 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
TableBank: A Benchmark Dataset for Table Detection and Recognition
Mar 05, 2019
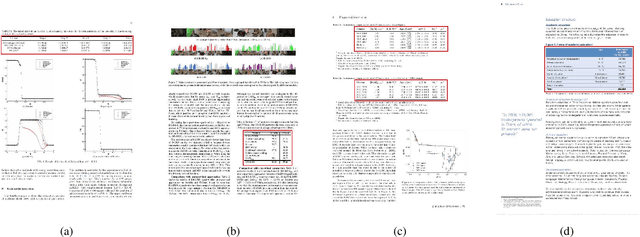
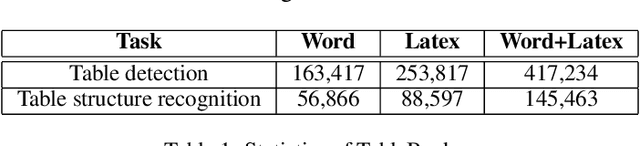
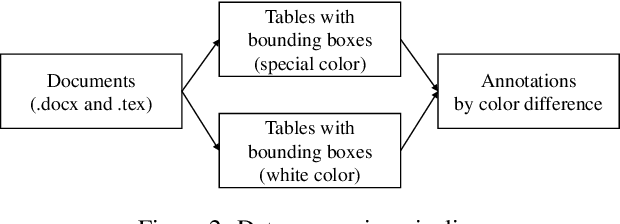
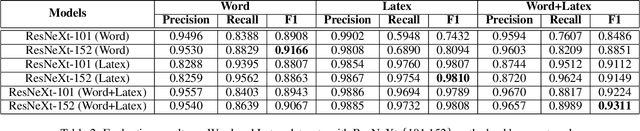
We present TableBank, a new image-based table detection and recognition dataset built with novel weak supervision from Word and Latex documents on the internet. Existing research for image-based table detection and recognition usually fine-tunes pre-trained models on out-of-domain data with a few thousands human labeled examples, which is difficult to generalize on real world applications. With TableBank that contains 417K high-quality labeled tables, we build several strong baselines using state-of-the-art models with deep neural networks. We make TableBank publicly available (https://github.com/doc-analysis/TableBank) and hope it will empower more deep learning approaches in the table detection and recognition task.
Pseudo-Labeling for Small Lesion Detection on Diabetic Retinopathy Images
Mar 26, 2020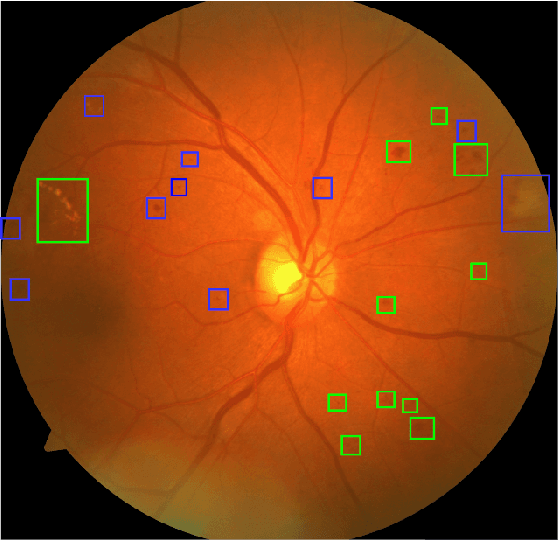
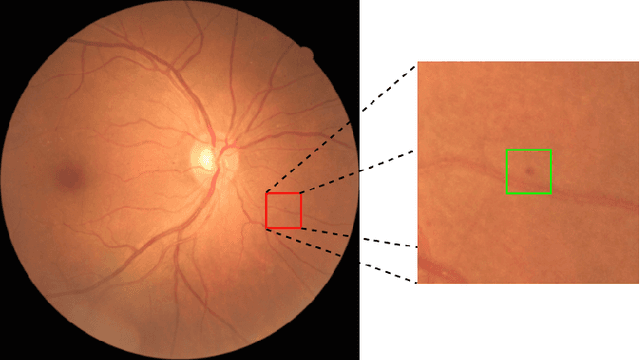
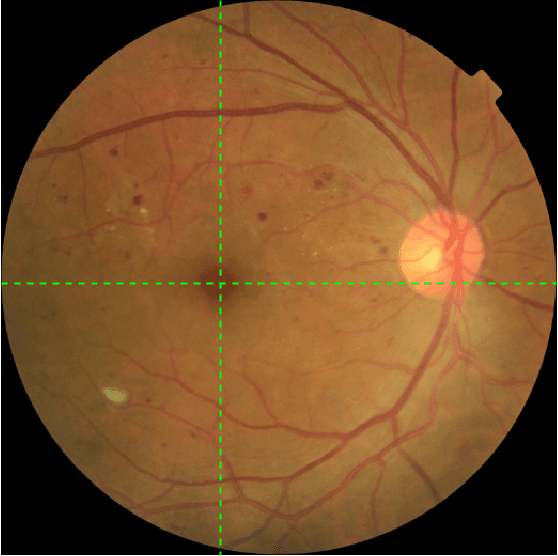
Diabetic retinopathy (DR) is a primary cause of blindness in working-age people worldwide. About 3 to 4 million people with diabetes become blind because of DR every year. Diagnosis of DR through color fundus images is a common approach to mitigate such problem. However, DR diagnosis is a difficult and time consuming task, which requires experienced clinicians to identify the presence and significance of many small features on high resolution images. Convolutional Neural Network (CNN) has proved to be a promising approach for automatic biomedical image analysis recently. In this work, we investigate lesion detection on DR fundus images with CNN-based object detection methods. Lesion detection on fundus images faces two unique challenges. The first one is that our dataset is not fully labeled, i.e., only a subset of all lesion instances are marked. Not only will these unlabeled lesion instances not contribute to the training of the model, but also they will be mistakenly counted as false negatives, leading the model move to the opposite direction. The second challenge is that the lesion instances are usually very small, making them difficult to be found by normal object detectors. To address the first challenge, we introduce an iterative training algorithm for the semi-supervised method of pseudo-labeling, in which a considerable number of unlabeled lesion instances can be discovered to boost the performance of the lesion detector. For the small size targets problem, we extend both the input size and the depth of feature pyramid network (FPN) to produce a large CNN feature map, which can preserve the detail of small lesions and thus enhance the effectiveness of the lesion detector. The experimental results show that our proposed methods significantly outperform the baselines.
Improved Inference via Deep Input Transfer
Apr 15, 2019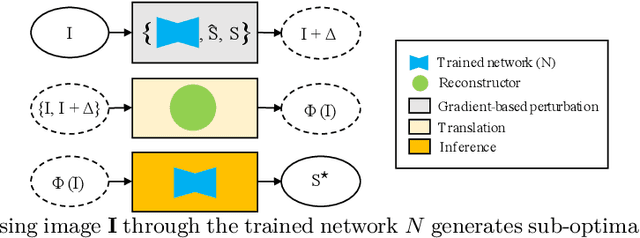
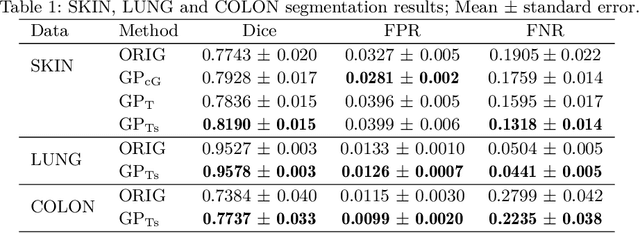
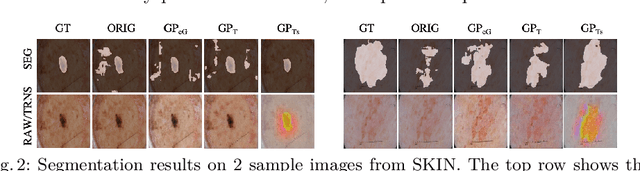
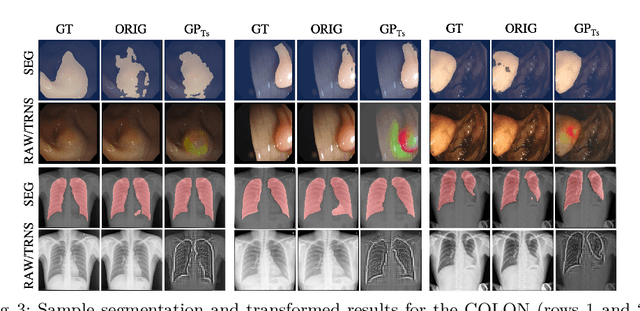
Although numerous improvements have been made in the field of image segmentation using convolutional neural networks, the majority of these improvements rely on training with larger datasets, model architecture modifications, novel loss functions, and better optimizers. In this paper, we propose a new segmentation performance boosting paradigm that relies on optimally modifying the network's input instead of the network itself. In particular, we leverage the gradients of a trained segmentation network with respect to the input to transfer it to a space where the segmentation accuracy improves. We test the proposed method on three publicly available medical image segmentation datasets: the ISIC 2017 Skin Lesion Segmentation dataset, the Shenzhen Chest X-Ray dataset, and the CVC-ColonDB dataset, for which our method achieves improvements of 5.8%, 0.5%, and 4.8% in the average Dice scores, respectively.
Deep Learning System to Screen Coronavirus Disease 2019 Pneumonia
Feb 21, 2020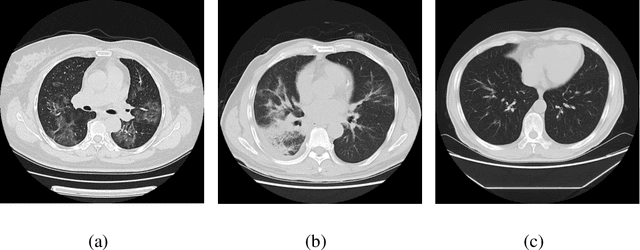
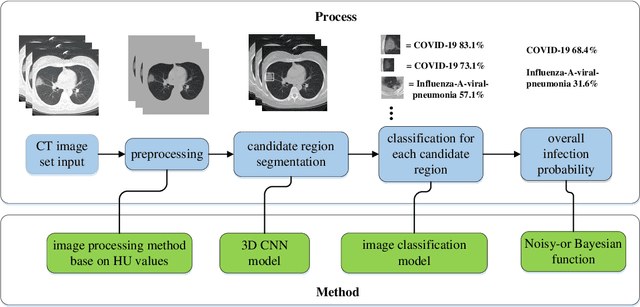

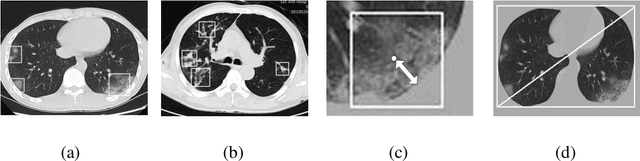
We found that the real time reverse transcription-polymerase chain reaction (RT-PCR) detection of viral RNA from sputum or nasopharyngeal swab has a relatively low positive rate in the early stage to determine COVID-19 (named by the World Health Organization). The manifestations of computed tomography (CT) imaging of COVID-19 had their own characteristics, which are different from other types of viral pneumonia, such as Influenza-A viral pneumonia. Therefore, clinical doctors call for another early diagnostic criteria for this new type of pneumonia as soon as possible.This study aimed to establish an early screening model to distinguish COVID-19 pneumonia from Influenza-A viral pneumonia and healthy cases with pulmonary CT images using deep learning techniques. The candidate infection regions were first segmented out using a 3-dimensional deep learning model from pulmonary CT image set. These separated images were then categorized into COVID-19, Influenza-A viral pneumonia and irrelevant to infection groups, together with the corresponding confidence scores using a location-attention classification model. Finally the infection type and total confidence score of this CT case were calculated with Noisy-or Bayesian function.The experiments result of benchmark dataset showed that the overall accuracy was 86.7 % from the perspective of CT cases as a whole.The deep learning models established in this study were effective for the early screening of COVID-19 patients and demonstrated to be a promising supplementary diagnostic method for frontline clinical doctors.
BDNet: Bengali handwritten numeral digit recognition based on densely connected convolutional neural networks
Jun 11, 2019
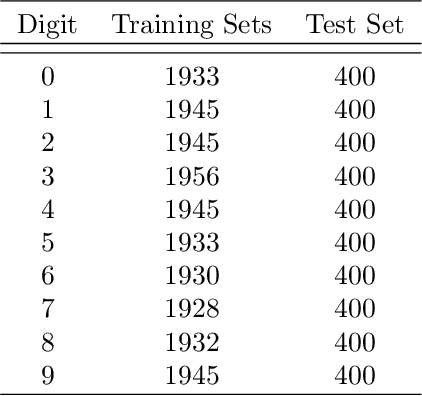
Bengali handwritten digit recognition can be done using different image classification techniques. But the images of handwritten digits are different from natural images as the orientation of a digit as well as similarity of features of different digits are important. On the other hand, deep convolutional neural networks are achieving huge success in computer vision problems, especially in image classification. This BDNet is a densely connected deep convolutional neural network model based on state-of-the-art algorithm DenseNet to classify Bengali handwritten numeral digits. The BDNet has end-to-end trained using ISI Bengali handwritten numeral dataset with 5-fold cross-validation. The BDNet has achieved a test accuracy of 99.65% (baseline was 99.40%) on test data of ISI Bengali handwritten numerals. The trained model also gives 97.50% on own created dataset (which are not used during training). That is, this model gives a 41.66% error reduction compared to the previous state-of-the-art model. Codes, trained model and own dataset available at: https://github.com/Sufianlab/BDNet.
Towards Causal VQA: Revealing and Reducing Spurious Correlations by Invariant and Covariant Semantic Editing
Dec 22, 2019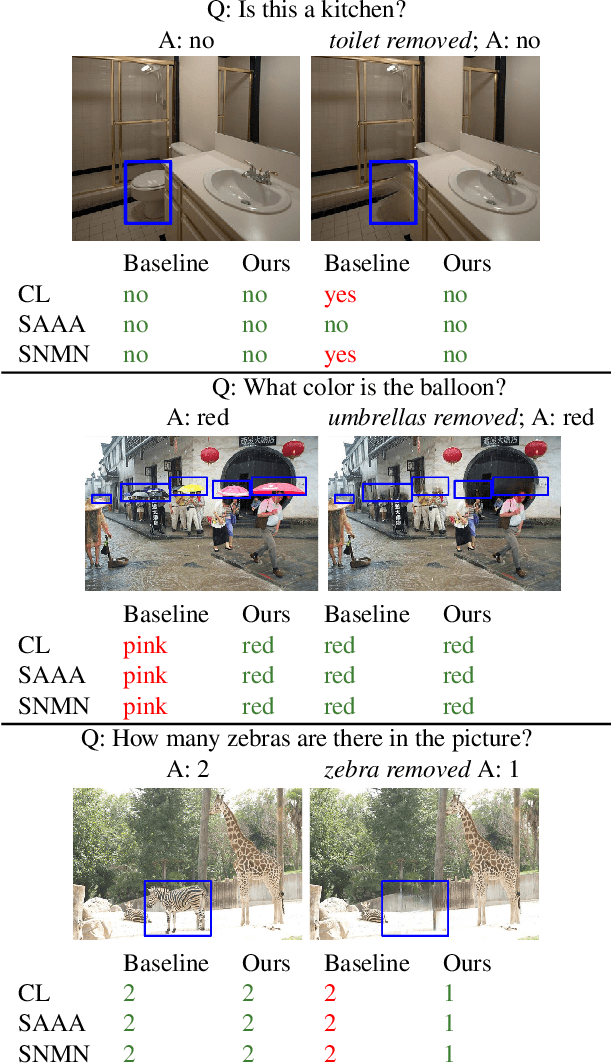

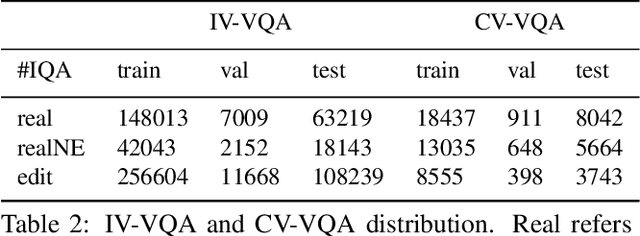

Despite significant success in Visual Question Answering (VQA), VQA models have been shown to be notoriously brittle to linguistic variations in the questions. Due to deficiencies in models and datasets, today's models often rely on correlations rather than predictions that are causal w.r.t. data. In this paper, we propose a novel way to analyze and measure the robustness of the state of the art models w.r.t semantic visual variations as well as propose ways to make models more robust against spurious correlations. Our method performs automated semantic image manipulations and tests for consistency in model predictions to quantify the model robustness as well as generate synthetic data to counter these problems. We perform our analysis on three diverse, state of the art VQA models and diverse question types with a particular focus on challenging counting questions. In addition, we show that models can be made significantly more robust against inconsistent predictions using our edited data. Finally, we show that results also translate to real-world error cases of state of the art models, which results in improved overall performance
Adversarial Learning of Disentangled and Generalizable Representations for Visual Attributes
Apr 09, 2019
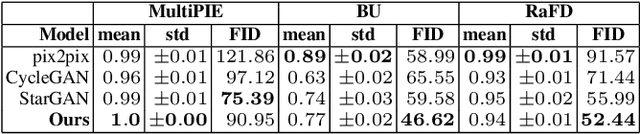
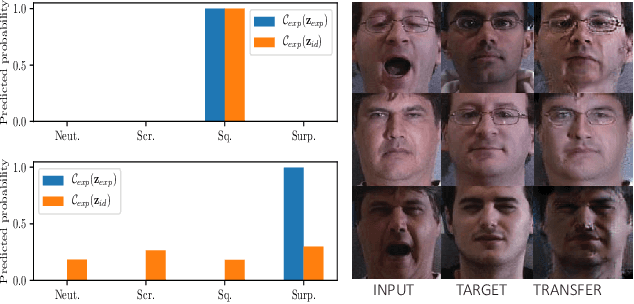
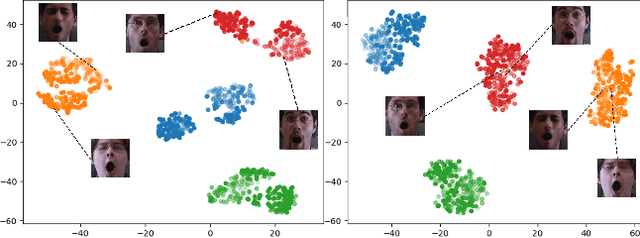
Recently, a multitude of methods for image-to-image translation has demonstrated impressive results on problems such as multi-domain or multi-attribute transfer. The vast majority of such works leverages the strengths of adversarial learning in tandem with deep convolutional autoencoders to achieve realistic results by well-capturing the target data distribution. Nevertheless, the most prominent representatives of this class of methods do not facilitate semantic structure in the latent space, and usually rely on domain labels for test-time transfer. This leads to rigid models that are unable to capture the variance of each domain label. In this light, we propose a novel adversarial learning method that (i) facilitates latent structure by disentangling sources of variation based on a novel cost function and (ii) encourages learning generalizable, continuous and transferable latent codes that can be utilized for tasks such as unpaired multi-domain image transfer and synthesis, without requiring labelled test data. The resulting representations can be combined in arbitrary ways to generate novel hybrid imagery, as for example generating mixtures of identities. We demonstrate the merits of the proposed method by a set of qualitative and quantitative experiments on popular databases, where our method clearly outperforms other, state-of-the-art methods. Code for reproducing our results can be found at: https://github.com/james-oldfield/adv-attribute-disentanglement
Shape Detection of Liver From 2D Ultrasound Images
Nov 23, 2019Applications of ultrasound images have expanded from fetal imaging to abdominal and cardiac diagnosis. Liver-being the largest gland in the body and responsible for metabolic activities requires to be to be diagnosed and therefore subject to utmost injury. Although, ultrasound imaging has developed into three and four dimensions providing higher amount of information; it requires highly trained medical staff due to the image complexity and dimensions it contain. Since 2D ultrasound images are still considered to be the basis of clinical treatments,computer aided automated liver diagnosis is very essential. Due to the limitations of ultrasound images, such as loss of resolution leading to speckle noise, it is difficult to detect shape of organs.In this project, we propose a shape detection method for liver in 2D Ultrasound images. Then we compare the accuracies of the method for both noise and after noise removal.
AI Matrix: A Deep Learning Benchmark for Alibaba Data Centers
Sep 23, 2019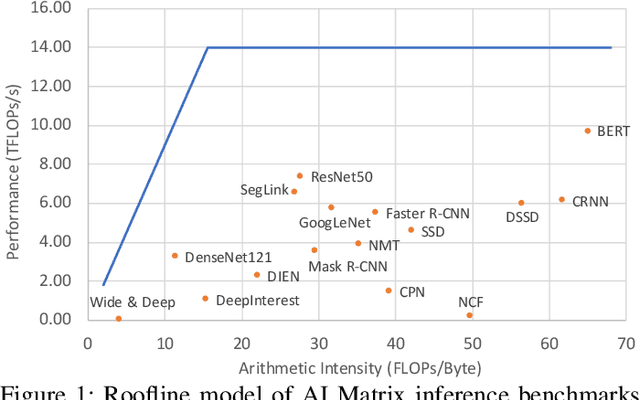
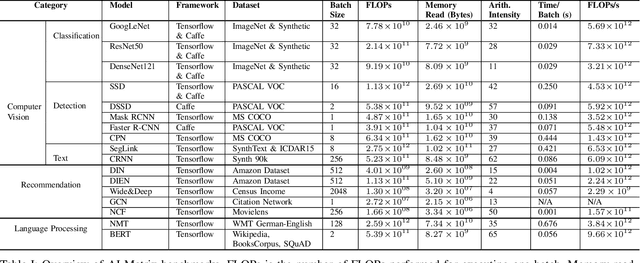
Alibaba has China's largest e-commerce platform. To support its diverse businesses, Alibaba has its own large-scale data centers providing the computing foundation for a wide variety of software applications. Among these applications, deep learning (DL) has been playing an important role in delivering services like image recognition, objection detection, text recognition, recommendation, and language processing. To build more efficient data centers that deliver higher performance for these DL applications, it is important to understand their computational needs and use that information to guide the design of future computing infrastructure. An effective way to achieve this is through benchmarks that can fully represent Alibaba's DL applications.
Uncertainty Measures and Prediction Quality Rating for the Semantic Segmentation of Nested Multi Resolution Street Scene Images
Apr 09, 2019
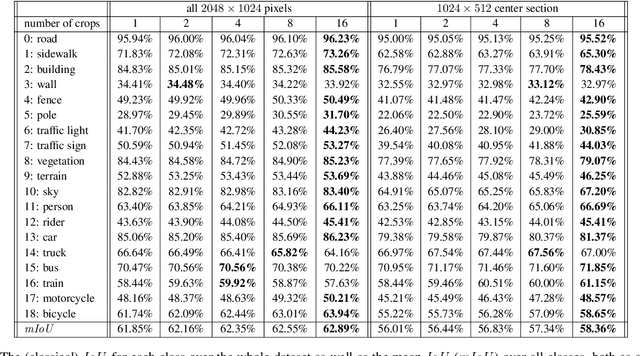


In the semantic segmentation of street scenes the reliability of the prediction and therefore uncertainty measures are of highest interest. We present a method that generates for each input image a hierarchy of nested crops around the image center and presents these, all re-scaled to the same size, to a neural network for semantic segmentation. The resulting softmax outputs are then post processed such that we can investigate mean and variance over all image crops as well as mean and variance of uncertainty heat maps obtained from pixel-wise uncertainty measures, like the entropy, applied to each crop's softmax output. In our tests, we use the publicly available DeepLabv3+ MobilenetV2 network (trained on the Cityscapes dataset) and demonstrate that the incorporation of crops improves the quality of the prediction and that we obtain more reliable uncertainty measures. These are then aggregated over predicted segments for either classifying between IoU=0 and IoU>0 (meta classification) or predicting the IoU via linear regression (meta regression). The latter yields reliable performance estimates for segmentation networks, in particular useful in the absence of ground truth. For the task of meta classification we obtain a classification accuracy of $81.93\%$ and an AUROC of $89.89\%$. For meta regression we obtain an $R^2$ value of $84.77\%$. These results yield significant improvements compared to other approaches.