 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShort-term electricity load forecasting with multi-frequency reconstruction diffusion
Jan 10, 2026Diffusion models have emerged as a powerful method in various applications. However, their application to Short-Term Electricity Load Forecasting (STELF) -- a typical scenario in energy systems -- remains largely unexplored. Considering the nonlinear and fluctuating characteristics of the load data, effectively utilizing the powerful modeling capabilities of diffusion models to enhance STELF accuracy remains a challenge. This paper proposes a novel diffusion model with multi-frequency reconstruction for STELF, referred to as the Multi-Frequency-Reconstruction-based Diffusion (MFRD) model. The MFRD model achieves accurate load forecasting through four key steps: (1) The original data is combined with the decomposed multi-frequency modes to form a new data representation; (2) The diffusion model adds noise to the new data, effectively reducing and weakening the noise in the original data; (3) The reverse process adopts a denoising network that combines Long Short-Term Memory (LSTM) and Transformer to enhance noise removal; and (4) The inference process generates the final predictions based on the trained denoising network. To validate the effectiveness of the MFRD model, we conducted experiments on two data platforms: Australian Energy Market Operator (AEMO) and Independent System Operator of New England (ISO-NE). The experimental results show that our model consistently outperforms the compared models.
HF-VTON: High-Fidelity Virtual Try-On via Consistent Geometric and Semantic Alignment
May 26, 2025Virtual try-on technology has become increasingly important in the fashion and retail industries, enabling the generation of high-fidelity garment images that adapt seamlessly to target human models. While existing methods have achieved notable progress, they still face significant challenges in maintaining consistency across different poses. Specifically, geometric distortions lead to a lack of spatial consistency, mismatches in garment structure and texture across poses result in semantic inconsistency, and the loss or distortion of fine-grained details diminishes visual fidelity. To address these challenges, we propose HF-VTON, a novel framework that ensures high-fidelity virtual try-on performance across diverse poses. HF-VTON consists of three key modules: (1) the Appearance-Preserving Warp Alignment Module (APWAM), which aligns garments to human poses, addressing geometric deformations and ensuring spatial consistency; (2) the Semantic Representation and Comprehension Module (SRCM), which captures fine-grained garment attributes and multi-pose data to enhance semantic representation, maintaining structural, textural, and pattern consistency; and (3) the Multimodal Prior-Guided Appearance Generation Module (MPAGM), which integrates multimodal features and prior knowledge from pre-trained models to optimize appearance generation, ensuring both semantic and geometric consistency. Additionally, to overcome data limitations in existing benchmarks, we introduce the SAMP-VTONS dataset, featuring multi-pose pairs and rich textual annotations for a more comprehensive evaluation. Experimental results demonstrate that HF-VTON outperforms state-of-the-art methods on both VITON-HD and SAMP-VTONS, excelling in visual fidelity, semantic consistency, and detail preservation.
Dynamic Manifold Evolution Theory: Modeling and Stability Analysis of Latent Representations in Large Language Models
May 24, 2025We introduce Dynamic Manifold Evolution Theory (DMET),a unified framework that models large language model generation as a controlled dynamical system evolving on a low_dimensional semantic manifold. By casting latent_state updates as discrete time Euler approximations of continuous dynamics, we map intrinsic energy_driven flows and context_dependent forces onto Transformer components (residual connections, attention, feed-forward networks). Leveraging Lyapunov stability theory We define three empirical metrics (state continuity, clustering quality, topological persistence) that quantitatively link latent_trajectory properties to text fluency, grammaticality, and semantic coherence. Extensive experiments across decoding parameters validate DMET's predictions and yield principled guidelines for balancing creativity and consistency in text generation.
Multi-Scale Manifold Alignment: A Unified Framework for Enhanced Explainability of Large Language Models
May 24, 2025Recent advances in Large Language Models (LLMs) have achieved strong performance, yet their internal reasoning remains opaque, limiting interpretability and trust in critical applications. We propose a novel Multi_Scale Manifold Alignment framework that decomposes the latent space into global, intermediate, and local semantic manifolds capturing themes, context, and word-level details. Our method introduces cross_scale mapping functions that jointly enforce geometric alignment (e.g., Procrustes analysis) and information preservation (via mutual information constraints like MINE or VIB). We further incorporate curvature regularization and hyperparameter tuning for stable optimization. Theoretical analysis shows that alignment error, measured by KL divergence, can be bounded under mild assumptions. This framework offers a unified explanation of how LLMs structure multi-scale semantics, advancing interpretability and enabling applications such as bias detection and robustness enhancement.
Multi-Scale Probabilistic Generation Theory: A Hierarchical Framework for Interpreting Large Language Models
May 23, 2025Large Transformer based language models achieve remarkable performance but remain opaque in how they plan, structure, and realize text. We introduce Multi_Scale Probabilistic Generation Theory (MSPGT), a hierarchical framework that factorizes generation into three semantic scales_global context, intermediate structure, and local word choices and aligns each scale with specific layer ranges in Transformer architectures. To identify scale boundaries, we propose two complementary metrics: attention span thresholds and inter layer mutual information peaks. Across four representative models (GPT-2, BERT, RoBERTa, and T5), these metrics yield stable local/intermediate/global partitions, corroborated by probing tasks and causal interventions. We find that decoder_only models allocate more layers to intermediate and global processing while encoder_only models emphasize local feature extraction. Through targeted interventions, we demonstrate that local scale manipulations primarily influence lexical diversity, intermediate-scale modifications affect sentence structure and length, and global_scale perturbations impact discourse coherence all with statistically significant effects. MSPGT thus offers a unified, architecture-agnostic method for interpreting, diagnosing, and controlling large language models, bridging the gap between mechanistic interpretability and emergent capabilities.
Short-Term Electricity-Load Forecasting by Deep Learning: A Comprehensive Survey
Aug 29, 2024Short-Term Electricity-Load Forecasting (STELF) refers to the prediction of the immediate demand (in the next few hours to several days) for the power system. Various external factors, such as weather changes and the emergence of new electricity consumption scenarios, can impact electricity demand, causing load data to fluctuate and become non-linear, which increases the complexity and difficulty of STELF. In the past decade, deep learning has been applied to STELF, modeling and predicting electricity demand with high accuracy, and contributing significantly to the development of STELF. This paper provides a comprehensive survey on deep-learning-based STELF over the past ten years. It examines the entire forecasting process, including data pre-processing, feature extraction, deep-learning modeling and optimization, and results evaluation. This paper also identifies some research challenges and potential research directions to be further investigated in future work.
Non-autoregressive Sequence-to-Sequence Vision-Language Models
Mar 04, 2024



Sequence-to-sequence vision-language models are showing promise, but their applicability is limited by their inference latency due to their autoregressive way of generating predictions. We propose a parallel decoding sequence-to-sequence vision-language model, trained with a Query-CTC loss, that marginalizes over multiple inference paths in the decoder. This allows us to model the joint distribution of tokens, rather than restricting to conditional distribution as in an autoregressive model. The resulting model, NARVL, achieves performance on-par with its state-of-the-art autoregressive counterpart, but is faster at inference time, reducing from the linear complexity associated with the sequential generation of tokens to a paradigm of constant time joint inference.
DocFormerv2: Local Features for Document Understanding
Jun 02, 2023



We propose DocFormerv2, a multi-modal transformer for Visual Document Understanding (VDU). The VDU domain entails understanding documents (beyond mere OCR predictions) e.g., extracting information from a form, VQA for documents and other tasks. VDU is challenging as it needs a model to make sense of multiple modalities (visual, language and spatial) to make a prediction. Our approach, termed DocFormerv2 is an encoder-decoder transformer which takes as input - vision, language and spatial features. DocFormerv2 is pre-trained with unsupervised tasks employed asymmetrically i.e., two novel document tasks on encoder and one on the auto-regressive decoder. The unsupervised tasks have been carefully designed to ensure that the pre-training encourages local-feature alignment between multiple modalities. DocFormerv2 when evaluated on nine datasets shows state-of-the-art performance over strong baselines e.g. TabFact (4.3%), InfoVQA (1.4%), FUNSD (1%). Furthermore, to show generalization capabilities, on three VQA tasks involving scene-text, Doc- Formerv2 outperforms previous comparably-sized models and even does better than much larger models (such as GIT2, PaLi and Flamingo) on some tasks. Extensive ablations show that due to its pre-training, DocFormerv2 understands multiple modalities better than prior-art in VDU.
Visual Composite Set Detection Using Part-and-Sum Transformers
May 05, 2021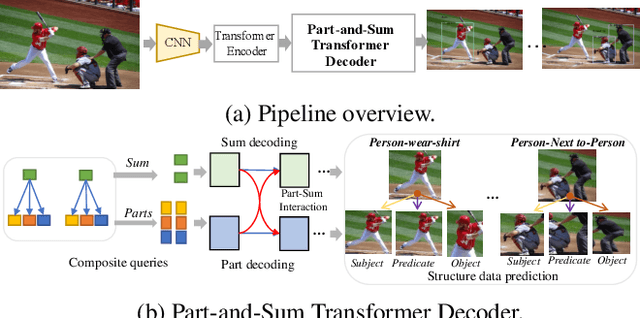

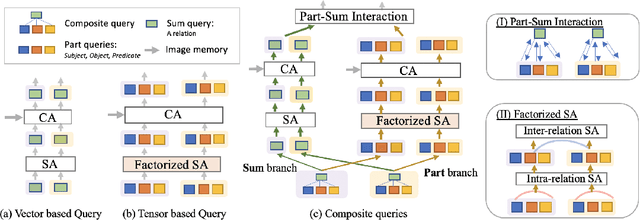

Computer vision applications such as visual relationship detection and human-object interaction can be formulated as a composite (structured) set detection problem in which both the parts (subject, object, and predicate) and the sum (triplet as a whole) are to be detected in a hierarchical fashion. In this paper, we present a new approach, denoted Part-and-Sum detection Transformer (PST), to perform end-to-end composite set detection. Different from existing Transformers in which queries are at a single level, we simultaneously model the joint part and sum hypotheses/interactions with composite queries and attention modules. We explicitly incorporate sum queries to enable better modeling of the part-and-sum relations that are absent in the standard Transformers. Our approach also uses novel tensor-based part queries and vector-based sum queries, and models their joint interaction. We report experiments on two vision tasks, visual relationship detection, and human-object interaction, and demonstrate that PST achieves state-of-the-art results among single-stage models, while nearly matching the results of custom-designed two-stage models.
Unsupervised Deep Learning by Neighbourhood Discovery
May 30, 2019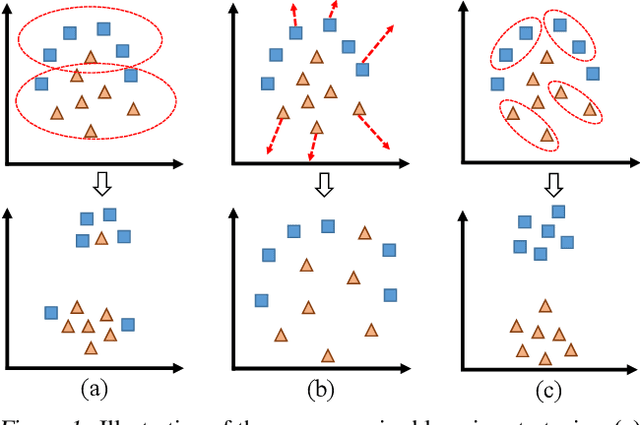
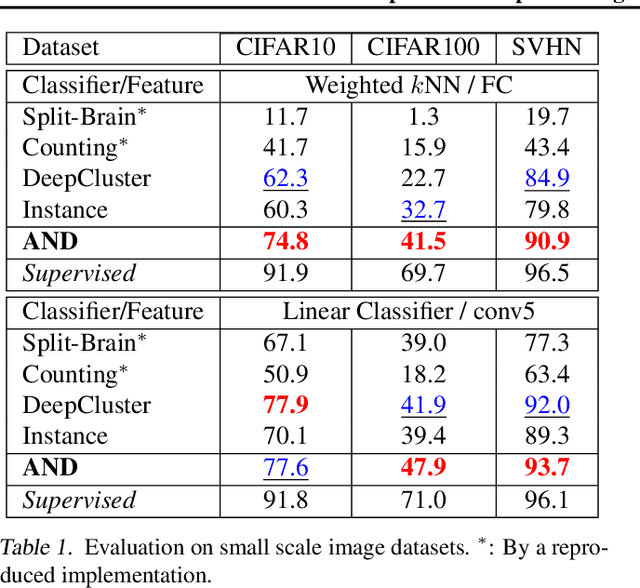
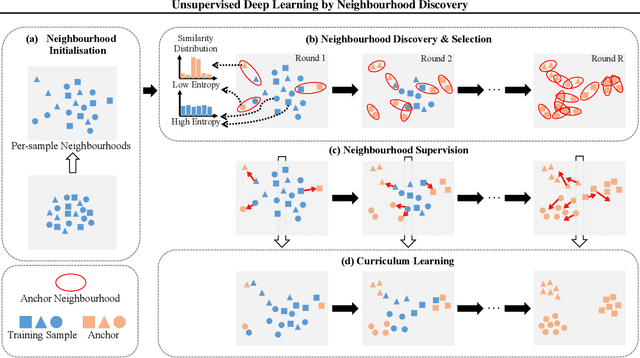
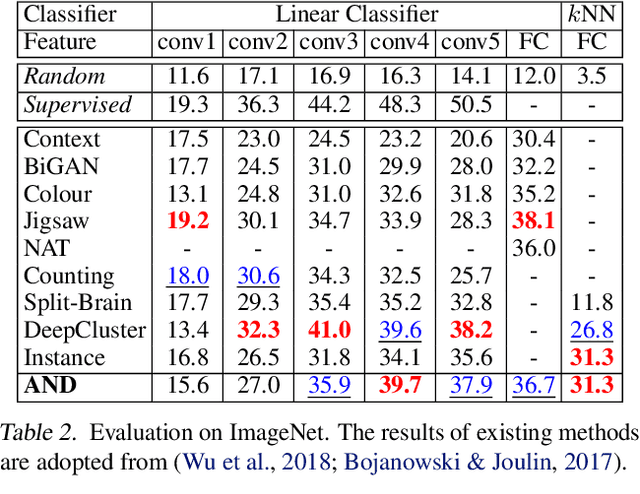
Deep convolutional neural networks (CNNs) have demonstrated remarkable success in computer vision by supervisedly learning strong visual feature representations. However, training CNNs relies heavily on the availability of exhaustive training data annotations, limiting significantly their deployment and scalability in many application scenarios. In this work, we introduce a generic unsupervised deep learning approach to training deep models without the need for any manual label supervision. Specifically, we progressively discover sample anchored/centred neighbourhoods to reason and learn the underlying class decision boundaries iteratively and accumulatively. Every single neighbourhood is specially formulated so that all the member samples can share the same unseen class labels at high probability for facilitating the extraction of class discriminative feature representations during training. Experiments on image classification show the performance advantages of the proposed method over the state-of-the-art unsupervised learning models on six benchmarks including both coarse-grained and fine-grained object image categorisation.