 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
SLIQ: Quantum Image Similarity Networks on Noisy Quantum Computers
Sep 26, 2023
Exploration into quantum machine learning has grown tremendously in recent years due to the ability of quantum computers to speed up classical programs. However, these efforts have yet to solve unsupervised similarity detection tasks due to the challenge of porting them to run on quantum computers. To overcome this challenge, we propose SLIQ, the first open-sourced work for resource-efficient quantum similarity detection networks, built with practical and effective quantum learning and variance-reducing algorithms.
1st Place Solution of Egocentric 3D Hand Pose Estimation Challenge 2023 Technical Report:A Concise Pipeline for Egocentric Hand Pose Reconstruction
Oct 10, 2023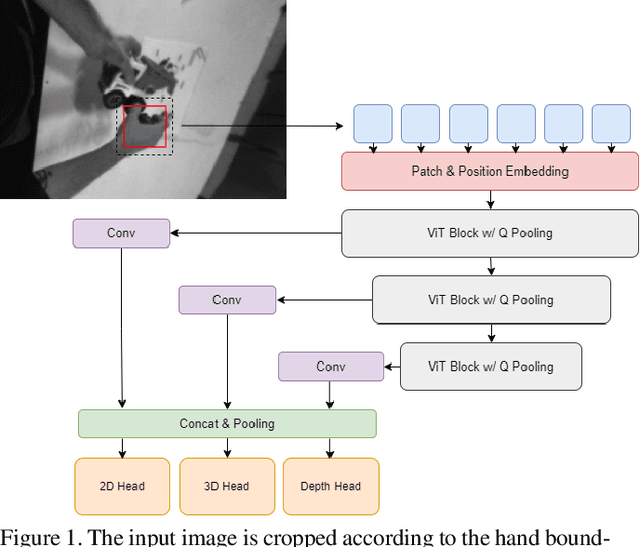

This report introduce our work on Egocentric 3D Hand Pose Estimation workshop. Using AssemblyHands, this challenge focuses on egocentric 3D hand pose estimation from a single-view image. In the competition, we adopt ViT based backbones and a simple regressor for 3D keypoints prediction, which provides strong model baselines. We noticed that Hand-objects occlusions and self-occlusions lead to performance degradation, thus proposed a non-model method to merge multi-view results in the post-process stage. Moreover, We utilized test time augmentation and model ensemble to make further improvement. We also found that public dataset and rational preprocess are beneficial. Our method achieved 12.21mm MPJPE on test dataset, achieve the first place in Egocentric 3D Hand Pose Estimation challenge.
Pixel State Value Network for Combined Prediction and Planning in Interactive Environments
Oct 11, 2023Automated vehicles operating in urban environments have to reliably interact with other traffic participants. Planning algorithms often utilize separate prediction modules forecasting probabilistic, multi-modal, and interactive behaviors of objects. Designing prediction and planning as two separate modules introduces significant challenges, particularly due to the interdependence of these modules. This work proposes a deep learning methodology to combine prediction and planning. A conditional GAN with the U-Net architecture is trained to predict two high-resolution image sequences. The sequences represent explicit motion predictions, mainly used to train context understanding, and pixel state values suitable for planning encoding kinematic reachability, object dynamics, safety, and driving comfort. The model can be trained offline on target images rendered by a sampling-based model-predictive planner, leveraging real-world driving data. Our results demonstrate intuitive behavior in complex situations, such as lane changes amidst conflicting objectives.
Generalized Neural Sorting Networks with Error-Free Differentiable Swap Functions
Oct 11, 2023Sorting is a fundamental operation of all computer systems, having been a long-standing significant research topic. Beyond the problem formulation of traditional sorting algorithms, we consider sorting problems for more abstract yet expressive inputs, e.g., multi-digit images and image fragments, through a neural sorting network. To learn a mapping from a high-dimensional input to an ordinal variable, the differentiability of sorting networks needs to be guaranteed. In this paper we define a softening error by a differentiable swap function, and develop an error-free swap function that holds non-decreasing and differentiability conditions. Furthermore, a permutation-equivariant Transformer network with multi-head attention is adopted to capture dependency between given inputs and also leverage its model capacity with self-attention. Experiments on diverse sorting benchmarks show that our methods perform better than or comparable to baseline methods.
Drivable Avatar Clothing: Faithful Full-Body Telepresence with Dynamic Clothing Driven by Sparse RGB-D Input
Oct 11, 2023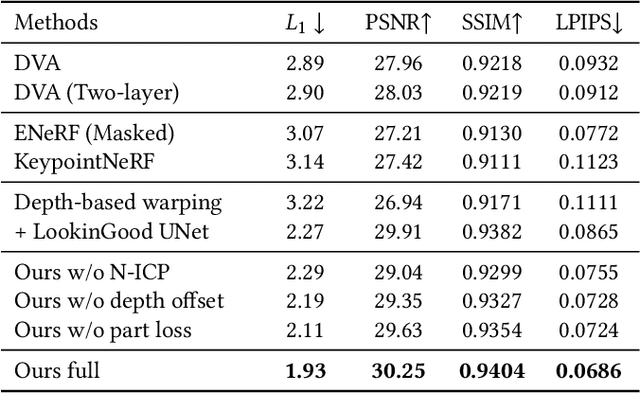


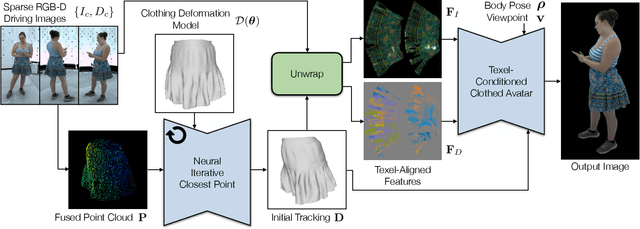
Clothing is an important part of human appearance but challenging to model in photorealistic avatars. In this work we present avatars with dynamically moving loose clothing that can be faithfully driven by sparse RGB-D inputs as well as body and face motion. We propose a Neural Iterative Closest Point (N-ICP) algorithm that can efficiently track the coarse garment shape given sparse depth input. Given the coarse tracking results, the input RGB-D images are then remapped to texel-aligned features, which are fed into the drivable avatar models to faithfully reconstruct appearance details. We evaluate our method against recent image-driven synthesis baselines, and conduct a comprehensive analysis of the N-ICP algorithm. We demonstrate that our method can generalize to a novel testing environment, while preserving the ability to produce high-fidelity and faithful clothing dynamics and appearance.
Semantic Scene Difference Detection in Daily Life Patroling by Mobile Robots using Pre-Trained Large-Scale Vision-Language Model
Sep 28, 2023It is important for daily life support robots to detect changes in their environment and perform tasks. In the field of anomaly detection in computer vision, probabilistic and deep learning methods have been used to calculate the image distance. These methods calculate distances by focusing on image pixels. In contrast, this study aims to detect semantic changes in the daily life environment using the current development of large-scale vision-language models. Using its Visual Question Answering (VQA) model, we propose a method to detect semantic changes by applying multiple questions to a reference image and a current image and obtaining answers in the form of sentences. Unlike deep learning-based methods in anomaly detection, this method does not require any training or fine-tuning, is not affected by noise, and is sensitive to semantic state changes in the real world. In our experiments, we demonstrated the effectiveness of this method by applying it to a patrol task in a real-life environment using a mobile robot, Fetch Mobile Manipulator. In the future, it may be possible to add explanatory power to changes in the daily life environment through spoken language.
LOVECon: Text-driven Training-Free Long Video Editing with ControlNet
Oct 15, 2023Leveraging pre-trained conditional diffusion models for video editing without further tuning has gained increasing attention due to its promise in film production, advertising, etc. Yet, seminal works in this line fall short in generation length, temporal coherence, or fidelity to the source video. This paper aims to bridge the gap, establishing a simple and effective baseline for training-free diffusion model-based long video editing. As suggested by prior arts, we build the pipeline upon ControlNet, which excels at various image editing tasks based on text prompts. To break down the length constraints caused by limited computational memory, we split the long video into consecutive windows and develop a novel cross-window attention mechanism to ensure the consistency of global style and maximize the smoothness among windows. To achieve more accurate control, we extract the information from the source video via DDIM inversion and integrate the outcomes into the latent states of the generations. We also incorporate a video frame interpolation model to mitigate the frame-level flickering issue. Extensive empirical studies verify the superior efficacy of our method over competing baselines across scenarios, including the replacement of the attributes of foreground objects, style transfer, and background replacement. In particular, our method manages to edit videos with up to 128 frames according to user requirements. Code is available at https://github.com/zhijie-group/LOVECon.
FuseSR: Super Resolution for Real-time Rendering through Efficient Multi-resolution Fusion
Oct 15, 2023The workload of real-time rendering is steeply increasing as the demand for high resolution, high refresh rates, and high realism rises, overwhelming most graphics cards. To mitigate this problem, one of the most popular solutions is to render images at a low resolution to reduce rendering overhead, and then manage to accurately upsample the low-resolution rendered image to the target resolution, a.k.a. super-resolution techniques. Most existing methods focus on exploiting information from low-resolution inputs, such as historical frames. The absence of high frequency details in those LR inputs makes them hard to recover fine details in their high-resolution predictions. In this paper, we propose an efficient and effective super-resolution method that predicts high-quality upsampled reconstructions utilizing low-cost high-resolution auxiliary G-Buffers as additional input. With LR images and HR G-buffers as input, the network requires to align and fuse features at multi resolution levels. We introduce an efficient and effective H-Net architecture to solve this problem and significantly reduce rendering overhead without noticeable quality deterioration. Experiments show that our method is able to produce temporally consistent reconstructions in $4 \times 4$ and even challenging $8 \times 8$ upsampling cases at 4K resolution with real-time performance, with substantially improved quality and significant performance boost compared to existing works.
Self-Supervised Neuron Segmentation with Multi-Agent Reinforcement Learning
Oct 06, 2023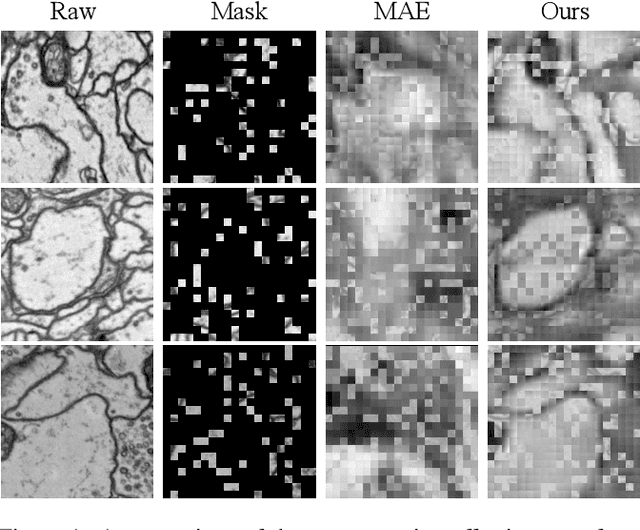
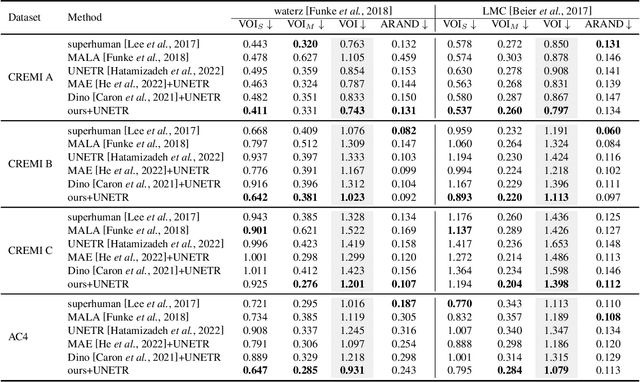
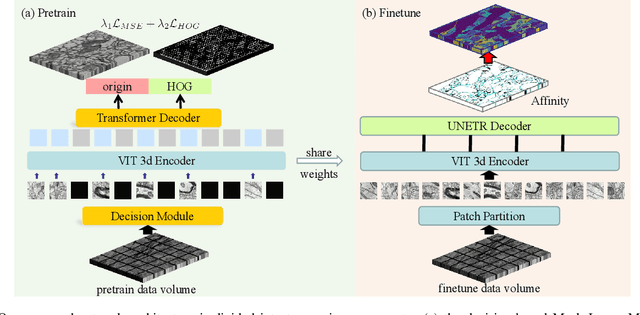
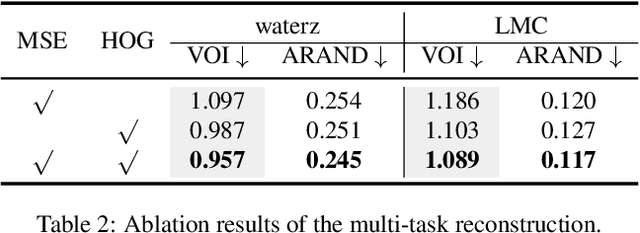
The performance of existing supervised neuron segmentation methods is highly dependent on the number of accurate annotations, especially when applied to large scale electron microscopy (EM) data. By extracting semantic information from unlabeled data, self-supervised methods can improve the performance of downstream tasks, among which the mask image model (MIM) has been widely used due to its simplicity and effectiveness in recovering original information from masked images. However, due to the high degree of structural locality in EM images, as well as the existence of considerable noise, many voxels contain little discriminative information, making MIM pretraining inefficient on the neuron segmentation task. To overcome this challenge, we propose a decision-based MIM that utilizes reinforcement learning (RL) to automatically search for optimal image masking ratio and masking strategy. Due to the vast exploration space, using single-agent RL for voxel prediction is impractical. Therefore, we treat each input patch as an agent with a shared behavior policy, allowing for multi-agent collaboration. Furthermore, this multi-agent model can capture dependencies between voxels, which is beneficial for the downstream segmentation task. Experiments conducted on representative EM datasets demonstrate that our approach has a significant advantage over alternative self-supervised methods on the task of neuron segmentation. Code is available at \url{https://github.com/ydchen0806/dbMiM}.
ClusVPR: Efficient Visual Place Recognition with Clustering-based Weighted Transformer
Oct 06, 2023

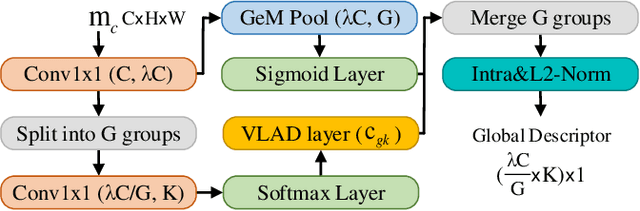
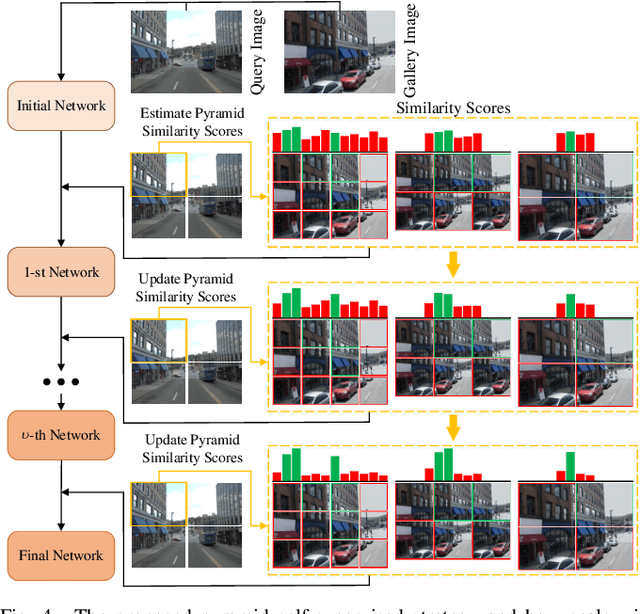
Visual place recognition (VPR) is a highly challenging task that has a wide range of applications, including robot navigation and self-driving vehicles. VPR is particularly difficult due to the presence of duplicate regions and the lack of attention to small objects in complex scenes, resulting in recognition deviations. In this paper, we present ClusVPR, a novel approach that tackles the specific issues of redundant information in duplicate regions and representations of small objects. Different from existing methods that rely on Convolutional Neural Networks (CNNs) for feature map generation, ClusVPR introduces a unique paradigm called Clustering-based Weighted Transformer Network (CWTNet). CWTNet leverages the power of clustering-based weighted feature maps and integrates global dependencies to effectively address visual deviations encountered in large-scale VPR problems. We also introduce the optimized-VLAD (OptLAD) layer that significantly reduces the number of parameters and enhances model efficiency. This layer is specifically designed to aggregate the information obtained from scale-wise image patches. Additionally, our pyramid self-supervised strategy focuses on extracting representative and diverse information from scale-wise image patches instead of entire images, which is crucial for capturing representative and diverse information in VPR. Extensive experiments on four VPR datasets show our model's superior performance compared to existing models while being less complex.