 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Budget-aware Semi-Supervised Semantic and Instance Segmentation
May 14, 2019
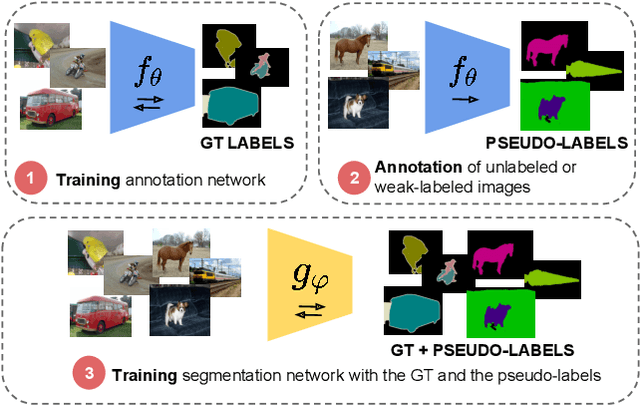


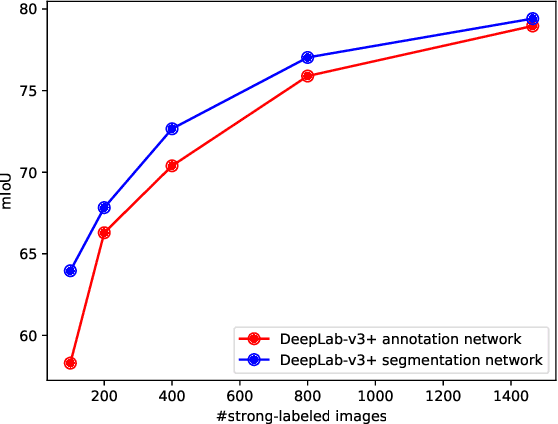
Methods that move towards less supervised scenarios are key for image segmentation, as dense labels demand significant human intervention. Generally, the annotation burden is mitigated by labeling datasets with weaker forms of supervision, e.g. image-level labels or bounding boxes. Another option are semi-supervised settings, that commonly leverage a few strong annotations and a huge number of unlabeled/weakly-labeled data. In this paper, we revisit semi-supervised segmentation schemes and narrow down significantly the annotation budget (in terms of total labeling time of the training set) compared to previous approaches. With a very simple pipeline, we demonstrate that at low annotation budgets, semi-supervised methods outperform by a wide margin weakly-supervised ones for both semantic and instance segmentation. Our approach also outperforms previous semi-supervised works at a much reduced labeling cost. We present results for the Pascal VOC benchmark and unify weakly and semi-supervised approaches by considering the total annotation budget, thus allowing a fairer comparison between methods.
Land Cover Change Detection via Semantic Segmentation
Nov 28, 2019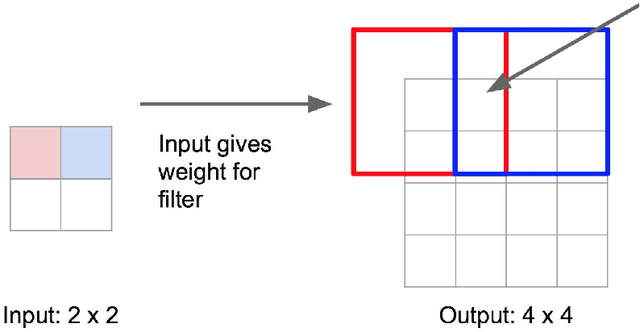
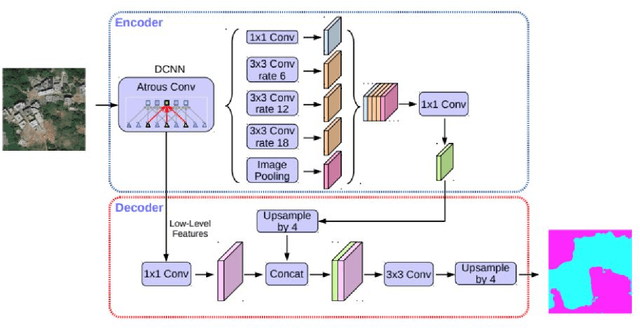

This paper presents a change detection method that identifies land cover changes from aerial imagery, using semantic segmentation, a machine learning approach. We present a land cover classification training pipeline with Deeplab v3+, state-of-the-art semantic segmentation technology, including data preparation, model training for seven land cover types, and model exporting modules. In the land cover change detection system, the inputs are images retrieved from Google Earth at the same location but from different times. The system then predicts semantic segmentation results on these images using the trained model and calculates the land cover class percentage for each input image. We see an improvement in the accuracy of the land cover semantic segmentation model, with a mean IoU of 0.756 compared to 0.433, as reported in the DeepGlobe land cover classification challenge. The land cover change detection system that leverages the state-of-the-art semantic segmentation technology is proposed and can be used for deforestation analysis, land management, and urban planning.
CG-GAN: An Interactive Evolutionary GAN-based Approach for Facial Composite Generation)
Nov 28, 2019

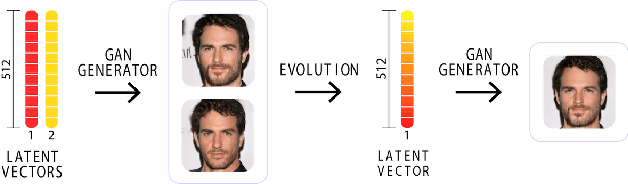
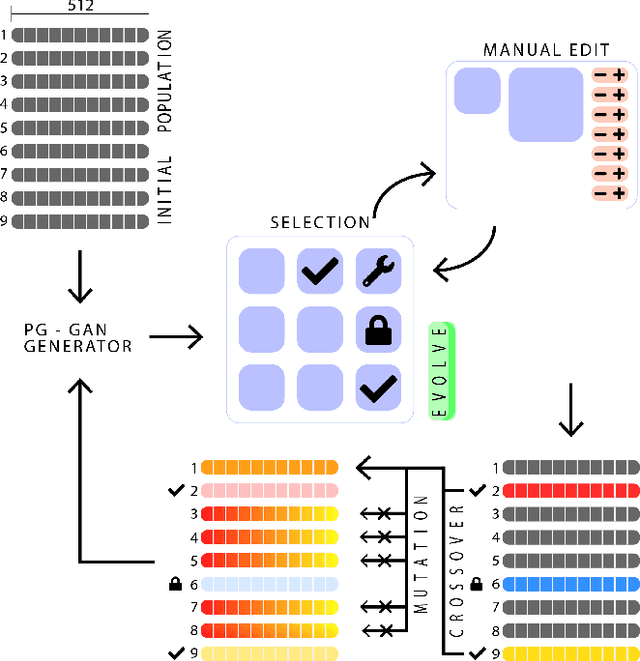
Facial composites are graphical representations of an eyewitness's memory of a face. Many digital systems are available for the creation of such composites but are either unable to reproduce features unless previously designed or do not allow holistic changes to the image. In this paper, we improve the efficiency of composite creation by removing the reliance on expert knowledge and letting the system learn to represent faces from examples. The novel approach, Composite Generating GAN (CG-GAN), applies generative and evolutionary computation to allow casual users to easily create facial composites. Specifically, CG-GAN utilizes the generator network of a pg-GAN to create high-resolution human faces. Users are provided with several functions to interactively breed and edit faces. CG-GAN offers a novel way of generating and handling static and animated photo-realistic facial composites, with the possibility of combining multiple representations of the same perpetrator, generated by different eyewitnesses.
Unsupervised Deep Learning by Neighbourhood Discovery
May 14, 2019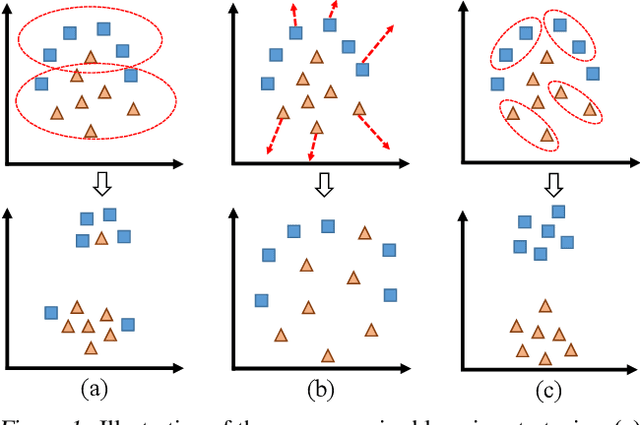
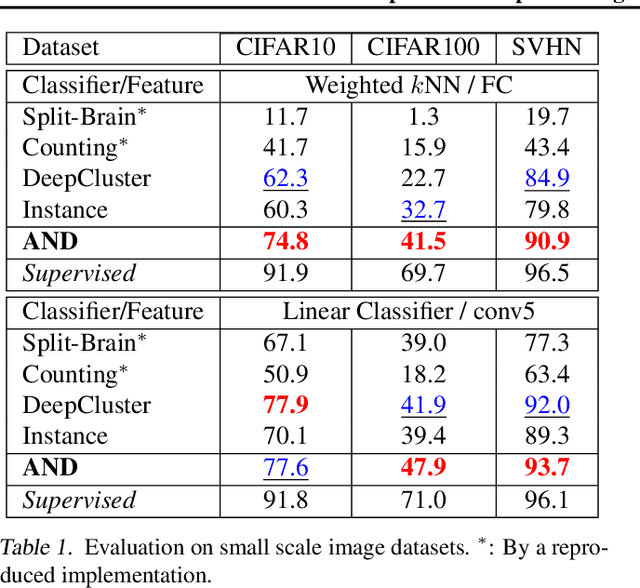
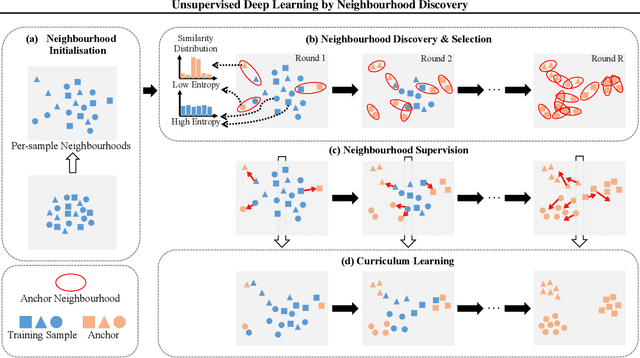
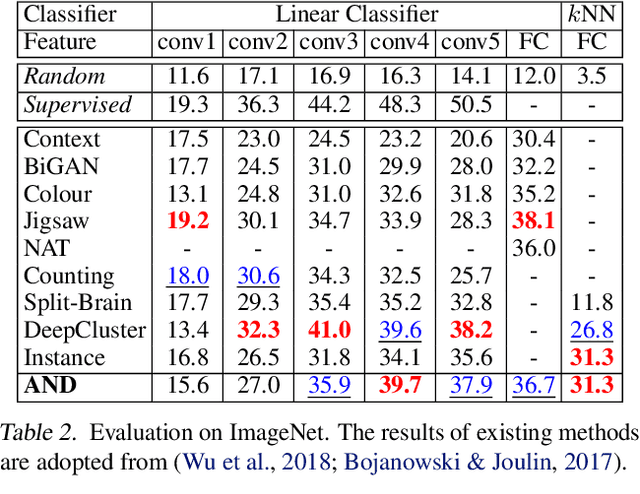
Deep convolutional neural networks (CNNs) have demonstrated remarkable success in computer vision by supervisedly learning strong visual feature representations. However, training CNNs relies heavily on the availability of exhaustive training data annotations, limiting significantly their deployment and scalability in many application scenarios. In this work, we introduce a generic unsupervised deep learning approach to training deep models without the need for any manual label supervision. Specifically, we progressively discover sample anchored/centred neighbourhoods to reason and learn the underlying class decision boundaries iteratively and accumulatively. Every single neighbourhood is specially formulated so that all the member samples can share the same unseen class labels at high probability for facilitating the extraction of class discriminative feature representations during training. Experiments on image classification show the performance advantages of the proposed method over the state-of-the-art unsupervised learning models on six benchmarks including both coarse-grained and fine-grained object image categorisation.
Learning from Synthetic Animals
Dec 17, 2019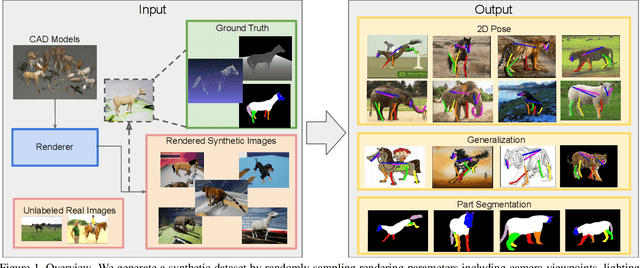
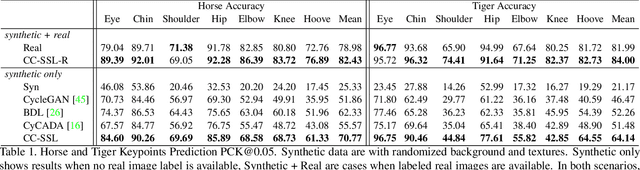
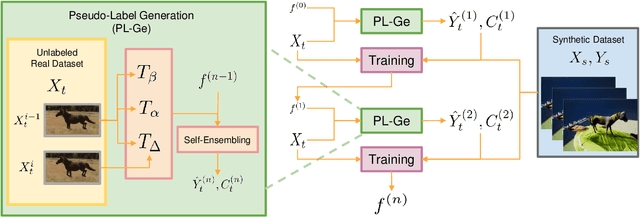

Despite great success in human parsing, progress for parsing other deformable articulated objects, like animals, is still limited by the lack of labeled data. In this paper, we use synthetic images and ground truth generated from CAD animal models to address this challenge. To bridge the gap between real and synthetic images, we propose a novel consistency-constrained semi-supervised learning method (CC-SSL). Our method leverages both spatial and temporal consistencies, to bootstrap weak models trained on synthetic data with unlabeled real images. We demonstrate the effectiveness of our method on highly deformable animals, such as horses and tigers. Without using any real image label, our method allows for accurate keypoints prediction on real images. Moreover, we quantitatively show that models using synthetic data achieve better generalization performance than models trained on real images across different domains in the Visual Domain Adaptation Challenge dataset. Our synthetic dataset contains 10+ animals with diverse poses and rich ground truth, which enables us to use the multi-task learning strategy to further boost models' performance.
DeepHashing using TripletLoss
Dec 17, 2019


Hashing is one of the most efficient techniques for approximate nearest neighbour search for large scale image retrieval. Most of the techniques are based on hand-engineered features and do not give optimal results all the time. Deep Convolutional Neural Networks have proven to generate very effective representation of images that are used for various computer vision tasks and inspired by this there have been several Deep Hashing models like Wang et al. (2016) have been proposed. These models train on the triplet loss function which can be used to train models with superior representation capabilities. Taking the latest advancements in training using the triplet loss I propose new techniques that help the Deep Hash-ing models train more faster and efficiently. Experiment result1show that using the more efficient techniques for training on the triplet loss, we have obtained a 5%percent improvement in our model compared to the original work of Wang et al.(2016). Using a larger model and more training data we can drastically improve the performance using the techniques we propose
Deep Verifier Networks: Verification of Deep Discriminative Models with Deep Generative Models
Nov 18, 2019
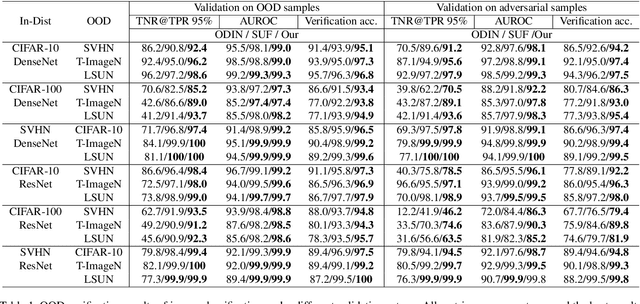
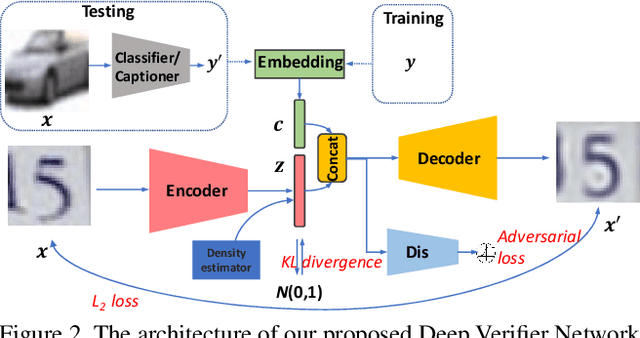

AI Safety is a major concern in many deep learning applications such as autonomous driving. Given a trained deep learning model, an important natural problem is how to reliably verify the model's prediction. In this paper, we propose a novel framework --- deep verifier networks (DVN) to verify the inputs and outputs of deep discriminative models with deep generative models. Our proposed model is based on conditional variational auto-encoders with disentanglement constraints. We give both intuitive and theoretical justifications of the model. Our verifier network is trained independently with the prediction model, which eliminates the need of retraining the verifier network for a new model. We test the verifier network on out-of-distribution detection and adversarial example detection problems, as well as anomaly detection problems in structured prediction tasks such as image caption generation. We achieve state-of-the-art results in all of these problems.
Learning Similarity Attention
Nov 18, 2019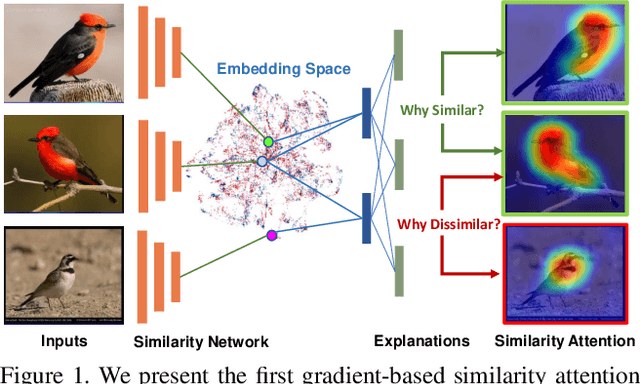
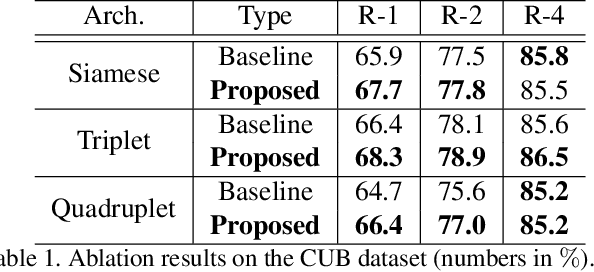
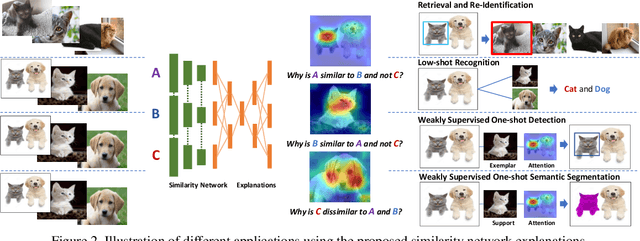
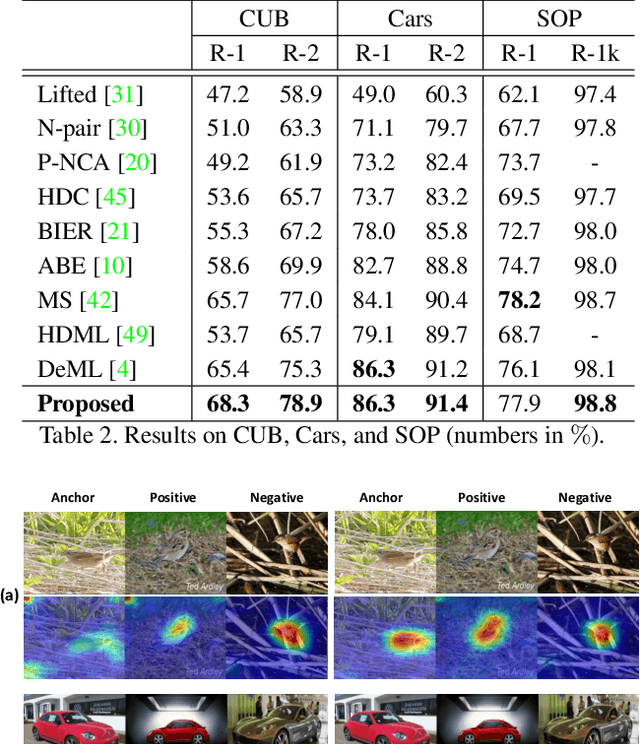
We consider the problem of learning similarity functions. While there has been substantial progress in learning suitable distance metrics, these techniques in general lack decision reasoning, i.e., explaining why the input set of images is similar or dissimilar. In this work, we solve this key problem by proposing the first method to generate generic visual similarity explanations with gradient-based attention. We demonstrate that our technique is agnostic to the specific similarity model type, e.g., we show applicability to Siamese, triplet, and quadruplet models. Furthermore, we make our proposed similarity attention a principled part of the learning process, resulting in a new paradigm for learning similarity functions. We demonstrate that our learning mechanism results in more generalizable, as well as explainable, similarity models. Finally, we demonstrate the generality of our framework by means of experiments on a variety of tasks, including image retrieval, person re-identification, and low-shot semantic segmentation.
CAMAL: Context-Aware Multi-scale Attention framework for Lightweight Visual Place Recognition
Sep 18, 2019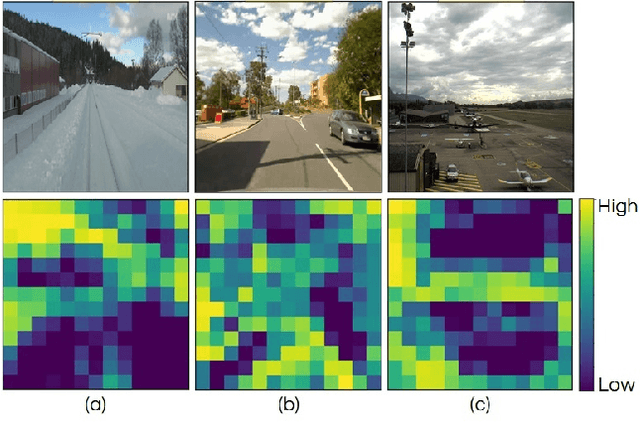
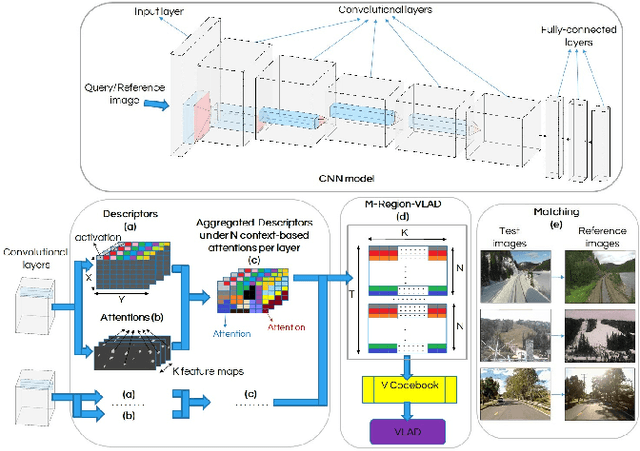
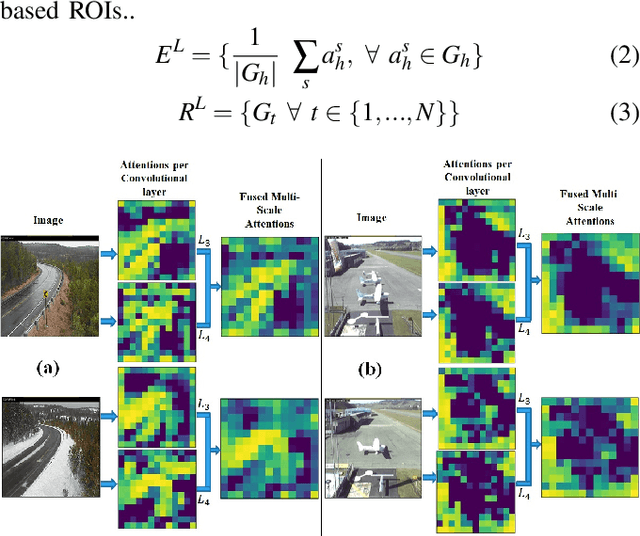
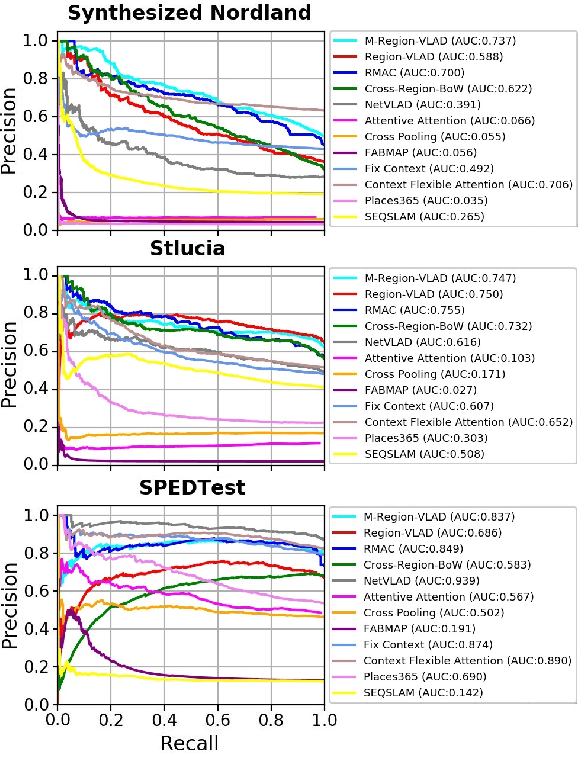
In the last few years, Deep Convolutional Neural Networks (D-CNNs) have shown state-of-the-art performances for Visual Place Recognition (VPR). Their prestigious generalization power has played a vital role in identifying persistent image regions under changing conditions and viewpoints. However, against the computation intensive D-CNNs based VPR algorithms, lightweight VPR techniques are preferred for resource-constraints mobile robots. This paper presents a lightweight CNN-based VPR technique that captures multi-layer context-aware attentions robust under changing environment and viewpoints. Evaluation of challenging benchmark datasets reveals better performance at low memory and resources utilization over state-of-the-art contemporary VPR methodologies.
Distributed High Dimensional Information Theoretical Image Registration via Random Projections
Oct 02, 2012

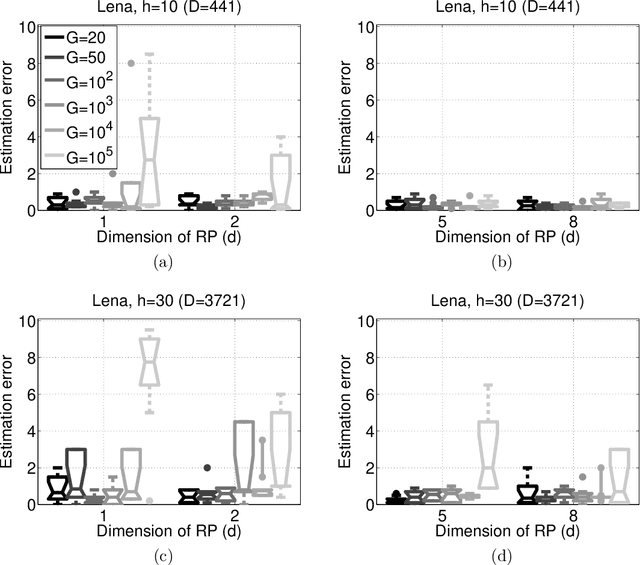
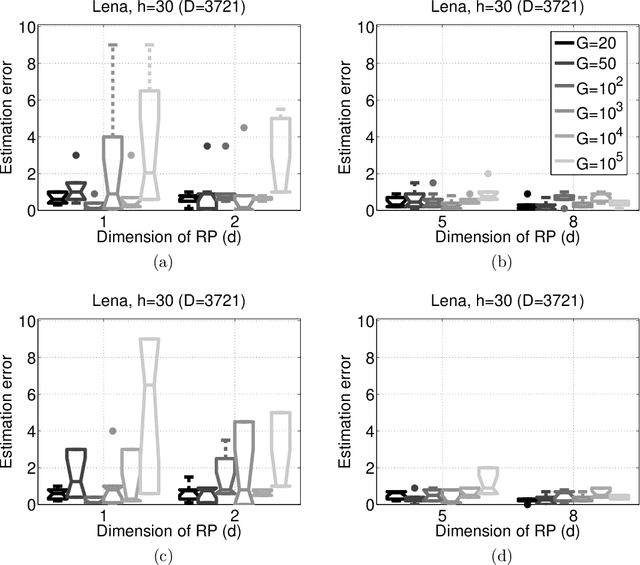
Information theoretical measures, such as entropy, mutual information, and various divergences, exhibit robust characteristics in image registration applications. However, the estimation of these quantities is computationally intensive in high dimensions. On the other hand, consistent estimation from pairwise distances of the sample points is possible, which suits random projection (RP) based low dimensional embeddings. We adapt the RP technique to this task by means of a simple ensemble method. To the best of our knowledge, this is the first distributed, RP based information theoretical image registration approach. The efficiency of the method is demonstrated through numerical examples.