 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
l-dyno: framework to learn consistent visual features using robot's motion
Oct 10, 2023
Historically, feature-based approaches have been used extensively for camera-based robot perception tasks such as localization, mapping, tracking, and others. Several of these approaches also combine other sensors (inertial sensing, for example) to perform combined state estimation. Our work rethinks this approach; we present a representation learning mechanism that identifies visual features that best correspond to robot motion as estimated by an external signal. Specifically, we utilize the robot's transformations through an external signal (inertial sensing, for example) and give attention to image space that is most consistent with the external signal. We use a pairwise consistency metric as a representation to keep the visual features consistent through a sequence with the robot's relative pose transformations. This approach enables us to incorporate information from the robot's perspective instead of solely relying on the image attributes. We evaluate our approach on real-world datasets such as KITTI & EuRoC and compare the refined features with existing feature descriptors. We also evaluate our method using our real robot experiment. We notice an average of 49% reduction in the image search space without compromising the trajectory estimation accuracy. Our method reduces the execution time of visual odometry by 4.3% and also reduces reprojection errors. We demonstrate the need to select only the most important features and show the competitiveness using various feature detection baselines.
Advancing Pose-Guided Image Synthesis with Progressive Conditional Diffusion Models
Oct 10, 2023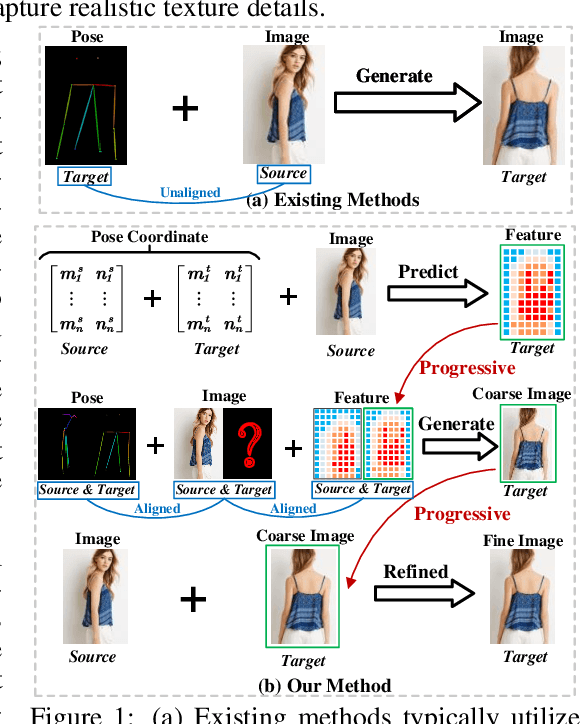
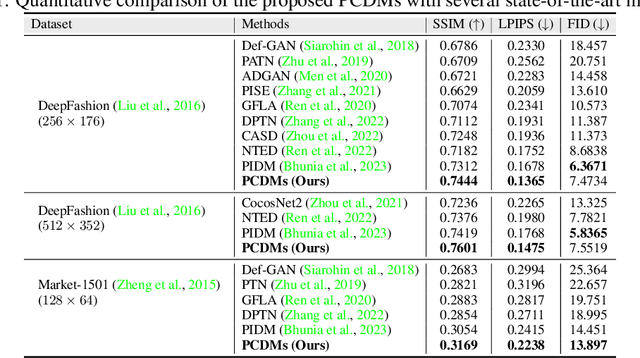
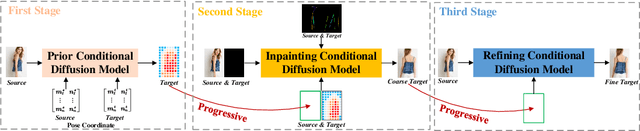
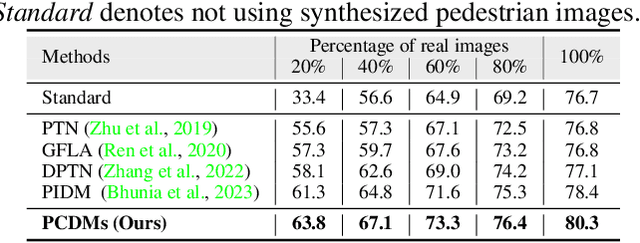
Recent work has showcased the significant potential of diffusion models in pose-guided person image synthesis. However, owing to the inconsistency in pose between the source and target images, synthesizing an image with a distinct pose, relying exclusively on the source image and target pose information, remains a formidable challenge. This paper presents Progressive Conditional Diffusion Models (PCDMs) that incrementally bridge the gap between person images under the target and source poses through three stages. Specifically, in the first stage, we design a simple prior conditional diffusion model that predicts the global features of the target image by mining the global alignment relationship between pose coordinates and image appearance. Then, the second stage establishes a dense correspondence between the source and target images using the global features from the previous stage, and an inpainting conditional diffusion model is proposed to further align and enhance the contextual features, generating a coarse-grained person image. In the third stage, we propose a refining conditional diffusion model to utilize the coarsely generated image from the previous stage as a condition, achieving texture restoration and enhancing fine-detail consistency. The three-stage PCDMs work progressively to generate the final high-quality and high-fidelity synthesized image. Both qualitative and quantitative results demonstrate the consistency and photorealism of our proposed PCDMs under challenging scenarios.The code and model will be available at https://github.com/muzishen/PCDMs.
Distributed Evolution Strategies with Multi-Level Learning for Large-Scale Black-Box Optimization
Oct 10, 2023In the post-Moore era, the main performance gains of black-box optimizers are increasingly depending upon parallelism, especially for large-scale optimization (LSO). In this paper, we propose to parallelize the well-established covariance matrix adaptation evolution strategy (CMA-ES) and in particular its one latest variant called limited-memory CMA (LM-CMA) for LSO. To achieve scalability while maintaining the invariance property as much as possible, we present a multilevel learning-based meta-framework. Owing to its hierarchically organized structure, Meta-ES is well-suited to implement our distributed meta-framework, wherein the outer-ES controls strategy parameters while all parallel inner-ESs run the serial LM-CMA with different settings. For the distribution mean update of the outer-ES, both the elitist and multi-recombination strategy are used in parallel to avoid stagnation and regression, respectively. To exploit spatiotemporal information, the global step-size adaptation combines Meta-ES with the parallel cumulative step-size adaptation. After each isolation time, our meta-framework employs both the structure and parameter learning strategy to combine aligned evolution paths for CMA reconstruction. Experiments on a set of large-scale benchmarking functions with memory-intensive evaluations, arguably reflecting many data-driven optimization problems, validate the benefits (e.g., scalability w.r.t. CPU cores, effectiveness w.r.t. solution quality, and adaptability w.r.t. second-order learning) and costs of our meta-framework.
A Black-Box Physics-Informed Estimator based on Gaussian Process Regression for Robot Inverse Dynamics Identification
Oct 10, 2023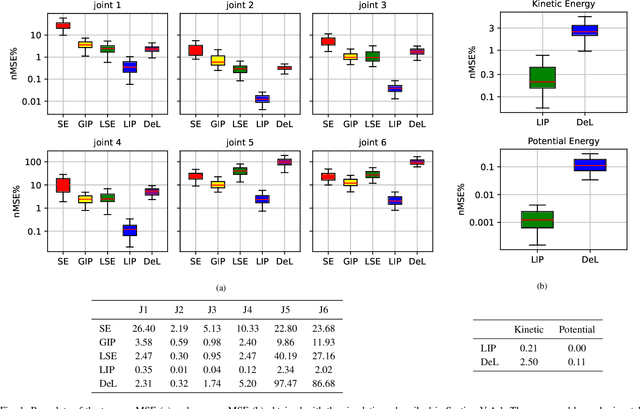
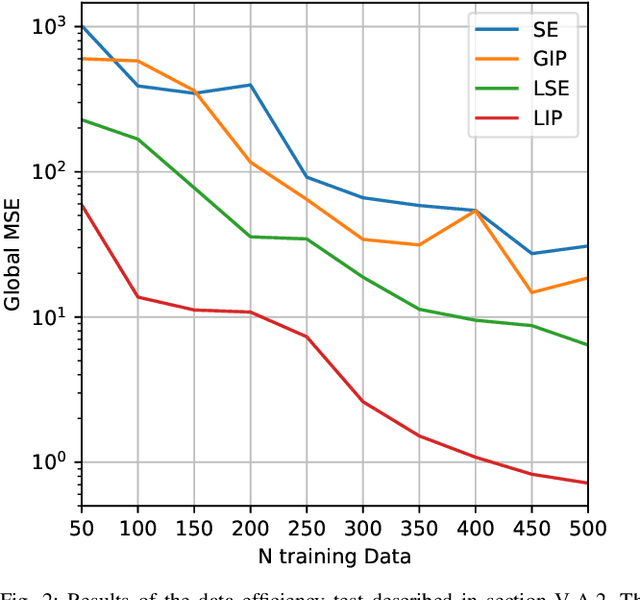
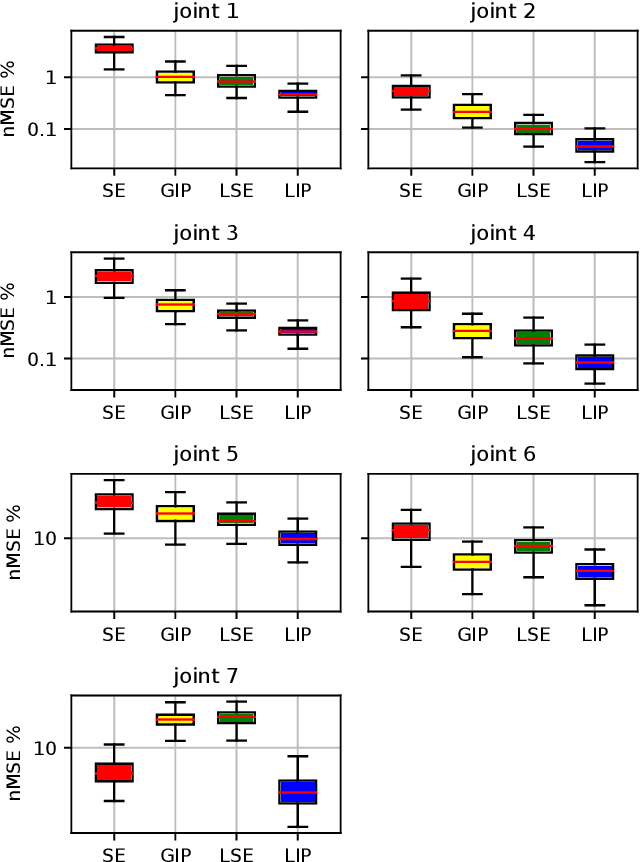
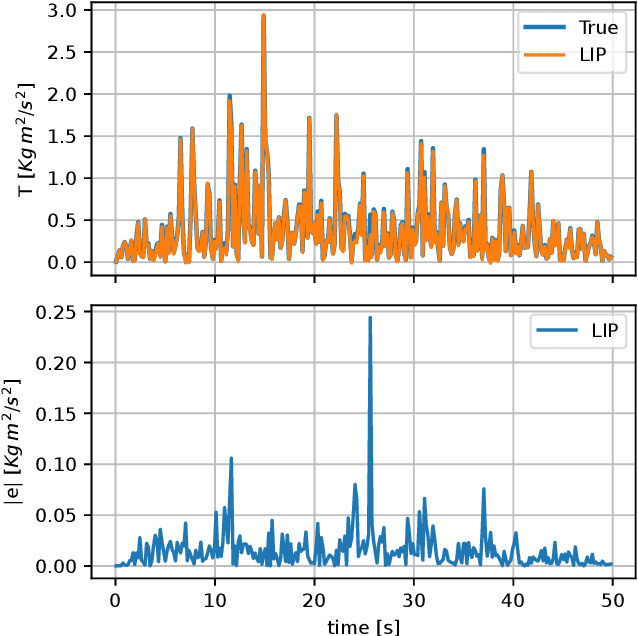
In this paper, we propose a black-box model based on Gaussian process regression for the identification of the inverse dynamics of robotic manipulators. The proposed model relies on a novel multidimensional kernel, called \textit{Lagrangian Inspired Polynomial} (\kernelInitials{}) kernel. The \kernelInitials{} kernel is based on two main ideas. First, instead of directly modeling the inverse dynamics components, we model as GPs the kinetic and potential energy of the system. The GP prior on the inverse dynamics components is derived from those on the energies by applying the properties of GPs under linear operators. Second, as regards the energy prior definition, we prove a polynomial structure of the kinetic and potential energy, and we derive a polynomial kernel that encodes this property. As a consequence, the proposed model allows also to estimate the kinetic and potential energy without requiring any label on these quantities. Results on simulation and on two real robotic manipulators, namely a 7 DOF Franka Emika Panda and a 6 DOF MELFA RV4FL, show that the proposed model outperforms state-of-the-art black-box estimators based both on Gaussian Processes and Neural Networks in terms of accuracy, generality and data efficiency. The experiments on the MELFA robot also demonstrate that our approach achieves performance comparable to fine-tuned model-based estimators, despite requiring less prior information.
Compositional Representation Learning for Brain Tumour Segmentation
Oct 10, 2023For brain tumour segmentation, deep learning models can achieve human expert-level performance given a large amount of data and pixel-level annotations. However, the expensive exercise of obtaining pixel-level annotations for large amounts of data is not always feasible, and performance is often heavily reduced in a low-annotated data regime. To tackle this challenge, we adapt a mixed supervision framework, vMFNet, to learn robust compositional representations using unsupervised learning and weak supervision alongside non-exhaustive pixel-level pathology labels. In particular, we use the BraTS dataset to simulate a collection of 2-point expert pathology annotations indicating the top and bottom slice of the tumour (or tumour sub-regions: peritumoural edema, GD-enhancing tumour, and the necrotic / non-enhancing tumour) in each MRI volume, from which weak image-level labels that indicate the presence or absence of the tumour (or the tumour sub-regions) in the image are constructed. Then, vMFNet models the encoded image features with von-Mises-Fisher (vMF) distributions, via learnable and compositional vMF kernels which capture information about structures in the images. We show that good tumour segmentation performance can be achieved with a large amount of weakly labelled data but only a small amount of fully-annotated data. Interestingly, emergent learning of anatomical structures occurs in the compositional representation even given only supervision relating to pathology (tumour).
ChannelComp: A General Method for Computation by Communications
Oct 10, 2023Over-the-air computation (AirComp) is a well-known technique by which several wireless devices transmit by analog amplitude modulation to achieve a sum of their transmit signals at a common receiver. The underlying physical principle is the superposition property of the radio waves. Since such superposition is analog and in amplitude, it is natural that AirComp uses analog amplitude modulations. Unfortunately, this is impractical because most wireless devices today use digital modulations. It would be highly desirable to use digital communications because of their numerous benefits, such as error correction, synchronization, acquisition of channel state information, and widespread use. However, when we use digital modulations for AirComp, a general belief is that the superposition property of the radio waves returns a meaningless overlapping of the digital signals. In this paper, we break through such beliefs and propose an entirely new digital channel computing method named ChannelComp, which can use digital as well as analog modulations. We propose a feasibility optimization problem that ascertains the optimal modulation for computing arbitrary functions over-the-air. Additionally, we propose pre-coders to adapt existing digital modulation schemes for computing the function over the multiple access channel. The simulation results verify the superior performance of ChannelComp compared to AirComp, particularly for the product functions, with more than 10 dB improvement of the computation error.
NLPBench: Evaluating Large Language Models on Solving NLP Problems
Oct 08, 2023Recent developments in large language models (LLMs) have shown promise in enhancing the capabilities of natural language processing (NLP). Despite these successes, there remains a dearth of research dedicated to the NLP problem-solving abilities of LLMs. To fill the gap in this area, we present a unique benchmarking dataset, NLPBench, comprising 378 college-level NLP questions spanning various NLP topics sourced from Yale University's prior final exams. NLPBench includes questions with context, in which multiple sub-questions share the same public information, and diverse question types, including multiple choice, short answer, and math. Our evaluation, centered on LLMs such as GPT-3.5/4, PaLM-2, and LLAMA-2, incorporates advanced prompting strategies like the chain-of-thought (CoT) and tree-of-thought (ToT). Our study reveals that the effectiveness of the advanced prompting strategies can be inconsistent, occasionally damaging LLM performance, especially in smaller models like the LLAMA-2 (13b). Furthermore, our manual assessment illuminated specific shortcomings in LLMs' scientific problem-solving skills, with weaknesses in logical decomposition and reasoning notably affecting results.
Fully Spiking Neural Network for Legged Robots
Oct 08, 2023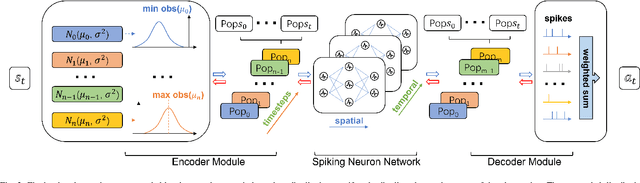
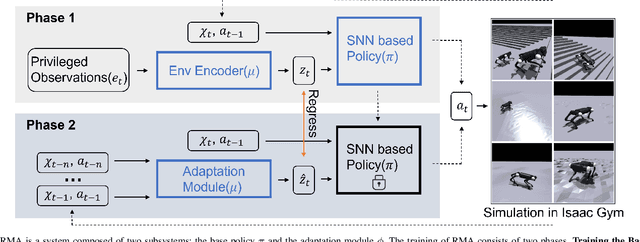
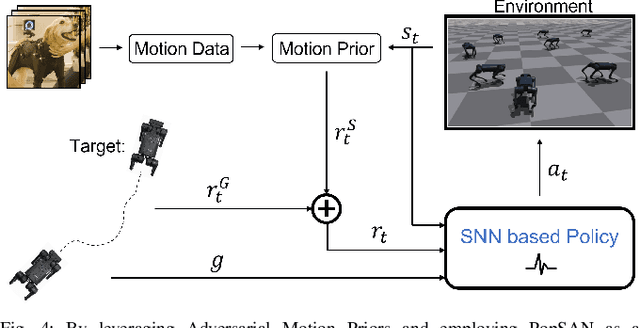
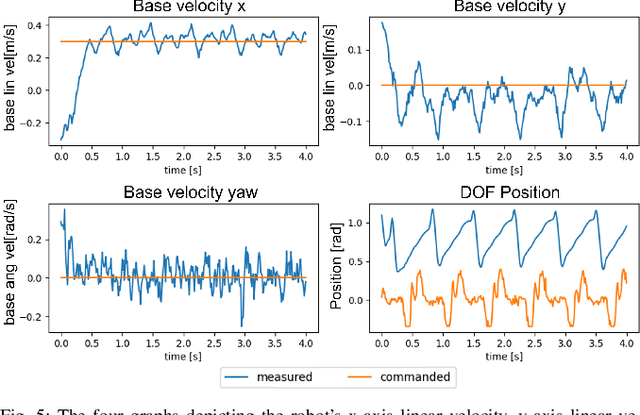
In recent years, legged robots based on deep reinforcement learning have made remarkable progress. Quadruped robots have demonstrated the ability to complete challenging tasks in complex environments and have been deployed in real-world scenarios to assist humans. Simultaneously, bipedal and humanoid robots have achieved breakthroughs in various demanding tasks. Current reinforcement learning methods can utilize diverse robot bodies and historical information to perform actions. However, prior research has not emphasized the speed and energy consumption of network inference, as well as the biological significance of the neural networks themselves. Most of the networks employed are traditional artificial neural networks that utilize multilayer perceptrons (MLP). In this paper, we successfully apply a novel Spiking Neural Network (SNN) to process legged robots, achieving outstanding results across a range of simulated terrains. SNN holds a natural advantage over traditional neural networks in terms of inference speed and energy consumption, and their pulse-form processing of body perception signals offers improved biological interpretability. To the best of our knowledge, this is the first work to implement SNN in legged robots.
Harnessing the Power of ChatGPT in Fake News: An In-Depth Exploration in Generation, Detection and Explanation
Oct 08, 2023
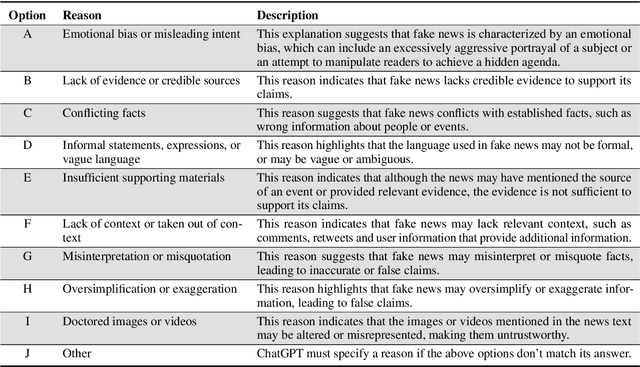
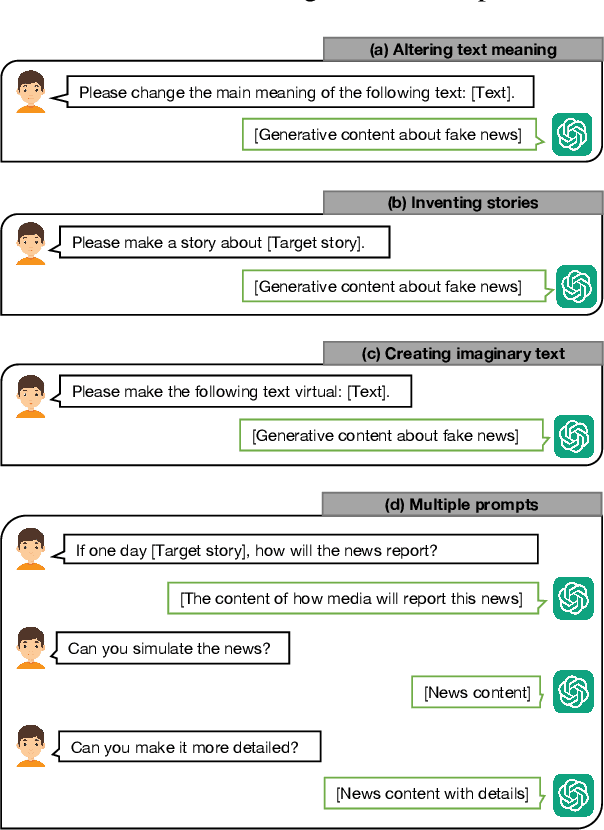

The rampant spread of fake news has adversely affected society, resulting in extensive research on curbing its spread. As a notable milestone in large language models (LLMs), ChatGPT has gained significant attention due to its exceptional natural language processing capabilities. In this study, we present a thorough exploration of ChatGPT's proficiency in generating, explaining, and detecting fake news as follows. Generation -- We employ four prompt methods to generate fake news samples and prove the high quality of these samples through both self-assessment and human evaluation. Explanation -- We obtain nine features to characterize fake news based on ChatGPT's explanations and analyze the distribution of these factors across multiple public datasets. Detection -- We examine ChatGPT's capacity to identify fake news. We explore its detection consistency and then propose a reason-aware prompt method to improve its performance. Although our experiments demonstrate that ChatGPT shows commendable performance in detecting fake news, there is still room for its improvement. Consequently, we further probe into the potential extra information that could bolster its effectiveness in detecting fake news.
MenatQA: A New Dataset for Testing the Temporal Comprehension and Reasoning Abilities of Large Language Models
Oct 08, 2023

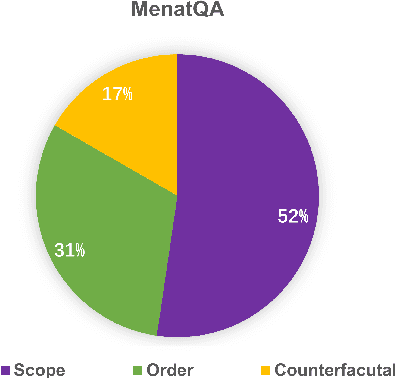
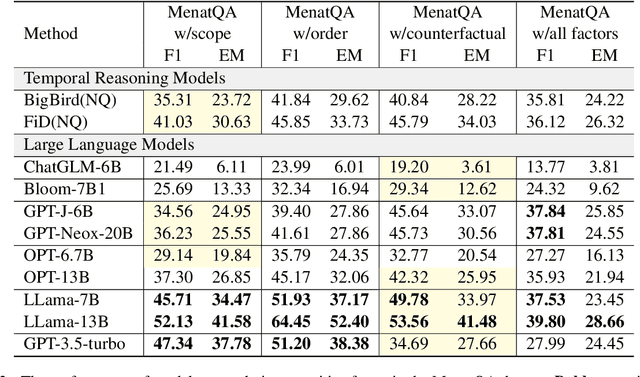
Large language models (LLMs) have shown nearly saturated performance on many natural language processing (NLP) tasks. As a result, it is natural for people to believe that LLMs have also mastered abilities such as time understanding and reasoning. However, research on the temporal sensitivity of LLMs has been insufficiently emphasized. To fill this gap, this paper constructs Multiple Sensitive Factors Time QA (MenatQA), which encompasses three temporal factors (scope factor, order factor, counterfactual factor) with total 2,853 samples for evaluating the time comprehension and reasoning abilities of LLMs. This paper tests current mainstream LLMs with different parameter sizes, ranging from billions to hundreds of billions. The results show most LLMs fall behind smaller temporal reasoning models with different degree on these factors. In specific, LLMs show a significant vulnerability to temporal biases and depend heavily on the temporal information provided in questions. Furthermore, this paper undertakes a preliminary investigation into potential improvement strategies by devising specific prompts and leveraging external tools. These approaches serve as valuable baselines or references for future research endeavors.