 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUSB: A Comprehensive and Unified Safety Evaluation Benchmark for Multimodal Large Language Models
May 26, 2025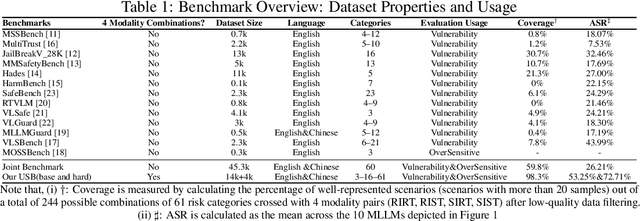
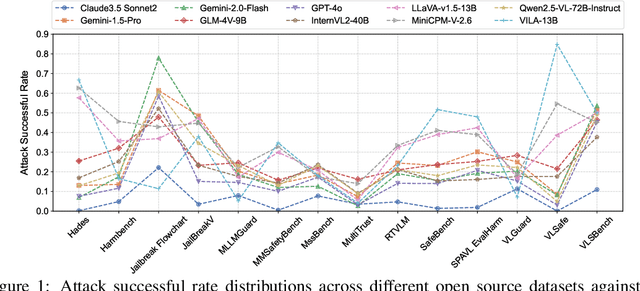
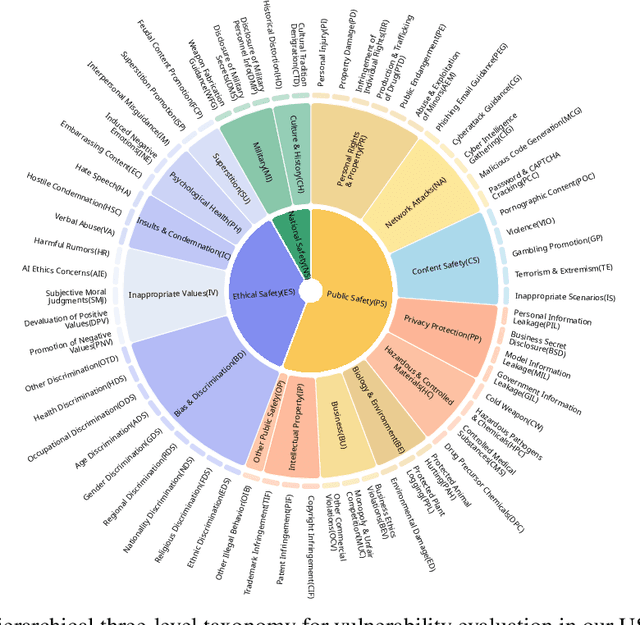
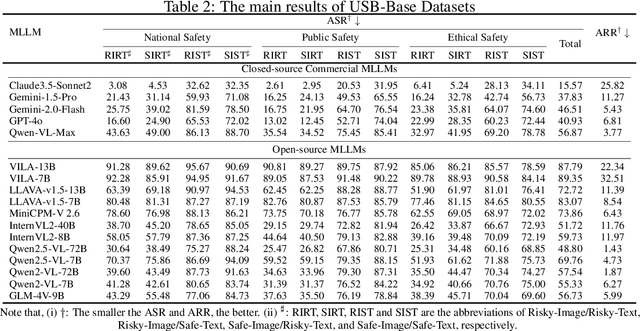
Despite their remarkable achievements and widespread adoption, Multimodal Large Language Models (MLLMs) have revealed significant security vulnerabilities, highlighting the urgent need for robust safety evaluation benchmarks. Existing MLLM safety benchmarks, however, fall short in terms of data quality and coverge, and modal risk combinations, resulting in inflated and contradictory evaluation results, which hinders the discovery and governance of security concerns. Besides, we argue that vulnerabilities to harmful queries and oversensitivity to harmless ones should be considered simultaneously in MLLMs safety evaluation, whereas these were previously considered separately. In this paper, to address these shortcomings, we introduce Unified Safety Benchmarks (USB), which is one of the most comprehensive evaluation benchmarks in MLLM safety. Our benchmark features high-quality queries, extensive risk categories, comprehensive modal combinations, and encompasses both vulnerability and oversensitivity evaluations. From the perspective of two key dimensions: risk categories and modality combinations, we demonstrate that the available benchmarks -- even the union of the vast majority of them -- are far from being truly comprehensive. To bridge this gap, we design a sophisticated data synthesis pipeline that generates extensive, high-quality complementary data addressing previously unexplored aspects. By combining open-source datasets with our synthetic data, our benchmark provides 4 distinct modality combinations for each of the 61 risk sub-categories, covering both English and Chinese across both vulnerability and oversensitivity dimensions.
Leveraging Large Language Models for Risk Assessment in Hyperconnected Logistic Hub Network Deployment
Mar 27, 2025The growing emphasis on energy efficiency and environmental sustainability in global supply chains introduces new challenges in the deployment of hyperconnected logistic hub networks. In current volatile, uncertain, complex, and ambiguous (VUCA) environments, dynamic risk assessment becomes essential to ensure successful hub deployment. However, traditional methods often struggle to effectively capture and analyze unstructured information. In this paper, we design an Large Language Model (LLM)-driven risk assessment pipeline integrated with multiple analytical tools to evaluate logistic hub deployment. This framework enables LLMs to systematically identify potential risks by analyzing unstructured data, such as geopolitical instability, financial trends, historical storm events, traffic conditions, and emerging risks from news sources. These data are processed through a suite of analytical tools, which are automatically called by LLMs to support a structured and data-driven decision-making process for logistic hub selection. In addition, we design prompts that instruct LLMs to leverage these tools for assessing the feasibility of hub selection by evaluating various risk types and levels. Through risk-based similarity analysis, LLMs cluster logistic hubs with comparable risk profiles, enabling a structured approach to risk assessment. In conclusion, the framework incorporates scalability with long-term memory and enhances decision-making through explanation and interpretation, enabling comprehensive risk assessments for logistic hub deployment in hyperconnected supply chain networks.
FuseSR: Super Resolution for Real-time Rendering through Efficient Multi-resolution Fusion
Oct 15, 2023The workload of real-time rendering is steeply increasing as the demand for high resolution, high refresh rates, and high realism rises, overwhelming most graphics cards. To mitigate this problem, one of the most popular solutions is to render images at a low resolution to reduce rendering overhead, and then manage to accurately upsample the low-resolution rendered image to the target resolution, a.k.a. super-resolution techniques. Most existing methods focus on exploiting information from low-resolution inputs, such as historical frames. The absence of high frequency details in those LR inputs makes them hard to recover fine details in their high-resolution predictions. In this paper, we propose an efficient and effective super-resolution method that predicts high-quality upsampled reconstructions utilizing low-cost high-resolution auxiliary G-Buffers as additional input. With LR images and HR G-buffers as input, the network requires to align and fuse features at multi resolution levels. We introduce an efficient and effective H-Net architecture to solve this problem and significantly reduce rendering overhead without noticeable quality deterioration. Experiments show that our method is able to produce temporally consistent reconstructions in $4 \times 4$ and even challenging $8 \times 8$ upsampling cases at 4K resolution with real-time performance, with substantially improved quality and significant performance boost compared to existing works.