 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVLAD-BuFF: Burst-aware Fast Feature Aggregation for Visual Place Recognition
Sep 28, 2024Visual Place Recognition (VPR) is a crucial component of many visual localization pipelines for embodied agents. VPR is often formulated as an image retrieval task aimed at jointly learning local features and an aggregation method. The current state-of-the-art VPR methods rely on VLAD aggregation, which can be trained to learn a weighted contribution of features through their soft assignment to cluster centers. However, this process has two key limitations. Firstly, the feature-to-cluster weighting does not account for over-represented repetitive structures within a cluster, e.g., shadows or window panes; this phenomenon is also referred to as the `burstiness' problem, classically solved by discounting repetitive features before aggregation. Secondly, feature to cluster comparisons are compute-intensive for state-of-the-art image encoders with high-dimensional local features. This paper addresses these limitations by introducing VLAD-BuFF with two novel contributions: i) a self-similarity based feature discounting mechanism to learn Burst-aware features within end-to-end VPR training, and ii) Fast Feature aggregation by reducing local feature dimensions specifically through PCA-initialized learnable pre-projection. We benchmark our method on 9 public datasets, where VLAD-BuFF sets a new state of the art. Our method is able to maintain its high recall even for 12x reduced local feature dimensions, thus enabling fast feature aggregation without compromising on recall. Through additional qualitative studies, we show how our proposed weighting method effectively downweights the non-distinctive features. Source code: https://github.com/Ahmedest61/VLAD-BuFF/.
MultiRes-NetVLAD: Augmenting Place Recognition Training with Low-Resolution Imagery
Feb 18, 2022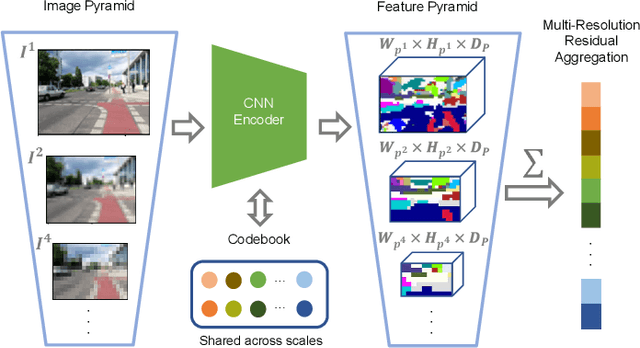
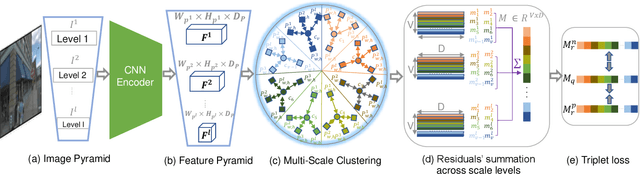
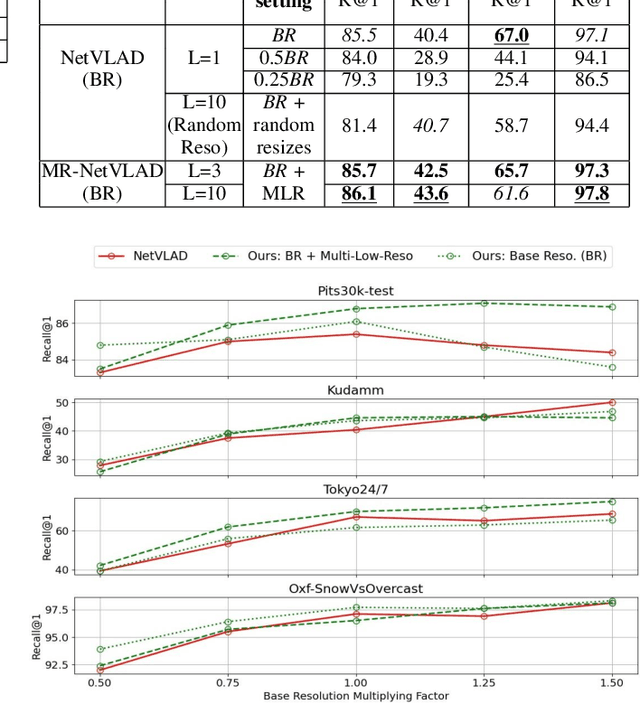

Visual Place Recognition (VPR) is a crucial component of 6-DoF localization, visual SLAM and structure-from-motion pipelines, tasked to generate an initial list of place match hypotheses by matching global place descriptors. However, commonly-used CNN-based methods either process multiple image resolutions after training or use a single resolution and limit multi-scale feature extraction to the last convolutional layer during training. In this paper, we augment NetVLAD representation learning with low-resolution image pyramid encoding which leads to richer place representations. The resultant multi-resolution feature pyramid can be conveniently aggregated through VLAD into a single compact representation, avoiding the need for concatenation or summation of multiple patches in recent multi-scale approaches. Furthermore, we show that the underlying learnt feature tensor can be combined with existing multi-scale approaches to improve their baseline performance. Evaluation on 15 viewpoint-varying and viewpoint-consistent benchmarking datasets confirm that the proposed MultiRes-NetVLAD leads to state-of-the-art Recall@N performance for global descriptor based retrieval, compared against 11 existing techniques. Source code is publicly available at https://github.com/Ahmedest61/MultiRes-NetVLAD.
* 12 pages, 6 Figures, Accepted for publication in IEEE RA-L 2022 and ICRA 2022, includes supplementary material
CAMAL: Context-Aware Multi-scale Attention framework for Lightweight Visual Place Recognition
Sep 18, 2019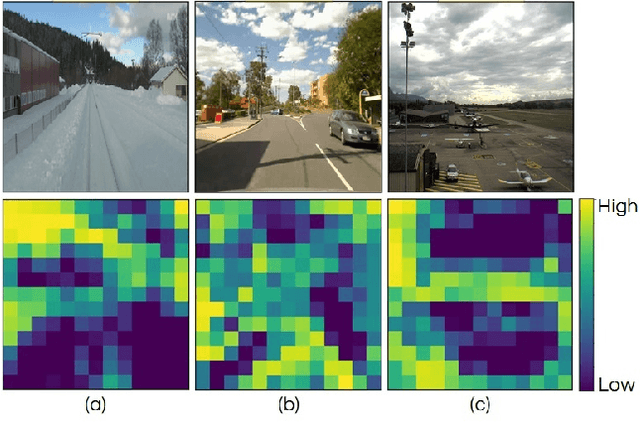
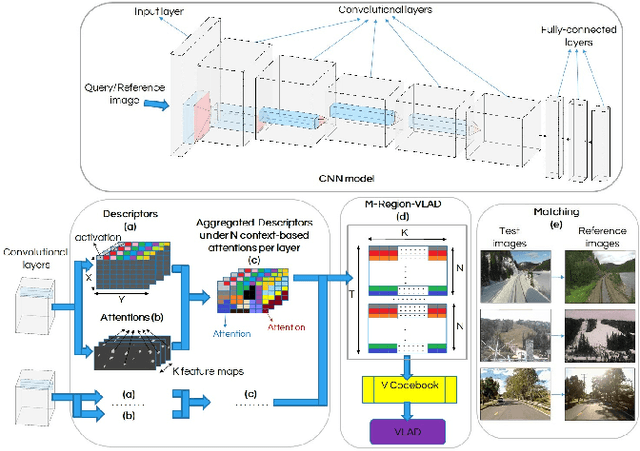
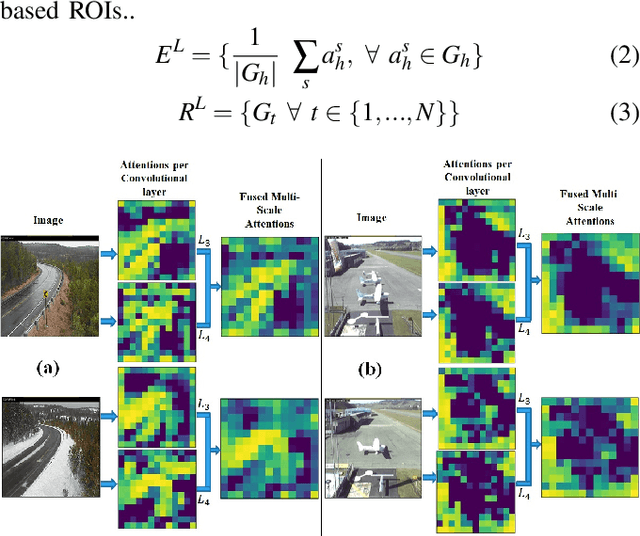
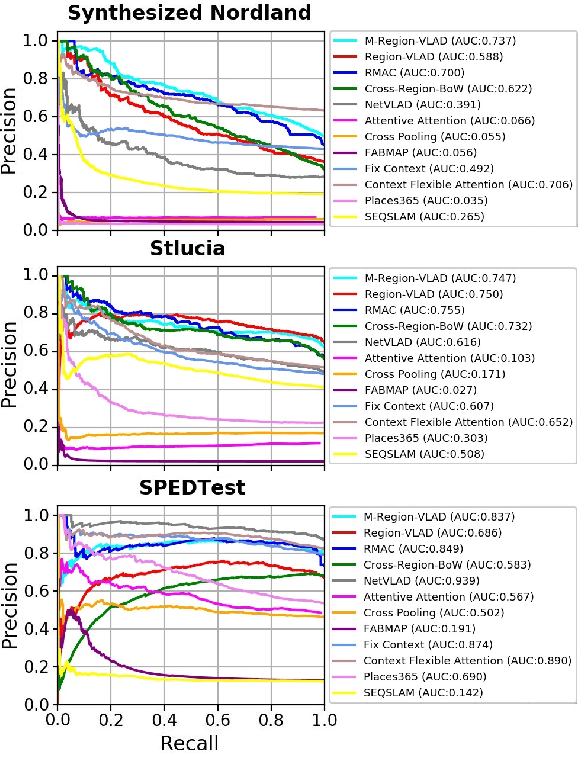
In the last few years, Deep Convolutional Neural Networks (D-CNNs) have shown state-of-the-art performances for Visual Place Recognition (VPR). Their prestigious generalization power has played a vital role in identifying persistent image regions under changing conditions and viewpoints. However, against the computation intensive D-CNNs based VPR algorithms, lightweight VPR techniques are preferred for resource-constraints mobile robots. This paper presents a lightweight CNN-based VPR technique that captures multi-layer context-aware attentions robust under changing environment and viewpoints. Evaluation of challenging benchmark datasets reveals better performance at low memory and resources utilization over state-of-the-art contemporary VPR methodologies.
Are State-of-the-art Visual Place Recognition Techniques any Good for Aerial Robotics?
May 22, 2019



Visual Place Recognition (VPR) has seen significant advances at the frontiers of matching performance and computational superiority over the past few years. However, these evaluations are performed for ground-based mobile platforms and cannot be generalized to aerial platforms. The degree of viewpoint variation experienced by aerial robots is complex, with their processing power and on-board memory limited by payload size and battery ratings. Therefore, in this paper, we collect $8$ state-of-the-art VPR techniques that have been previously evaluated for ground-based platforms and compare them on $2$ recently proposed aerial place recognition datasets with three prime focuses: a) Matching performance b) Processing power consumption c) Projected memory requirements. This gives a birds-eye view of the applicability of contemporary VPR research to aerial robotics and lays down the the nature of challenges for aerial-VPR.
Levelling the Playing Field: A Comprehensive Comparison of Visual Place Recognition Approaches under Changing Conditions
Mar 21, 2019



In recent years there has been significant improvement in the capability of Visual Place Recognition (VPR) methods, building on the success of both hand-crafted and learnt visual features, temporal filtering and usage of semantic scene information. The wide range of approaches and the relatively recent growth in interest in the field has meant that a wide range of datasets and assessment methodologies have been proposed, often with a focus only on precision-recall type metrics, making comparison difficult. In this paper we present a comprehensive approach to evaluating the performance of 10 state-of-the-art recently-developed VPR techniques, which utilizes three standardized metrics: (a) Matching Performance b) Matching Time c) Memory Footprint. Together this analysis provides an up-to-date and widely encompassing snapshot of the various strengths and weaknesses of contemporary approaches to the VPR problem. The aim of this work is to help move this particular research field towards a more mature and unified approach to the problem, enabling better comparison and hence more progress to be made in future research.
A Holistic Visual Place Recognition Approach using Lightweight CNNs for Severe ViewPoint and Appearance Changes
Nov 14, 2018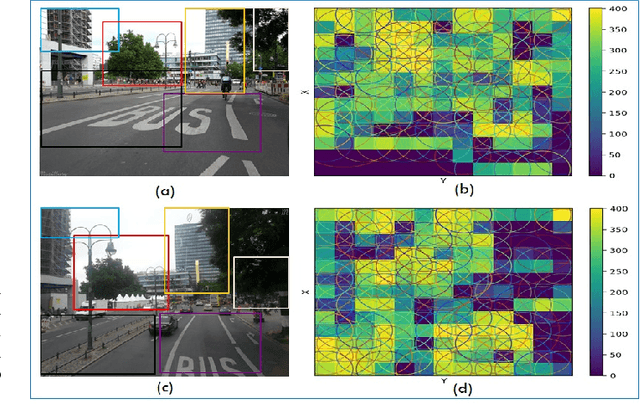
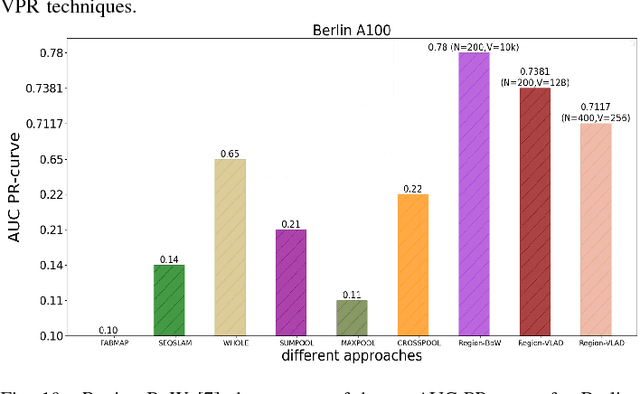
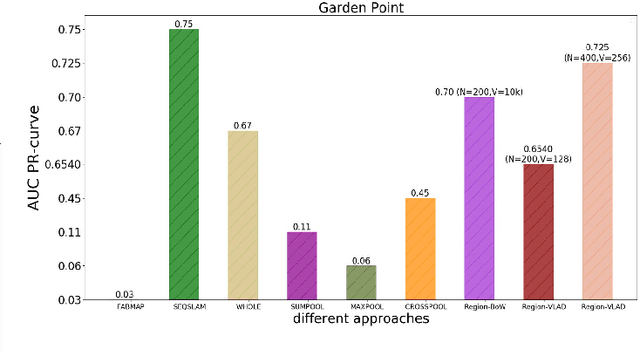
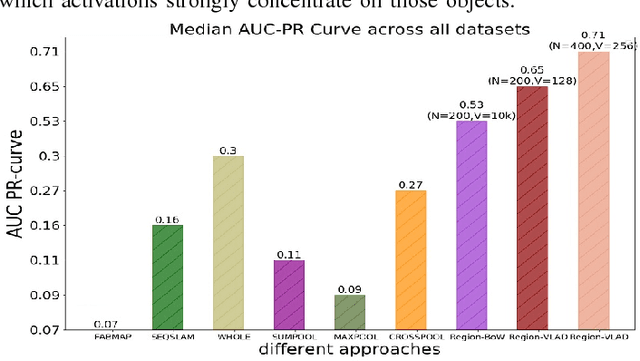
This paper presents a lightweight visual place recognition approach, capable of achieving high performance with low computational cost, and feasible for mobile robotics under severe viewpoint and appearance changes. Results on several benchmark datasets confirm an average boost of 10% in accuracy, and 5% average speedup relative to state-of-the-art methods.