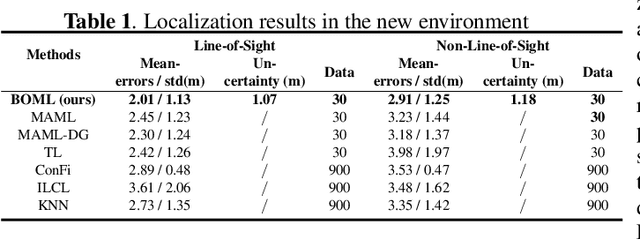
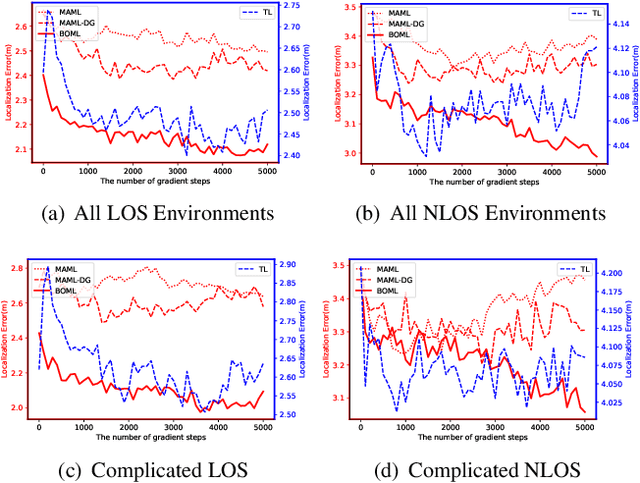
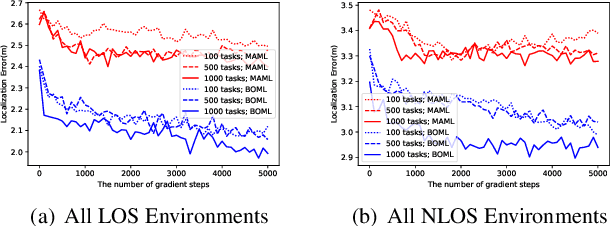
Existing localization approaches utilizing environment-specific channel state information (CSI) excel under specific environment but struggle to generalize across varied environments. This challenge becomes even more pronounced when confronted with limited training data. To address these issues, we present the Bayes-Optimal Meta-Learning for Localization (BOML-Loc) framework, inspired by the PAC-Optimal Hyper-Posterior (PACOH) algorithm. Improving on our earlier MetaLoc, BOML-Loc employs a Bayesian approach, reducing the need for extensive training and lowering overfitting risk. Even with limited training tasks, BOML-Loc guarantees robust localization and impressive generalization. In both LOS and NLOS environments with site-surveyed data, BOML-Loc surpasses existing models, demonstrating enhanced localization accuracy and reduced overfitting in new environments.