 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Improving Normalization with the James-Stein Estimator
Dec 01, 2023
Stein's paradox holds considerable sway in high-dimensional statistics, highlighting that the sample mean, traditionally considered the de facto estimator, might not be the most efficacious in higher dimensions. To address this, the James-Stein estimator proposes an enhancement by steering the sample means toward a more centralized mean vector. In this paper, first, we establish that normalization layers in deep learning use inadmissible estimators for mean and variance. Next, we introduce a novel method to employ the James-Stein estimator to improve the estimation of mean and variance within normalization layers. We evaluate our method on different computer vision tasks: image classification, semantic segmentation, and 3D object classification. Through these evaluations, it is evident that our improved normalization layers consistently yield superior accuracy across all tasks without extra computational burden. Moreover, recognizing that a plethora of shrinkage estimators surpass the traditional estimator in performance, we study two other prominent shrinkage estimators: Ridge and LASSO. Additionally, we provide visual representations to intuitively demonstrate the impact of shrinkage on the estimated layer statistics. Finally, we study the effect of regularization and batch size on our modified batch normalization. The studies show that our method is less sensitive to batch size and regularization, improving accuracy under various setups.
Interpreting CLIP's Image Representation via Text-Based Decomposition
Oct 10, 2023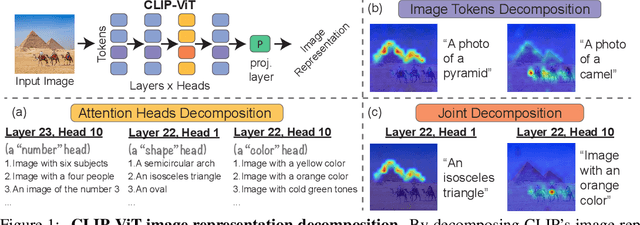
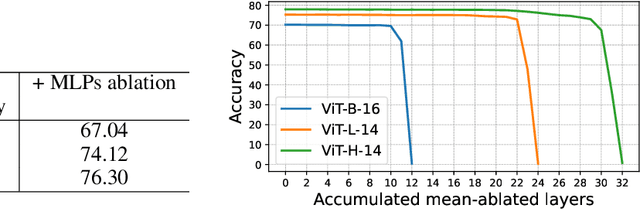

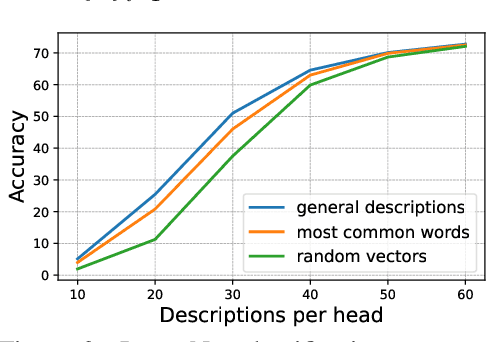
We investigate the CLIP image encoder by analyzing how individual model components affect the final representation. We decompose the image representation as a sum across individual image patches, model layers, and attention heads, and use CLIP's text representation to interpret the summands. Interpreting the attention heads, we characterize each head's role by automatically finding text representations that span its output space, which reveals property-specific roles for many heads (e.g. location or shape). Next, interpreting the image patches, we uncover an emergent spatial localization within CLIP. Finally, we use this understanding to remove spurious features from CLIP and to create a strong zero-shot image segmenter. Our results indicate that a scalable understanding of transformer models is attainable and can be used to repair and improve models.
FGPrompt: Fine-grained Goal Prompting for Image-goal Navigation
Oct 11, 2023Learning to navigate to an image-specified goal is an important but challenging task for autonomous systems. The agent is required to reason the goal location from where a picture is shot. Existing methods try to solve this problem by learning a navigation policy, which captures semantic features of the goal image and observation image independently and lastly fuses them for predicting a sequence of navigation actions. However, these methods suffer from two major limitations. 1) They may miss detailed information in the goal image, and thus fail to reason the goal location. 2) More critically, it is hard to focus on the goal-relevant regions in the observation image, because they attempt to understand observation without goal conditioning. In this paper, we aim to overcome these limitations by designing a Fine-grained Goal Prompting (FGPrompt) method for image-goal navigation. In particular, we leverage fine-grained and high-resolution feature maps in the goal image as prompts to perform conditioned embedding, which preserves detailed information in the goal image and guides the observation encoder to pay attention to goal-relevant regions. Compared with existing methods on the image-goal navigation benchmark, our method brings significant performance improvement on 3 benchmark datasets (i.e., Gibson, MP3D, and HM3D). Especially on Gibson, we surpass the state-of-the-art success rate by 8% with only 1/50 model size. Project page: https://xinyusun.github.io/fgprompt-pages
Benchmarking Feature Extractors for Reinforcement Learning-Based Semiconductor Defect Localization
Nov 18, 2023
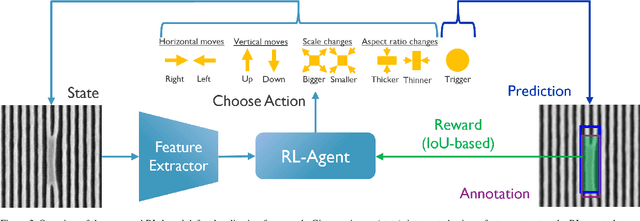
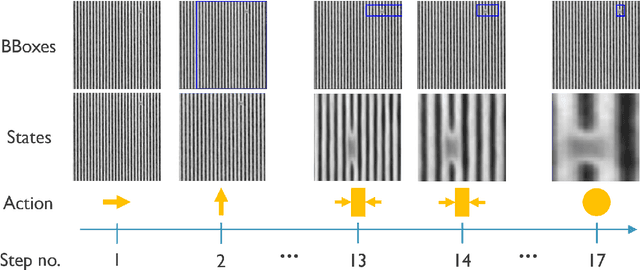

As semiconductor patterning dimensions shrink, more advanced Scanning Electron Microscopy (SEM) image-based defect inspection techniques are needed. Recently, many Machine Learning (ML)-based approaches have been proposed for defect localization and have shown impressive results. These methods often rely on feature extraction from a full SEM image and possibly a number of regions of interest. In this study, we propose a deep Reinforcement Learning (RL)-based approach to defect localization which iteratively extracts features from increasingly smaller regions of the input image. We compare the results of 18 agents trained with different feature extractors. We discuss the advantages and disadvantages of different feature extractors as well as the RL-based framework in general for semiconductor defect localization.
* 5 pages, 5 figures, 3 tables
FisherRF: Active View Selection and Uncertainty Quantification for Radiance Fields using Fisher Information
Nov 29, 2023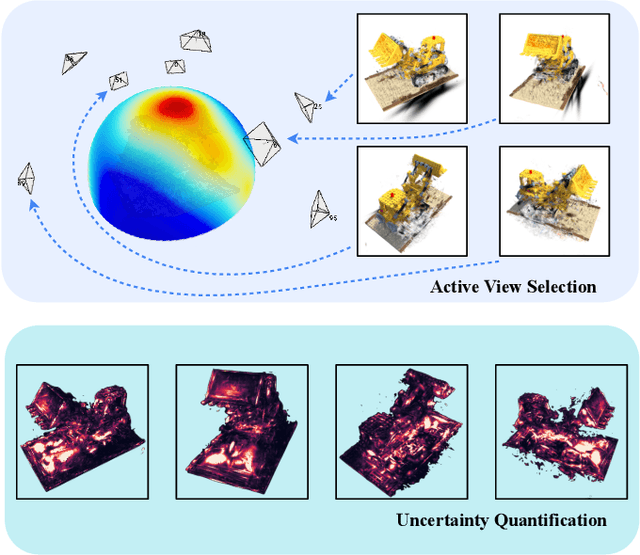
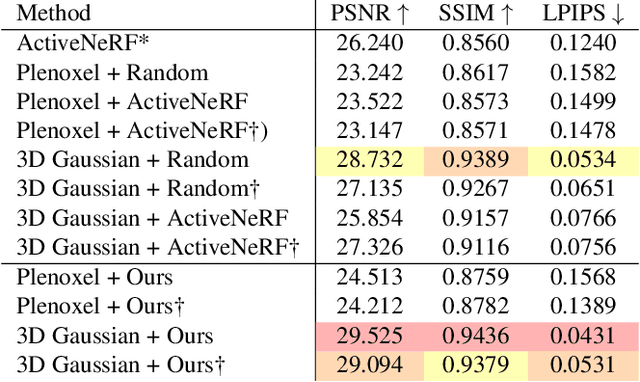

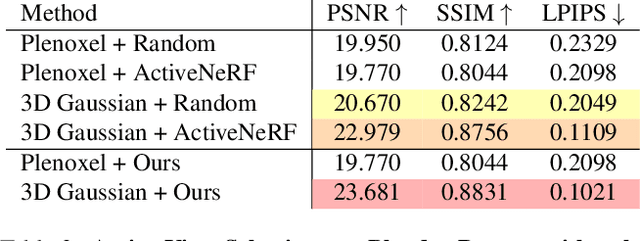
This study addresses the challenging problem of active view selection and uncertainty quantification within the domain of Radiance Fields. Neural Radiance Fields (NeRF) have greatly advanced image rendering and reconstruction, but the limited availability of 2D images poses uncertainties stemming from occlusions, depth ambiguities, and imaging errors. Efficiently selecting informative views becomes crucial, and quantifying NeRF model uncertainty presents intricate challenges. Existing approaches either depend on model architecture or are based on assumptions regarding density distributions that are not generally applicable. By leveraging Fisher Information, we efficiently quantify observed information within Radiance Fields without ground truth data. This can be used for the next best view selection and pixel-wise uncertainty quantification. Our method overcomes existing limitations on model architecture and effectiveness, achieving state-of-the-art results in both view selection and uncertainty quantification, demonstrating its potential to advance the field of Radiance Fields. Our method with the 3D Gaussian Splatting backend could perform view selections at 70 fps.
Learning and Autonomy for Extraterrestrial Terrain Sampling: An Experience Report from OWLAT Deployment
Nov 29, 2023Extraterrestrial autonomous lander missions increasingly demand adaptive capabilities to handle the unpredictable and diverse nature of the terrain. This paper discusses the deployment of a Deep Meta-Learning with Controlled Deployment Gaps (CoDeGa) trained model for terrain scooping tasks in Ocean Worlds Lander Autonomy Testbed (OWLAT) at NASA Jet Propulsion Laboratory. The CoDeGa-powered scooping strategy is designed to adapt to novel terrains, selecting scooping actions based on the available RGB-D image data and limited experience. The paper presents our experiences with transferring the scooping framework with CoDeGa-trained model from a low-fidelity testbed to the high-fidelity OWLAT testbed. Additionally, it validates the method's performance in novel, realistic environments, and shares the lessons learned from deploying learning-based autonomy algorithms for space exploration. Experimental results from OWLAT substantiate the efficacy of CoDeGa in rapidly adapting to unfamiliar terrains and effectively making autonomous decisions under considerable domain shifts, thereby endorsing its potential utility in future extraterrestrial missions.
Precipitation Nowcasting With Spatial And Temporal Transfer Learning Using Swin-UNETR
Nov 29, 2023Climate change has led to an increase in frequency of extreme weather events. Early warning systems can prevent disasters and loss of life. Managing such events remain a challenge for both public and private institutions. Precipitation nowcasting can help relevant institutions to better prepare for such events. Numerical weather prediction (NWP) has traditionally been used to make physics based forecasting, and recently deep learning based approaches have been used to reduce turn-around time for nowcasting. In this work, recently proposed Swin-UNETR (Swin UNEt TRansformer) is used for precipitation nowcasting for ten different regions of Europe. Swin-UNETR utilizes a U-shaped network within which a swin transformer-based encoder extracts multi-scale features from multiple input channels of satellite image, while CNN-based decoder makes the prediction. Trained model is capable of nowcasting not only for the regions for which data is available, but can also be used for new regions for which data is not available.
Unsupervised Keypoints from Pretrained Diffusion Models
Nov 29, 2023Unsupervised learning of keypoints and landmarks has seen significant progress with the help of modern neural network architectures, but performance is yet to match the supervised counterpart, making their practicability questionable. We leverage the emergent knowledge within text-to-image diffusion models, towards more robust unsupervised keypoints. Our core idea is to find text embeddings that would cause the generative model to consistently attend to compact regions in images (i.e. keypoints). To do so, we simply optimize the text embedding such that the cross-attention maps within the denoising network are localized as Gaussians with small standard deviations. We validate our performance on multiple datasets: the CelebA, CUB-200-2011, Tai-Chi-HD, DeepFashion, and Human3.6m datasets. We achieve significantly improved accuracy, sometimes even outperforming supervised ones, particularly for data that is non-aligned and less curated. Our code is publicly available and can be found through our project page: https://ubc-vision.github.io/StableKeypoints/
Learning Site-specific Styles for Multi-institutional Unsupervised Cross-modality Domain Adaptation
Nov 21, 2023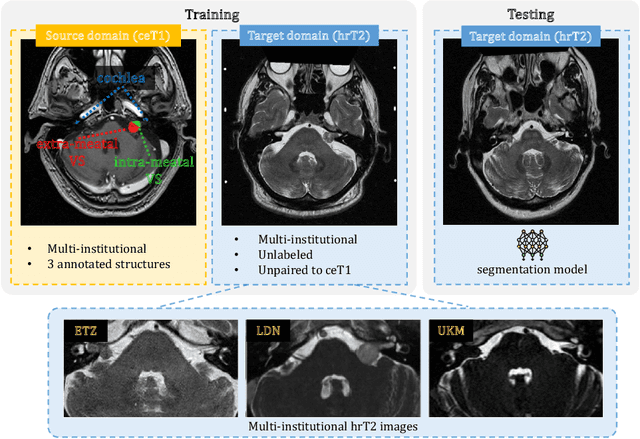
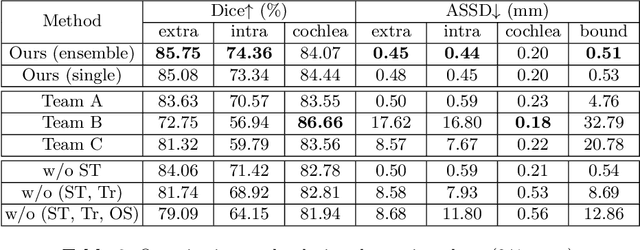
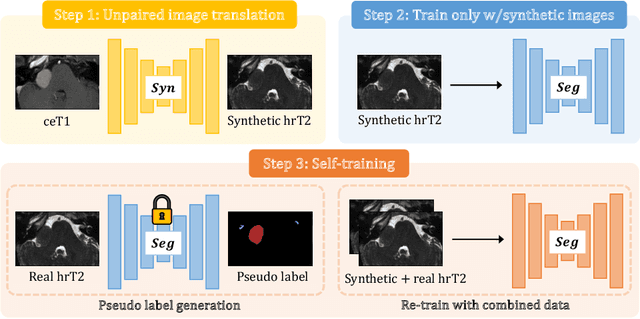
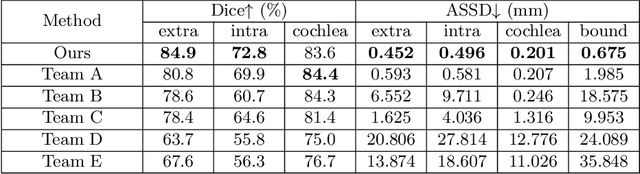
Unsupervised cross-modality domain adaptation is a challenging task in medical image analysis, and it becomes more challenging when source and target domain data are collected from multiple institutions. In this paper, we present our solution to tackle the multi-institutional unsupervised domain adaptation for the crossMoDA 2023 challenge. First, we perform unpaired image translation to translate the source domain images to the target domain, where we design a dynamic network to generate synthetic target domain images with controllable, site-specific styles. Afterwards, we train a segmentation model using the synthetic images and further reduce the domain gap by self-training. Our solution achieved the 1st place during both the validation and testing phases of the challenge.
Enhancing Rock Image Segmentation in Digital Rock Physics: A Fusion of Generative AI and State-of-the-Art Neural Networks
Nov 10, 2023In digital rock physics, analysing microstructures from CT and SEM scans is crucial for estimating properties like porosity and pore connectivity. Traditional segmentation methods like thresholding and CNNs often fall short in accurately detailing rock microstructures and are prone to noise. U-Net improved segmentation accuracy but required many expert-annotated samples, a laborious and error-prone process due to complex pore shapes. Our study employed an advanced generative AI model, the diffusion model, to overcome these limitations. This model generated a vast dataset of CT/SEM and binary segmentation pairs from a small initial dataset. We assessed the efficacy of three neural networks: U-Net, Attention-U-net, and TransUNet, for segmenting these enhanced images. The diffusion model proved to be an effective data augmentation technique, improving the generalization and robustness of deep learning models. TransU-Net, incorporating Transformer structures, demonstrated superior segmentation accuracy and IoU metrics, outperforming both U-Net and Attention-U-net. Our research advances rock image segmentation by combining the diffusion model with cutting-edge neural networks, reducing dependency on extensive expert data and boosting segmentation accuracy and robustness. TransU-Net sets a new standard in digital rock physics, paving the way for future geoscience and engineering breakthroughs.