 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Featuring the topology with the unsupervised machine learning
Aug 01, 2019
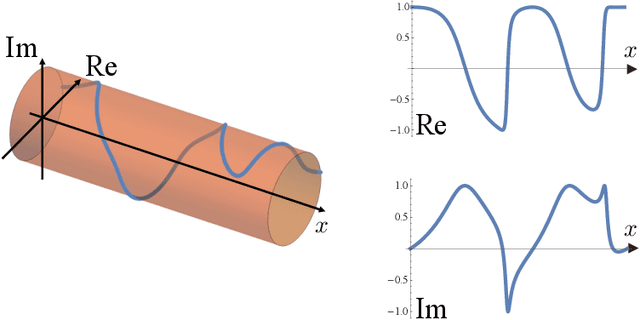
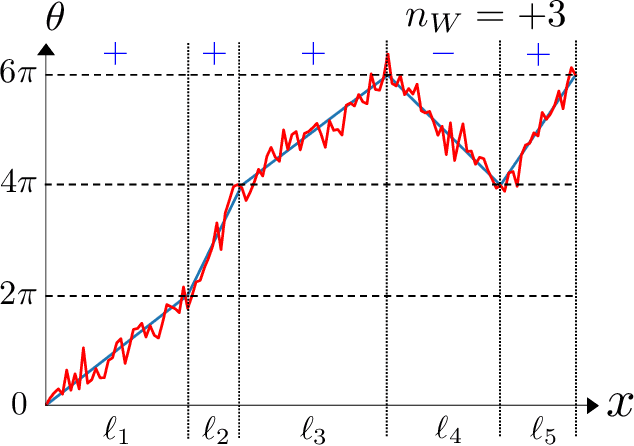
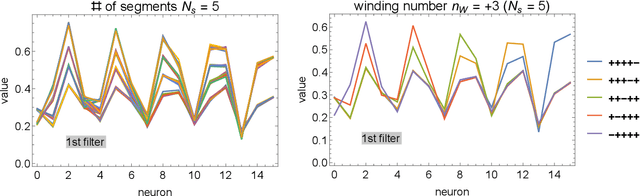
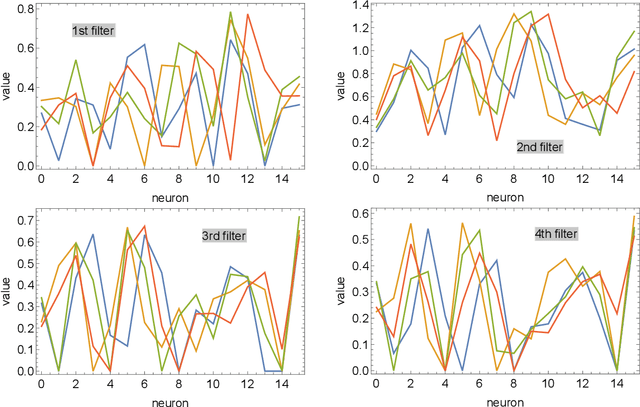
Images of line drawings are generally composed of primitive elements. One of the most fundamental elements to characterize images is the topology; line segments belong to a category different from closed circles, and closed circles with different winding degrees are nonequivalent. We investigate images with nontrivial winding using the unsupervised machine learning. We build an autoencoder model with a combination of convolutional and fully connected neural networks. We confirm that compressed data filtered from the trained model retain more than 90% of correct information on the topology, evidencing that image clustering from the unsupervised learning features the topology.
Coverage Testing of Deep Learning Models using Dataset Characterization
Nov 17, 2019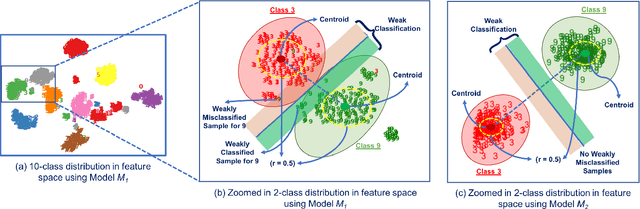
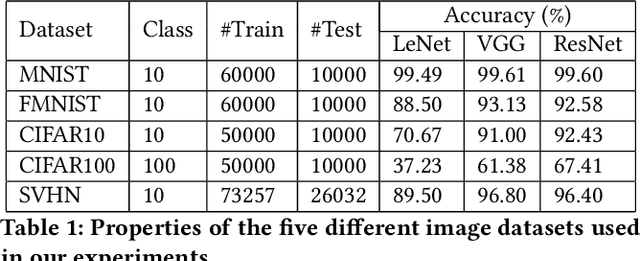
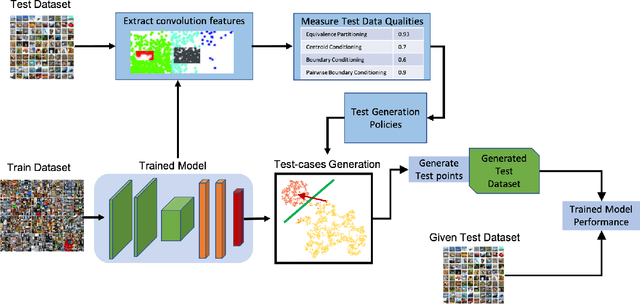
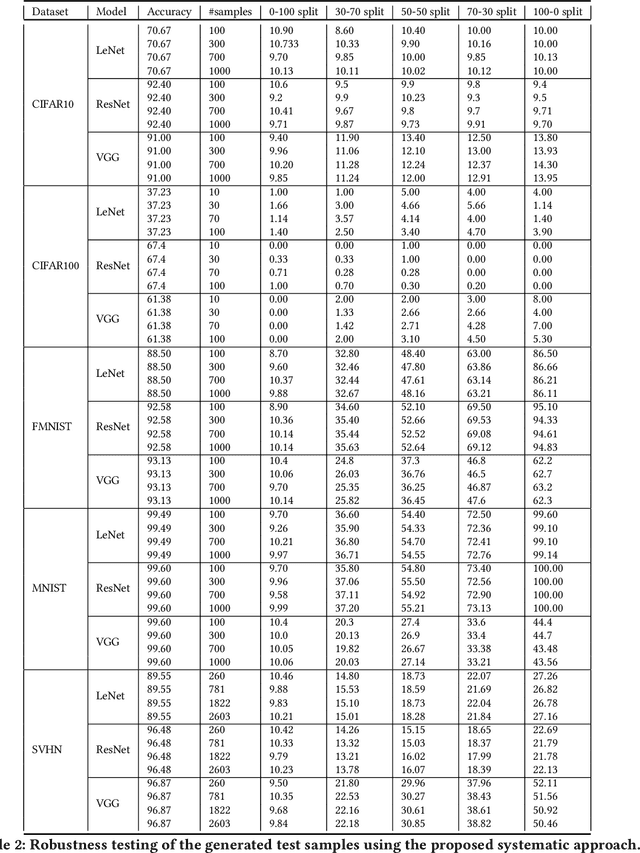
Deep Neural Networks (DNNs), with its promising performance, are being increasingly used in safety critical applications such as autonomous driving, cancer detection, and secure authentication. With growing importance in deep learning, there is a requirement for a more standardized framework to evaluate and test deep learning models. The primary challenge involved in automated generation of extensive test cases are: (i) neural networks are difficult to interpret and debug and (ii) availability of human annotators to generate specialized test points. In this research, we explain the necessity to measure the quality of a dataset and propose a test case generation system guided by the dataset properties. From a testing perspective, four different dataset quality dimensions are proposed: (i) equivalence partitioning, (ii) centroid positioning, (iii) boundary conditioning, and (iv) pair-wise boundary conditioning. The proposed system is evaluated on well known image classification datasets such as MNIST, Fashion-MNIST, CIFAR10, CIFAR100, and SVHN against popular deep learning models such as LeNet, ResNet-20, VGG-19. Further, we conduct various experiments to demonstrate the effectiveness of systematic test case generation system for evaluating deep learning models.
Deep Surface Normal Estimation with Hierarchical RGB-D Fusion
Apr 06, 2019
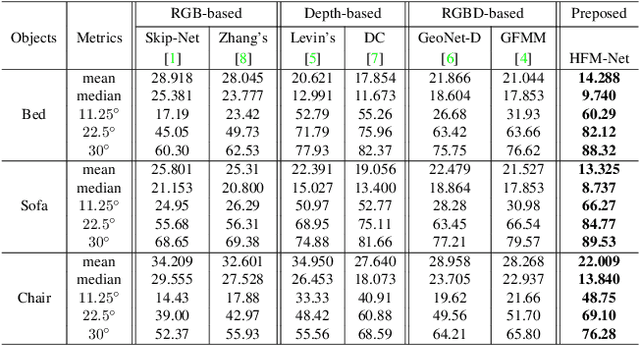
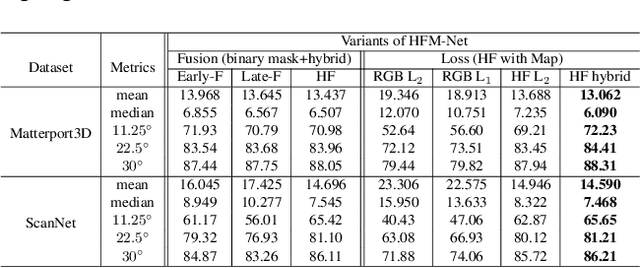
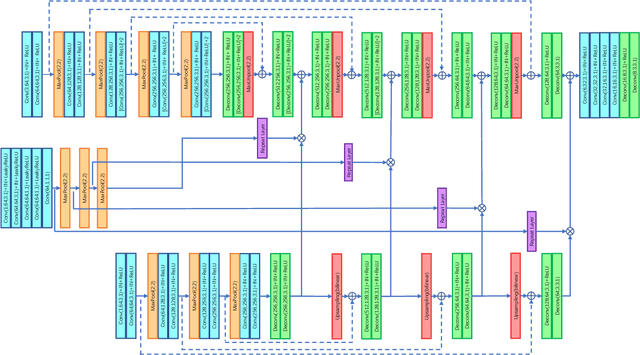
The growing availability of commodity RGB-D cameras has boosted the applications in the field of scene understanding. However, as a fundamental scene understanding task, surface normal estimation from RGB-D data lacks thorough investigation. In this paper, a hierarchical fusion network with adaptive feature re-weighting is proposed for surface normal estimation from a single RGB-D image. Specifically, the features from color image and depth are successively integrated at multiple scales to ensure global surface smoothness while preserving visually salient details. Meanwhile, the depth features are re-weighted with a confidence map estimated from depth before merging into the color branch to avoid artifacts caused by input depth corruption. Additionally, a hybrid multi-scale loss function is designed to learn accurate normal estimation given noisy ground-truth dataset. Extensive experimental results validate the effectiveness of the fusion strategy and the loss design, outperforming state-of-the-art normal estimation schemes.
Understanding Neural Pathways in Zebrafish through Deep Learning and High Resolution Electron Microscope Data
Aug 31, 2018

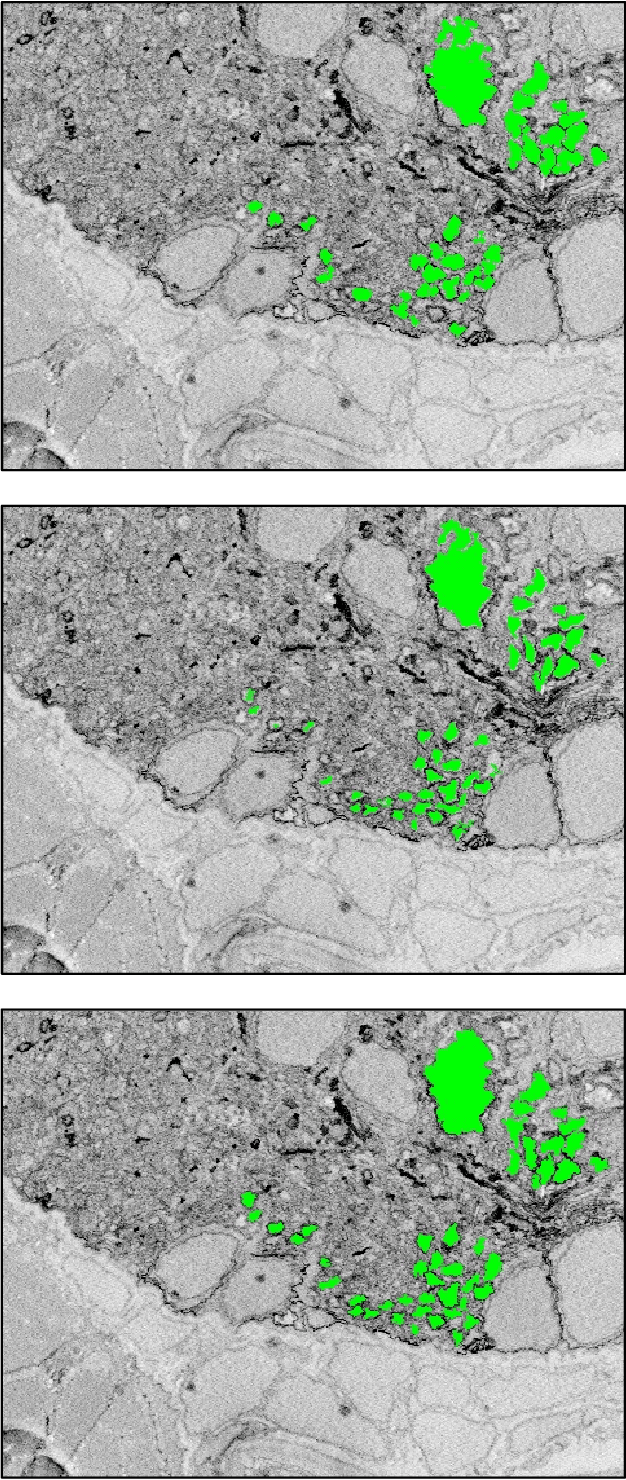

The tracing of neural pathways through large volumes of image data is an incredibly tedious and time-consuming process that significantly encumbers progress in neuroscience. We are exploring deep learning's potential to automate segmentation of high-resolution scanning electron microscope (SEM) image data to remove that barrier. We have started with neural pathway tracing through 5.1GB of whole-brain serial-section slices from larval zebrafish collected by the Center for Brain Science at Harvard University. This kind of manual image segmentation requires years of careful work to properly trace the neural pathways in an organism as small as a zebrafish larva (approximately 5mm in total body length). In automating this process, we would vastly improve productivity, leading to faster data analysis and breakthroughs in understanding the complexity of the brain. We will build upon prior attempts to employ deep learning for automatic image segmentation extending methods for unconventional deep learning data.
* 8 pages, 5 figures (1a to 5c), PEARC '18: Practice and Experience in Advanced Research Computing, July 22--26, 2018, Pittsburgh, PA, USA
Deep Instance-Level Hard Negative Mining Model for Histopathology Images
Jun 27, 2019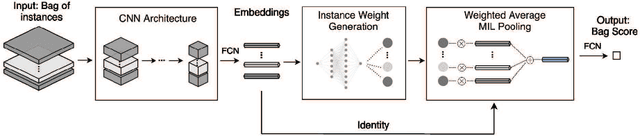
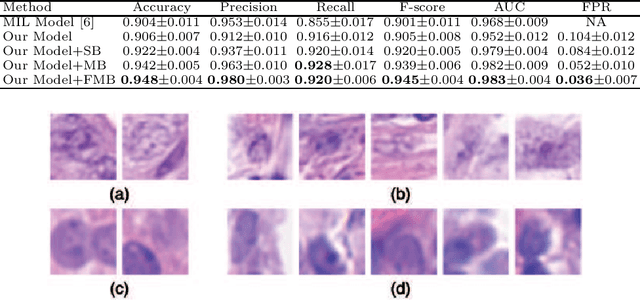
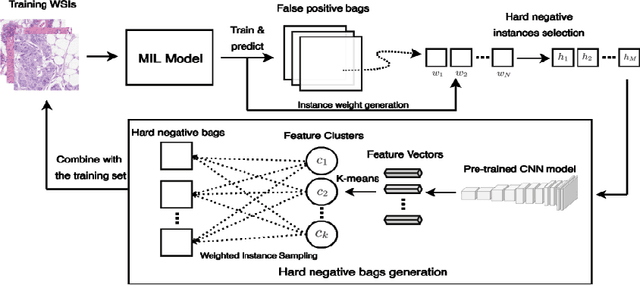

Histopathology image analysis can be considered as a Multiple instance learning (MIL) problem, where the whole slide histopathology image (WSI) is regarded as a bag of instances (i.e, patches) and the task is to predict a single class label to the WSI. However, in many real-life applications such as computational pathology, discovering the key instances that trigger the bag label is of great interest because it provides reasons for the decision made by the system. In this paper, we propose a deep convolutional neural network (CNN) model that addresses the primary task of a bag classification on a WSI and also learns to identify the response of each instance to provide interpretable results to the final prediction. We incorporate the attention mechanism into the proposed model to operate the transformation of instances and learn attention weights to allow us to find key patches. To perform a balanced training, we introduce adaptive weighing in each training bag to explicitly adjust the weight distribution in order to concentrate more on the contribution of hard samples. Based on the learned attention weights, we further develop a solution to boost the classification performance by generating the bags with hard negative instances. We conduct extensive experiments on colon and breast cancer histopathology data and show that our framework achieves state-of-the-art performance.
Tensor Recovery from Noisy and Multi-Level Quantized Measurements
Dec 05, 2019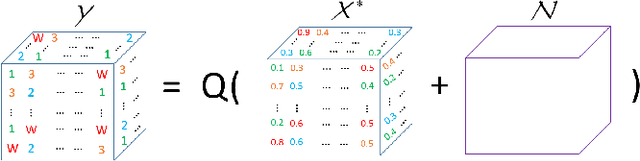
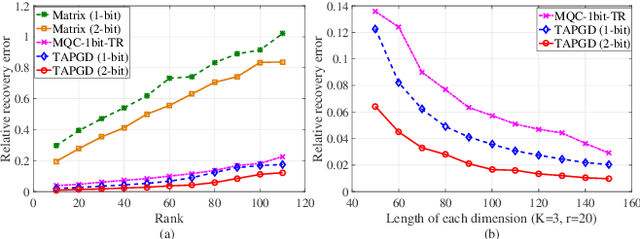
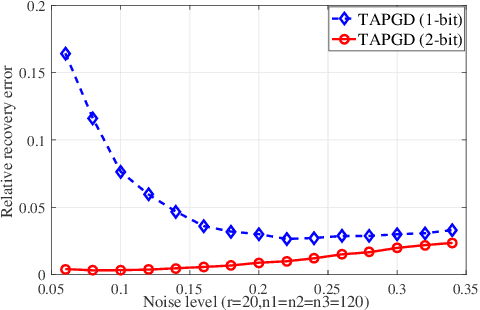
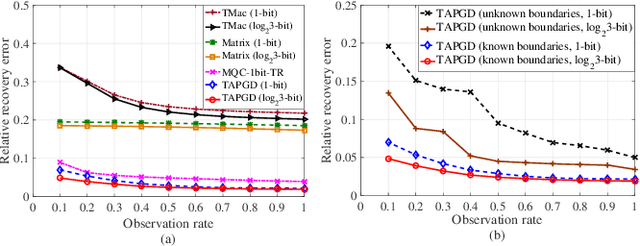
Higher-order tensors can represent scores in a rating system, frames in a video, and images of the same subject. In practice, the measurements are often highly quantized due to the sampling strategies or the quality of devices. Existing works on tensor recovery have focused on data losses and random noises. Only a few works consider tensor recovery from quantized measurements but are restricted to binary measurements. This paper, for the first time, addresses the problem of tensor recovery from multi-level quantized measurements. Leveraging the low-rank property of the tensor, this paper proposes a nonconvex optimization problem for tensor recovery. We provide a theoretical upper bound of the recovery error, which diminishes to zero when the sizes of dimensions increase to infinity. Our error bound significantly improves over the existing results in one-bit tensor recovery and quantized matrix recovery. A tensor-based alternating proximal gradient descent algorithm with a convergence guarantee is proposed to solve the nonconvex problem. Our recovery method can handle data losses and do not need the information of the quantization rule. The method is validated on synthetic data, image datasets, and music recommender datasets.
SAC-Net: Spatial Attenuation Context for Salient Object Detection
Mar 25, 2019
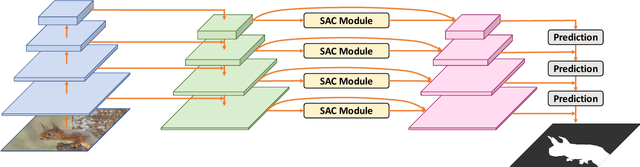
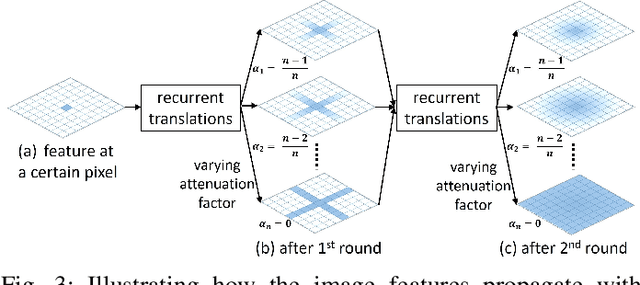
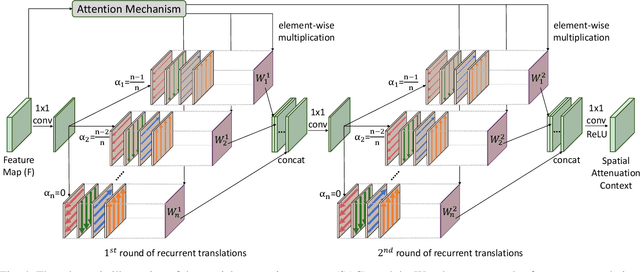
This paper presents a new deep neural network design for salient object detection by maximizing the integration of local and global image context within, around, and beyond the salient objects. Our key idea is to adaptively propagate and aggregate the image context with variable attenuation over the entire feature maps. To achieve this, we design the spatial attenuation context (SAC) module to recurrently translate and aggregate the context features independently with different attenuation factors and then attentively learn the weights to adaptively integrate the aggregated context features. By further embedding the module to process individual layers in a deep network, namely SAC-Net, we can train the network end-to-end and optimize the context features for detecting salient objects. Compared with 22 state-of-the-art methods, experimental results show that our method performs favorably over all the others on six common benchmark data, both quantitatively and visually.
Resampling detection of recompressed images via dual-stream convolutional neural network
Jan 15, 2019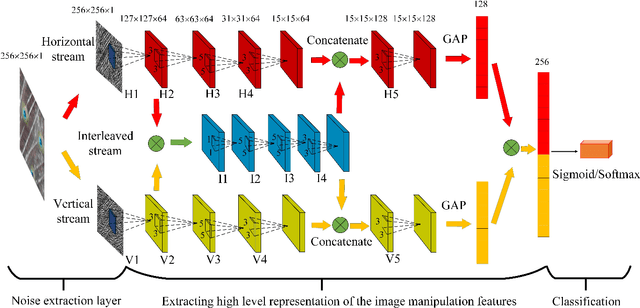

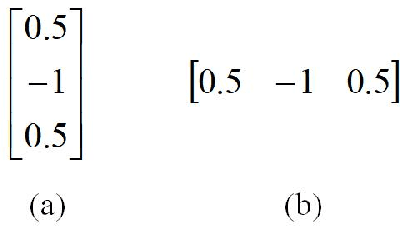

Resampling detection plays an important role in identifying image tampering, such as image splicing. Currently, the resampling detection is still difficult in recompressed images, which are yielded by applying resampling and post-JPEG compression to primary JPEG images. Although low quality primary compression benefits the detection, it remains rather challenging due to the widespread use of middle/high quality compression in imaging devices. In this paper, we propose a novel deep learning approach to learn resampling features directly from the recompressed images. To this end, a noise extraction layer based on low-order high pass filters is deployed to yield the image noise residual domain, which is more beneficial to extract manipulation trail features. A dual-stream convolutional neural network (CNN) is presented to capture the resampling trails along different directions, where the horizontal and vertical streams are interleaved and concatenated. Lastly, the learned features are fed into Sigmoid/Softmax layer, which is used as a binary/multiple classifier for achieving the blind detection or parameter estimation of resampling operations, respectively. Extensive experimental results demonstrate that our proposed method could detect resampling effectively in recompressed images and outperform the state-of-the-art detectors.
Approximate Bayesian Computation with the Sliced-Wasserstein Distance
Oct 28, 2019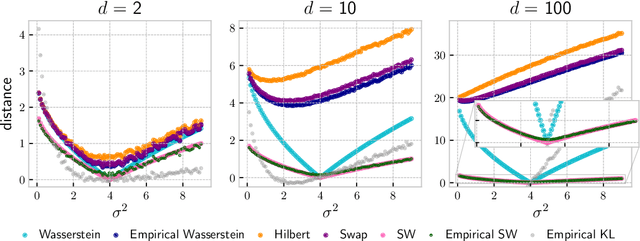
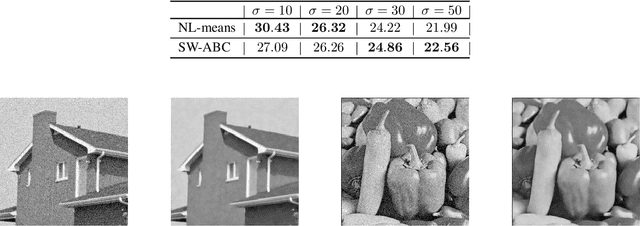
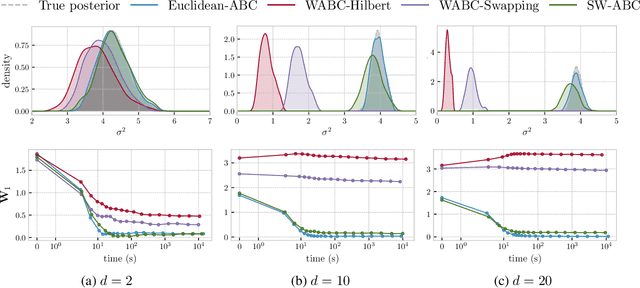
Approximate Bayesian Computation (ABC) is a popular method for approximate inference in generative models with intractable but easy-to-sample likelihood. It constructs an approximate posterior distribution by finding parameters for which the simulated data are close to the observations in terms of summary statistics. These statistics are defined beforehand and might induce a loss of information, which has been shown to deteriorate the quality of the approximation. To overcome this problem, Wasserstein-ABC has been recently proposed, and compares the datasets via the Wasserstein distance between their empirical distributions, but does not scale well to the dimension or the number of samples. We propose a new ABC technique, called Sliced-Wasserstein ABC and based on the Sliced-Wasserstein distance, which has better computational and statistical properties. We derive two theoretical results showing the asymptotical consistency of our approach, and we illustrate its advantages on synthetic data and an image denoising task.
Non-discriminative data or weak model? On the relative importance of data and model resolution
Oct 17, 2019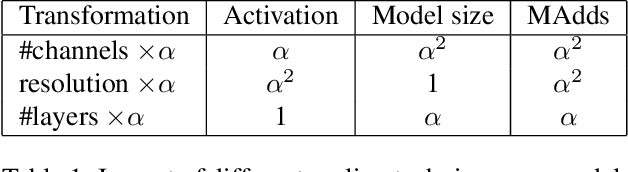
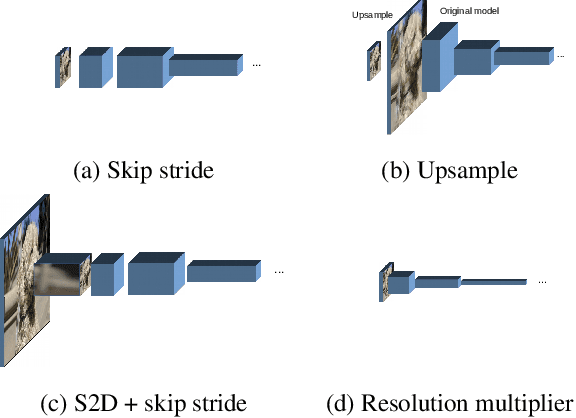
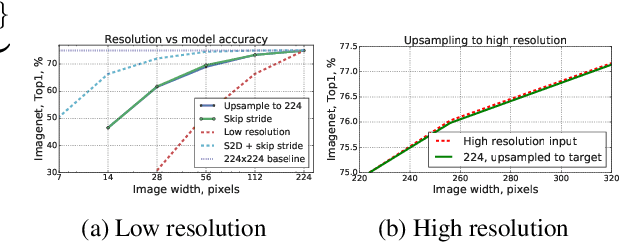

We explore the question of how the resolution of the input image ("input resolution") affects the performance of a neural network when compared to the resolution of the hidden layers ("internal resolution"). Adjusting these characteristics is frequently used as a hyperparameter providing a trade-off between model performance and accuracy. An intuitive interpretation is that the reduced information content in the low-resolution input causes decay in the accuracy. In this paper, we show that up to a point, the input resolution alone plays little role in the network performance, and it is the internal resolution that is the critical driver of model quality. We then build on these insights to develop novel neural network architectures that we call \emph{Isometric Neural Networks}. These models maintain a fixed internal resolution throughout their entire depth. We demonstrate that they lead to high accuracy models with low activation footprint and parameter count.