 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDimensionality Controls When Modularity Helps in Continual Learning
Jun 16, 2026Compositional learning systems must balance plasticity, the ability to acquire new knowledge, with stability, the preservation of previously learned components, especially when tasks share structure and risk interference. We study how modular architecture, task similarity, and representational dimensionality jointly shape compositional continual learning in a sequential A-B-A paradigm, comparing a task-partitioned recurrent network to a single-network baseline while inducing high- and low-dimensional regimes via weight-scale manipulations. In a high-dimensional "lazy" regime, both architectures achieve similar performance and internal geometry, suggesting that explicit modular structure has little impact when representations are weakly constrained. In a lower-dimensional "rich" regime, modularity becomes decisive: the modular network develops graded task-specific subspaces that overlap for similar tasks, partially align for moderately dissimilar tasks, and separate for dissimilar tasks, yielding a more compositional and interpretable organization than the single network. These findings identify the representational regime induced by initialization scale, which co-varies with representational dimensionality, as a key factor governing when compositional, modular structure is functionally beneficial in continual learning, and support viewing safety and robustness as problems of adaptive allocation of representational subspaces rather than fixed separation versus sharing.
Vector Policy Optimization: Training for Diversity Improves Test-Time Search
May 21, 2026Language models must now generalize out of the box to novel environments and work inside inference-scaling search procedures, such as AlphaEvolve, that select rollouts with a variety of task-specific reward functions. Unfortunately, the standard paradigm of LLM post-training optimizes a pre-specified scalar reward, often leading current LLMs to produce low-entropy response distributions and thus to struggle at displaying the diversity that inference-time search will require. We propose Vector Policy Optimization (VPO), an RL algorithm that explicitly trains policies to anticipate diverse downstream reward functions and to produce diverse solutions. VPO exploits that rewards are often vector-valued in practice, like per-test-case correctness in code generation or, say, multiple different user personas or reward models. VPO is essentially a drop-in replacement for the GRPO advantage estimator, but it trains the LLM to output a set of solutions where individual solutions specialize to different trade-offs in the vector reward space. Across four tasks, VPO matches or beats the strongest scalar RL baselines on test-time search (e.g. pass@k and best@k), with the gap widening as the search budget grows. For evolutionary search, VPO models unlock problems that GRPO models cannot solve at all. As test-time search becomes more standardized, optimizing for diversity may need to become the default post-training objective.
Learning Developmental Scaffoldings to Guide Self-Organisation
May 14, 2026From subcellular structures to entire organisms, many natural systems generate complex organisation through self-organisation: local interactions that collectively give rise to global structure without any blueprint of the outcome. Yet a significant portion of the information driving such processes is not produced by self-organisation itself, instead, it is often offloaded to initial conditions of the system. Biological development is a prime example, where maternal pre-patterns encode positional and symmetry-breaking information that scaffolds the self-organising process. From maternal morphogen gradients in early embryogenesis to tissue-level morphogenetic pre-patterns guiding organ formation, this transfer of information to initial conditions, analogous to a memory-compute trade-off in computational systems, is a fundamental part of developmental processes. In this work, we study this offloading phenomenon by introducing a model that jointly learns both the self-organisation rules and the pre-patterns, allowing their interplay to be varied and measured under controlled conditions: a Neural Cellular Automaton (NCA) paired with a learned coordinate-based pattern generator (SIREN), both trained simultaneously to generate a set of patterns. We provide information-theoretic analyses of how information is distributed between pre-patterns and the self-organising process, and show that jointly learning both components yields improvements in robustness, encoding capacity, and symmetry breaking over purely self-organising alternatives. Our analysis further suggests that effective pre-patterns do not simply approximate their targets; rather, they bias the developmental dynamics in ways that facilitate convergence, pointing to a non-trivial relationship between the structure of initial conditions and the dynamics of self-organisation.
Simple Baselines are Competitive with Code Evolution
Feb 18, 2026Code evolution is a family of techniques that rely on large language models to search through possible computer programs by evolving or mutating existing code. Many proposed code evolution pipelines show impressive performance but are often not compared to simpler baselines. We test how well two simple baselines do over three domains: finding better mathematical bounds, designing agentic scaffolds, and machine learning competitions. We find that simple baselines match or exceed much more sophisticated methods in all three. By analyzing these results we find various shortcomings in how code evolution is both developed and used. For the mathematical bounds, a problem's search space and domain knowledge in the prompt are chiefly what dictate a search's performance ceiling and efficiency, with the code evolution pipeline being secondary. Thus, the primary challenge in finding improved bounds is designing good search spaces, which is done by domain experts, and not the search itself. When designing agentic scaffolds we find that high variance in the scaffolds coupled with small datasets leads to suboptimal scaffolds being selected, resulting in hand-designed majority vote scaffolds performing best. We propose better evaluation methods that reduce evaluation stochasticity while keeping the code evolution economically feasible. We finish with a discussion of avenues and best practices to enable more rigorous code evolution in future work.
Tournament Informed Adversarial Quality Diversity
Jan 27, 2026Quality diversity (QD) is a branch of evolutionary computation that seeks high-quality and behaviorally diverse solutions to a problem. While adversarial problems are common, classical QD cannot be easily applied to them, as both the fitness and the behavior depend on the opposing solutions. Recently, Generational Adversarial MAP-Elites (GAME) has been proposed to coevolve both sides of an adversarial problem by alternating the execution of a multi-task QD algorithm against previous elites, called tasks. The original algorithm selects new tasks based on a behavioral criterion, which may lead to undesired dynamics due to inter-side dependencies. In addition, comparing sets of solutions cannot be done directly using classical QD measures due to side dependencies. In this paper, we (1) use an inter-variants tournament to compare the sets of solutions, ensuring a fair comparison, with 6 measures of quality and diversity, and (2) propose two tournament-informed task selection methods to promote higher quality and diversity at each generation. We evaluate the variants across three adversarial problems: Pong, a Cat-and-mouse game, and a Pursuers-and-evaders game. We show that the tournament-informed task selection method leads to higher adversarial quality and diversity. We hope that this work will help further advance adversarial quality diversity. Code, videos, and supplementary material are available at https://github.com/Timothee-ANNE/GAME_tournament_informed.
Digital Red Queen: Adversarial Program Evolution in Core War with LLMs
Jan 06, 2026Large language models (LLMs) are increasingly being used to evolve solutions to problems in many domains, in a process inspired by biological evolution. However, unlike biological evolution, most LLM-evolution frameworks are formulated as static optimization problems, overlooking the open-ended adversarial dynamics that characterize real-world evolutionary processes. Here, we study Digital Red Queen (DRQ), a simple self-play algorithm that embraces these so-called "Red Queen" dynamics via continual adaptation to a changing objective. DRQ uses an LLM to evolve assembly-like programs, called warriors, which compete against each other for control of a virtual machine in the game of Core War, a Turing-complete environment studied in artificial life and connected to cybersecurity. In each round of DRQ, the model evolves a new warrior to defeat all previous ones, producing a sequence of adapted warriors. Over many rounds, we observe that warriors become increasingly general (relative to a set of held-out human warriors). Interestingly, warriors also become less behaviorally diverse across independent runs, indicating a convergence pressure toward a general-purpose behavioral strategy, much like convergent evolution in nature. This result highlights a potential value of shifting from static objectives to dynamic Red Queen objectives. Our work positions Core War as a rich, controllable sandbox for studying adversarial adaptation in artificial systems and for evaluating LLM-based evolution methods. More broadly, the simplicity and effectiveness of DRQ suggest that similarly minimal self-play approaches could prove useful in other more practical multi-agent adversarial domains, like real-world cybersecurity or combating drug resistance.
Hypernetworks That Evolve Themselves
Dec 18, 2025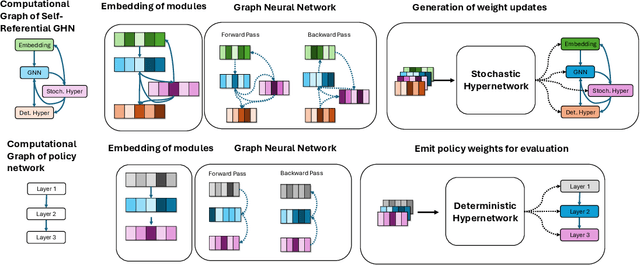

How can neural networks evolve themselves without relying on external optimizers? We propose Self-Referential Graph HyperNetworks, systems where the very machinery of variation and inheritance is embedded within the network. By uniting hypernetworks, stochastic parameter generation, and graph-based representations, Self-Referential GHNs mutate and evaluate themselves while adapting mutation rates as selectable traits. Through new reinforcement learning benchmarks with environmental shifts (CartPoleSwitch, LunarLander-Switch), Self-Referential GHNs show swift, reliable adaptation and emergent population dynamics. In the locomotion benchmark Ant-v5, they evolve coherent gaits, showing promising fine-tuning capabilities by autonomously decreasing variation in the population to concentrate around promising solutions. Our findings support the idea that evolvability itself can emerge from neural self-reference. Self-Referential GHNs reflect a step toward synthetic systems that more closely mirror biological evolution, offering tools for autonomous, open-ended learning agents.
Solving Inverse Problems in Stochastic Self-Organising Systems through Invariant Representations
Jun 13, 2025Self-organising systems demonstrate how simple local rules can generate complex stochastic patterns. Many natural systems rely on such dynamics, making self-organisation central to understanding natural complexity. A fundamental challenge in modelling such systems is solving the inverse problem: finding the unknown causal parameters from macroscopic observations. This task becomes particularly difficult when observations have a strong stochastic component, yielding diverse yet equivalent patterns. Traditional inverse methods fail in this setting, as pixel-wise metrics cannot capture feature similarities between variable outcomes. In this work, we introduce a novel inverse modelling method specifically designed to handle stochasticity in the observable space, leveraging the capacity of visual embeddings to produce robust representations that capture perceptual invariances. By mapping the pattern representations onto an invariant embedding space, we can effectively recover unknown causal parameters without the need for handcrafted objective functions or heuristics. We evaluate the method on two canonical models--a reaction-diffusion system and an agent-based model of social segregation--and show that it reliably recovers parameters despite stochasticity in the outcomes. We further apply the method to real biological patterns, highlighting its potential as a tool for both theorists and experimentalists to investigate the dynamics underlying complex stochastic pattern formation.
When Does Neuroevolution Outcompete Reinforcement Learning in Transfer Learning Tasks?
May 28, 2025



The ability to continuously and efficiently transfer skills across tasks is a hallmark of biological intelligence and a long-standing goal in artificial systems. Reinforcement learning (RL), a dominant paradigm for learning in high-dimensional control tasks, is known to suffer from brittleness to task variations and catastrophic forgetting. Neuroevolution (NE) has recently gained attention for its robustness, scalability, and capacity to escape local optima. In this paper, we investigate an understudied dimension of NE: its transfer learning capabilities. To this end, we introduce two benchmarks: a) in stepping gates, neural networks are tasked with emulating logic circuits, with designs that emphasize modular repetition and variation b) ecorobot extends the Brax physics engine with objects such as walls and obstacles and the ability to easily switch between different robotic morphologies. Crucial in both benchmarks is the presence of a curriculum that enables evaluating skill transfer across tasks of increasing complexity. Our empirical analysis shows that NE methods vary in their transfer abilities and frequently outperform RL baselines. Our findings support the potential of NE as a foundation for building more adaptable agents and highlight future challenges for scaling NE to complex, real-world problems.
Adversarial Coevolutionary Illumination with Generational Adversarial MAP-Elites
May 10, 2025



Unlike traditional optimization algorithms focusing on finding a single optimal solution, Quality-Diversity (QD) algorithms illuminate a search space by finding high-performing solutions that cover a specified behavior space. However, tackling adversarial problems is more challenging due to the behavioral interdependence between opposing sides. Most applications of QD algorithms to these problems evolve only one side, thus reducing illumination coverage. In this paper, we propose a new QD algorithm, Generational Adversarial MAP-Elites (GAME), which coevolves solutions by alternating sides through a sequence of generations. Combining GAME with vision embedding models enables the algorithm to directly work from videos of behaviors instead of handcrafted descriptors. Some key findings are that (1) emerging evolutionary dynamics sometimes resemble an arms race, (2) starting each generation from scratch increases open-endedness, and (3) keeping neutral mutations preserves stepping stones that seem necessary to reach the highest performance. In conclusion, the results demonstrate that GAME can successfully illuminate an adversarial multi-agent game, opening up interesting future directions in understanding the emergence of open-ended coevolution.