 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
GroundVLP: Harnessing Zero-shot Visual Grounding from Vision-Language Pre-training and Open-Vocabulary Object Detection
Dec 22, 2023
Visual grounding, a crucial vision-language task involving the understanding of the visual context based on the query expression, necessitates the model to capture the interactions between objects, as well as various spatial and attribute information. However, the annotation data of visual grounding task is limited due to its time-consuming and labor-intensive annotation process, resulting in the trained models being constrained from generalizing its capability to a broader domain. To address this challenge, we propose GroundVLP, a simple yet effective zero-shot method that harnesses visual grounding ability from the existing models trained from image-text pairs and pure object detection data, both of which are more conveniently obtainable and offer a broader domain compared to visual grounding annotation data. GroundVLP proposes a fusion mechanism that combines the heatmap from GradCAM and the object proposals of open-vocabulary detectors. We demonstrate that the proposed method significantly outperforms other zero-shot methods on RefCOCO/+/g datasets, surpassing prior zero-shot state-of-the-art by approximately 28\% on the test split of RefCOCO and RefCOCO+. Furthermore, GroundVLP performs comparably to or even better than some non-VLP-based supervised models on the Flickr30k entities dataset. Our code is available at https://github.com/om-ai-lab/GroundVLP.
PEAN: A Diffusion-based Prior-Enhanced Attention Network for Scene Text Image Super-Resolution
Nov 29, 2023Scene text image super-resolution (STISR) aims at simultaneously increasing the resolution and readability of low-resolution scene text images, thus boosting the performance of the downstream recognition task. Two factors in scene text images, semantic information and visual structure, affect the recognition performance significantly. To mitigate the effects from these factors, this paper proposes a Prior-Enhanced Attention Network (PEAN). Specifically, a diffusion-based module is developed to enhance the text prior, hence offering better guidance for the SR network to generate SR images with higher semantic accuracy. Meanwhile, the proposed PEAN leverages an attention-based modulation module to understand scene text images by neatly perceiving the local and global dependence of images, despite the shape of the text. A multi-task learning paradigm is employed to optimize the network, enabling the model to generate legible SR images. As a result, PEAN establishes new SOTA results on the TextZoom benchmark. Experiments are also conducted to analyze the importance of the enhanced text prior as a means of improving the performance of the SR network. Code will be made available at https://github.com/jdfxzzy/PEAN.
MobileSAMv2: Faster Segment Anything to Everything
Dec 15, 2023Segment anything model (SAM) addresses two practical yet challenging segmentation tasks: \textbf{segment anything (SegAny)}, which utilizes a certain point to predict the mask for a single object of interest, and \textbf{segment everything (SegEvery)}, which predicts the masks for all objects on the image. What makes SegAny slow for SAM is its heavyweight image encoder, which has been addressed by MobileSAM via decoupled knowledge distillation. The efficiency bottleneck of SegEvery with SAM, however, lies in its mask decoder because it needs to first generate numerous masks with redundant grid-search prompts and then perform filtering to obtain the final valid masks. We propose to improve its efficiency by directly generating the final masks with only valid prompts, which can be obtained through object discovery. Our proposed approach not only helps reduce the total time on the mask decoder by at least 16 times but also achieves superior performance. Specifically, our approach yields an average performance boost of 3.6\% (42.5\% \textit{v.s.} 38.9\%) for zero-shot object proposal on the LVIS dataset with the mask AR@$K$ metric. Qualitative results show that our approach generates fine-grained masks while avoiding over-segmenting things. This project targeting faster SegEvery than the original SAM is termed MobileSAMv2 to differentiate from MobileSAM which targets faster SegAny. Moreover, we demonstrate that our new prompt sampling is also compatible with the distilled image encoders in MobileSAM, contributing to a unified framework for efficient SegAny and SegEvery. The code is available at the same link as MobileSAM Project \href{https://github.com/ChaoningZhang/MobileSAM}{\textcolor{red}{https://github.com/ChaoningZhang/MobileSAM}}. \end{abstract}
CAR: Consolidation, Augmentation and Regulation for Recipe Retrieval
Dec 08, 2023Learning recipe and food image representation in common embedding space is non-trivial but crucial for cross-modal recipe retrieval. In this paper, we propose CAR framework with three novel techniques, i.e., Consolidation, Augmentation and Regulation, for cross-modal recipe retrieval. We introduce adapter layers to consolidate pre-trained CLIP model with much less computation cost than fully cumbersome fine-tuning all the parameters. Furthermore, leveraging on the strong capability of foundation models (i.e., SAM and LLM), we propose to augment recipe and food image by extracting information related to the counterpart. SAM generates image segments corresponding to ingredients in the recipe, while LLM produces a visual imagination description from the recipe, aiming to capture the visual cues of a food image. In addition, we introduce circle loss to regulate cross-modal embedding space, which assigns different penalties for positive and negative pairs. With the extra augmented data from recipe and image, multi-level circle loss is proposed, which applies circle loss not only to original image-recipe pairs, but also to image segments and recipe, visual imagination description and food image as well as any two sections within a recipe. On Recipe1M dataset, our proposed CAR outperforms all the existing methods by a large margin. Extensive ablation studies are conducted to validate the effectiveness of each component of CAR. We will make our code and models publicly available.
Trainwreck: A damaging adversarial attack on image classifiers
Nov 24, 2023Adversarial attacks are an important security concern for computer vision (CV), as they enable malicious attackers to reliably manipulate CV models. Existing attacks aim to elicit an output desired by the attacker, but keep the model fully intact on clean data. With CV models becoming increasingly valuable assets in applied practice, a new attack vector is emerging: disrupting the models as a form of economic sabotage. This paper opens up the exploration of damaging adversarial attacks (DAAs) that seek to damage the target model and maximize the total cost incurred by the damage. As a pioneer DAA, this paper proposes Trainwreck, a train-time attack that poisons the training data of image classifiers to degrade their performance. Trainwreck conflates the data of similar classes using stealthy ($\epsilon \leq 8/255$) class-pair universal perturbations computed using a surrogate model. Trainwreck is a black-box, transferable attack: it requires no knowledge of the target model's architecture, and a single poisoned dataset degrades the performance of any model trained on it. The experimental evaluation on CIFAR-10 and CIFAR-100 demonstrates that Trainwreck is indeed an effective attack across various model architectures including EfficientNetV2, ResNeXt-101, and a finetuned ViT-L-16. The strength of the attack can be customized by the poison rate parameter. Finally, data redundancy with file hashing and/or pixel difference are identified as a reliable defense technique against Trainwreck or similar DAAs. The code is available at https://github.com/JanZahalka/trainwreck.
Joint covariance property under geometric image transformations for spatio-temporal receptive fields according to the generalized Gaussian derivative model for visual receptive fields
Nov 20, 2023The influence of natural image transformations on receptive field responses is crucial for modelling visual operations in computer vision and biological vision. In this regard, covariance properties with respect to geometric image transformations in the earliest layers of the visual hierarchy are essential for expressing robust image operations and for formulating invariant visual operations at higher levels. This paper defines and proves a joint covariance property under compositions of spatial scaling transformations, spatial affine transformations, Galilean transformations and temporal scaling transformations, which makes it possible to characterize how different types of image transformations interact with each other. Specifically, the derived relations show how the receptive field parameters need to be transformed, in order to match the output from spatio-temporal receptive fields with the underlying spatio-temporal image transformations.
Semi-supervised Semantic Segmentation Meets Masked Modeling:Fine-grained Locality Learning Matters in Consistency Regularization
Dec 14, 2023Semi-supervised semantic segmentation aims to utilize limited labeled images and abundant unlabeled images to achieve label-efficient learning, wherein the weak-to-strong consistency regularization framework, popularized by FixMatch, is widely used as a benchmark scheme. Despite its effectiveness, we observe that such scheme struggles with satisfactory segmentation for the local regions. This can be because it originally stems from the image classification task and lacks specialized mechanisms to capture fine-grained local semantics that prioritizes in dense prediction. To address this issue, we propose a novel framework called \texttt{MaskMatch}, which enables fine-grained locality learning to achieve better dense segmentation. On top of the original teacher-student framework, we design a masked modeling proxy task that encourages the student model to predict the segmentation given the unmasked image patches (even with 30\% only) and enforces the predictions to be consistent with pseudo-labels generated by the teacher model using the complete image. Such design is motivated by the intuition that if the predictions are more consistent given insufficient neighboring information, stronger fine-grained locality perception is achieved. Besides, recognizing the importance of reliable pseudo-labels in the above locality learning and the original consistency learning scheme, we design a multi-scale ensembling strategy that considers context at different levels of abstraction for pseudo-label generation. Extensive experiments on benchmark datasets demonstrate the superiority of our method against previous approaches and its plug-and-play flexibility.
VehicleGAN: Pair-flexible Pose Guided Image Synthesis for Vehicle Re-identification
Nov 27, 2023Vehicle Re-identification (Re-ID) has been broadly studied in the last decade; however, the different camera view angle leading to confused discrimination in the feature subspace for the vehicles of various poses, is still challenging for the Vehicle Re-ID models in the real world. To promote the Vehicle Re-ID models, this paper proposes to synthesize a large number of vehicle images in the target pose, whose idea is to project the vehicles of diverse poses into the unified target pose so as to enhance feature discrimination. Considering that the paired data of the same vehicles in different traffic surveillance cameras might be not available in the real world, we propose the first Pair-flexible Pose Guided Image Synthesis method for Vehicle Re-ID, named as VehicleGAN in this paper, which works for both supervised and unsupervised settings without the knowledge of geometric 3D models. Because of the feature distribution difference between real and synthetic data, simply training a traditional metric learning based Re-ID model with data-level fusion (i.e., data augmentation) is not satisfactory, therefore we propose a new Joint Metric Learning (JML) via effective feature-level fusion from both real and synthetic data. Intensive experimental results on the public VeRi-776 and VehicleID datasets prove the accuracy and effectiveness of our proposed VehicleGAN and JML.
Score-based diffusion priors for multi-target detection
Dec 13, 2023

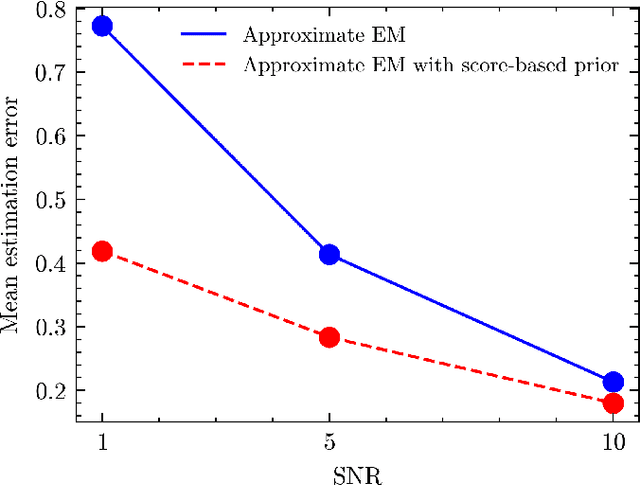
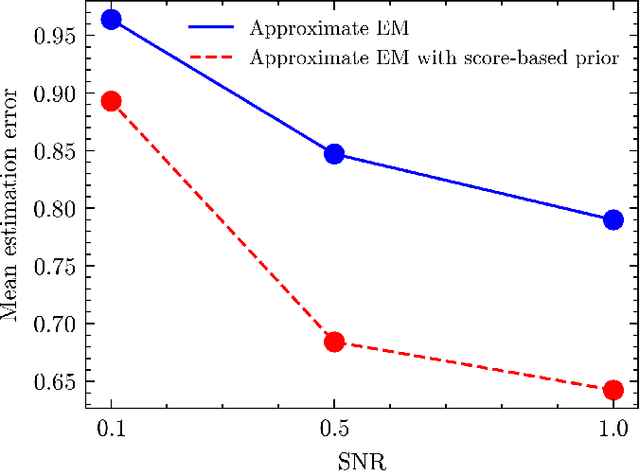
Multi-target detection (MTD) is the problem of estimating an image from a large, noisy measurement that contains randomly translated and rotated copies of the image. Motivated by the single-particle cryo-electron microscopy technology, we design data-driven diffusion priors for the MTD problem, derived from score-based stochastic differential equations models. We then integrate the prior into the approximate expectation-maximization algorithm. In particular, our method alternates between an expectation step that approximates the expected log-likelihood and a maximization step that balances the approximated log-likelihood with the learned log-prior. We show on two datasets that adding the data-driven prior substantially reduces the estimation error, in particular in high noise regimes.
Domain Similarity-Perceived Label Assignment for Domain Generalized Underwater Object Detection
Dec 20, 2023The inherent characteristics and light fluctuations of water bodies give rise to the huge difference between different layers and regions in underwater environments. When the test set is collected in a different marine area from the training set, the issue of domain shift emerges, significantly compromising the model's ability to generalize. The Domain Adversarial Learning (DAL) training strategy has been previously utilized to tackle such challenges. However, DAL heavily depends on manually one-hot domain labels, which implies no difference among the samples in the same domain. Such an assumption results in the instability of DAL. This paper introduces the concept of Domain Similarity-Perceived Label Assignment (DSP). The domain label for each image is regarded as its similarity to the specified domains. Through domain-specific data augmentation techniques, we achieved state-of-the-art results on the underwater cross-domain object detection benchmark S-UODAC2020. Furthermore, we validated the effectiveness of our method in the Cityscapes dataset.