 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Tell2Design: A Dataset for Language-Guided Floor Plan Generation
Nov 27, 2023
We consider the task of generating designs directly from natural language descriptions, and consider floor plan generation as the initial research area. Language conditional generative models have recently been very successful in generating high-quality artistic images. However, designs must satisfy different constraints that are not present in generating artistic images, particularly spatial and relational constraints. We make multiple contributions to initiate research on this task. First, we introduce a novel dataset, \textit{Tell2Design} (T2D), which contains more than $80k$ floor plan designs associated with natural language instructions. Second, we propose a Sequence-to-Sequence model that can serve as a strong baseline for future research. Third, we benchmark this task with several text-conditional image generation models. We conclude by conducting human evaluations on the generated samples and providing an analysis of human performance. We hope our contributions will propel the research on language-guided design generation forward.
Model-based reconstructions for quantitative imaging in photoacoustic tomography
Nov 27, 2023The reconstruction task in photoacoustic tomography can vary a lot depending on measured targets, geometry, and especially the quantity we want to recover. Specifically, as the signal is generated due to the coupling of light and sound by the photoacoustic effect, we have the possibility to recover acoustic as well as optical tissue parameters. This is referred to as quantitative imaging, i.e, correct recovery of physical parameters and not just a qualitative image. In this chapter, we aim to give an overview on established reconstruction techniques in photoacoustic tomography. We start with modelling of the optical and acoustic phenomena, necessary for a reliable recovery of quantitative values. Furthermore, we give an overview of approaches for the tomographic reconstruction problem with an emphasis on the recovery of quantitative values, from direct and fast analytic approaches to computationally involved optimisation based techniques and recent data-driven approaches.
Elijah: Eliminating Backdoors Injected in Diffusion Models via Distribution Shift
Nov 27, 2023Diffusion models (DM) have become state-of-the-art generative models because of their capability to generate high-quality images from noises without adversarial training. However, they are vulnerable to backdoor attacks as reported by recent studies. When a data input (e.g., some Gaussian noise) is stamped with a trigger (e.g., a white patch), the backdoored model always generates the target image (e.g., an improper photo). However, effective defense strategies to mitigate backdoors from DMs are underexplored. To bridge this gap, we propose the first backdoor detection and removal framework for DMs. We evaluate our framework Elijah on hundreds of DMs of 3 types including DDPM, NCSN and LDM, with 13 samplers against 3 existing backdoor attacks. Extensive experiments show that our approach can have close to 100% detection accuracy and reduce the backdoor effects to close to zero without significantly sacrificing the model utility.
Generative Models: What do they know? Do they know things? Let's find out!
Nov 28, 2023Generative models have been shown to be capable of synthesizing highly detailed and realistic images. It is natural to suspect that they implicitly learn to model some image intrinsics such as surface normals, depth, or shadows. In this paper, we present compelling evidence that generative models indeed internally produce high-quality scene intrinsic maps. We introduce Intrinsic LoRA (I LoRA), a universal, plug-and-play approach that transforms any generative model into a scene intrinsic predictor, capable of extracting intrinsic scene maps directly from the original generator network without needing additional decoders or fully fine-tuning the original network. Our method employs a Low-Rank Adaptation (LoRA) of key feature maps, with newly learned parameters that make up less than 0.6% of the total parameters in the generative model. Optimized with a small set of labeled images, our model-agnostic approach adapts to various generative architectures, including Diffusion models, GANs, and Autoregressive models. We show that the scene intrinsic maps produced by our method compare well with, and in some cases surpass those generated by leading supervised techniques.
Egocentric Whole-Body Motion Capture with FisheyeViT and Diffusion-Based Motion Refinement
Nov 28, 2023In this work, we explore egocentric whole-body motion capture using a single fisheye camera, which simultaneously estimates human body and hand motion. This task presents significant challenges due to three factors: the lack of high-quality datasets, fisheye camera distortion, and human body self-occlusion. To address these challenges, we propose a novel approach that leverages FisheyeViT to extract fisheye image features, which are subsequently converted into pixel-aligned 3D heatmap representations for 3D human body pose prediction. For hand tracking, we incorporate dedicated hand detection and hand pose estimation networks for regressing 3D hand poses. Finally, we develop a diffusion-based whole-body motion prior model to refine the estimated whole-body motion while accounting for joint uncertainties. To train these networks, we collect a large synthetic dataset, EgoWholeBody, comprising 840,000 high-quality egocentric images captured across a diverse range of whole-body motion sequences. Quantitative and qualitative evaluations demonstrate the effectiveness of our method in producing high-quality whole-body motion estimates from a single egocentric camera.
Multi-Scale 3D Gaussian Splatting for Anti-Aliased Rendering
Nov 28, 2023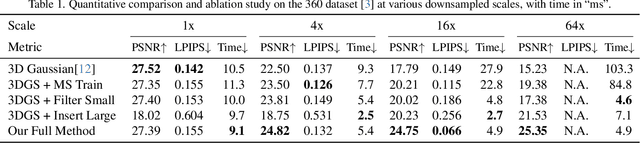
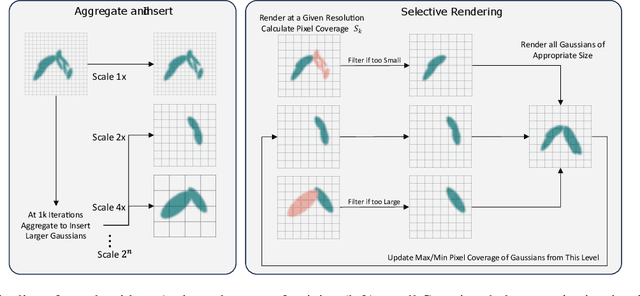
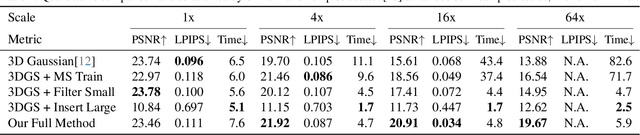
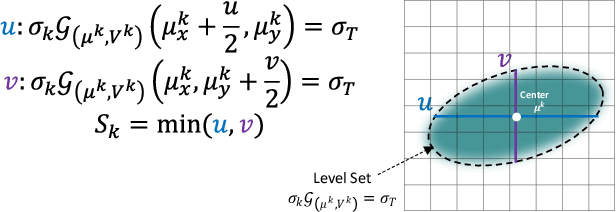
3D Gaussians have recently emerged as a highly efficient representation for 3D reconstruction and rendering. Despite its high rendering quality and speed at high resolutions, they both deteriorate drastically when rendered at lower resolutions or from far away camera position. During low resolution or far away rendering, the pixel size of the image can fall below the Nyquist frequency compared to the screen size of each splatted 3D Gaussian and leads to aliasing effect. The rendering is also drastically slowed down by the sequential alpha blending of more splatted Gaussians per pixel. To address these issues, we propose a multi-scale 3D Gaussian splatting algorithm, which maintains Gaussians at different scales to represent the same scene. Higher-resolution images are rendered with more small Gaussians, and lower-resolution images are rendered with fewer larger Gaussians. With similar training time, our algorithm can achieve 13\%-66\% PSNR and 160\%-2400\% rendering speed improvement at 4$\times$-128$\times$ scale rendering on Mip-NeRF360 dataset compared to the single scale 3D Gaussian splatting.
DepthSSC: Depth-Spatial Alignment and Dynamic Voxel Resolution for Monocular 3D Semantic Scene Completion
Nov 28, 2023The task of 3D semantic scene completion with monocular cameras is gaining increasing attention in the field of autonomous driving. Its objective is to predict the occupancy status of each voxel in the 3D scene from partial image inputs. Despite the existence of numerous methods, many of them overlook the issue of accurate alignment between spatial and depth information. To address this, we propose DepthSSC, an advanced method for semantic scene completion solely based on monocular cameras. DepthSSC combines the ST-GF (Spatial Transformation Graph Fusion) module with geometric-aware voxelization, enabling dynamic adjustment of voxel resolution and considering the geometric complexity of 3D space to ensure precise alignment between spatial and depth information. This approach successfully mitigates spatial misalignment and distortion issues observed in prior methods. Through evaluation on the SemanticKITTI dataset, DepthSSC not only demonstrates its effectiveness in capturing intricate 3D structural details but also achieves state-of-the-art performance. We believe DepthSSC provides a fresh perspective on monocular camera-based 3D semantic scene completion research and anticipate it will inspire further related studies.
Efficient Key-Based Adversarial Defense for ImageNet by Using Pre-trained Model
Nov 28, 2023In this paper, we propose key-based defense model proliferation by leveraging pre-trained models and utilizing recent efficient fine-tuning techniques on ImageNet-1k classification. First, we stress that deploying key-based models on edge devices is feasible with the latest model deployment advancements, such as Apple CoreML, although the mainstream enterprise edge artificial intelligence (Edge AI) has been focused on the Cloud. Then, we point out that the previous key-based defense on on-device image classification is impractical for two reasons: (1) training many classifiers from scratch is not feasible, and (2) key-based defenses still need to be thoroughly tested on large datasets like ImageNet. To this end, we propose to leverage pre-trained models and utilize efficient fine-tuning techniques to proliferate key-based models even on limited computing resources. Experiments were carried out on the ImageNet-1k dataset using adaptive and non-adaptive attacks. The results show that our proposed fine-tuned key-based models achieve a superior classification accuracy (more than 10% increase) compared to the previous key-based models on classifying clean and adversarial examples.
Multi-Channel Cross Modal Detection of Synthetic Face Images
Nov 28, 2023Synthetically generated face images have shown to be indistinguishable from real images by humans and as such can lead to a lack of trust in digital content as they can, for instance, be used to spread misinformation. Therefore, the need to develop algorithms for detecting entirely synthetic face images is apparent. Of interest are images generated by state-of-the-art deep learning-based models, as these exhibit a high level of visual realism. Recent works have demonstrated that detecting such synthetic face images under realistic circumstances remains difficult as new and improved generative models are proposed with rapid speed and arbitrary image post-processing can be applied. In this work, we propose a multi-channel architecture for detecting entirely synthetic face images which analyses information both in the frequency and visible spectra using Cross Modal Focal Loss. We compare the proposed architecture with several related architectures trained using Binary Cross Entropy and show in cross-model experiments that the proposed architecture supervised using Cross Modal Focal Loss, in general, achieves most competitive performance.
Towards Full-scene Domain Generalization in Multi-agent Collaborative Bird's Eye View Segmentation for Connected and Autonomous Driving
Nov 28, 2023Collaborative perception has recently gained significant attention in autonomous driving, improving perception quality by enabling the exchange of additional information among vehicles. However, deploying collaborative perception systems can lead to domain shifts due to diverse environmental conditions and data heterogeneity among connected and autonomous vehicles (CAVs). To address these challenges, we propose a unified domain generalization framework applicable in both training and inference stages of collaborative perception. In the training phase, we introduce an Amplitude Augmentation (AmpAug) method to augment low-frequency image variations, broadening the model's ability to learn across various domains. We also employ a meta-consistency training scheme to simulate domain shifts, optimizing the model with a carefully designed consistency loss to encourage domain-invariant representations. In the inference phase, we introduce an intra-system domain alignment mechanism to reduce or potentially eliminate the domain discrepancy among CAVs prior to inference. Comprehensive experiments substantiate the effectiveness of our method in comparison with the existing state-of-the-art works. Code will be released at https://github.com/DG-CAVs/DG-CoPerception.git.