 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Hypergraph Learning for Identification of COVID-19 with CT Imaging
May 07, 2020
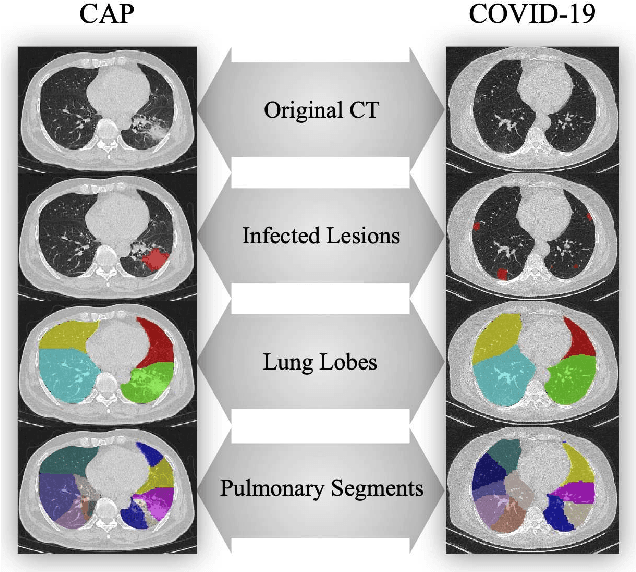

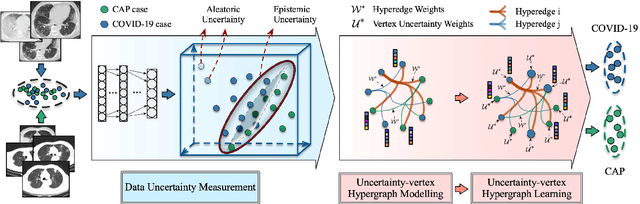

The coronavirus disease, named COVID-19, has become the largest global public health crisis since it started in early 2020. CT imaging has been used as a complementary tool to assist early screening, especially for the rapid identification of COVID-19 cases from community acquired pneumonia (CAP) cases. The main challenge in early screening is how to model the confusing cases in the COVID-19 and CAP groups, with very similar clinical manifestations and imaging features. To tackle this challenge, we propose an Uncertainty Vertex-weighted Hypergraph Learning (UVHL) method to identify COVID-19 from CAP using CT images. In particular, multiple types of features (including regional features and radiomics features) are first extracted from CT image for each case. Then, the relationship among different cases is formulated by a hypergraph structure, with each case represented as a vertex in the hypergraph. The uncertainty of each vertex is further computed with an uncertainty score measurement and used as a weight in the hypergraph. Finally, a learning process of the vertex-weighted hypergraph is used to predict whether a new testing case belongs to COVID-19 or not. Experiments on a large multi-center pneumonia dataset, consisting of 2,148 COVID-19 cases and 1,182 CAP cases from five hospitals, are conducted to evaluate the performance of the proposed method. Results demonstrate the effectiveness and robustness of our proposed method on the identification of COVID-19 in comparison to state-of-the-art methods.
Joint Demosaicing and Super-Resolution (JDSR): Network Design and Perceptual Optimization
Nov 08, 2019
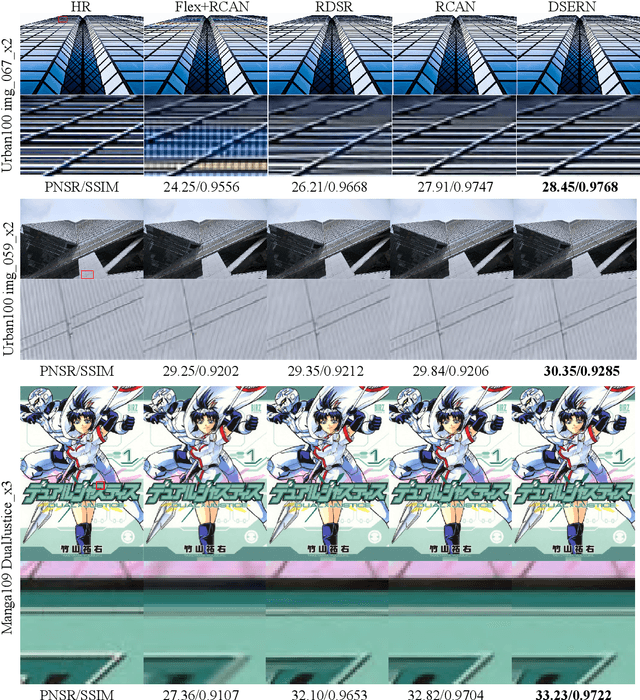


Image demosaicing and super-resolution are two important tasks in color imaging pipeline. So far they have been mostly independently studied in the open literature of deep learning; little is known about the potential benefit of formulating a joint demosaicing and super-resolution (JDSR) problem. In this paper, we propose an end-to-end optimization solution to the JDSR problem and demonstrate its practical significance in computational imaging. Our technical contributions are mainly two-fold. On network design, we have developed a Densely-connected Squeeze-and-Excitation Residual Network (DSERN) for JDSR. For the first time, we address the issue of spatio-spectral attention for color images and discuss how to achieve better information flow by smooth activation for JDSR. Experimental results have shown moderate PSNR/SSIM gain can be achieved by DSERN over previous naive network architectures. On perceptual optimization, we propose to leverage the latest ideas including relativistic discriminator and pre-excitation perceptual loss function to further improve the visual quality of reconstructed images. Our extensive experiment results have shown that Texture-enhanced Relativistic average Generative Adversarial Network (TRaGAN) can produce both subjectively more pleasant images and objectively lower perceptual distortion scores than standard GAN for JDSR. We have verified the benefit of JDSR to high-quality image reconstruction from real-world Bayer pattern collected by NASA Mars Curiosity.
Resolving Referring Expressions in Images With Labeled Elements
Oct 25, 2018

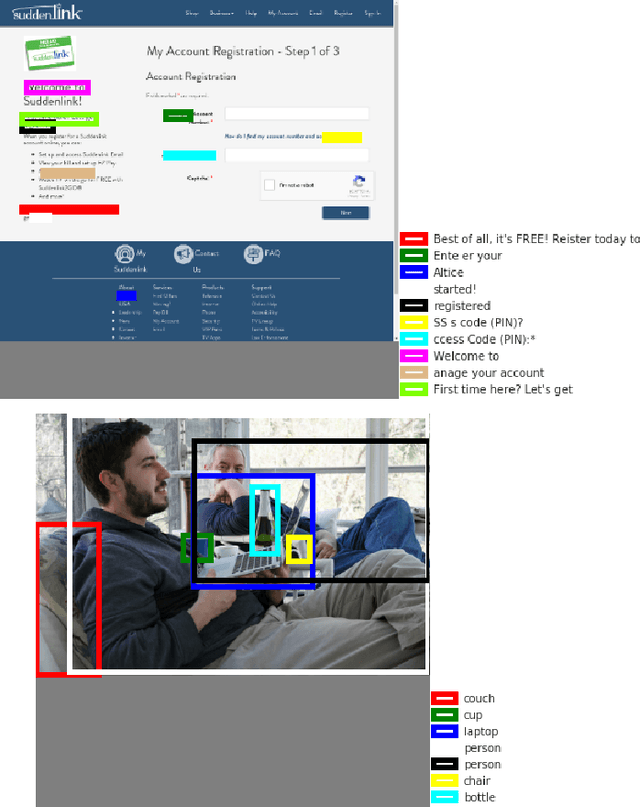

Images may have elements containing text and a bounding box associated with them, for example, text identified via optical character recognition on a computer screen image, or a natural image with labeled objects. We present an end-to-end trainable architecture to incorporate the information from these elements and the image to segment/identify the part of the image a natural language expression is referring to. We calculate an embedding for each element and then project it onto the corresponding location (i.e., the associated bounding box) of the image feature map. We show that this architecture gives an improvement in resolving referring expressions, over only using the image, and other methods that incorporate the element information. We demonstrate experimental results on the referring expression datasets based on COCO, and on a webpage image referring expression dataset that we developed.
Gradient-based Data Augmentation for Semi-Supervised Learning
Mar 28, 2020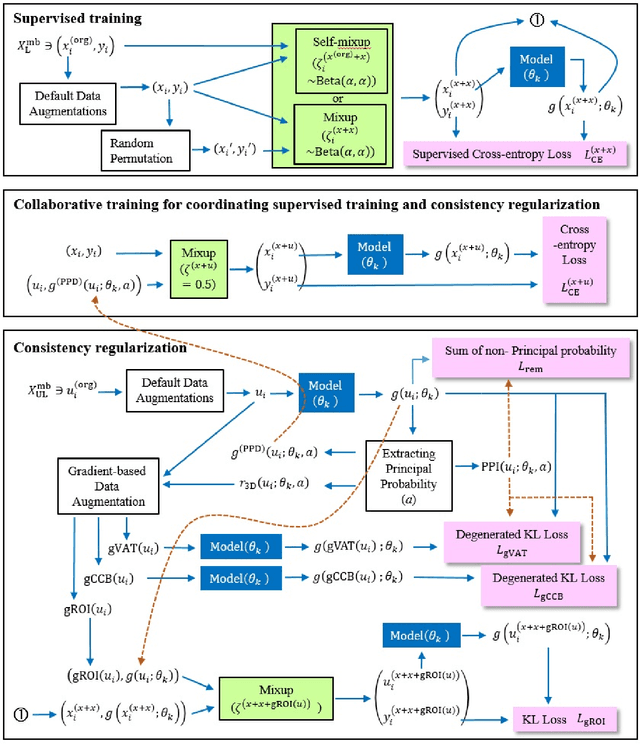
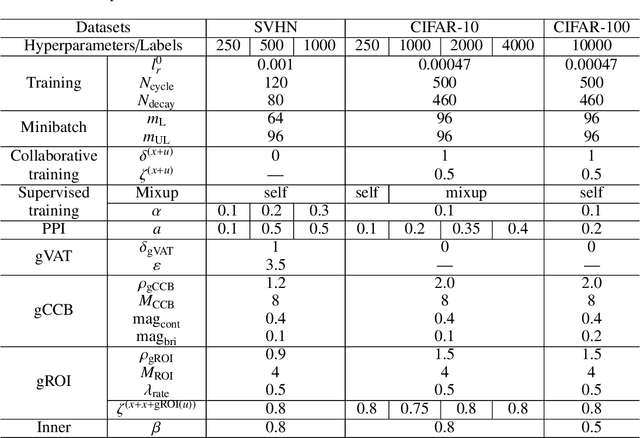
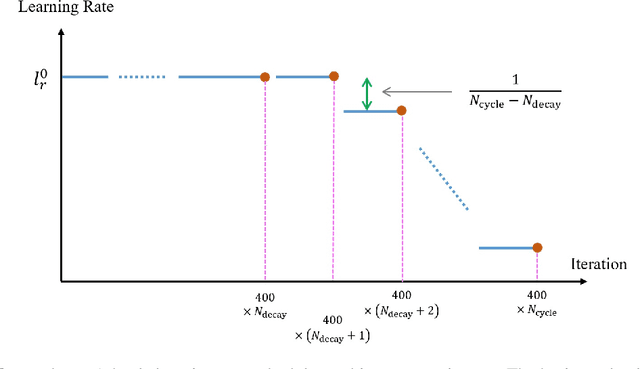
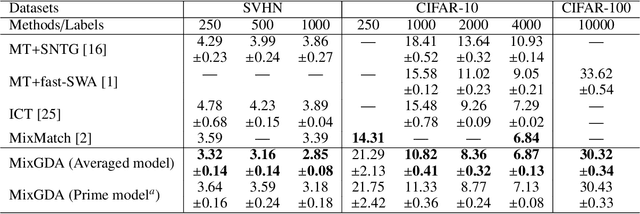
In semi-supervised learning (SSL), a technique called consistency regularization (CR) achieves high performance. It has been proved that the diversity of data used in CR is extremely important to obtain a model with high discrimination performance by CR. We propose a new data augmentation (Gradient-based Data Augmentation (GDA)) that is deterministically calculated from the image pixel value gradient of the posterior probability distribution that is the model output. We aim to secure effective data diversity for CR by utilizing three types of GDA. On the other hand, it has been demonstrated that the mixup method for labeled data and unlabeled data is also effective in SSL. We propose an SSL method named MixGDA by combining various mixup methods and GDA. The discrimination performance achieved by MixGDA is evaluated against the 13-layer CNN that is used as standard in SSL research. As a result, for CIFAR-10 (4000 labels), MixGDA achieves the same level of performance as the best performance ever achieved. For SVHN (250 labels, 500 labels and 1000 labels) and CIFAR-100 (10000 labels), MixGDA achieves state-of-the-art performance.
Wasserstein Smoothing: Certified Robustness against Wasserstein Adversarial Attacks
Oct 23, 2019
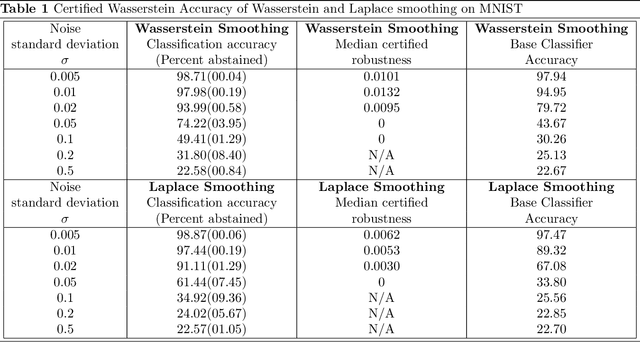

In the last couple of years, several adversarial attack methods based on different threat models have been proposed for the image classification problem. Most existing defenses consider additive threat models in which sample perturbations have bounded L_p norms. These defenses, however, can be vulnerable against adversarial attacks under non-additive threat models. An example of an attack method based on a non-additive threat model is the Wasserstein adversarial attack proposed by Wong et al. (2019), where the distance between an image and its adversarial example is determined by the Wasserstein metric ("earth-mover distance") between their normalized pixel intensities. Until now, there has been no certifiable defense against this type of attack. In this work, we propose the first defense with certified robustness against Wasserstein Adversarial attacks using randomized smoothing. We develop this certificate by considering the space of possible flows between images, and representing this space such that Wasserstein distance between images is upper-bounded by L_1 distance in this flow-space. We can then apply existing randomized smoothing certificates for the L_1 metric. In MNIST and CIFAR-10 datasets, we find that our proposed defense is also practically effective, demonstrating significantly improved accuracy under Wasserstein adversarial attack compared to unprotected models.
An Image Based Technique for Enhancement of Underwater Images
Dec 03, 2012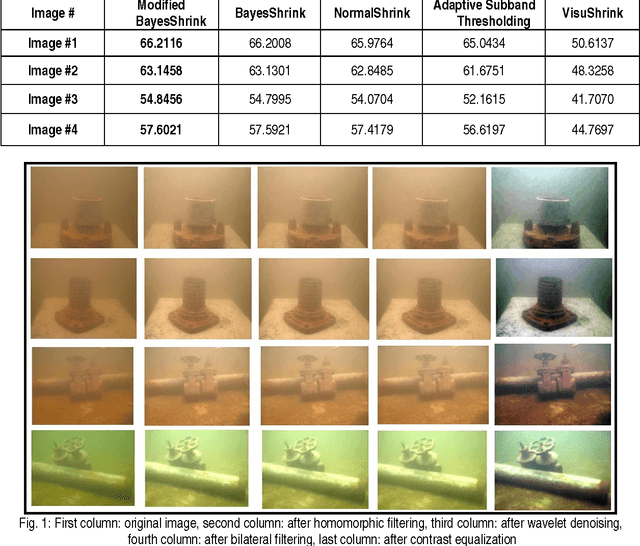
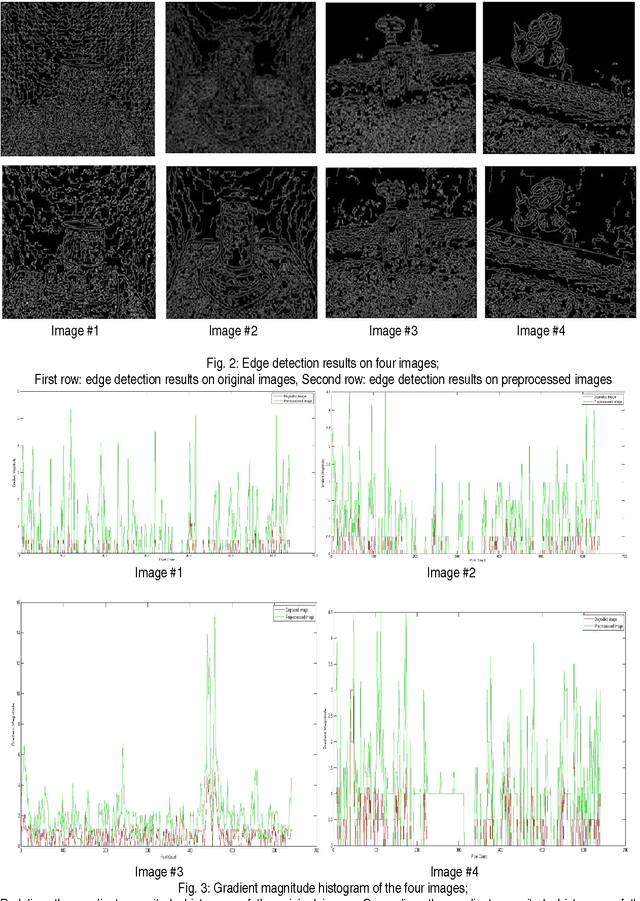
The underwater images usually suffers from non-uniform lighting, low contrast, blur and diminished colors. In this paper, we proposed an image based preprocessing technique to enhance the quality of the underwater images. The proposed technique comprises a combination of four filters such as homomorphic filtering, wavelet denoising, bilateral filter and contrast equalization. These filters are applied sequentially on degraded underwater images. The literature survey reveals that image based preprocessing algorithms uses standard filter techniques with various combinations. For smoothing the image, the image based preprocessing algorithms uses the anisotropic filter. The main drawback of the anisotropic filter is that iterative in nature and computation time is high compared to bilateral filter. In the proposed technique, in addition to other three filters, we employ a bilateral filter for smoothing the image. The experimentation is carried out in two stages. In the first stage, we have conducted various experiments on captured images and estimated optimal parameters for bilateral filter. Similarly, optimal filter bank and optimal wavelet shrinkage function are estimated for wavelet denoising. In the second stage, we conducted the experiments using estimated optimal parameters, optimal filter bank and optimal wavelet shrinkage function for evaluating the proposed technique. We evaluated the technique using quantitative based criteria such as a gradient magnitude histogram and Peak Signal to Noise Ratio (PSNR). Further, the results are qualitatively evaluated based on edge detection results. The proposed technique enhances the quality of the underwater images and can be employed prior to apply computer vision techniques.
Fast Distance-based Anomaly Detection in Images Using an Inception-like Autoencoder
Mar 12, 2020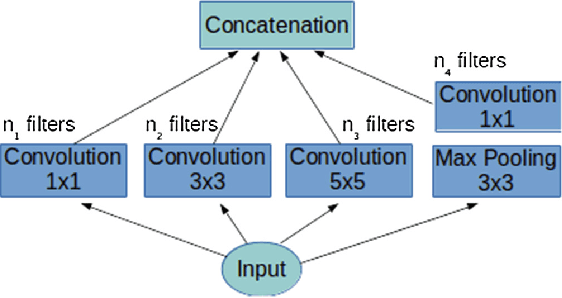
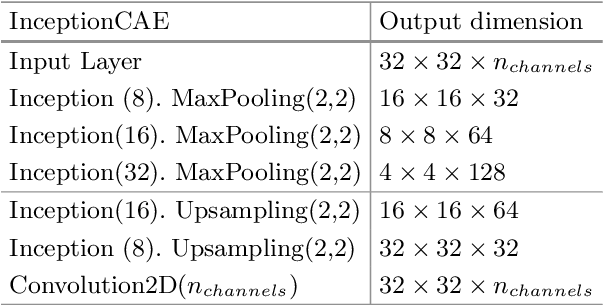
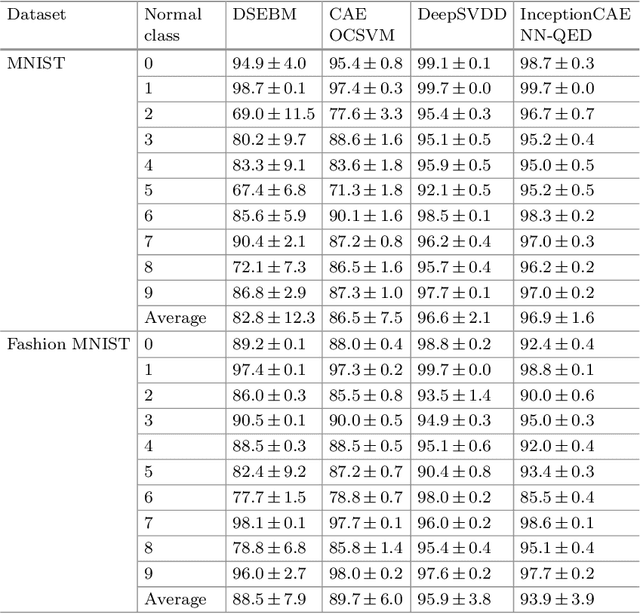
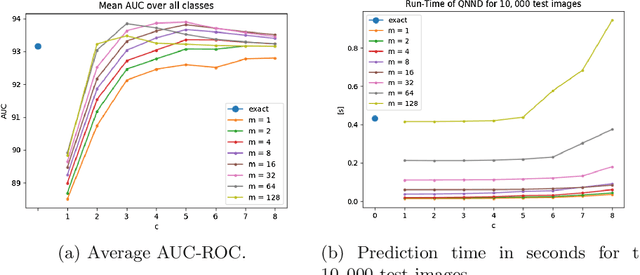
The goal of anomaly detection is to identify examples that deviate from normal or expected behavior. We tackle this problem for images. We consider a two-phase approach. First, using normal examples, a convolutional autoencoder (CAE) is trained to extract a low-dimensional representation of the images. Here, we propose a novel architectural choice when designing the CAE, an Inception-like CAE. It combines convolutional filters of different kernel sizes and it uses a Global Average Pooling (GAP) operation to extract the representations from the CAE's bottleneck layer. Second, we employ a distanced-based anomaly detector in the low-dimensional space of the learned representation for the images. However, instead of computing the exact distance, we compute an approximate distance using product quantization. This alleviates the high memory and prediction time costs of distance-based anomaly detectors. We compare our proposed approach to a number of baselines and state-of-the-art methods on four image datasets, and we find that our approach resulted in improved predictive performance.
* 22nd International Conference on Discovery Science, DS 2019
MVLoc: Multimodal Variational Geometry-Aware Learning for Visual Localization
Mar 12, 2020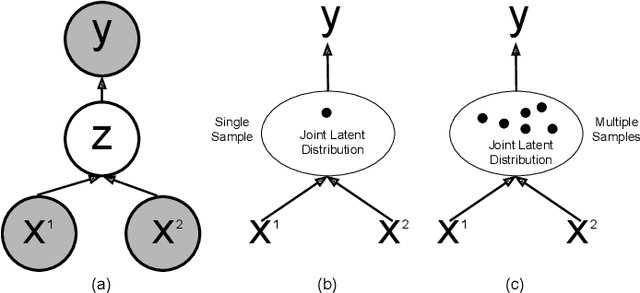
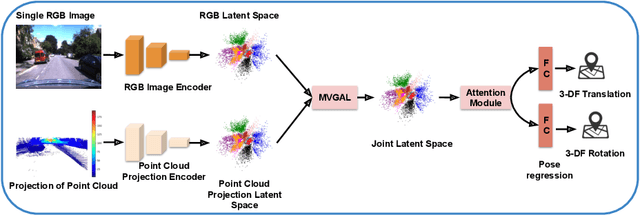
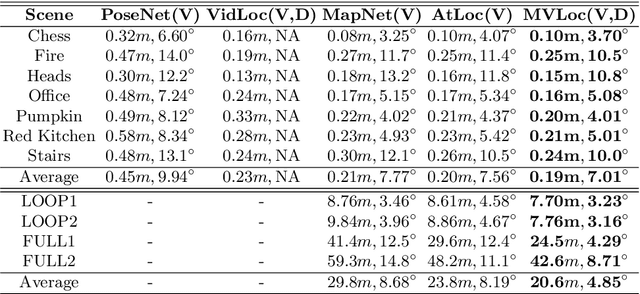
Recent learning-based research has achieved impressive results in the field of single-shot camera relocalization. However, how best to fuse multiple modalities, for example, image and depth, and how to deal with degraded or missing input are less well studied. In particular, we note that previous approaches towards deep fusion do not perform significantly better than models employing a single modality. We conjecture that this is because of the naive approaches to feature space fusion through summation or concatenation which do not take into account the different strengths of each modality, specifically appearance for images and structure for depth. To address this, we propose an end-to-end framework to fuse different sensor inputs through a variational Product-of-Experts (PoE) joint encoder followed by attention-based fusion. Unlike prior work which draws a single sample from the joint encoder, we show how accuracy can be increased through importance sampling and reparameterization of the latent space. Our model is extensively evaluated on RGB-D datasets, outperforming existing baselines by a large margin.
Bayesian convolutional neural network based MRI brain extraction on nonhuman primates
May 18, 2020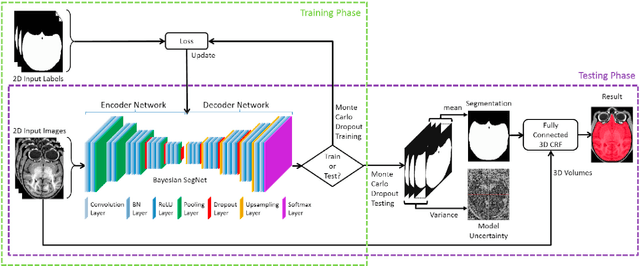
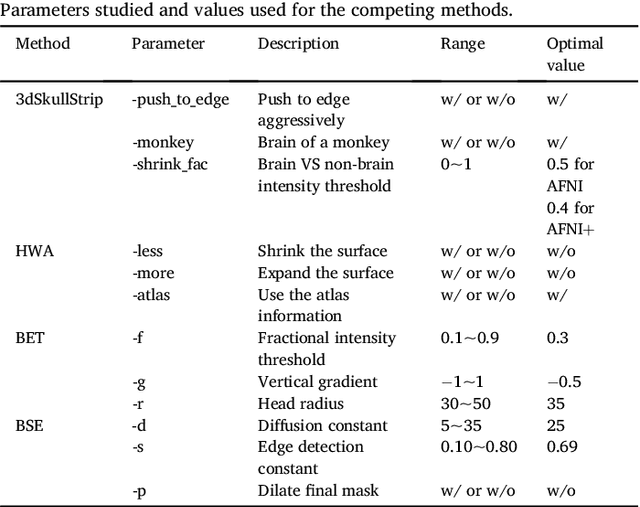
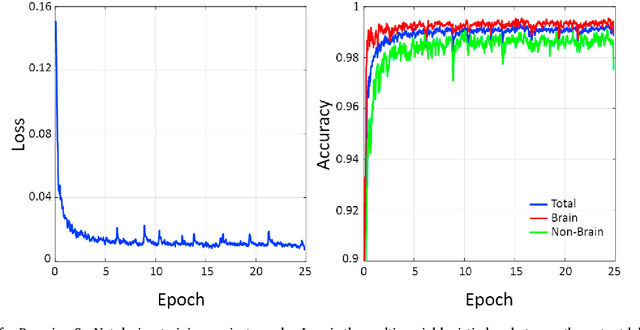
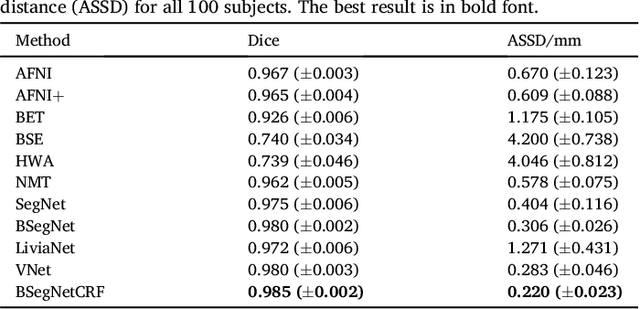
Brain extraction or skull stripping of magnetic resonance images (MRI) is an essential step in neuroimaging studies, the accuracy of which can severely affect subsequent image processing procedures. Current automatic brain extraction methods demonstrate good results on human brains, but are often far from satisfactory on nonhuman primates, which are a necessary part of neuroscience research. To overcome the challenges of brain extraction in nonhuman primates, we propose a fully-automated brain extraction pipeline combining deep Bayesian convolutional neural network (CNN) and fully connected three-dimensional (3D) conditional random field (CRF). The deep Bayesian CNN, Bayesian SegNet, is used as the core segmentation engine. As a probabilistic network, it is not only able to perform accurate high-resolution pixel-wise brain segmentation, but also capable of measuring the model uncertainty by Monte Carlo sampling with dropout in the testing stage. Then, fully connected 3D CRF is used to refine the probability result from Bayesian SegNet in the whole 3D context of the brain volume. The proposed method was evaluated with a manually brain-extracted dataset comprising T1w images of 100 nonhuman primates. Our method outperforms six popular publicly available brain extraction packages and three well-established deep learning based methods with a mean Dice coefficient of 0.985 and a mean average symmetric surface distance of 0.220 mm. A better performance against all the compared methods was verified by statistical tests (all p-values<10-4, two-sided, Bonferroni corrected). The maximum uncertainty of the model on nonhuman primate brain extraction has a mean value of 0.116 across all the 100 subjects...
* 37 pages, 14 figures
Development of a Robotic System for Automatic Wheel Removal and Fitting
Aug 19, 2019
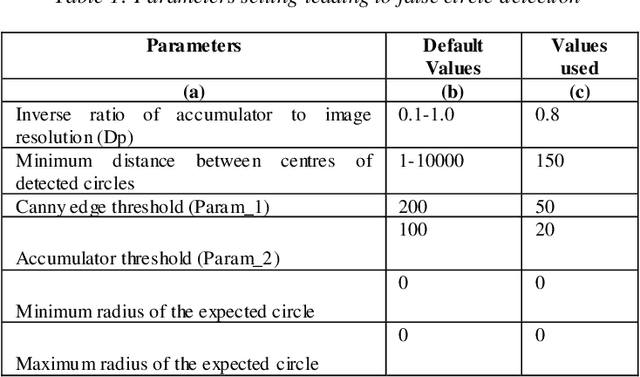
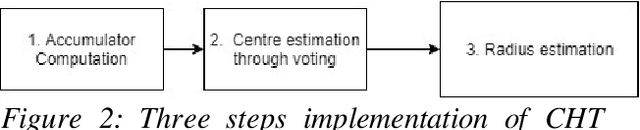
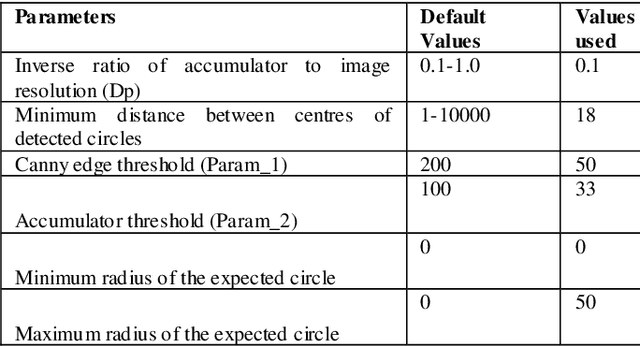
This paper discusses the image processing and computer vision algorithms for real time detection and tracking of a sample wheel of a vehicle. During the manual tyre changing process, spinal and other muscular injuries are common and even more serious injuries have been recorded when occasionally, tyres fail (burst) during this process. It, therefore, follows that the introduction of a robotic system to take over this process would be a welcome development. This work discusses various useful applicable algorithms, Circular Hough Transform (CHT) as well as Continuously adaptive mean shift (Camshift) and provides some of the software solutions which can be deployed with a robotic mechanical arm to make the task of tyre changing faster, safer and more efficient. Image acquisition and software to accurately detect and classify specific objects of interest were implemented successfully, outcomes were discussed and areas for further studies suggested.