 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Sampling-Free Learning of Bayesian Quantized Neural Networks
Dec 06, 2019

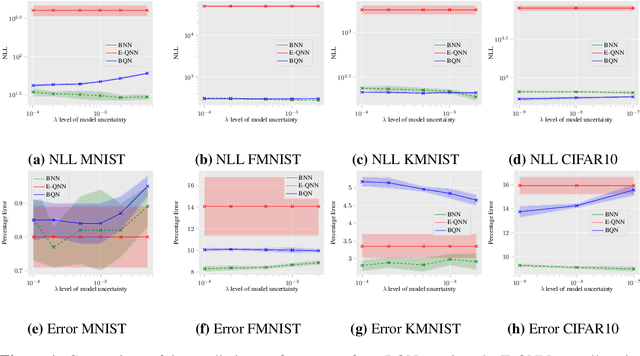
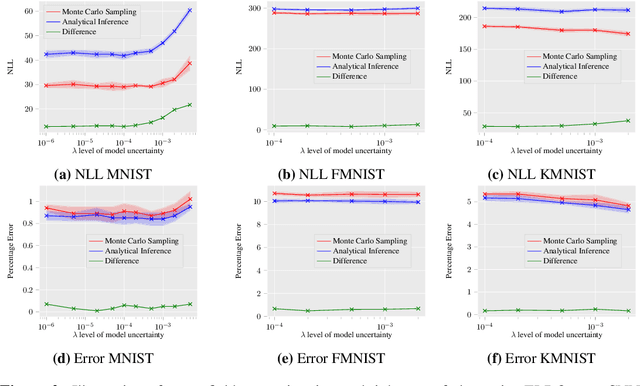

Bayesian learning of model parameters in neural networks is important in scenarios where estimates with well-calibrated uncertainty are important. In this paper, we propose Bayesian quantized networks (BQNs), quantized neural networks (QNNs) for which we learn a posterior distribution over their discrete parameters. We provide a set of efficient algorithms for learning and prediction in BQNs without the need to sample from their parameters or activations, which not only allows for differentiable learning in QNNs, but also reduces the variance in gradients. We evaluate BQNs on MNIST, Fashion-MNIST, KMNIST and CIFAR10 image classification datasets, compared against bootstrap ensemble of QNNs (E-QNN). We demonstrate BQNs achieve both lower predictive errors and better-calibrated uncertainties than E-QNN (with less than 20% of the negative log-likelihood).
Unsupervised Cross-spectral Stereo Matching by Learning to Synthesize
Mar 04, 2019



Unsupervised cross-spectral stereo matching aims at recovering disparity given cross-spectral image pairs without any supervision in the form of ground truth disparity or depth. The estimated depth provides additional information complementary to individual semantic features, which can be helpful for other vision tasks such as tracking, recognition and detection. However, there are large appearance variations between images from different spectral bands, which is a challenge for cross-spectral stereo matching. Existing deep unsupervised stereo matching methods are sensitive to the appearance variations and do not perform well on cross-spectral data. We propose a novel unsupervised cross-spectral stereo matching framework based on image-to-image translation. First, a style adaptation network transforms images across different spectral bands by cycle consistency and adversarial learning, during which appearance variations are minimized. Then, a stereo matching network is trained with image pairs from the same spectra using view reconstruction loss. At last, the estimated disparity is utilized to supervise the spectral-translation network in an end-to-end way. Moreover, a novel style adaptation network F-cycleGAN is proposed to improve the robustness of spectral translation. Our method can tackle appearance variations and enhance the robustness of unsupervised cross-spectral stereo matching. Experimental results show that our method achieves good performance without using depth supervision or explicit semantic information.
Embedding of FRPN in CNN architecture
Dec 27, 2019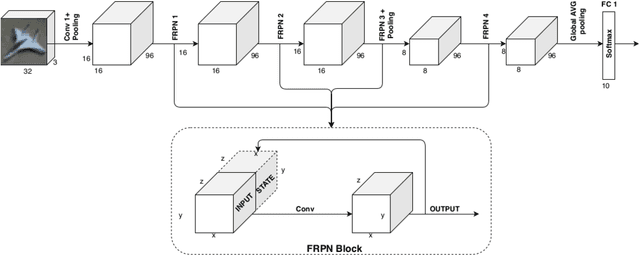
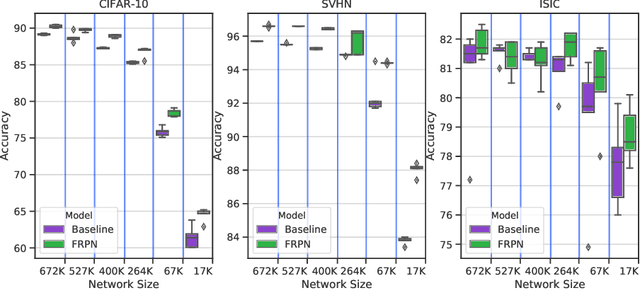
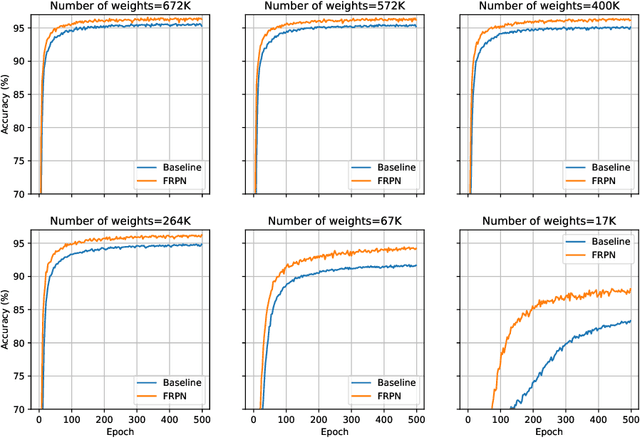
This paper extends the fully recursive perceptron network (FRPN) model for vectorial inputs to include deep convolutional neural networks (CNNs) which can accept multi-dimensional inputs. A FRPN consists of a recursive layer, which, given a fixed input, iteratively computes an equilibrium state. The unfolding realized with this kind of iterative mechanism allows to simulate a deep neural network with any number of layers. The extension of the FRPN to CNN results in an architecture, which we call convolutional-FRPN (C-FRPN), where the convolutional layers are recursive. The method is evaluated on several image classification benchmarks. It is shown that the C-FRPN consistently outperforms standard CNNs having the same number of parameters. The gap in performance is particularly large for small networks, showing that the C-FRPN is a very powerful architecture, since it allows to obtain equivalent performance with fewer parameters when compared with deep CNNs.
Data Consistent Artifact Reduction for Limited Angle Tomography with Deep Learning Prior
Aug 28, 2019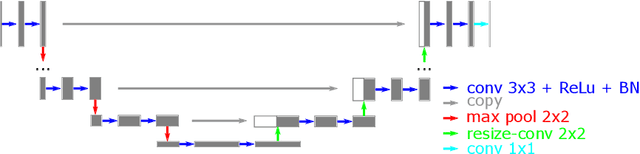
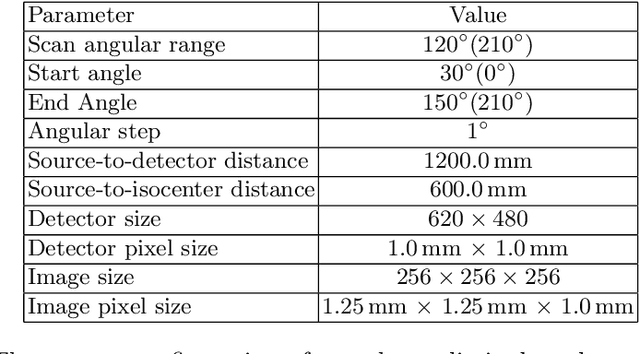
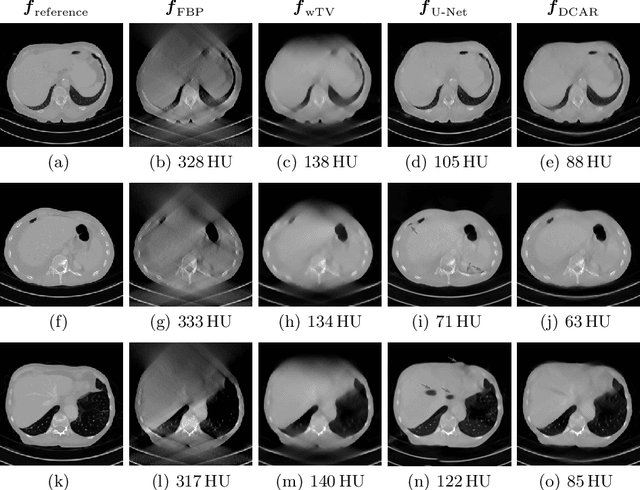
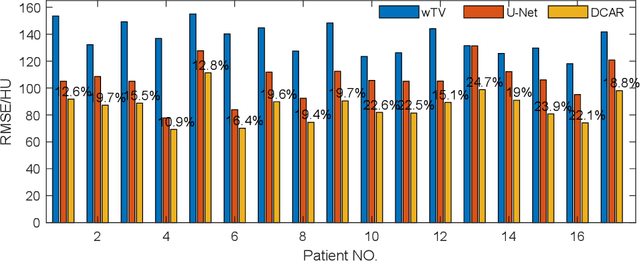
Robustness of deep learning methods for limited angle tomography is challenged by two major factors: a) due to insufficient training data the network may not generalize well to unseen data; b) deep learning methods are sensitive to noise. Thus, generating reconstructed images directly from a neural network appears inadequate. We propose to constrain the reconstructed images to be consistent with the measured projection data, while the unmeasured information is complemented by learning based methods. For this purpose, a data consistent artifact reduction (DCAR) method is introduced: First, a prior image is generated from an initial limited angle reconstruction via deep learning as a substitute for missing information. Afterwards, a conventional iterative reconstruction algorithm is applied, integrating the data consistency in the measured angular range and the prior information in the missing angular range. This ensures data integrity in the measured area, while inaccuracies incorporated by the deep learning prior lie only in areas where no information is acquired. The proposed DCAR method achieves significant image quality improvement: for 120-degree cone-beam limited angle tomography more than 10% RMSE reduction in noise-free case and more than 24% RMSE reduction in noisy case compared with a state-of-the-art U-Net based method.
Channel Attention with Embedding Gaussian Process: A Probabilistic Methodology
Mar 10, 2020
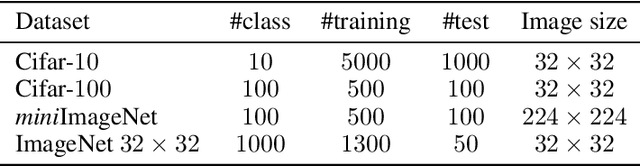
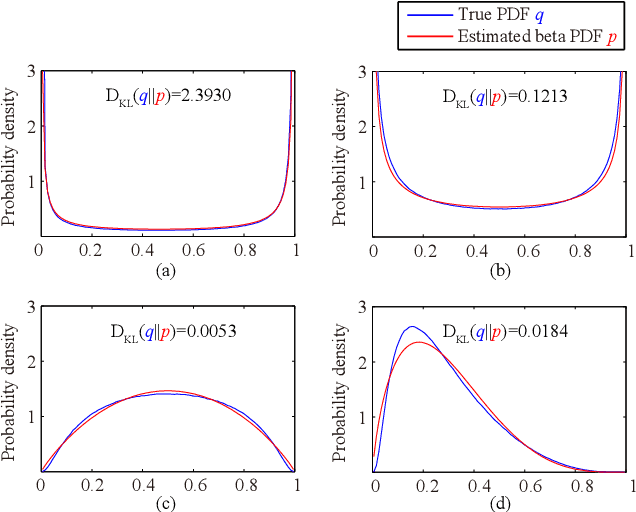
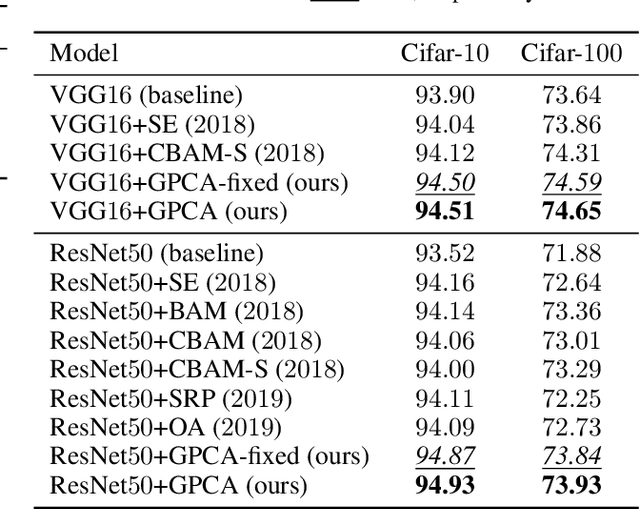
Channel attention mechanisms, as the key components of some modern convolutional neural networks (CNNs) architectures, have been commonly used in many visual tasks for effective performance improvement. It is able to reinforce the informative channels and to suppress useless channels of feature maps obtained by CNNs. Recently, different attention modules have been proposed, which are implemented in various ways. However, they are mainly based on convolution and pooling operations, which are lack of intuitive and reasonable insights about the principles that they are based on. Moreover, the ways that they improve the performance of the CNNs is not clear either. In this paper, we propose a Gaussian process embedded channel attention (GPCA) module and interpret the channel attention intuitively and reasonably in a probabilistic way. The GPCA module is able to model the correlations from channels which are assumed as beta distributed variables with Gaussian process prior. As the beta distribution is intractably integrated into the end-to-end training of the CNNs, we utilize an appropriate approximation of the beta distribution to make the distribution assumption implemented easily. In this case, the proposed GPCA module can be integrated into the end-to-end training of the CNNs. Experimental results demonstrate that the proposed GPCA module can improve the accuracies of image classification on four widely used datasets.
Animating Arbitrary Objects via Deep Motion Transfer
Dec 24, 2018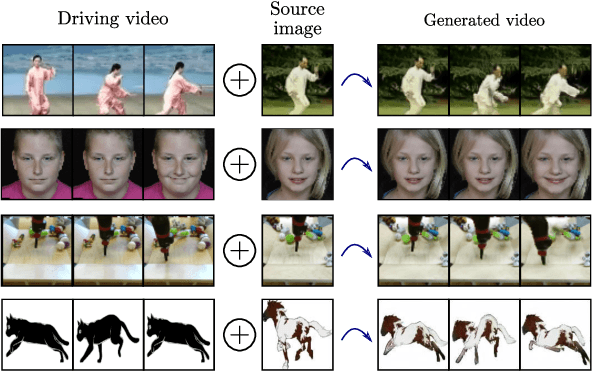

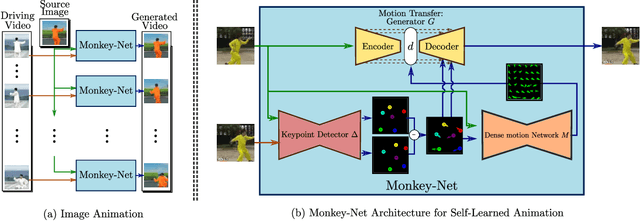
This paper introduces a novel deep learning framework for image animation. Given an input image with a target object and a driving video sequence depicting a moving object, our framework generates a video in which the target object is animated according to the driving sequence. This is achieved through a deep architecture that decouples appearance and motion information. Our framework consists of three main modules: (i) a Keypoint Detector unsupervisely trained to extract object keypoints, (ii) a Dense Motion prediction network for generating dense heatmaps from sparse keypoints, in order to better encode motion information and (iii) a Motion Transfer Network, which uses the motion heatmaps and appearance information extracted from the input image to synthesize the output frames. We demonstrate the effectiveness of our method on several benchmark datasets, spanning a wide variety of object appearances, and show that our approach outperforms state-of-the-art image animation and video generation methods.
Going Negative Online? -- A Study of Negative Advertising on Social Media
Oct 14, 2019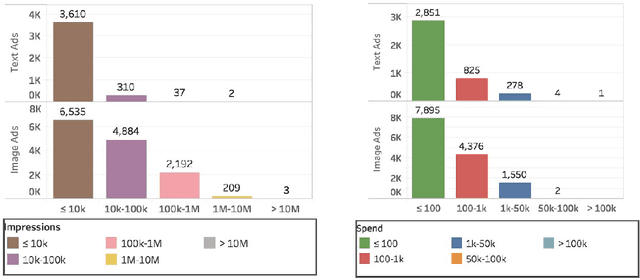
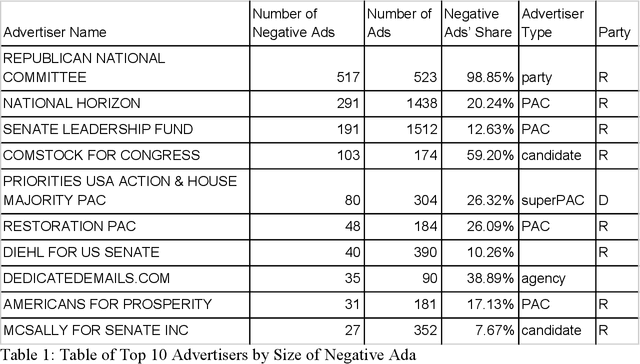
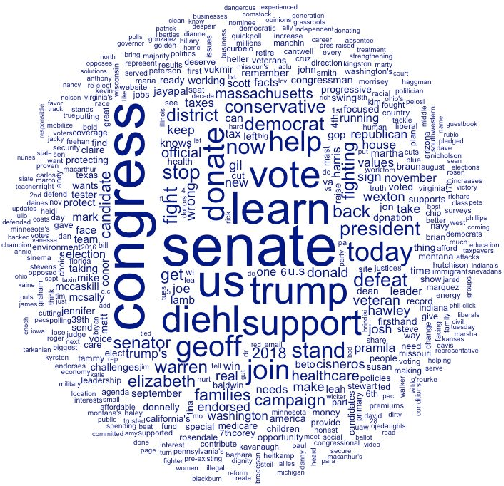
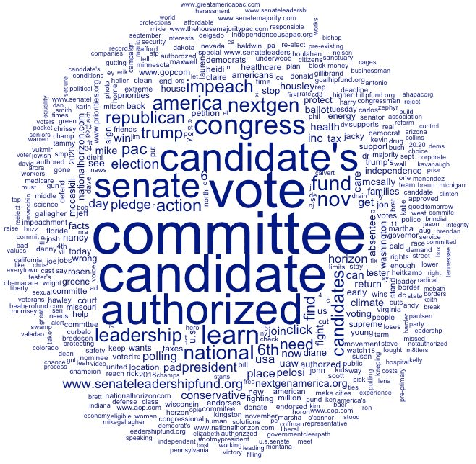
A growing number of empirical studies suggest that negative advertising is effective in campaigning, while the mechanisms are rarely mentioned. With the scandal of Cambridge Analytica and Russian intervention behind the Brexit and the 2016 presidential election, people have become aware of the political ads on social media and have pressured congress to restrict political advertising on social media. Following the related legislation, social media companies began disclosing their political ads archive for transparency during the summer of 2018 when the midterm election campaign was just beginning. This research collects the data of the related political ads in the context of the U.S. midterm elections since August to study the overall pattern of political ads on social media and uses sets of machine learning methods to conduct sentiment analysis on these ads to classify the negative ads. A novel approach is applied that uses AI image recognition to study the image data. Through data visualization, this research shows that negative advertising is still the minority, Republican advertisers and third party organizations are more likely to engage in negative advertising than their counterparts. Based on ordinal regressions, this study finds that anger evoked information-seeking is one of the main mechanisms causing negative ads to be more engaging and effective rather than the negative bias theory. Overall, this study provides a unique understanding of political advertising on social media by applying innovative data science methods. Further studies can extend the findings, methods, and datasets in this study, and several suggestions are given for future research.
Multi-hypothesis contextual modeling for semantic segmentation
Dec 14, 2018
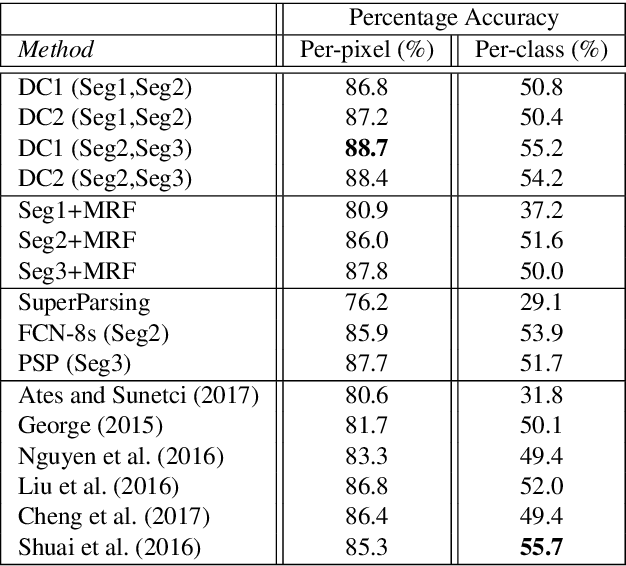
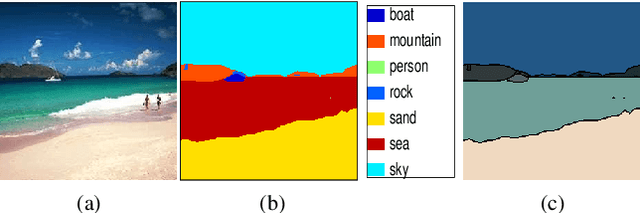
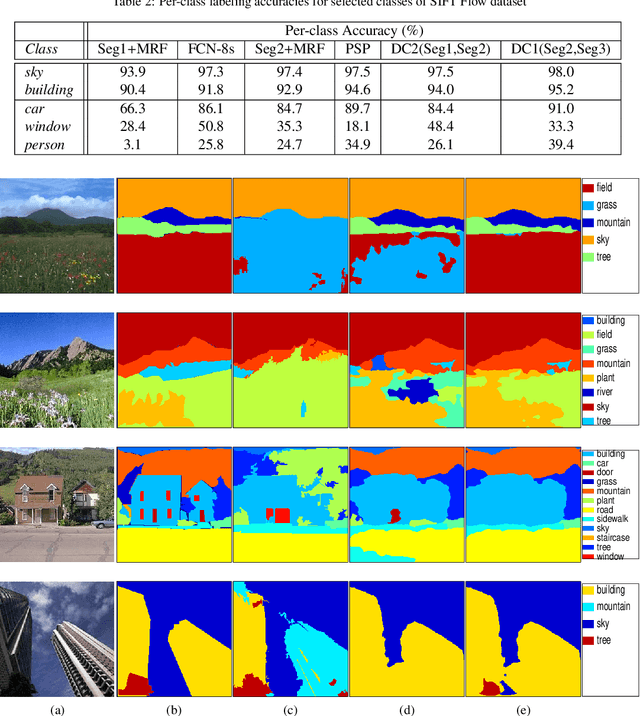
Semantic segmentation (i.e. image parsing) aims to annotate each image pixel with its corresponding semantic class label. Spatially consistent labeling of the image requires an accurate description and modeling of the local contextual information. Segmentation result is typically improved by Markov Random Field (MRF) optimization on the initial labels. However this improvement is limited by the accuracy of initial result and how the contextual neighborhood is defined. In this paper, we develop generalized and flexible contextual models for segmentation neighborhoods in order to improve parsing accuracy. Instead of using a fixed segmentation and neighborhood definition, we explore various contextual models for fusion of complementary information available in alternative segmentations of the same image. In other words, we propose a novel MRF framework that describes and optimizes the contextual dependencies between multiple segmentations. Simulation results on two common datasets demonstrate significant improvement in parsing accuracy over the baseline approaches.
Photo-realistic Monocular Gaze Redirection using Generative Adversarial Networks
Mar 29, 2019
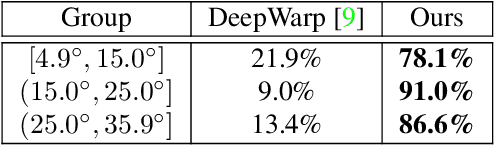
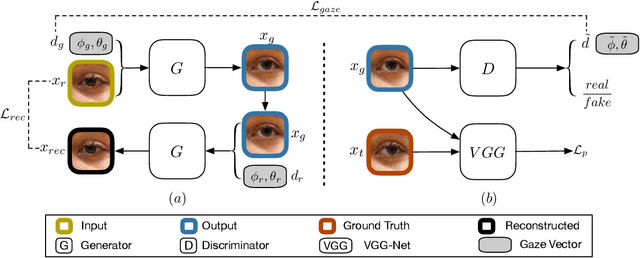
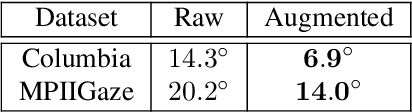
Gaze redirection is the task of changing the gaze to a desired direction for a given monocular eye patch image. Many applications such as videoconferencing, films and games, and generation of training data for gaze estimation require redirecting the gaze, without distorting the appearance of the area surrounding the eye and while producing photo-realistic images. Existing methods lack the ability to generate perceptually plausible images. In this work, we present a novel method to alleviate this problem by leveraging generative adversarial training to synthesize an eye image conditioned on a target gaze direction. Our method ensures perceptual similarity and consistency of synthesized images to the real images. Furthermore, a gaze estimation loss is used to control the gaze direction accurately. To attain high-quality images, we incorporate perceptual and cycle consistency losses into our architecture. In extensive evaluations we show that the proposed method outperforms state-of-the-art approaches in terms of both image quality and redirection precision. Finally, we show that generated images can bring significant improvement for the gaze estimation task if used to augment real training data.
Online Normalization for Training Neural Networks
May 15, 2019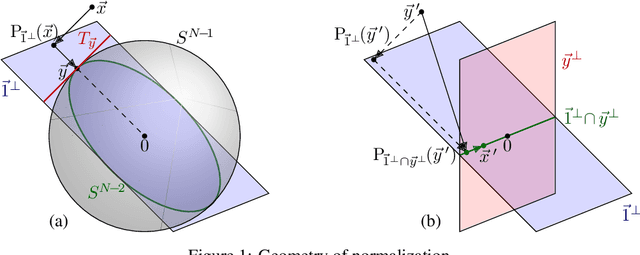
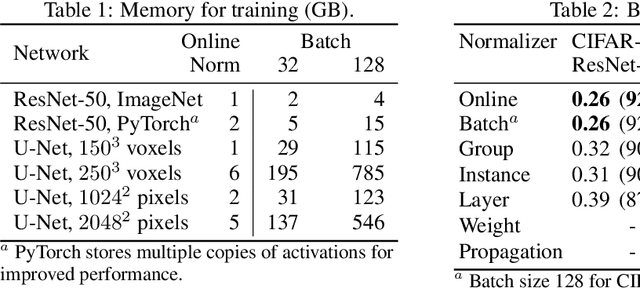
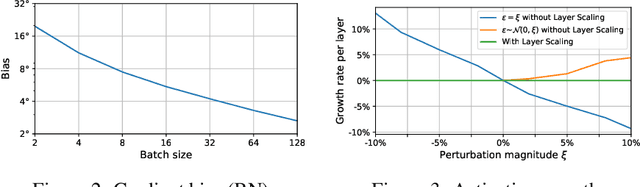
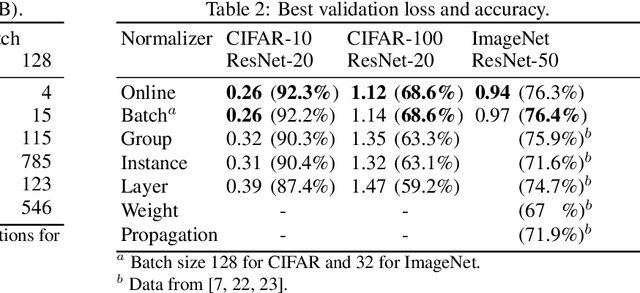
Online Normalization is a new technique for normalizing the hidden activations of a neural network. Like Batch Normalization, it normalizes the sample dimension. While Online Normalization does not use batches, it is as accurate as Batch Normalization. We resolve a theoretical limitation of Batch Normalization by introducing an unbiased technique for computing the gradient of normalized activations. Online Normalization works with automatic differentiation by adding statistical normalization as a primitive. This technique can be used in cases not covered by some other normalizers, such as recurrent networks, fully connected networks, and networks with activation memory requirements prohibitive for batching. We show its applications to image classification, image segmentation, and language modeling. We present formal proofs and experimental results on ImageNet, CIFAR, and PTB datasets.