 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Simultaneous Detection and Removal of Dynamic Objects in Multi-view Images
Dec 11, 2019

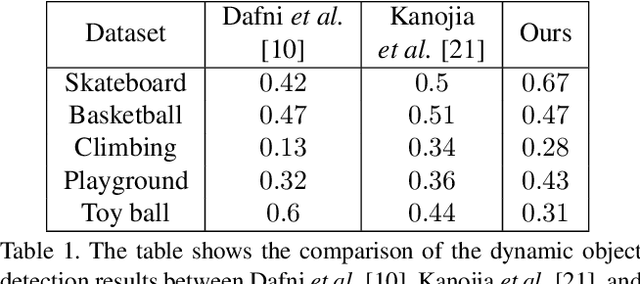


Consider a set of images of a scene consisting of moving objects captured using a hand-held camera. In this work, we propose an algorithm which takes this set of multi-view images as input, detects the dynamic objects present in the scene, and replaces them with the static regions which are being occluded by them. The proposed algorithm scans the reference image in the row-major order at the pixel level and classifies each pixel as static or dynamic. During the scan, when a pixel is classified as dynamic, the proposed algorithm replaces that pixel value with the corresponding pixel value of the static region which is being occluded by that dynamic region. We show that we achieve artifact-free removal of dynamic objects in multi-view images of several real-world scenes. To the best of our knowledge, we propose the first method which simultaneously detects and removes the dynamic objects present in multi-view images.
FCC-GAN: A Fully Connected and Convolutional Net Architecture for GANs
May 07, 2019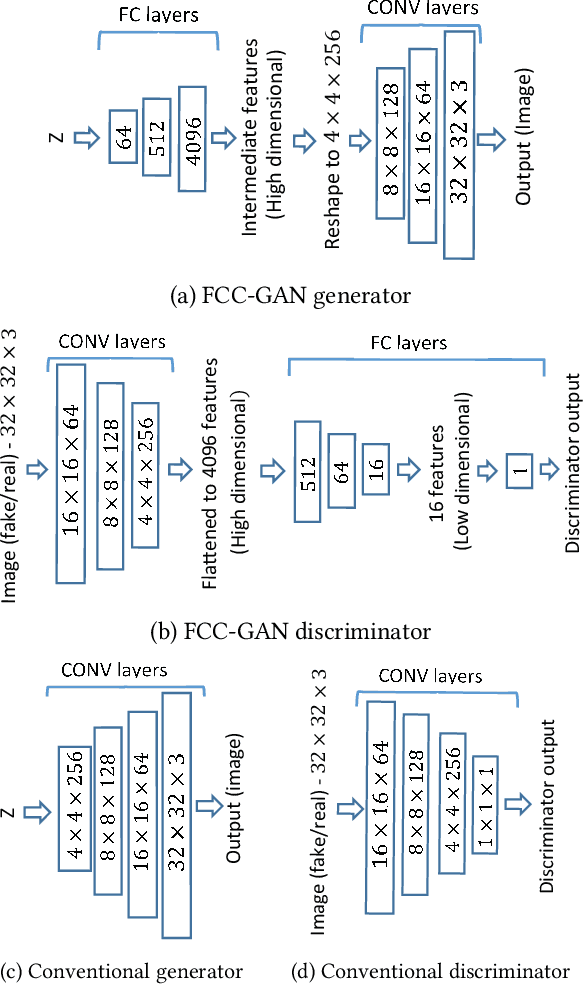
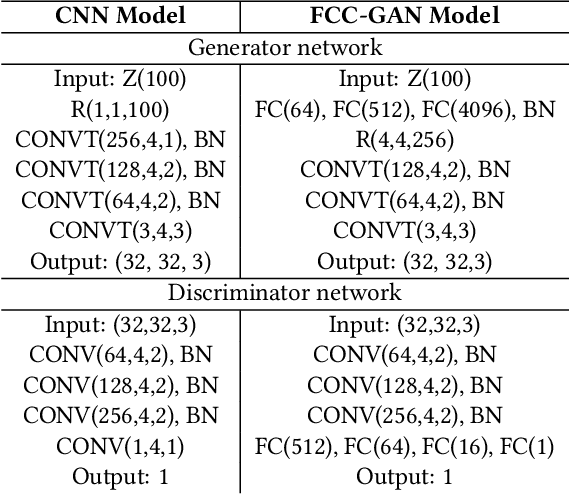
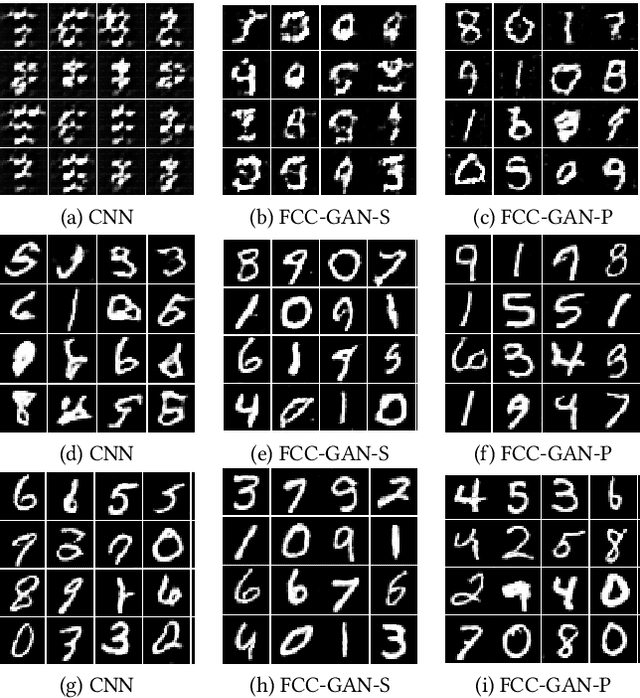
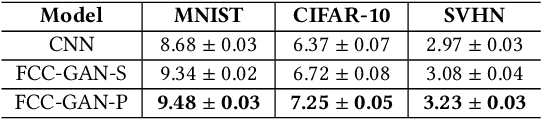
Generative Adversarial Networks (GANs) are a powerful class of generative models. Despite their successes, the most appropriate choice of a GAN network architecture is still not well understood. GAN models for image synthesis have adopted a deep convolutional network architecture, which eliminates or minimizes the use of fully connected and pooling layers in favor of convolution layers in the generator and discriminator of GANs. In this paper, we demonstrate that a convolution network architecture utilizing deep fully connected layers and pooling layers can be more effective than the traditional convolution-only architecture, and we propose FCC-GAN, a fully connected and convolutional GAN architecture. Models based on our FCC-GAN architecture learn both faster than the conventional architecture and also generate higher quality of samples. We demonstrate the effectiveness and stability of our approach across four popular image datasets.
GLU-Net: Global-Local Universal Network for Dense Flow and Correspondences
Dec 11, 2019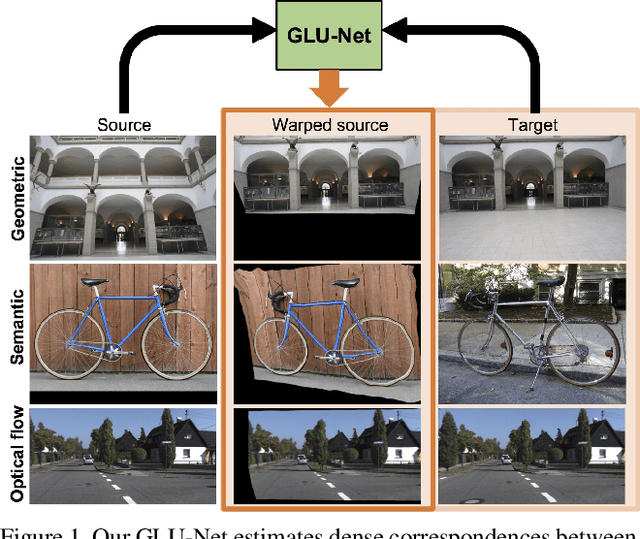
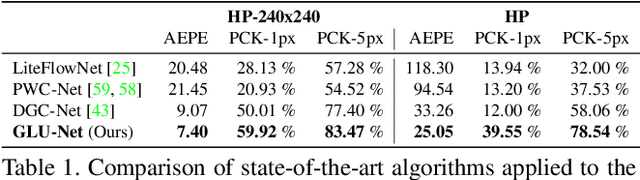
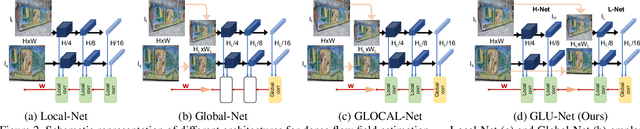
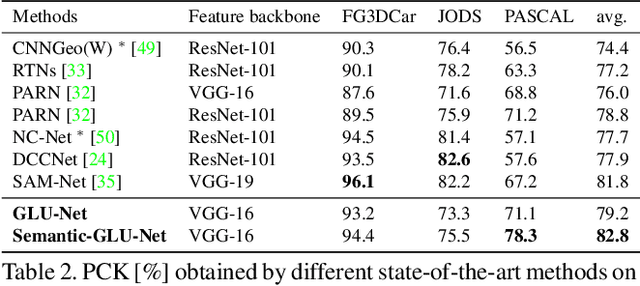
Establishing dense correspondences between a pair of images is an important and general problem, covering geometric matching, optical flow and semantic correspondences. While these applications share fundamental challenges, such as large displacements, pixel-accuracy, and appearance changes, they are currently addressed with specialized network architectures, designed for only one particular task. This severely limits the generalization capabilities of such networks to new scenarios, where e.g. robustness to larger displacements or higher accuracy is required. In this work, we propose a universal network architecture that is directly applicable to all the aforementioned dense correspondence problems. We achieve both high accuracy and robustness to large displacements by investigating the combined use of global and local correlation layers. We further propose an adaptive resolution strategy, allowing our network to operate on virtually any input image resolution. The proposed GLU-Net achieves state-of-the-art performance for geometric and semantic matching as well as optical flow, when using the same network and weights.
Unbiased Scene Graph Generation via Rich and Fair Semantic Extraction
Feb 01, 2020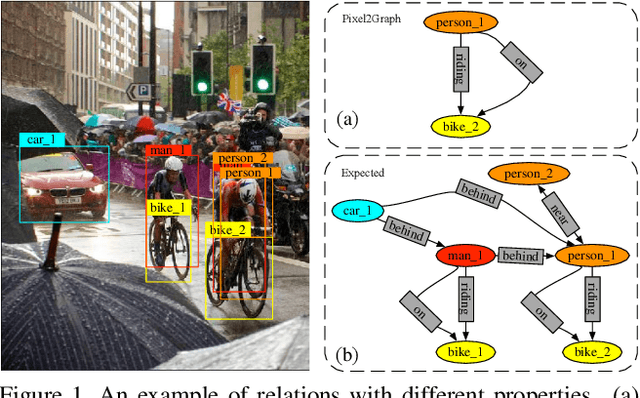
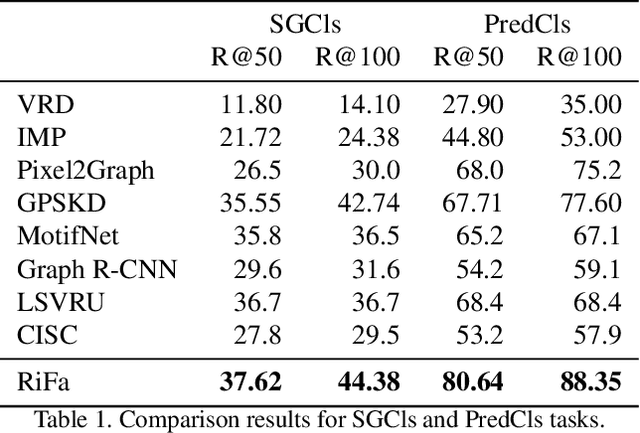
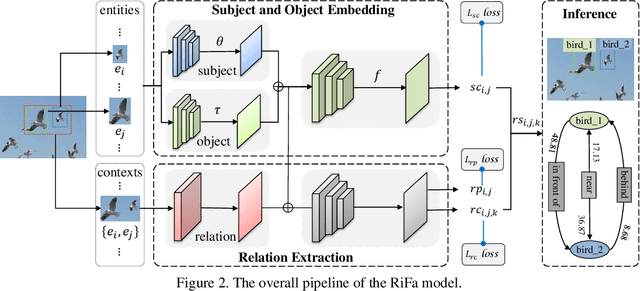
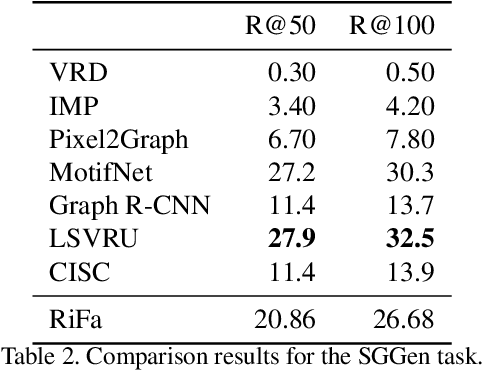
Extracting graph representation of visual scenes in image is a challenging task in computer vision. Although there has been encouraging progress of scene graph generation in the past decade, we surprisingly find that the performance of existing approaches is largely limited by the strong biases, which mainly stem from (1) unconsciously assuming relations with certain semantic properties such as symmetric and (2) imbalanced annotations over different relations. To alleviate the negative effects of these biases, we proposed a new and simple architecture named Rich and Fair semantic extraction network (RiFa for short), to not only capture rich semantic properties of the relations, but also fairly predict relations with different scale of annotations. Using pseudo-siamese networks, RiFa embeds the subject and object respectively to distinguish their semantic differences and meanwhile preserve their underlying semantic properties. Then, it further predicts subject-object relations based on both the visual and semantic features of entities under certain contextual area, and fairly ranks the relation predictions for those with a few annotations. Experiments on the popular Visual Genome dataset show that RiFa achieves state-of-the-art performance under several challenging settings of scene graph task. Especially, it performs significantly better on capturing different semantic properties of relations, and obtains the best overall per relation performance.
U-Net with spatial pyramid pooling for drusen segmentation in optical coherence tomography
Dec 11, 2019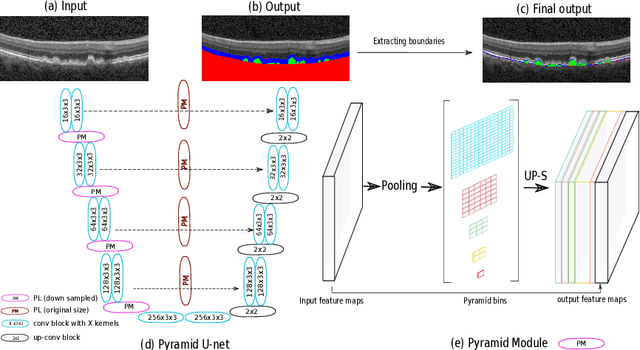

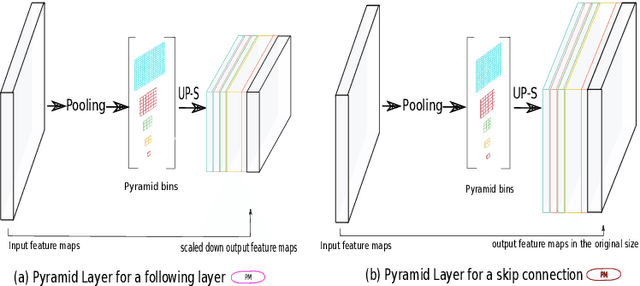
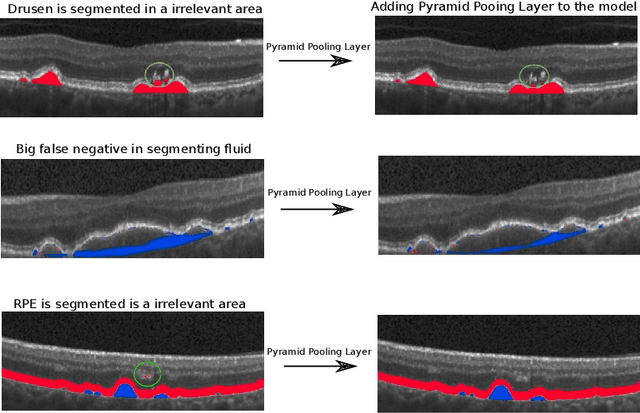
The presence of drusen is the main hallmark of early/intermediate age-related macular degeneration (AMD). Therefore, automated drusen segmentation is an important step in image-guided management of AMD. There are two common approaches to drusen segmentation. In the first, the drusen are segmented directly as a binary classification task. In the second approach, the surrounding retinal layers (outer boundary retinal pigment epithelium (OBRPE) and Bruch's membrane (BM)) are segmented and the remaining space between these two layers is extracted as drusen. In this work, we extend the standard U-Net architecture with spatial pyramid pooling components to introduce global feature context. We apply the model to the task of segmenting drusen together with BM and OBRPE. The proposed network was trained and evaluated on a longitudinal OCT dataset of 425 scans from 38 patients with early/intermediate AMD. This preliminary study showed that the proposed network consistently outperformed the standard U-net model.
SG-One: Similarity Guidance Network for One-Shot Semantic Segmentation
Oct 26, 2018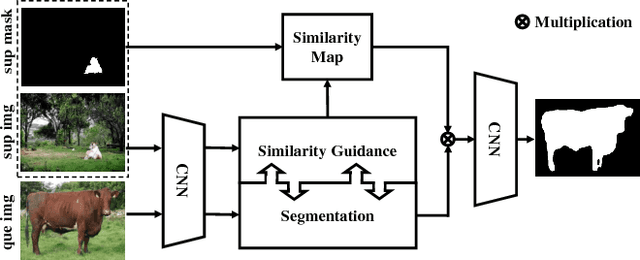

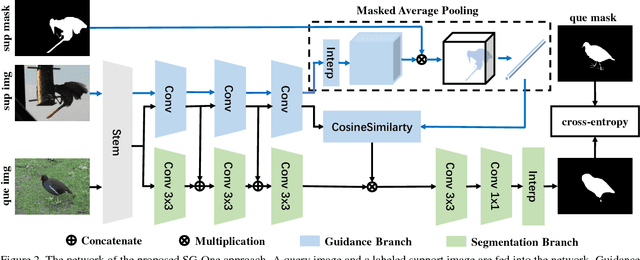
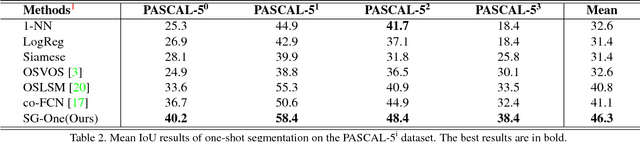
One-shot semantic segmentation poses a challenging task of recognizing the object regions from unseen categories with only one annotated example as supervision. In this paper, we propose a simple yet effective Similarity Guidance network to tackle the One-shot (SG-One) segmentation problem. We aim at predicting the segmentation mask of a query image with the reference to one densely labeled support image. To obtain the robust representative feature of the support image, we firstly propose a masked average pooling strategy for producing the guidance features using only the pixels belonging to the support image. We then leverage the cosine similarity to build the relationship between the guidance features and features of pixels from the query image. In this way, the possibilities embedded in the produced similarity maps can be adopted to guide the process of segmenting objects. Furthermore, our SG-One is a unified framework which can efficiently process both support and query images within one network and be learned in an end-to-end manner. We conduct extensive experiments on Pascal VOC 2012. In particular, our SG-One achieves the mIoU score of 46.3%, which outperforms the state-of-the-art.
Bayesian Grasp: Robotic visual stable grasp based on prior tactile knowledge
May 30, 2019

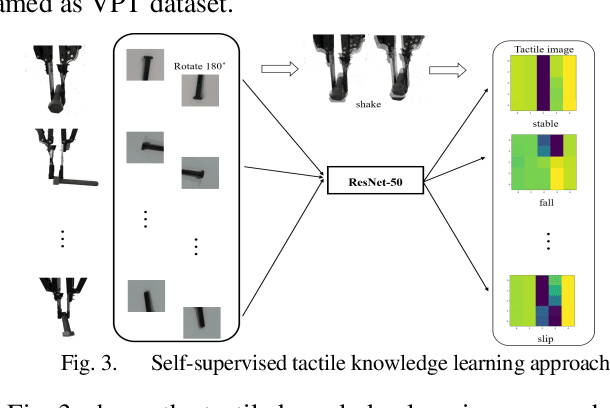
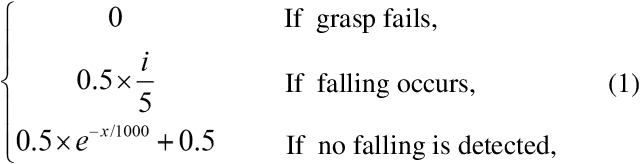
Robotic grasp detection is a fundamental capability for intelligent manipulation in unstructured environments. Previous work mainly employed visual and tactile fusion to achieve stable grasp, while, the whole process depending heavily on regrasping, which wastes much time to regulate and evaluate. We propose a novel way to improve robotic grasping: by using learned tactile knowledge, a robot can achieve a stable grasp from an image. First, we construct a prior tactile knowledge learning framework with novel grasp quality metric which is determined by measuring its resistance to external perturbations. Second, we propose a multi-phases Bayesian Grasp architecture to generate stable grasp configurations through a single RGB image based on prior tactile knowledge. Results show that this framework can classify the outcome of grasps with an average accuracy of 86% on known objects and 79% on novel objects. The prior tactile knowledge improves the successful rate of 55% over traditional vision-based strategies.
Representing Images in 200 Bytes: Compression via Triangulation
Sep 20, 2018

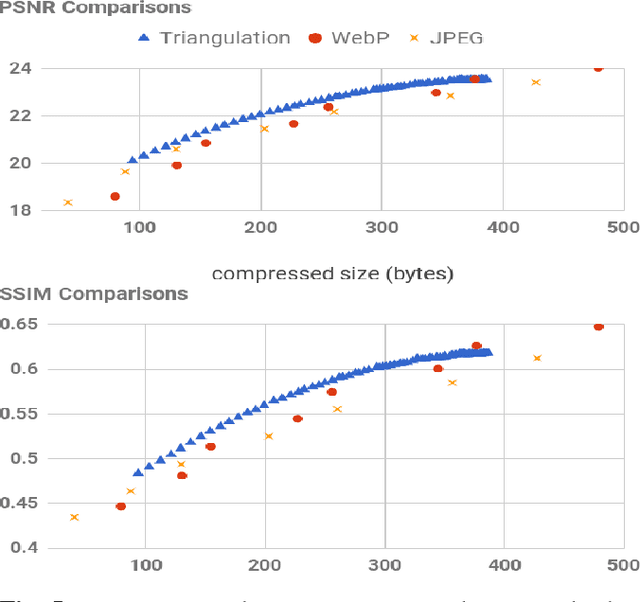
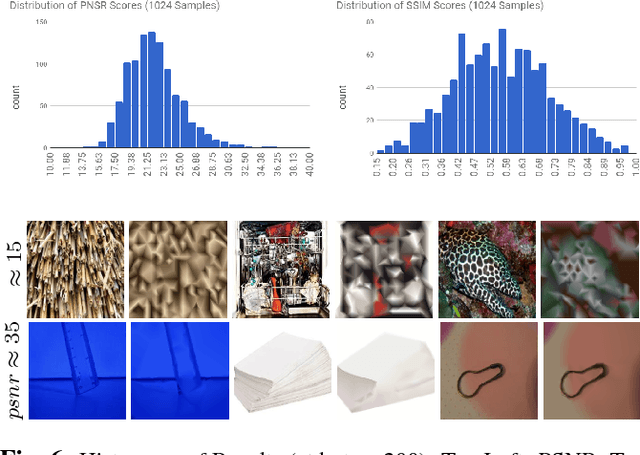
A rapidly increasing portion of internet traffic is dominated by requests from mobile devices with limited and metered bandwidth constraints. To satisfy these requests, it has become standard practice for websites to transmit small and extremely compressed image previews as part of the initial page load process to improve responsiveness. Increasing thumbnail compression beyond the capabilities of existing codecs is therefore an active research direction. In this work, we concentrate on extreme compression rates, where the size of the image is typically 200 bytes or less. First, we propose a novel approach for image compression that, unlike commonly used methods, does not rely on block-based statistics. We use an approach based on an adaptive triangulation of the target image, devoting more triangles to high entropy regions of the image. Second, we present a novel algorithm for encoding the triangles. The results show favorable statistics, in terms of PSNR and SSIM, over both the JPEG and the WebP standards.
Detection of Coronavirus (COVID-19) Associated Pneumonia based on Generative Adversarial Networks and a Fine-Tuned Deep Transfer Learning Model using Chest X-ray Dataset
Apr 02, 2020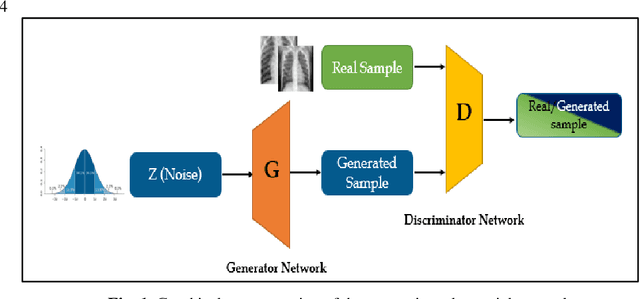
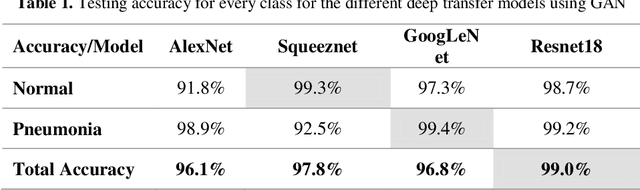
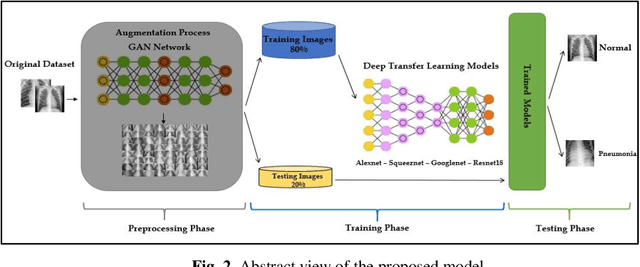
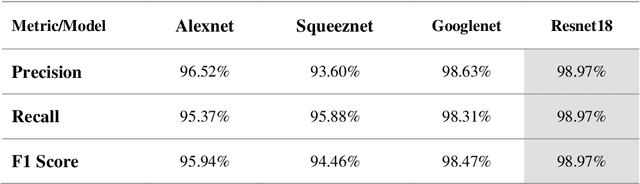
The COVID-19 coronavirus is one of the devastating viruses according to the world health organization. This novel virus leads to pneumonia, which is an infection that inflames the lungs' air sacs of a human. One of the methods to detect those inflames is by using x-rays for the chest. In this paper, a pneumonia chest x-ray detection based on generative adversarial networks (GAN) with a fine-tuned deep transfer learning for a limited dataset will be presented. The use of GAN positively affects the proposed model robustness and made it immune to the overfitting problem and helps in generating more images from the dataset. The dataset used in this research consists of 5863 X-ray images with two categories: Normal and Pneumonia. This research uses only 10% of the dataset for training data and generates 90% of images using GAN to prove the efficiency of the proposed model. Through the paper, AlexNet, GoogLeNet, Squeeznet, and Resnet18 are selected as deep transfer learning models to detect the pneumonia from chest x-rays. Those models are selected based on their small number of layers on their architectures, which will reflect in reducing the complexity of the models and the consumed memory and time. Using a combination of GAN and deep transfer models proved it is efficiency according to testing accuracy measurement. The research concludes that the Resnet18 is the most appropriate deep transfer model according to testing accuracy measurement and achieved 99% with the other performance metrics such as precision, recall, and F1 score while using GAN as an image augmenter. Finally, a comparison result was carried out at the end of the research with related work which used the same dataset except that this research used only 10% of original dataset. The presented work achieved a superior result than the related work in terms of testing accuracy.
An Open-set Recognition and Few-Shot Learning Dataset for Audio Event Classification in Domestic Environments
Feb 28, 2020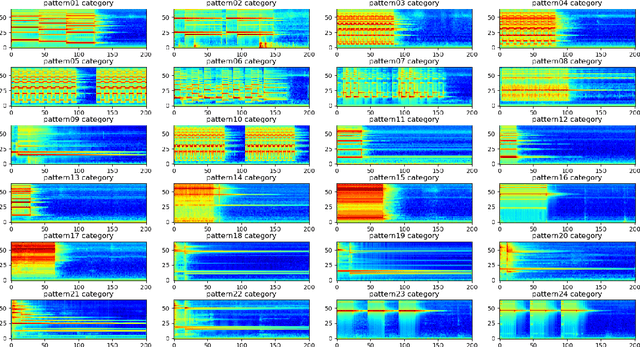
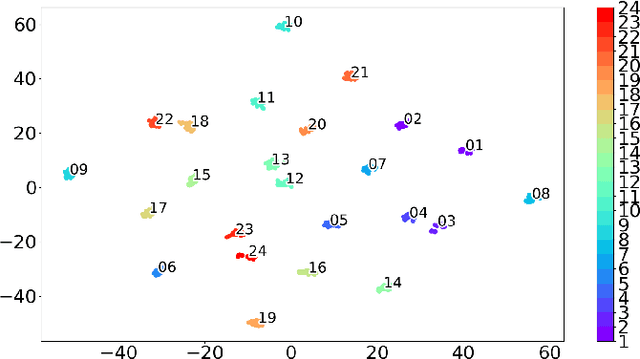

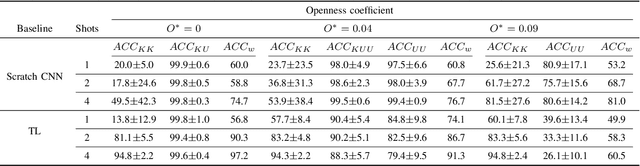
The problem of training a deep neural network with a small set of positive samples is known as few-shot learning (FSL). It is widely known that traditional deep learning (DL) algorithms usually show very good performance when trained with large datasets. However, in many applications, it is not possible to obtain such a high number of samples. In the image domain, typical FSL applications are those related to face recognition. In the audio domain, music fraud or speaker recognition can be clearly benefited from FSL methods. This paper deals with the application of FSL to the detection of specific and intentional acoustic events given by different types of sound alarms, such as door bells or fire alarms, using a limited number of samples. These sounds typically occur in domestic environments where many events corresponding to a wide variety of sound classes take place. Therefore, the detection of such alarms in a practical scenario can be considered an open-set recognition (OSR) problem. To address the lack of a dedicated public dataset for audio FSL, researchers usually make modifications on other available datasets. This paper is aimed at providing the audio recognition community with a carefully annotated dataset for FSL and OSR comprised of 1360 clips from 34 classes divided into pattern sounds and unwanted sounds. To facilitate and promote research in this area, results with two baseline systems (one trained from scratch and another based on transfer learning), are presented.