 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCAMAL: Context-Aware Multi-scale Attention framework for Lightweight Visual Place Recognition
Paper and Code
Sep 18, 2019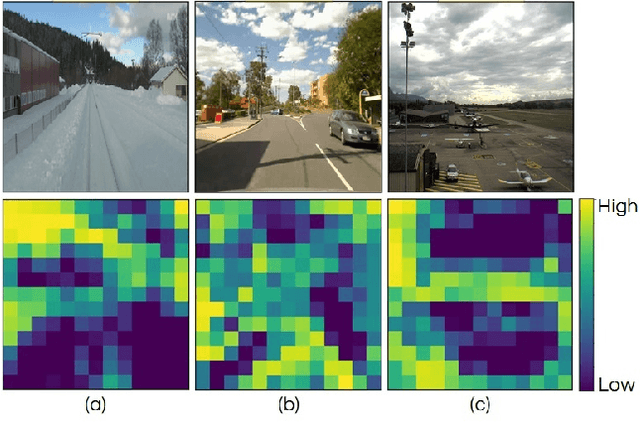
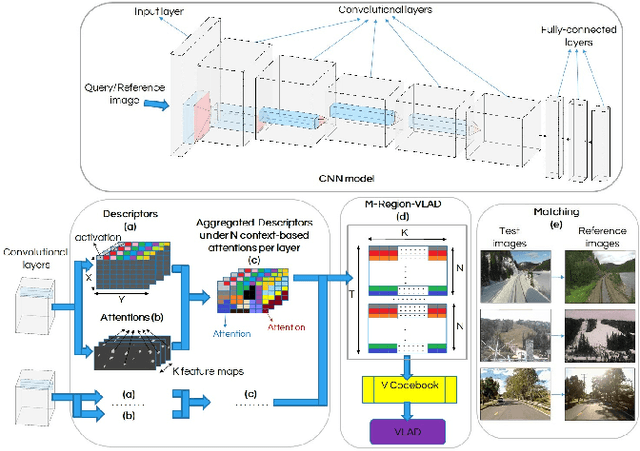
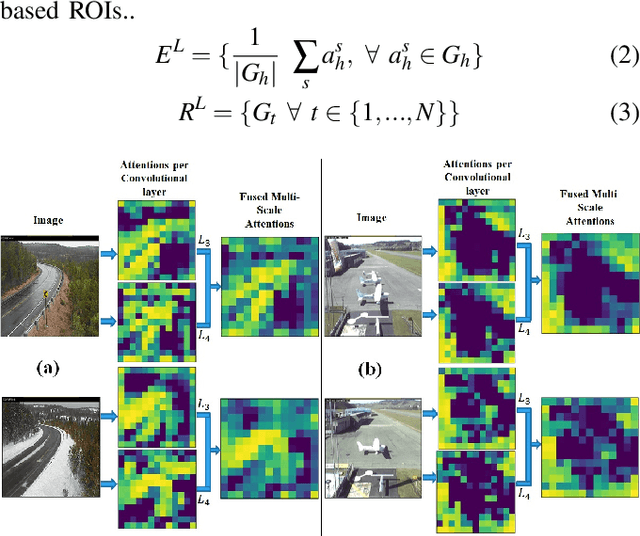
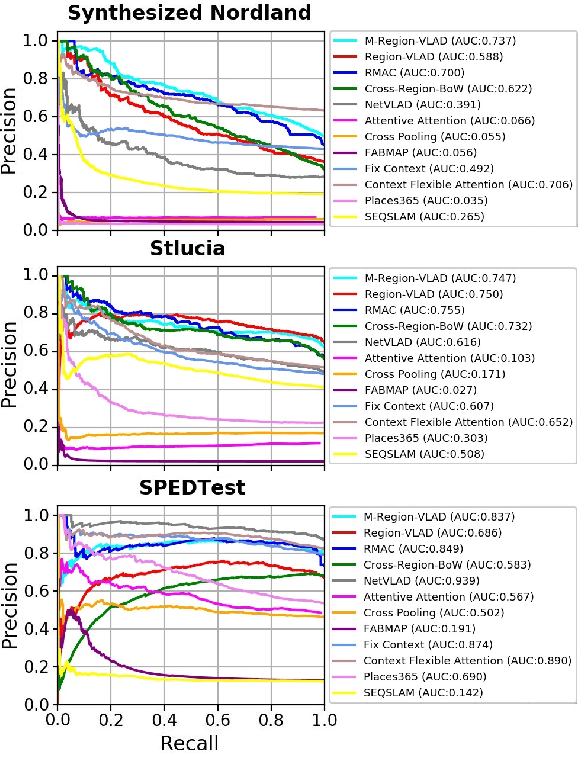
In the last few years, Deep Convolutional Neural Networks (D-CNNs) have shown state-of-the-art performances for Visual Place Recognition (VPR). Their prestigious generalization power has played a vital role in identifying persistent image regions under changing conditions and viewpoints. However, against the computation intensive D-CNNs based VPR algorithms, lightweight VPR techniques are preferred for resource-constraints mobile robots. This paper presents a lightweight CNN-based VPR technique that captures multi-layer context-aware attentions robust under changing environment and viewpoints. Evaluation of challenging benchmark datasets reveals better performance at low memory and resources utilization over state-of-the-art contemporary VPR methodologies.