 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnleashing Worms and Extracting Data: Escalating the Outcome of Attacks against RAG-based Inference in Scale and Severity Using Jailbreaking
Sep 12, 2024In this paper, we show that with the ability to jailbreak a GenAI model, attackers can escalate the outcome of attacks against RAG-based GenAI-powered applications in severity and scale. In the first part of the paper, we show that attackers can escalate RAG membership inference attacks and RAG entity extraction attacks to RAG documents extraction attacks, forcing a more severe outcome compared to existing attacks. We evaluate the results obtained from three extraction methods, the influence of the type and the size of five embeddings algorithms employed, the size of the provided context, and the GenAI engine. We show that attackers can extract 80%-99.8% of the data stored in the database used by the RAG of a Q&A chatbot. In the second part of the paper, we show that attackers can escalate the scale of RAG data poisoning attacks from compromising a single GenAI-powered application to compromising the entire GenAI ecosystem, forcing a greater scale of damage. This is done by crafting an adversarial self-replicating prompt that triggers a chain reaction of a computer worm within the ecosystem and forces each affected application to perform a malicious activity and compromise the RAG of additional applications. We evaluate the performance of the worm in creating a chain of confidential data extraction about users within a GenAI ecosystem of GenAI-powered email assistants and analyze how the performance of the worm is affected by the size of the context, the adversarial self-replicating prompt used, the type and size of the embeddings algorithm employed, and the number of hops in the propagation. Finally, we review and analyze guardrails to protect RAG-based inference and discuss the tradeoffs.
A Jailbroken GenAI Model Can Cause Substantial Harm: GenAI-powered Applications are Vulnerable to PromptWares
Aug 09, 2024



In this paper we argue that a jailbroken GenAI model can cause substantial harm to GenAI-powered applications and facilitate PromptWare, a new type of attack that flips the GenAI model's behavior from serving an application to attacking it. PromptWare exploits user inputs to jailbreak a GenAI model to force/perform malicious activity within the context of a GenAI-powered application. First, we introduce a naive implementation of PromptWare that behaves as malware that targets Plan & Execute architectures (a.k.a., ReAct, function calling). We show that attackers could force a desired execution flow by creating a user input that produces desired outputs given that the logic of the GenAI-powered application is known to attackers. We demonstrate the application of a DoS attack that triggers the execution of a GenAI-powered assistant to enter an infinite loop that wastes money and computational resources on redundant API calls to a GenAI engine, preventing the application from providing service to a user. Next, we introduce a more sophisticated implementation of PromptWare that we name Advanced PromptWare Threat (APwT) that targets GenAI-powered applications whose logic is unknown to attackers. We show that attackers could create user input that exploits the GenAI engine's advanced AI capabilities to launch a kill chain in inference time consisting of six steps intended to escalate privileges, analyze the application's context, identify valuable assets, reason possible malicious activities, decide on one of them, and execute it. We demonstrate the application of APwT against a GenAI-powered e-commerce chatbot and show that it can trigger the modification of SQL tables, potentially leading to unauthorized discounts on the items sold to the user.
The Adversarial Implications of Variable-Time Inference
Sep 05, 2023



Machine learning (ML) models are known to be vulnerable to a number of attacks that target the integrity of their predictions or the privacy of their training data. To carry out these attacks, a black-box adversary must typically possess the ability to query the model and observe its outputs (e.g., labels). In this work, we demonstrate, for the first time, the ability to enhance such decision-based attacks. To accomplish this, we present an approach that exploits a novel side channel in which the adversary simply measures the execution time of the algorithm used to post-process the predictions of the ML model under attack. The leakage of inference-state elements into algorithmic timing side channels has never been studied before, and we have found that it can contain rich information that facilitates superior timing attacks that significantly outperform attacks based solely on label outputs. In a case study, we investigate leakage from the non-maximum suppression (NMS) algorithm, which plays a crucial role in the operation of object detectors. In our examination of the timing side-channel vulnerabilities associated with this algorithm, we identified the potential to enhance decision-based attacks. We demonstrate attacks against the YOLOv3 detector, leveraging the timing leakage to successfully evade object detection using adversarial examples, and perform dataset inference. Our experiments show that our adversarial examples exhibit superior perturbation quality compared to a decision-based attack. In addition, we present a new threat model in which dataset inference based solely on timing leakage is performed. To address the timing leakage vulnerability inherent in the NMS algorithm, we explore the potential and limitations of implementing constant-time inference passes as a mitigation strategy.
Latent SHAP: Toward Practical Human-Interpretable Explanations
Nov 27, 2022



Model agnostic feature attribution algorithms (such as SHAP and LIME) are ubiquitous techniques for explaining the decisions of complex classification models, such as deep neural networks. However, since complex classification models produce superior performance when trained on low-level (or encoded) features, in many cases, the explanations generated by these algorithms are neither interpretable nor usable by humans. Methods proposed in recent studies that support the generation of human-interpretable explanations are impractical, because they require a fully invertible transformation function that maps the model's input features to the human-interpretable features. In this work, we introduce Latent SHAP, a black-box feature attribution framework that provides human-interpretable explanations, without the requirement for a fully invertible transformation function. We demonstrate Latent SHAP's effectiveness using (1) a controlled experiment where invertible transformation functions are available, which enables robust quantitative evaluation of our method, and (2) celebrity attractiveness classification (using the CelebA dataset) where invertible transformation functions are not available, which enables thorough qualitative evaluation of our method.
Attacking Object Detector Using A Universal Targeted Label-Switch Patch
Nov 16, 2022Adversarial attacks against deep learning-based object detectors (ODs) have been studied extensively in the past few years. These attacks cause the model to make incorrect predictions by placing a patch containing an adversarial pattern on the target object or anywhere within the frame. However, none of prior research proposed a misclassification attack on ODs, in which the patch is applied on the target object. In this study, we propose a novel, universal, targeted, label-switch attack against the state-of-the-art object detector, YOLO. In our attack, we use (i) a tailored projection function to enable the placement of the adversarial patch on multiple target objects in the image (e.g., cars), each of which may be located a different distance away from the camera or have a different view angle relative to the camera, and (ii) a unique loss function capable of changing the label of the attacked objects. The proposed universal patch, which is trained in the digital domain, is transferable to the physical domain. We performed an extensive evaluation using different types of object detectors, different video streams captured by different cameras, and various target classes, and evaluated different configurations of the adversarial patch in the physical domain.
Improving Interpretability via Regularization of Neural Activation Sensitivity
Nov 16, 2022



State-of-the-art deep neural networks (DNNs) are highly effective at tackling many real-world tasks. However, their wide adoption in mission-critical contexts is hampered by two major weaknesses - their susceptibility to adversarial attacks and their opaqueness. The former raises concerns about the security and generalization of DNNs in real-world conditions, whereas the latter impedes users' trust in their output. In this research, we (1) examine the effect of adversarial robustness on interpretability and (2) present a novel approach for improving the interpretability of DNNs that is based on regularization of neural activation sensitivity. We evaluate the interpretability of models trained using our method to that of standard models and models trained using state-of-the-art adversarial robustness techniques. Our results show that adversarially robust models are superior to standard models and that models trained using our proposed method are even better than adversarially robust models in terms of interpretability.
Adversarial Machine Learning Threat Analysis in Open Radio Access Networks
Jan 16, 2022

The Open Radio Access Network (O-RAN) is a new, open, adaptive, and intelligent RAN architecture. Motivated by the success of artificial intelligence in other domains, O-RAN strives to leverage machine learning (ML) to automatically and efficiently manage network resources in diverse use cases such as traffic steering, quality of experience prediction, and anomaly detection. Unfortunately, ML-based systems are not free of vulnerabilities; specifically, they suffer from a special type of logical vulnerabilities that stem from the inherent limitations of the learning algorithms. To exploit these vulnerabilities, an adversary can utilize an attack technique referred to as adversarial machine learning (AML). These special type of attacks has already been demonstrated in recent researches. In this paper, we present a systematic AML threat analysis for the O-RAN. We start by reviewing relevant ML use cases and analyzing the different ML workflow deployment scenarios in O-RAN. Then, we define the threat model, identifying potential adversaries, enumerating their adversarial capabilities, and analyzing their main goals. Finally, we explore the various AML threats in the O-RAN and review a large number of attacks that can be performed to materialize these threats and demonstrate an AML attack on a traffic steering model.
A Framework for Evaluating the Cybersecurity Risk of Real World, Machine Learning Production Systems
Jul 05, 2021

Although cyberattacks on machine learning (ML) production systems can be destructive, many industry practitioners are ill equipped, lacking tactical and strategic tools that would allow them to analyze, detect, protect against, and respond to cyberattacks targeting their ML-based systems. In this paper, we take a significant step toward securing ML production systems by integrating these systems and their vulnerabilities into cybersecurity risk assessment frameworks. Specifically, we performed a comprehensive threat analysis of ML production systems and developed an extension to the MulVAL attack graph generation and analysis framework to incorporate cyberattacks on ML production systems. Using the proposed extension, security practitioners can apply attack graph analysis methods in environments that include ML components, thus providing security experts with a practical tool for evaluating the impact and quantifying the risk of a cyberattack targeting an ML production system.
Adversarial robustness via stochastic regularization of neural activation sensitivity
Sep 23, 2020
Recent works have shown that the input domain of any machine learning classifier is bound to contain adversarial examples. Thus we can no longer hope to immune classifiers against adversarial examples and instead can only aim to achieve the following two defense goals: 1) making adversarial examples harder to find, or 2) weakening their adversarial nature by pushing them further away from correctly classified data points. Most if not all the previously suggested defense mechanisms attend to just one of those two goals, and as such, could be bypassed by adaptive attacks that take the defense mechanism into consideration. In this work we suggest a novel defense mechanism that simultaneously addresses both defense goals: We flatten the gradients of the loss surface, making adversarial examples harder to find, using a novel stochastic regularization term that explicitly decreases the sensitivity of individual neurons to small input perturbations. In addition, we push the decision boundary away from correctly classified inputs by leveraging Jacobian regularization. We present a solid theoretical basis and an empirical testing of our suggested approach, demonstrate its superiority over previously suggested defense mechanisms, and show that it is effective against a wide range of adaptive attacks.
An Automated, End-to-End Framework for Modeling Attacks From Vulnerability Descriptions
Aug 10, 2020
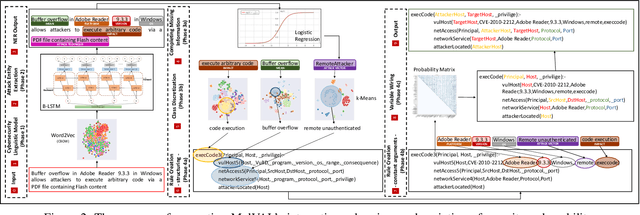
Attack graphs are one of the main techniques used to automate the risk assessment process. In order to derive a relevant attack graph, up-to-date information on known attack techniques should be represented as interaction rules. Designing and creating new interaction rules is not a trivial task and currently performed manually by security experts. However, since the number of new security vulnerabilities and attack techniques continuously and rapidly grows, there is a need to frequently update the rule set of attack graph tools with new attack techniques to ensure that the set of interaction rules is always up-to-date. We present a novel, end-to-end, automated framework for modeling new attack techniques from textual description of a security vulnerability. Given a description of a security vulnerability, the proposed framework first extracts the relevant attack entities required to model the attack, completes missing information on the vulnerability, and derives a new interaction rule that models the attack; this new rule is integrated within MulVAL attack graph tool. The proposed framework implements a novel pipeline that includes a dedicated cybersecurity linguistic model trained on the the NVD repository, a recurrent neural network model used for attack entity extraction, a logistic regression model used for completing the missing information, and a novel machine learning-based approach for automatically modeling the attacks as MulVAL's interaction rule. We evaluated the performance of each of the individual algorithms, as well as the complete framework and demonstrated its effectiveness.