 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Mass Estimation of Galaxy Clusters with Deep Learning I: Sunyaev-Zel'dovich Effect
Mar 13, 2020
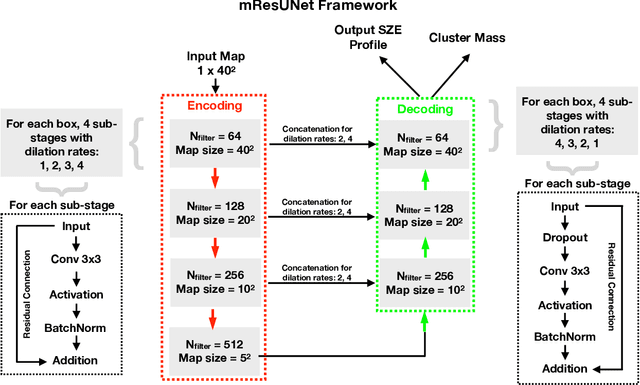
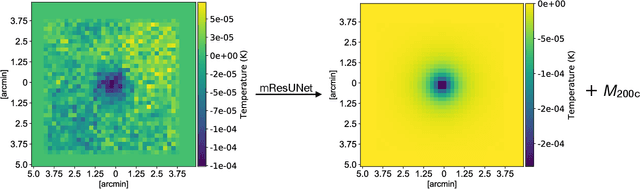
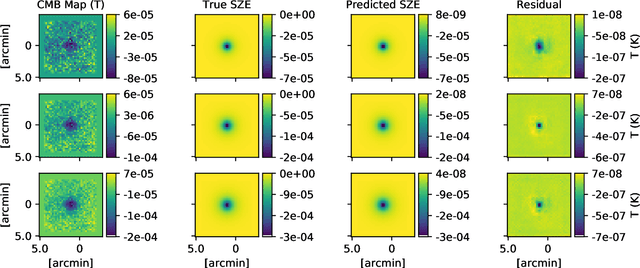
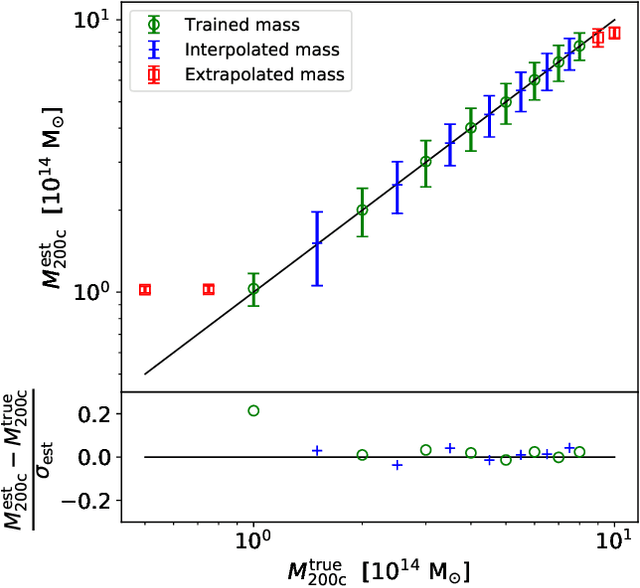
We present a new application of deep learning to infer the masses of galaxy clusters directly from images of the microwave sky. Effectively, this is a novel approach to determining the scaling relation between a cluster's Sunyaev-Zel'dovich (SZ) effect signal and mass. The deep learning algorithm used is mResUNet, which is a modified feed-forward deep learning algorithm that broadly combines residual learning, convolution layers with different dilation rates, image regression activation and a U-Net framework. We train and test the deep learning model using simulated images of the microwave sky that include signals from the cosmic microwave background (CMB), dusty and radio galaxies, instrumental noise as well as the cluster's own SZ signal. The simulated cluster sample covers the mass range 1$\times 10^{14}~\rm M_{\odot}$ $<M_{200\rm c}<$ 8$\times 10^{14}~\rm M_{\odot}$ at $z=0.7$. The trained model estimates the cluster masses with a 1 $\sigma$ uncertainty $\Delta M/M \leq 0.2$, consistent with the input scatter on the SZ signal of 20%. We verify that the model works for realistic SZ profiles even when trained on azimuthally symmetric SZ profiles by using the Magneticum hydrodynamical simulations. We find the model returns unbiased mass estimates for the hydrodynamical simulations with a scatter consistent with the SZ-mass scatter in the light cones.
Self-Supervised Fast Adaptation for Denoising via Meta-Learning
Jan 09, 2020



Under certain statistical assumptions of noise, recent self-supervised approaches for denoising have been introduced to learn network parameters without true clean images, and these methods can restore an image by exploiting information available from the given input (i.e., internal statistics) at test time. However, self-supervised methods are not yet combined with conventional supervised denoising methods which train the denoising networks with a large number of external training samples. Thus, we propose a new denoising approach that can greatly outperform the state-of-the-art supervised denoising methods by adapting their network parameters to the given input through selfsupervision without changing the networks architectures. Moreover, we propose a meta-learning algorithm to enable quick adaptation of parameters to the specific input at test time. We demonstrate that the proposed method can be easily employed with state-of-the-art denoising networks without additional parameters, and achieve state-of-the-art performance on numerous benchmark datasets.
Detection of small changes in medical and random-dot images comparing self-organizing map performance to human detection
Jun 26, 2019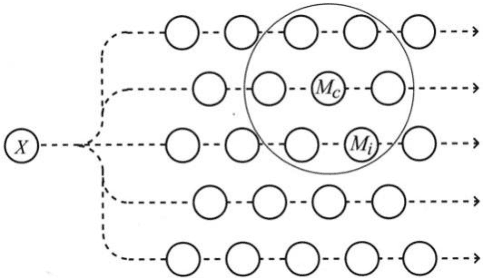
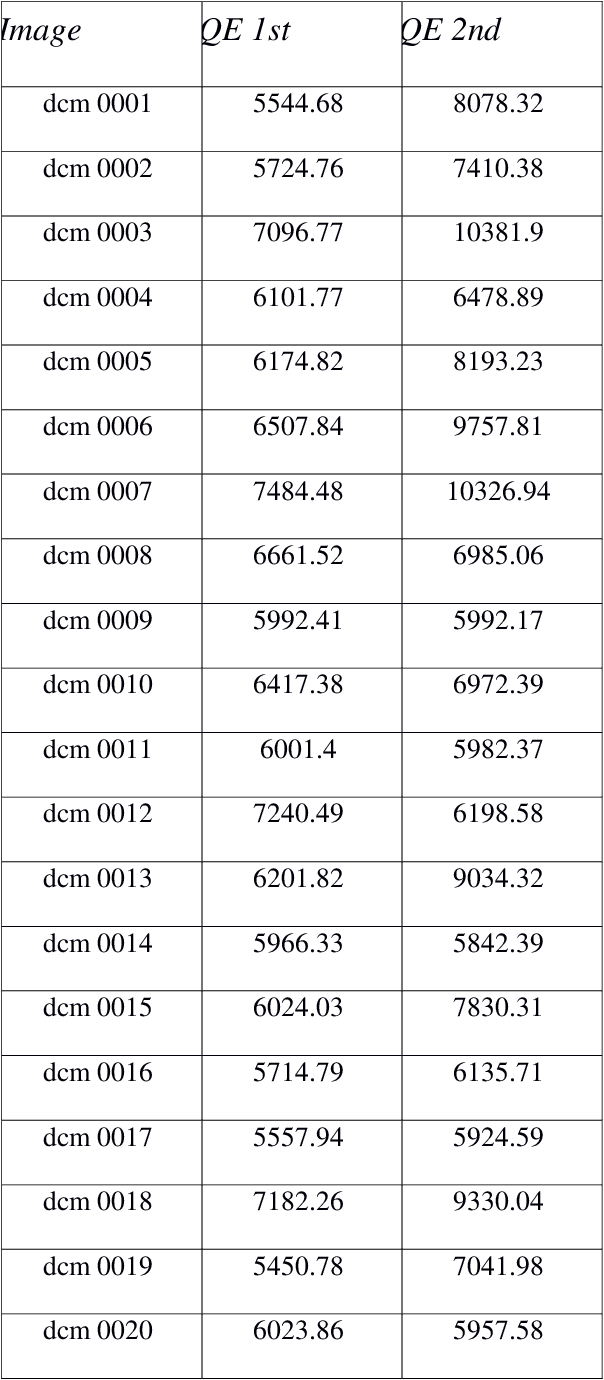
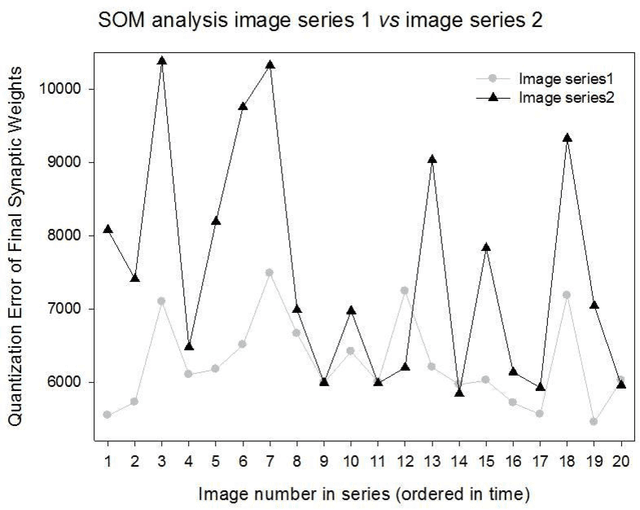
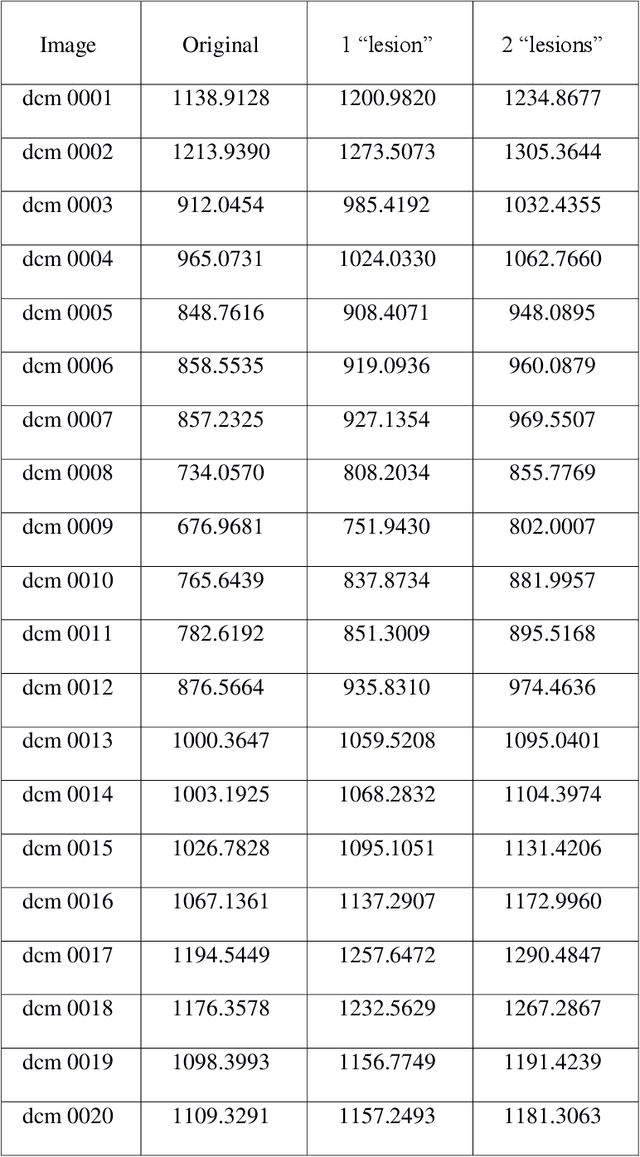
Radiologists use time series of medical images to monitor the progression of a patient condition. They compare information gleaned from sequences of images to gain insight on progression or remission of the lesions, thus evaluating the progress of a patient condition or response to therapy. Visual methods of determining differences between one series of images to another can be subjective or fail to detect very small differences. We propose the use of quantization errors obtained from Self Organizing Maps for image content analysis. We tested this technique with MRI images to which we progressively added synthetic lesions. We have used a global approach that considers changes on the entire image as opposed to changes in segmented lesion regions only. We claim that this approach does not suffer from the limitations imposed by segmentation, which may compromise the results. Results show quantization errors increased with the increase in lesions on the images. The results are also consistent with previous studies using alternative approaches. We then compared the detectability ability of our method to that of human novice observers having to detect very small local differences in random-dot images. The quantization errors of the SOM outputs compared with correct positive rates, after subtraction of false positive rates (guess rates), increased noticeably and consistently with small increases in local dot size that were not detectable by humans. We conclude that our method detects very small changes in complex images and suggest that it could be implemented to assist human operators in image based decision making.
* arXiv admin note: substantial text overlap with arXiv:1709.02292
Towards Generalizing Sensorimotor Control Across Weather Conditions
Jul 25, 2019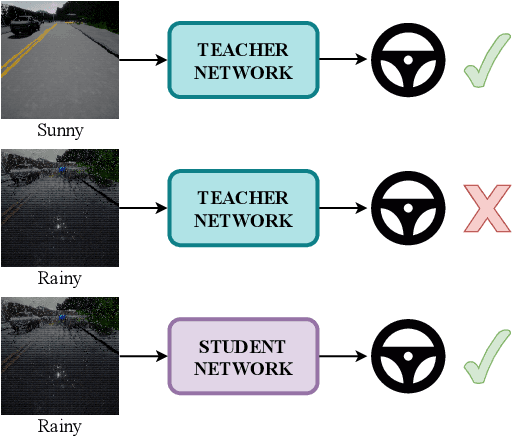
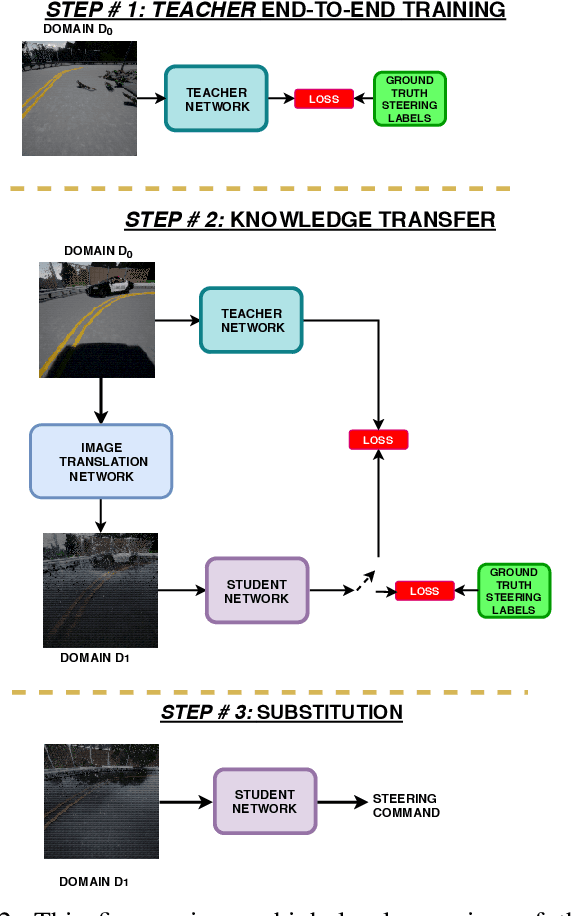
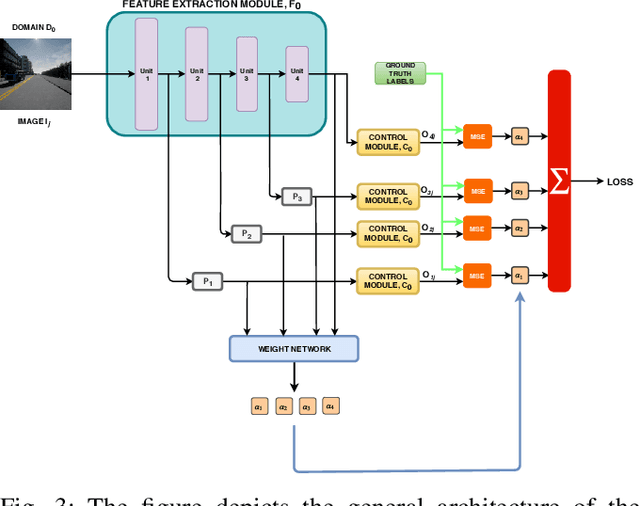
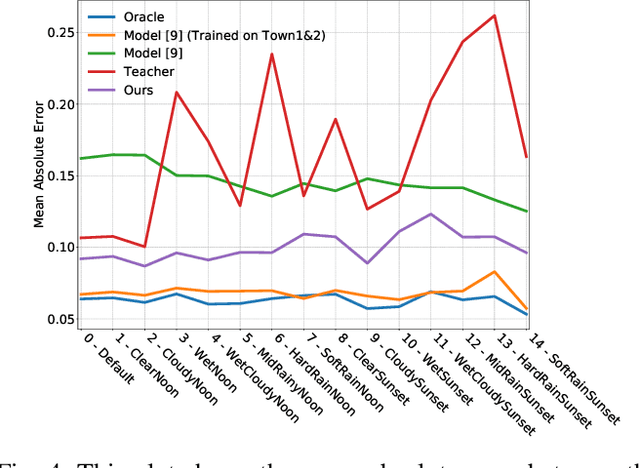
The ability of deep learning models to generalize well across different scenarios depends primarily on the quality and quantity of annotated data. Labeling large amounts of data for all possible scenarios that a model may encounter would not be feasible; if even possible. We propose a framework to deal with limited labeled training data and demonstrate it on the application of vision-based vehicle control. We show how limited steering angle data available for only one condition can be transferred to multiple different weather scenarios. This is done by leveraging unlabeled images in a teacher-student learning paradigm complemented with an image-to-image translation network. The translation network transfers the images to a new domain, whereas the teacher provides soft supervised targets to train the student on this domain. Furthermore, we demonstrate how utilization of auxiliary networks can reduce the size of a model at inference time, without affecting the accuracy. The experiments show that our approach generalizes well across multiple different weather conditions using only ground truth labels from one domain.
Orthogonal Convolutional Neural Networks
Nov 27, 2019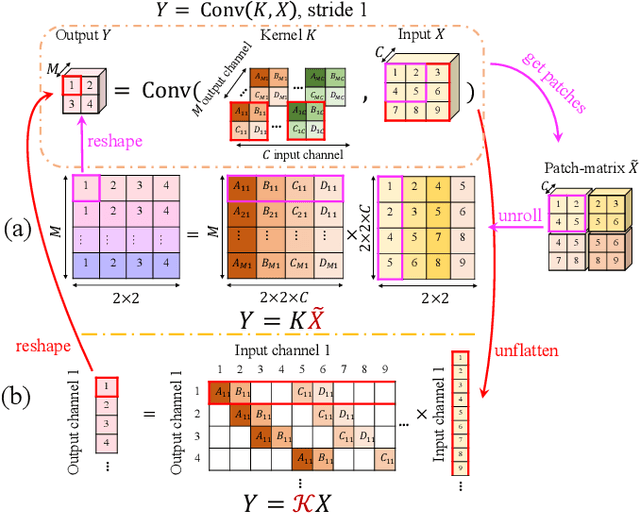
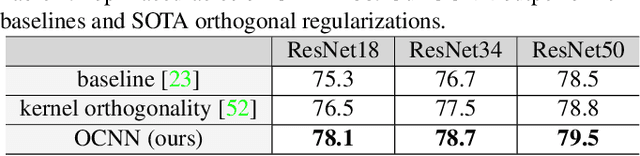
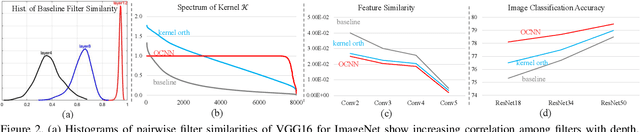

The instability and feature redundancy in CNNs hinders further performance improvement. Using orthogonality as a regularizer has shown success in alleviating these issues. Previous works however only considered the kernel orthogonality in the convolution layers of CNNs, which is a necessary but not sufficient condition for orthogonal convolutions in general. We propose orthogonal convolutions as regularizations in CNNs and benchmark its effect on various tasks. We observe up to 3% gain for CIFAR100 and up to 1% gain for ImageNet classification. Our experiments also demonstrate improved performance on image retrieval, inpainting and generation, which suggests orthogonal convolution improves the feature expressiveness. Empirically, we show that the uniform spectrum and reduced feature redundancy may account for the gain in performance and robustness under adversarial attacks.
Known-plaintext attack and ciphertext-only attack for encrypted single-pixel imaging
May 31, 2019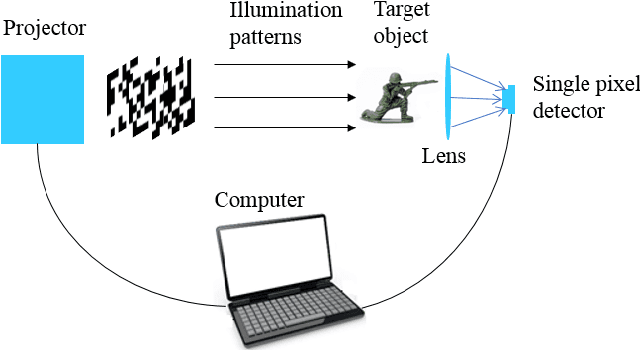
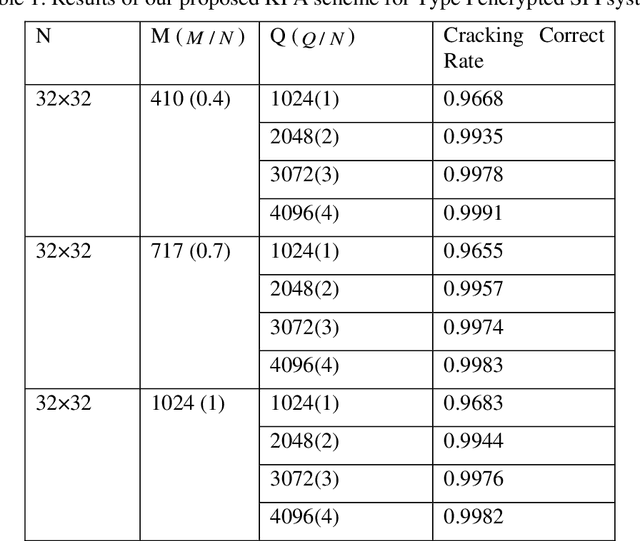
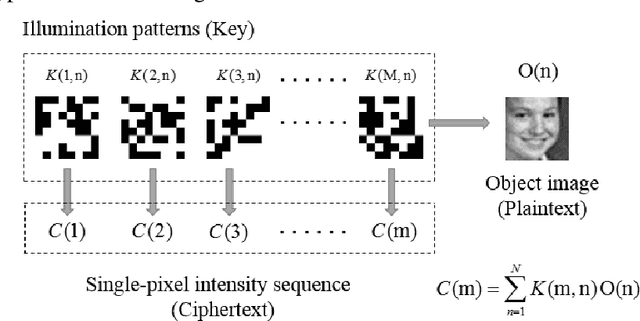
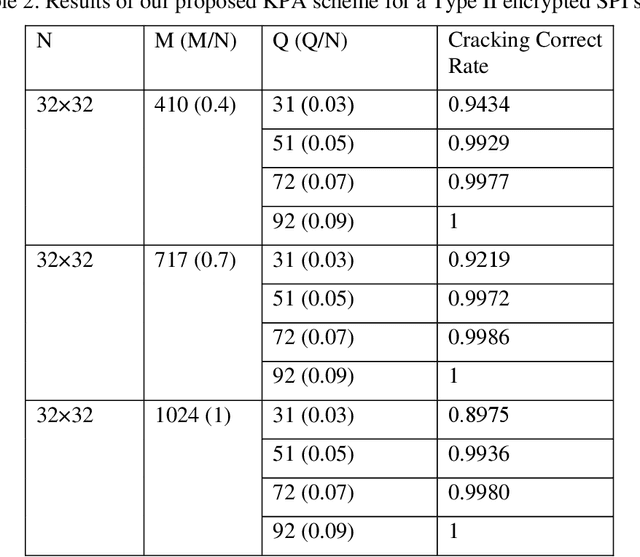
In many previous works, a single-pixel imaging (SPI) system is constructed as an optical image encryption system. Unauthorized users are not able to reconstruct the plaintext image from the ciphertext intensity sequence without knowing the illumination pattern key. However, little cryptanalysis about encrypted SPI has been investigated in the past. In this work, we propose a known-plaintext attack scheme and a ciphertext-only attack scheme to an encrypted SPI system for the first time. The known-plaintext attack is implemented by interchanging the roles of illumination patterns and object images in the SPI model. The ciphertext-only attack is implemented based on the statistical features of single-pixel intensity values. The two schemes can crack encrypted SPI systems and successfully recover the key containing correct illumination patterns.
COVID-CAPS: A Capsule Network-based Framework for Identification of COVID-19 cases from X-ray Images
Apr 06, 2020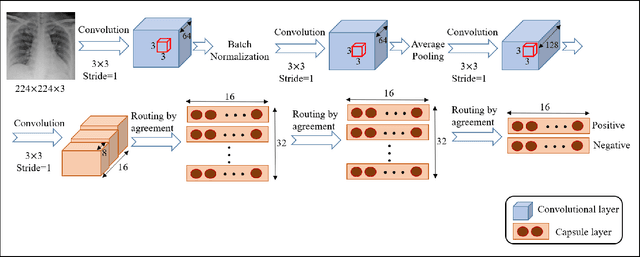

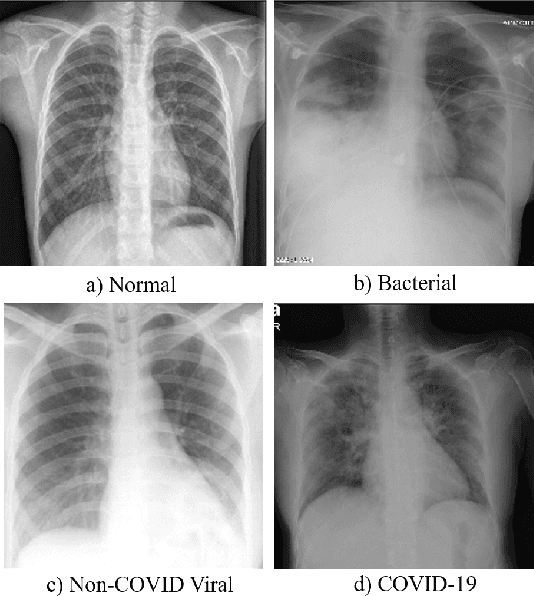
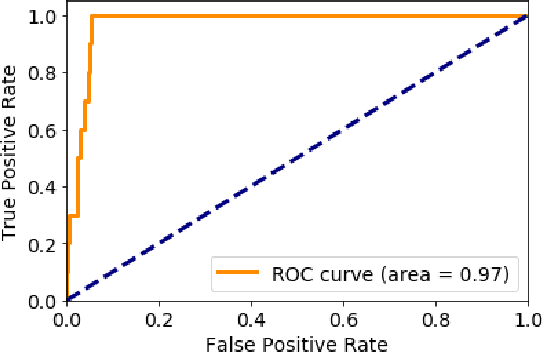
Novel Coronavirus disease (COVID-19) has abruptly and undoubtedly changed the world as we know it at the end of the 2nd decade of the 21st century. COVID-19 is extremely contagious and quickly spreading globally making its early diagnosis of paramount importance. Early diagnosis of COVID-19 enables health care professionals and government authorities to break the chain of transition and flatten the epidemic curve. The common type of COVID-19 diagnosis test, however, requires specific equipment and has relatively low sensitivity and high false-negative rate. Computed tomography (CT) scans and X-ray images, on the other hand, reveal specific manifestations associated with this disease. Overlap with other lung infections makes human-centered diagnosis of COVID-19 challenging. Consequently, there has been an urgent surge of interest to develop Deep Neural Network (DNN)-based diagnosis solutions, mainly based on Convolutional Neural Networks (CNNs), to facilitate identification of positive COVID-19 cases. CNNs, however, are prone to lose spatial information between image instances and require large datasets. This paper presents an alternative modeling framework based on Capsule Networks, referred to as the COVID-CAPS, being capable of handling small datasets, which is of significant importance due to sudden and rapid emergence of COVID-19. Our initial results based on a dataset of X-ray images show that COVID-CAPS has advantage over previous CNN-based models. COVID-CAPS achieved an Accuracy of 95.7%, Sensitivity of 90%, Specificity of 95.8%, and Area Under the Curve (AUC) of 0.97, while having far less number of trainable parameters in comparison to its counterparts.
A Cross-Stitch Architecture for Joint Registration and Segmentation in Adaptive Radiotherapy
Apr 17, 2020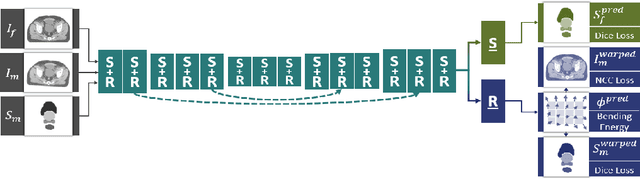
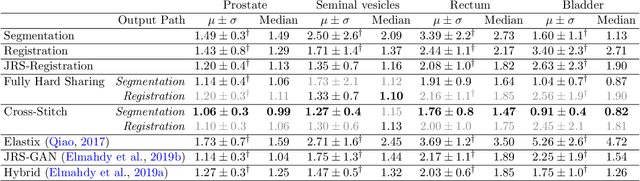
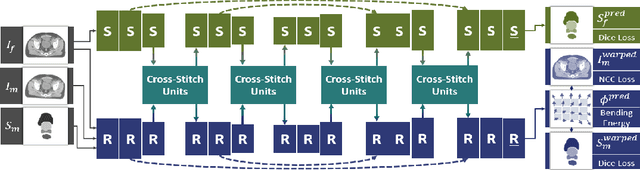
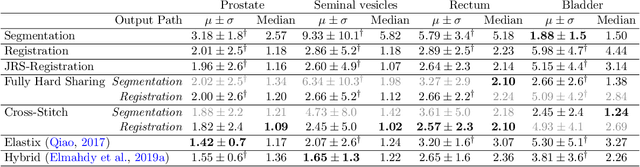
Recently, joint registration and segmentation has been formulated in a deep learning setting, by the definition of joint loss functions. In this work, we investigate joining these tasks at the architectural level. We propose a registration network that integrates segmentation propagation between images, and a segmentation network to predict the segmentation directly. These networks are connected into a single joint architecture via so-called cross-stitch units, allowing information to be exchanged between the tasks in a learnable manner. The proposed method is evaluated in the context of adaptive image-guided radiotherapy, using daily prostate CT imaging. Two datasets from different institutes and manufacturers were involved in the study. The first dataset was used for training (12 patients) and validation (6 patients), while the second dataset was used as an independent test set (14 patients). In terms of mean surface distance, our approach achieved $1.06 \pm 0.3$ mm, $0.91 \pm 0.4$ mm, $1.27 \pm 0.4$ mm, and $1.76 \pm 0.8$ mm on the validation set and $1.82 \pm 2.4$ mm, $2.45 \pm 2.4$ mm, $2.45 \pm 5.0$ mm, and $2.57 \pm 2.3$ mm on the test set for the prostate, bladder, seminal vesicles, and rectum, respectively. The proposed multi-task network outperformed single-task networks, as well as a network only joined through the loss function, thus demonstrating the capability to leverage the individual strengths of the segmentation and registration tasks. The obtained performance as well as the inference speed make this a promising candidate for daily re-contouring in adaptive radiotherapy, potentially reducing treatment-related side effects and improving quality-of-life after treatment.
Attention-aware Multi-stroke Style Transfer
Jan 16, 2019

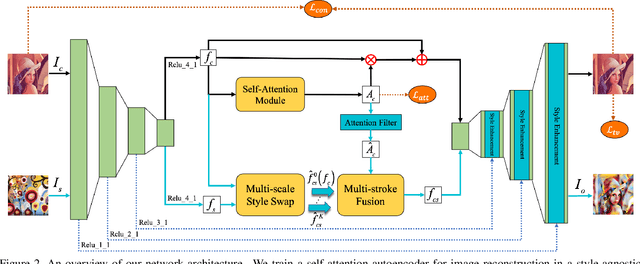
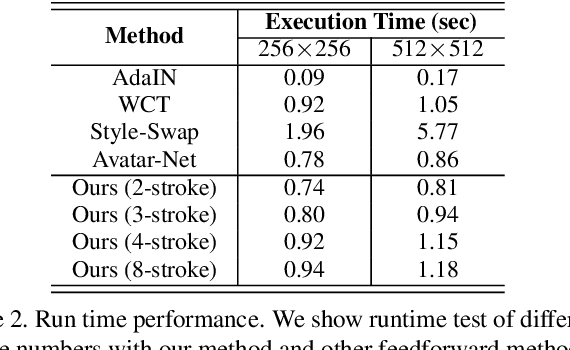
Neural style transfer has drawn considerable attention from both academic and industrial field. Although visual effect and efficiency have been significantly improved, existing methods are unable to coordinate spatial distribution of visual attention between the content image and stylized image, or render diverse level of detail via different brush strokes. In this paper, we tackle these limitations by developing an attention-aware multi-stroke style transfer model. We first propose to assemble self-attention mechanism into a style-agnostic reconstruction autoencoder framework, from which the attention map of a content image can be derived. By performing multi-scale style swap on content features and style features, we produce multiple feature maps reflecting different stroke patterns. A flexible fusion strategy is further presented to incorporate the salient characteristics from the attention map, which allows integrating multiple stroke patterns into different spatial regions of the output image harmoniously. We demonstrate the effectiveness of our method, as well as generate comparable stylized images with multiple stroke patterns against the state-of-the-art methods.
Your GAN is Secretly an Energy-based Model and You Should use Discriminator Driven Latent Sampling
Mar 12, 2020
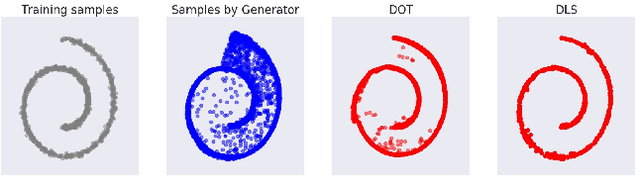
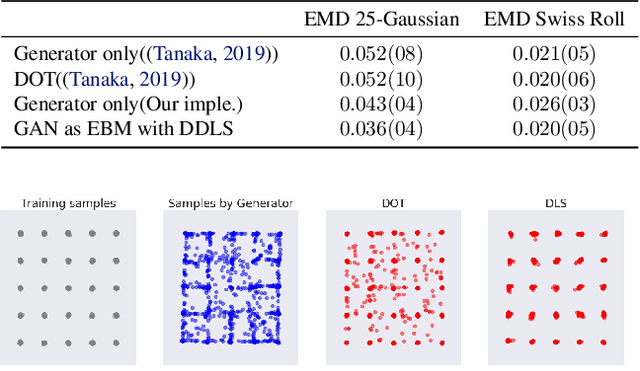

We show that the sum of the implicit generator log-density $\log p_g$ of a GAN with the logit score of the discriminator defines an energy function which yields the true data density when the generator is imperfect but the discriminator is optimal, thus making it possible to improve on the typical generator (with implicit density $p_g$). To make that practical, we show that sampling from this modified density can be achieved by sampling in latent space according to an energy-based model induced by the sum of the latent prior log-density and the discriminator output score. This can be achieved by running a Langevin MCMC in latent space and then applying the generator function, which we call Discriminator Driven Latent Sampling~(DDLS). We show that DDLS is highly efficient compared to previous methods which work in the high-dimensional pixel space and can be applied to improve on previously trained GANs of many types. We evaluate DDLS on both synthetic and real-world datasets qualitatively and quantitatively. On CIFAR-10, DDLS substantially improves the Inception Score of an off-the-shelf pre-trained SN-GAN~\citep{sngan} from $8.22$ to $9.09$ which is even comparable to the class-conditional BigGAN~\citep{biggan} model. This achieves a new state-of-the-art in unconditional image synthesis setting without introducing extra parameters or additional training.