 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComprehensive Evaluation of CNN-Based Audio Tagging Models on Resource-Constrained Devices
Sep 19, 2025Convolutional Neural Networks (CNNs) have demonstrated exceptional performance in audio tagging tasks. However, deploying these models on resource-constrained devices like the Raspberry Pi poses challenges related to computational efficiency and thermal management. In this paper, a comprehensive evaluation of multiple convolutional neural network (CNN) architectures for audio tagging on the Raspberry Pi is conducted, encompassing all 1D and 2D models from the Pretrained Audio Neural Networks (PANNs) framework, a ConvNeXt-based model adapted for audio classification, as well as MobileNetV3 architectures. In addition, two PANNs-derived networks, CNN9 and CNN13, recently proposed, are also evaluated. To enhance deployment efficiency and portability across diverse hardware platforms, all models are converted to the Open Neural Network Exchange (ONNX) format. Unlike previous works that focus on a single model, our analysis encompasses a broader range of architectures and involves continuous 24-hour inference sessions to assess performance stability. Our experiments reveal that, with appropriate model selection and optimization, it is possible to maintain consistent inference latency and manage thermal behavior effectively over extended periods. These findings provide valuable insights for deploying audio tagging models in real-world edge computing scenarios.
Threat Modeling for Enhancing Security of IoT Audio Classification Devices under a Secure Protocols Framework
Sep 19, 2025The rapid proliferation of IoT nodes equipped with microphones and capable of performing on-device audio classification exposes highly sensitive data while operating under tight resource constraints. To protect against this, we present a defence-in-depth architecture comprising a security protocol that treats the edge device, cellular network and cloud backend as three separate trust domains, linked by TPM-based remote attestation and mutually authenticated TLS 1.3. A STRIDE-driven threat model and attack-tree analysis guide the design. At startup, each boot stage is measured into TPM PCRs. The node can only decrypt its LUKS-sealed partitions after the cloud has verified a TPM quote and released a one-time unlock key. This ensures that rogue or tampered devices remain inert. Data in transit is protected by TLS 1.3 and hybridised with Kyber and Dilithium to provide post-quantum resilience. Meanwhile, end-to-end encryption and integrity hashes safeguard extracted audio features. Signed, rollback-protected AI models and tamper-responsive sensors harden firmware and hardware. Data at rest follows a 3-2-1 strategy comprising a solid-state drive sealed with LUKS, an offline cold archive encrypted with a hybrid post-quantum cipher and an encrypted cloud replica. Finally, we set out a plan for evaluating the physical and logical security of the proposed protocol.
Comparative Study of Spike Encoding Methods for Environmental Sound Classification
Mar 14, 2025Spiking Neural Networks (SNNs) offer a promising approach to reduce energy consumption and computational demands, making them particularly beneficial for embedded machine learning in edge applications. However, data from conventional digital sensors must first be converted into spike trains to be processed using neuromorphic computing technologies. The classification of environmental sounds presents unique challenges due to the high variability of frequencies, background noise, and overlapping acoustic events. Despite these challenges, most studies on spike-based audio encoding focus on speech processing, leaving non-speech environmental sounds underexplored. In this work, we conduct a comprehensive comparison of widely used spike encoding techniques, evaluating their effectiveness on the ESC-10 dataset. By understanding the impact of encoding choices on environmental sound processing, researchers and practitioners can select the most suitable approach for real-world applications such as smart surveillance, environmental monitoring, and industrial acoustic analysis. This study serves as a benchmark for spike encoding in environmental sound classification, providing a foundational reference for future research in neuromorphic audio processing.
Automatic Counting and Classification of Mosquito Eggs in Field Traps
May 31, 2024



The analysis of the field traps where the mosquitoes insert their eggs is vital to check that the sterile insect technique (SIT) is working properly. This is because the number of hatched eggs may indicate that the sterile males are not competing with the wild ones. Nowadays, the study of the traps is done manually by microscope and is very time-consuming and prone to human error. This paper presents an automatic trap survey. For this purpose, a device has been designed that automatically scans the slat obtaining different overlapping photos. Subsequently, the images are analyzed by a Mask-RCNN neural network that segments the eggs and classifies them into 2 classes: full or hatch
Practical aspects for the creation of an audio dataset from field recordings with optimized labeling budget with AI-assisted strategy
May 28, 2024Machine Listening focuses on developing technologies to extract relevant information from audio signals. A critical aspect of these projects is the acquisition and labeling of contextualized data, which is inherently complex and requires specific resources and strategies. Despite the availability of some audio datasets, many are unsuitable for commercial applications. The paper emphasizes the importance of Active Learning (AL) using expert labelers over crowdsourcing, which often lacks detailed insights into dataset structures. AL is an iterative process combining human labelers and AI models to optimize the labeling budget by intelligently selecting samples for human review. This approach addresses the challenge of handling large, constantly growing datasets that exceed available computational resources and memory. The paper presents a comprehensive data-centric framework for Machine Listening projects, detailing the configuration of recording nodes, database structure, and labeling budget optimization in resource-constrained scenarios. Applied to an industrial port in Valencia, Spain, the framework successfully labeled 6540 ten-second audio samples over five months with a small team, demonstrating its effectiveness and adaptability to various resource availability situations.
Female mosquito detection by means of AI techniques inside release containers in the context of a Sterile Insect Technique program
Jun 19, 2023



The Sterile Insect Technique (SIT) is a biological pest control technique based on the release into the environment of sterile males of the insect species whose population is to be controlled. The entire SIT process involves mass-rearing within a biofactory, sorting of the specimens by sex, sterilization, and subsequent release of the sterile males into the environment. The reason for avoiding the release of female specimens is because, unlike males, females bite, with the subsequent risk of disease transmission. In the case of Aedes mosquito biofactories for SIT, the key point of the whole process is sex separation. This process is nowadays performed by a combination of mechanical devices and AI-based vision systems. However, there is still a possibility of false negatives, so a last stage of verification is necessary before releasing them into the environment. It is known that the sound produced by the flapping of adult male mosquitoes is different from that produced by females, so this feature can be used to detect the presence of females in containers prior to environmental release. This paper presents a study for the detection of females in Aedes mosquito release vessels for SIT programs. The containers used consist of PVC a tubular design of 8.8cm diameter and 12.5cm height. The containers were placed in an experimental setup that allowed the recording of the sound of mosquito flight inside of them. Each container was filled with 250 specimens considering the cases of (i) only male mosquitoes, (ii) only female mosquitoes, and (iii) 75% males and 25% females. Case (i) was used for training and testing, whereas cases (ii) and (iii) were used only for testing. Two algorithms were implemented for the detection of female mosquitoes: an unsupervised outlier detection algorithm (iForest) and a one-class SVM trained with male-only recordings.
DCASE 2022: Comparative Analysis Of CNNs For Acoustic Scene Classification Under Low-Complexity Considerations
Jun 16, 2022

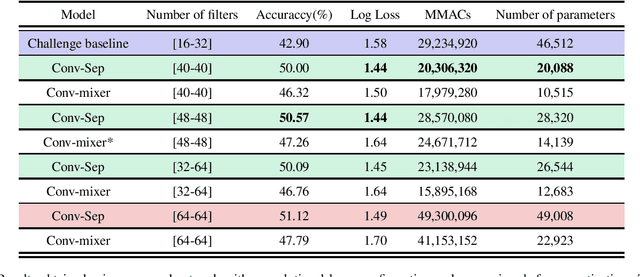
Acoustic scene classification is an automatic listening problem that aims to assign an audio recording to a pre-defined scene based on its audio data. Over the years (and in past editions of the DCASE) this problem has often been solved with techniques known as ensembles (use of several machine learning models to combine their predictions in the inference phase). While these solutions can show performance in terms of accuracy, they can be very expensive in terms of computational capacity, making it impossible to deploy them in IoT devices. Due to the drift in this field of study, this task has two limitations in terms of model complexity. It should be noted that there is also the added complexity of mismatching devices (the audios provided are recorded by different sources of information). This technical report makes a comparative study of two different network architectures: conventional CNN and Conv-mixer. Although both networks exceed the baseline required by the competition, the conventional CNN shows a higher performance, exceeding the baseline by 8 percentage points. Solutions based on Conv-mixer architectures show worse performance although they are much lighter solutions.
Task 1A DCASE 2021: Acoustic Scene Classification with mismatch-devices using squeeze-excitation technique and low-complexity constraint
Jul 30, 2021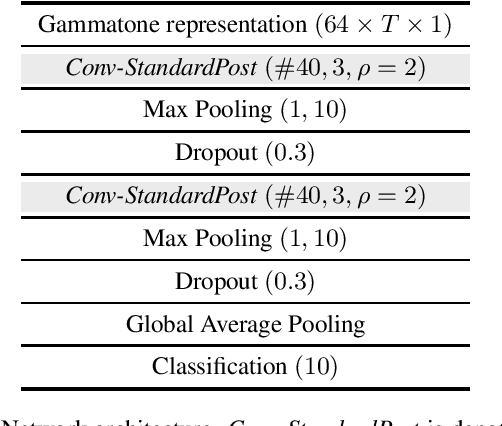

Acoustic scene classification (ASC) is one of the most popular problems in the field of machine listening. The objective of this problem is to classify an audio clip into one of the predefined scenes using only the audio data. This problem has considerably progressed over the years in the different editions of DCASE. It usually has several subtasks that allow to tackle this problem with different approaches. The subtask presented in this report corresponds to a ASC problem that is constrained by the complexity of the model as well as having audio recorded from different devices, known as mismatch devices (real and simulated). The work presented in this report follows the research line carried out by the team in previous years. Specifically, a system based on two steps is proposed: a two-dimensional representation of the audio using the Gamamtone filter bank and a convolutional neural network using squeeze-excitation techniques. The presented system outperforms the baseline by about 17 percentage points.
TASK3 DCASE2021 Challenge: Sound event localization and detection using squeeze-excitation residual CNNs
Jul 30, 2021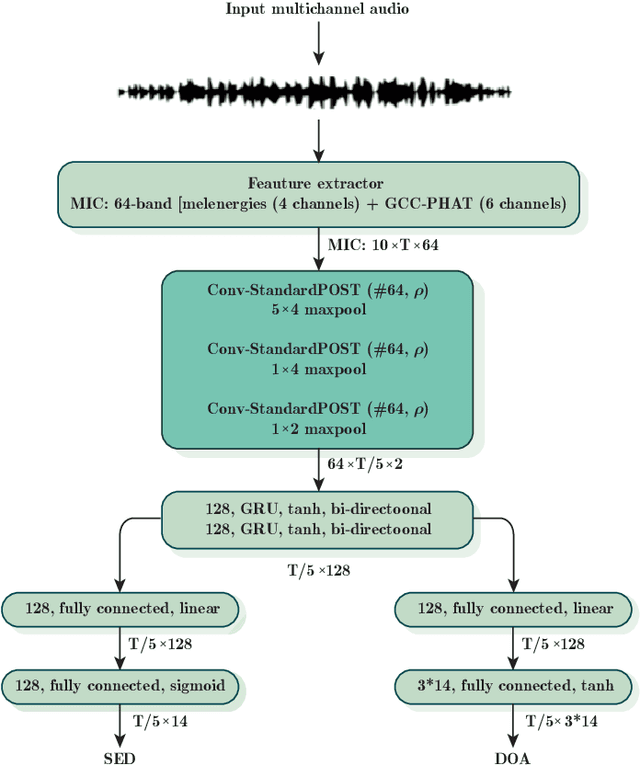
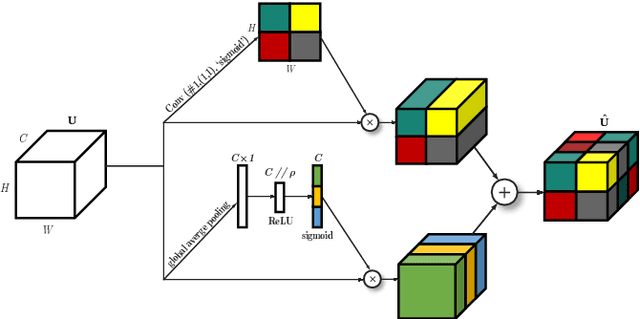
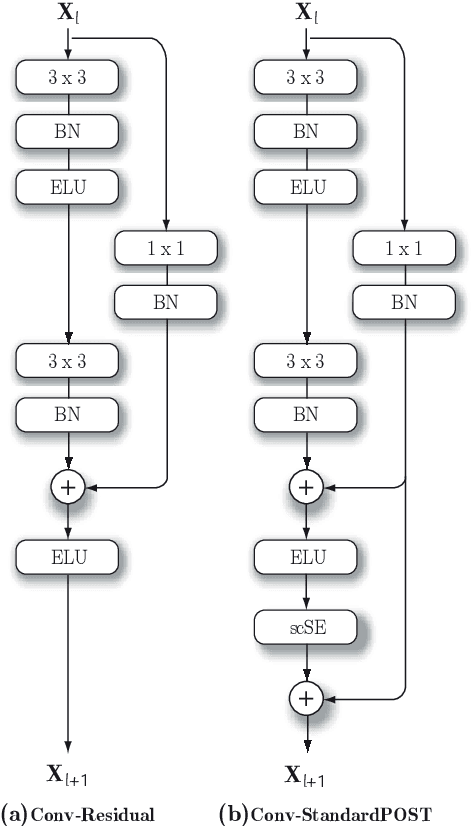

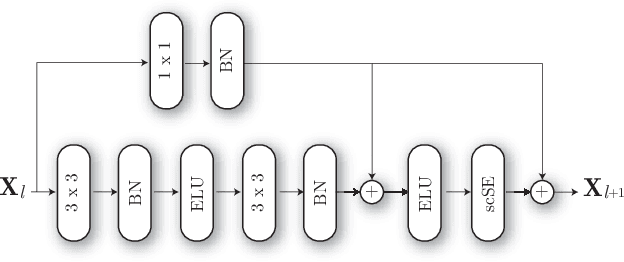
Sound event localisation and detection (SELD) is a problem in the field of automatic listening that aims at the temporal detection and localisation (direction of arrival estimation) of sound events within an audio clip, usually of long duration. Due to the amount of data present in the datasets related to this problem, solutions based on deep learning have positioned themselves at the top of the state of the art. Most solutions are based on 2D representations of the audio (different spectrograms) that are processed by a convolutional-recurrent network. The motivation of this submission is to study the squeeze-excitation technique in the convolutional part of the network and how it improves the performance of the system. This study is based on the one carried out by the same team last year. This year, it has been decided to study how this technique improves each of the datasets (last year only the MIC dataset was studied). This modification shows an improvement in the performance of the system compared to the baseline using MIC dataset.
Squeeze-Excitation Convolutional Recurrent Neural Networks for Audio-Visual Scene Classification
Jul 28, 2021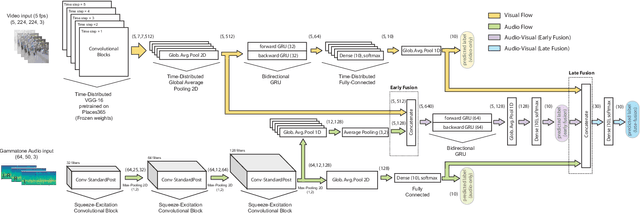


The use of multiple and semantically correlated sources can provide complementary information to each other that may not be evident when working with individual modalities on their own. In this context, multi-modal models can help producing more accurate and robust predictions in machine learning tasks where audio-visual data is available. This paper presents a multi-modal model for automatic scene classification that exploits simultaneously auditory and visual information. The proposed approach makes use of two separate networks which are respectively trained in isolation on audio and visual data, so that each network specializes in a given modality. The visual subnetwork is a pre-trained VGG16 model followed by a bidiretional recurrent layer, while the residual audio subnetwork is based on stacked squeeze-excitation convolutional blocks trained from scratch. After training each subnetwork, the fusion of information from the audio and visual streams is performed at two different stages. The early fusion stage combines features resulting from the last convolutional block of the respective subnetworks at different time steps to feed a bidirectional recurrent structure. The late fusion stage combines the output of the early fusion stage with the independent predictions provided by the two subnetworks, resulting in the final prediction. We evaluate the method using the recently published TAU Audio-Visual Urban Scenes 2021, which contains synchronized audio and video recordings from 12 European cities in 10 different scene classes. The proposed model has been shown to provide an excellent trade-off between prediction performance (86.5%) and system complexity (15M parameters) in the evaluation results of the DCASE 2021 Challenge.