 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Coronavirus Detection and Analysis on Chest CT with Deep Learning
Apr 06, 2020
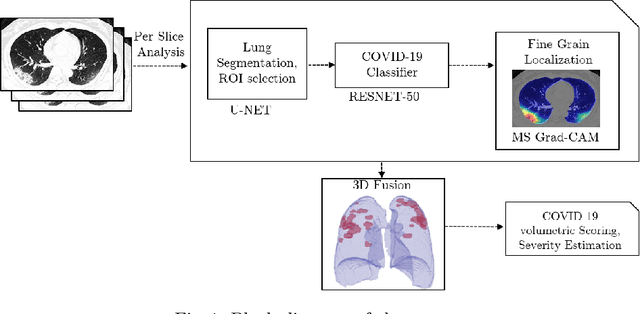


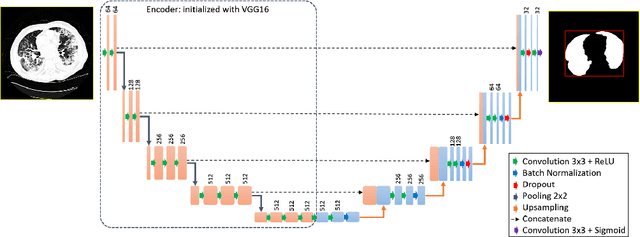
The outbreak of the novel coronavirus, officially declared a global pandemic, has a severe impact on our daily lives. As of this writing there are approximately 197,188 confirmed cases of which 80,881 are in "Mainland China" with 7,949 deaths, a mortality rate of 3.4%. In order to support radiologists in this overwhelming challenge, we develop a deep learning based algorithm that can detect, localize and quantify severity of COVID-19 manifestation from chest CT scans. The algorithm is comprised of a pipeline of image processing algorithms which includes lung segmentation, 2D slice classification and fine grain localization. In order to further understand the manifestations of the disease, we perform unsupervised clustering of abnormal slices. We present our results on a dataset comprised of 110 confirmed COVID-19 patients from Zhejiang province, China.
Guided Super-Resolution as a Learned Pixel-to-Pixel Transformation
Apr 02, 2019
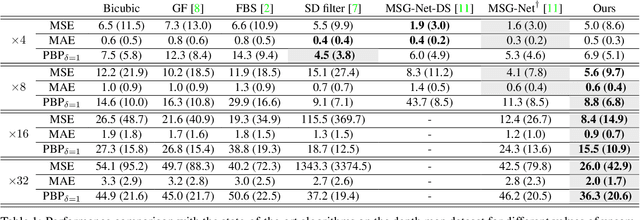
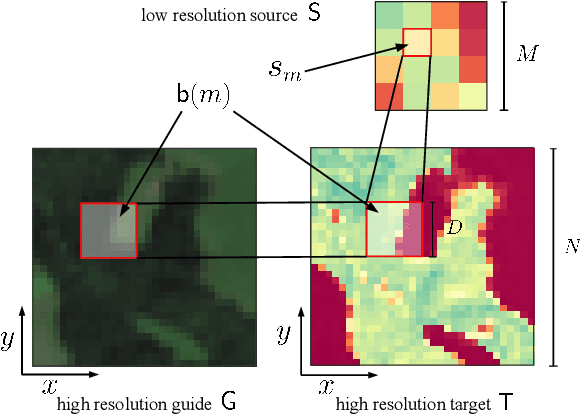
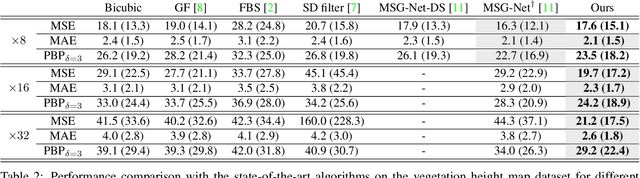
Guided super-resolution is a unifying framework for several computer vision tasks where the inputs are a low-resolution source image of some target quantity (e.g., perspective depth acquired with a time-of-flight camera) and a high-resolution guide image from a different domain (e.g., a gray-scale image from a conventional camera); and the target output is a high-resolution version of the source (in our example, a high-res depth map). The standard way of looking at this problem is to formulate it as a super-resolution task, i.e., the source image is upsampled to the target resolution, while transferring the missing high-frequency details from the guide. Here, we propose to turn that interpretation on its head and instead see it as a pixel-to-pixel mapping of the guide image to the domain of the source image. The pixel-wise mapping is parameterised as a multi-layer perceptron, whose weights are learned by minimising the discrepancies between the source image and the downsampled target image. Importantly, our formulation makes it possible to regularise only the mapping function, while avoiding regularisation of the outputs; Thus producing crisp, natural-looking images. The proposed method is unsupervised, using only the specific source and guide images to fit the mapping. We evaluate our method on two different tasks, super-resolution of depth maps and of tree height maps. In both cases we clearly outperform recent baselines in quantitative comparisons, while delivering visually much sharper outputs.
PDCOVIDNet: A Parallel-Dilated Convolutional Neural Network Architecture for Detecting COVID-19 from Chest X-Ray Images
Jul 29, 2020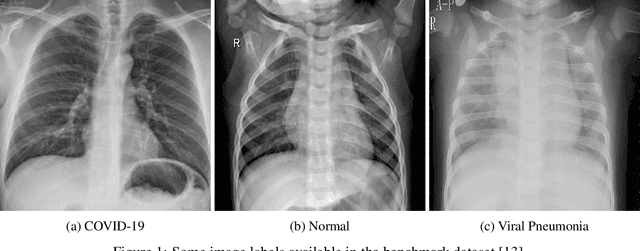

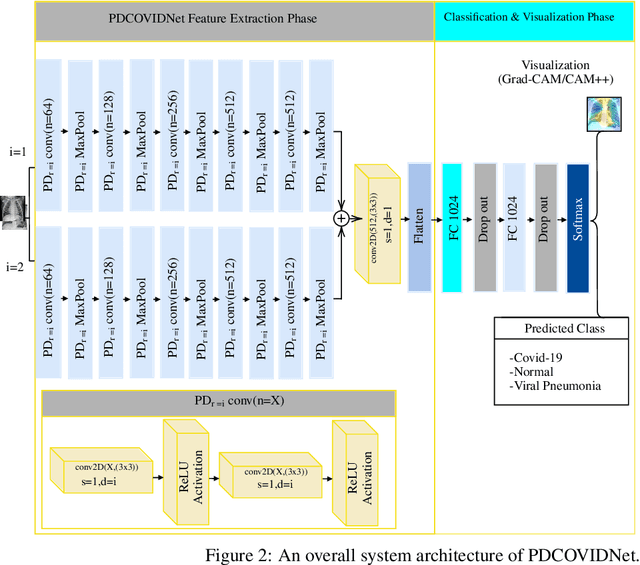
The COVID-19 pandemic continues to severely undermine the prosperity of the global health system. To combat this pandemic, effective screening techniques for infected patients are indispensable. There is no doubt that the use of chest X-ray images for radiological assessment is one of the essential screening techniques. Some of the early studies revealed that the patient's chest X-ray images showed abnormalities, which is natural for patients infected with COVID-19. In this paper, we proposed a parallel-dilated convolutional neural network (CNN) based COVID-19 detection system from chest x-ray images, named as Parallel-Dilated COVIDNet (PDCOVIDNet). First, the publicly available chest X-ray collection fully preloaded and enhanced, and then classified by the proposed method. Differing convolution dilation rate in a parallel form demonstrates the proof-of-principle for using PDCOVIDNet to extract radiological features for COVID-19 detection. Accordingly, we have assisted our method with two visualization methods, which are specifically designed to increase understanding of the key components associated with COVID-19 infection. Both visualization methods compute gradients for a given image category related to feature maps of the last convolutional layer to create a class-discriminative region. In our experiment, we used a total of 2,905 chest X-ray images, comprising three cases (such as COVID-19, normal, and viral pneumonia), and empirical evaluations revealed that the proposed method extracted more significant features expeditiously related to the suspected disease. The experimental results demonstrate that our proposed method significantly improves performance metrics: accuracy, precision, recall, and F1 scores reach 96.58%, 96.58%, 96.59%, and 96.58%, respectively, which is comparable or enhanced compared with the state-of-the-art methods.
APIR-Net: Autocalibrated Parallel Imaging Reconstruction using a Neural Network
Sep 19, 2019



Deep learning has been successfully demonstrated in MRI reconstruction of accelerated acquisitions. However, its dependence on representative training data limits the application across different contrasts, anatomies, or image sizes. To address this limitation, we propose an unsupervised, auto-calibrated k-space completion method, based on a uniquely designed neural network that reconstructs the full k-space from an undersampled k-space, exploiting the redundancy among the multiple channels in the receive coil in a parallel imaging acquisition. To achieve this, contrary to common convolutional network approaches, the proposed network has a decreasing number of feature maps of constant size. In contrast to conventional parallel imaging methods such as GRAPPA that estimate the prediction kernel from the fully sampled autocalibration signals in a linear way, our method is able to learn nonlinear relations between sampled and unsampled positions in k-space. The proposed method was compared to the start-of-the-art ESPIRiT and RAKI methods in terms of noise amplification and visual image quality in both phantom and in-vivo experiments. The experiments indicate that APIR-Net provides a promising alternative to the conventional parallel imaging methods, and results in improved image quality especially for low SNR acquisitions.
Neural Puppet: Generative Layered Cartoon Characters
Oct 04, 2019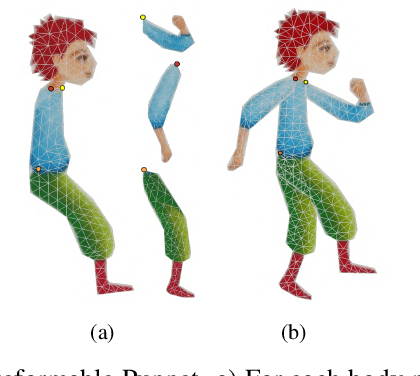
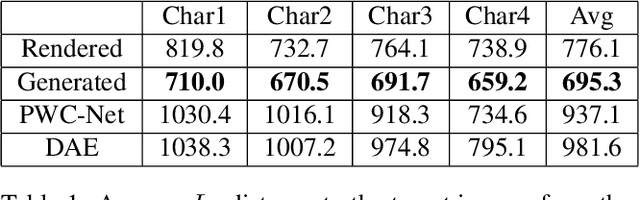
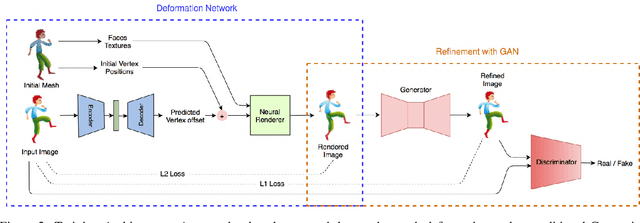
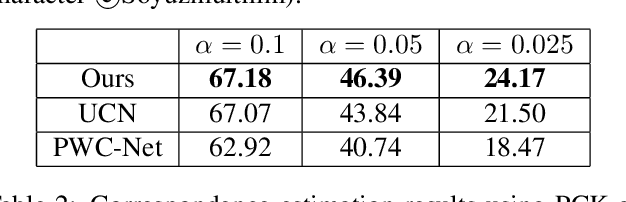
We propose a learning based method for generating new animations of a cartoon character given a few example images. Our method is designed to learn from a traditionally animated sequence, where each frame is drawn by an artist, and thus the input images lack any common structure, correspondences, or labels. We express pose changes as a deformation of a layered 2.5D template mesh, and devise a novel architecture that learns to predict mesh deformations matching the template to a target image. This enables us to extract a common low-dimensional structure from a diverse set of character poses. We combine recent advances in differentiable rendering as well as mesh-aware models to successfully align common template even if only a few character images are available during training. In addition to coarse poses, character appearance also varies due to shading, out-of-plane motions, and artistic effects. We capture these subtle changes by applying an image translation network to refine the mesh rendering, providing an end-to-end model to generate new animations of a character with high visual quality. We demonstrate that our generative model can be used to synthesize in-between frames and to create data-driven deformation. Our template fitting procedure outperforms state-of-the-art generic techniques for detecting image correspondences.
Meta-Learning without Memorization
Dec 09, 2019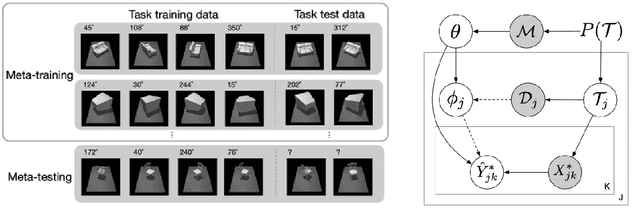

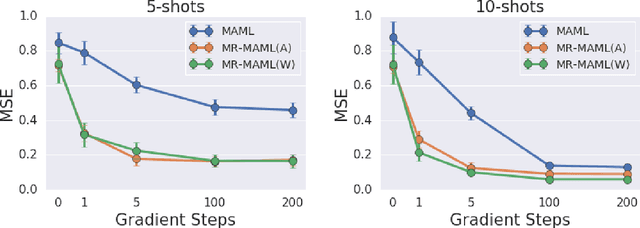

The ability to learn new concepts with small amounts of data is a critical aspect of intelligence that has proven challenging for deep learning methods. Meta-learning has emerged as a promising technique for leveraging data from previous tasks to enable efficient learning of new tasks. However, most meta-learning algorithms implicitly require that the meta-training tasks be mutually-exclusive, such that no single model can solve all of the tasks at once. For example, when creating tasks for few-shot image classification, prior work uses a per-task random assignment of image classes to N-way classification labels. If this is not done, the meta-learner can ignore the task training data and learn a single model that performs all of the meta-training tasks zero-shot, but does not adapt effectively to new image classes. This requirement means that the user must take great care in designing the tasks, for example by shuffling labels or removing task identifying information from the inputs. In some domains, this makes meta-learning entirely inapplicable. In this paper, we address this challenge by designing a meta-regularization objective using information theory that places precedence on data-driven adaptation. This causes the meta-learner to decide what must be learned from the task training data and what should be inferred from the task testing input. By doing so, our algorithm can successfully use data from non-mutually-exclusive tasks to efficiently adapt to novel tasks. We demonstrate its applicability to both contextual and gradient-based meta-learning algorithms, and apply it in practical settings where applying standard meta-learning has been difficult. Our approach substantially outperforms standard meta-learning algorithms in these settings.
1st Place Solution for Waymo Open Dataset Challenge - 3D Detection and Domain Adaptation
Jun 28, 2020
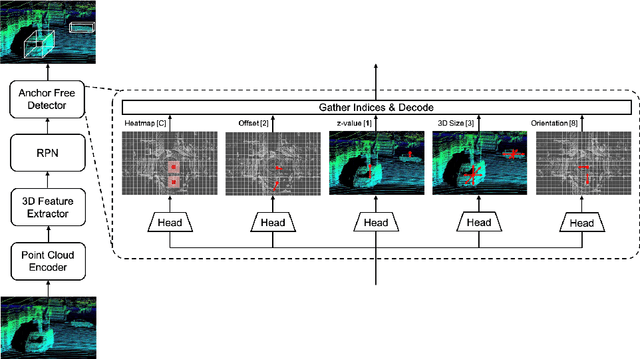
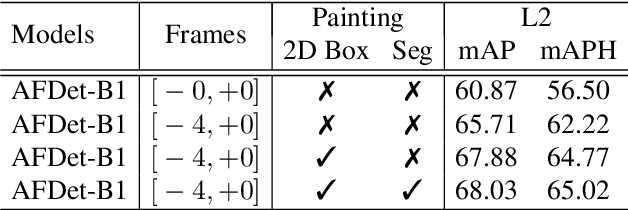
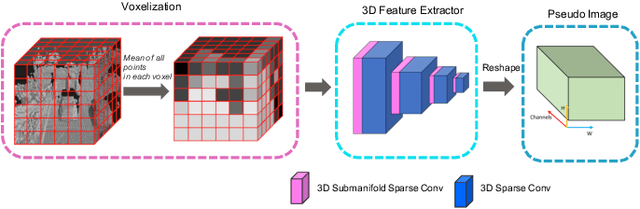
In this technical report, we introduce our winning solution "HorizonLiDAR3D" for the 3D detection track and the domain adaptation track in Waymo Open Dataset Challenge at CVPR 2020. Many existing 3D object detectors include prior-based anchor box design to account for different scales and aspect ratios and classes of objects, which limits its capability of generalization to a different dataset or domain and requires post-processing (e.g. Non-Maximum Suppression (NMS)). We proposed a one-stage, anchor-free and NMS-free 3D point cloud object detector AFDet, using object key-points to encode the 3D attributes, and to learn an end-to-end point cloud object detection without the need of hand-engineering or learning the anchors. AFDet serves as a strong baseline in our winning solution and significant improvements are made over this baseline during the challenges. Specifically, we design stronger networks and enhance the point cloud data using densification and point painting. To leverage camera information, we append/paint additional attributes to each point by projecting them to camera space and gathering image-based perception information. The final detection performance also benefits from model ensemble and Test-Time Augmentation (TTA) in both the 3D detection track and the domain adaptation track. Our solution achieves the 1st place with 77.11% mAPH/L2 and 69.49% mAPH/L2 respectively on the 3D detection track and the domain adaptation track.
Geometric algorithms for predicting resilience and recovering damage in neural networks
Jun 02, 2020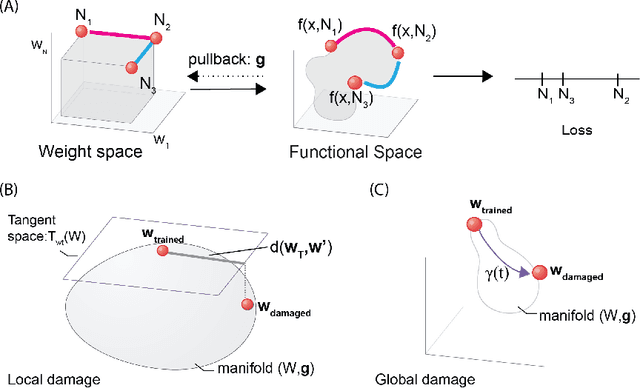
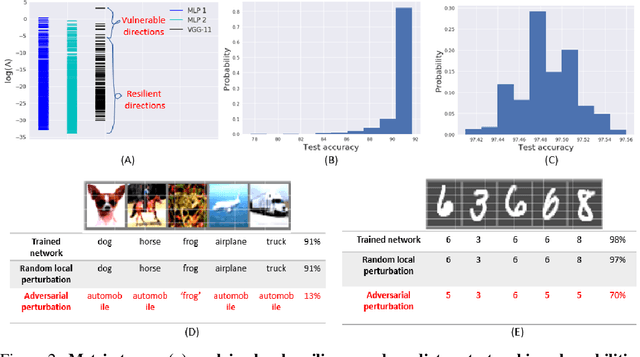
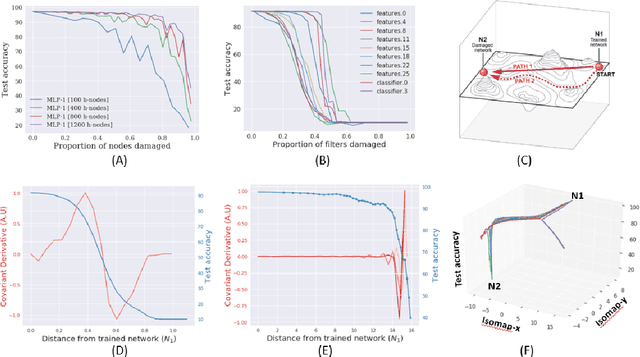
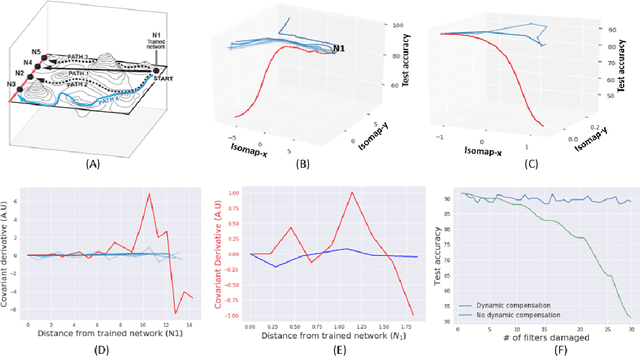
Biological neural networks have evolved to maintain performance despite significant circuit damage. To survive damage, biological network architectures have both intrinsic resilience to component loss and also activate recovery programs that adjust network weights through plasticity to stabilize performance. Despite the importance of resilience in technology applications, the resilience of artificial neural networks is poorly understood, and autonomous recovery algorithms have yet to be developed. In this paper, we establish a mathematical framework to analyze the resilience of artificial neural networks through the lens of differential geometry. Our geometric language provides natural algorithms that identify local vulnerabilities in trained networks as well as recovery algorithms that dynamically adjust networks to compensate for damage. We reveal striking vulnerabilities in commonly used image analysis networks, like MLP's and CNN's trained on MNIST and CIFAR10 respectively. We also uncover high-performance recovery paths that enable the same networks to dynamically re-adjust their parameters to compensate for damage. Broadly, our work provides procedures that endow artificial systems with resilience and rapid-recovery routines to enhance their integration with IoT devices as well as enable their deployment for critical applications.
Evolving Fuzzy Image Segmentation with Self-Configuration
Apr 23, 2015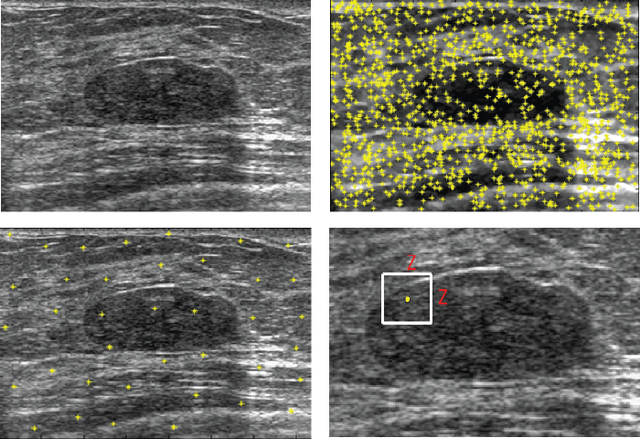

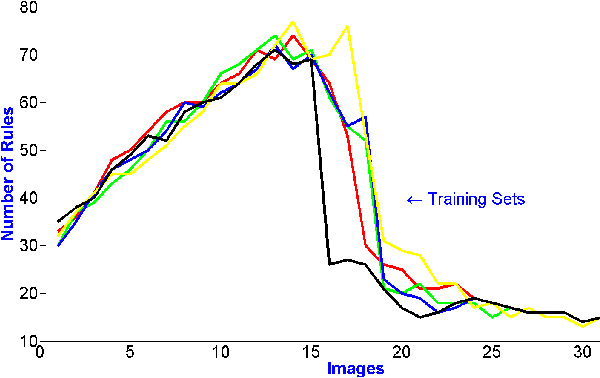
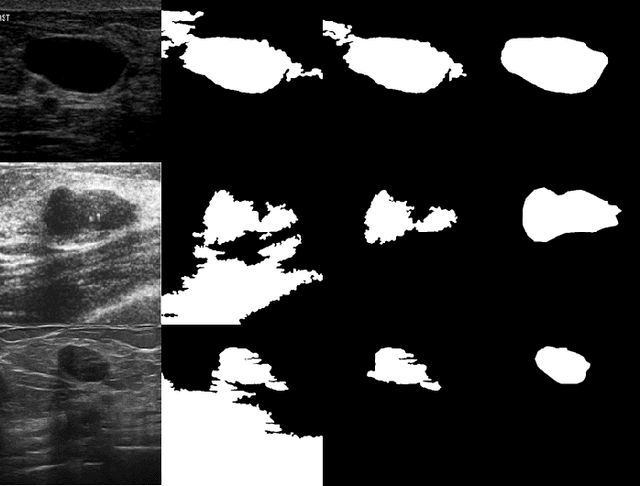
Current image segmentation techniques usually require that the user tune several parameters in order to obtain maximum segmentation accuracy, a computationally inefficient approach, especially when a large number of images must be processed sequentially in daily practice. The use of evolving fuzzy systems for designing a method that automatically adjusts parameters to segment medical images according to the quality expectation of expert users has been proposed recently (Evolving fuzzy image segmentation EFIS). However, EFIS suffers from a few limitations when used in practice mainly due to some fixed parameters. For instance, EFIS depends on auto-detection of the object of interest for feature calculation, a task that is highly application-dependent. This shortcoming limits the applicability of EFIS, which was proposed with the ultimate goal of offering a generic but adjustable segmentation scheme. In this paper, a new version of EFIS is proposed to overcome these limitations. The new EFIS, called self-configuring EFIS (SC-EFIS), uses available training data to self-estimate the parameters that are fixed in EFIS. As well, the proposed SC-EFIS relies on a feature selection process that does not require auto-detection of an ROI. The proposed SC-EFIS was evaluated using the same segmentation algorithms and the same dataset as for EFIS. The results show that SC-EFIS can provide the same results as EFIS but with a higher level of automation.
Field of View Extension in Computed Tomography Using Deep Learning Prior
Dec 09, 2019
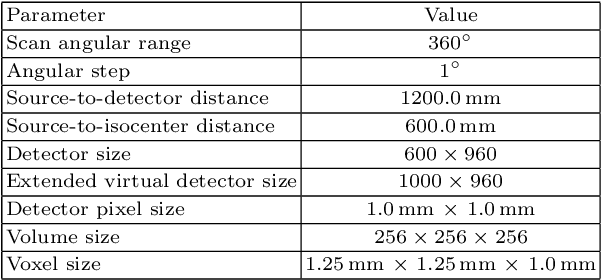
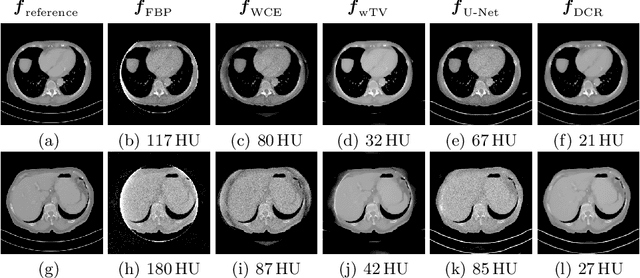
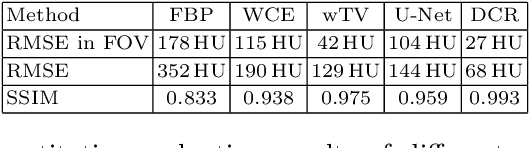
In computed tomography (CT), data truncation is a common problem. Images reconstructed by the standard filtered back-projection algorithm from truncated data suffer from cupping artifacts inside the field-of-view (FOV), while anatomical structures are severely distorted or missing outside the FOV. Deep learning, particularly the U-Net, has been applied to extend the FOV as a post-processing method. Since image-to-image prediction neglects the data fidelity to measured projection data, incorrect structures, even inside the FOV, might be reconstructed by such an approach. Therefore, generating reconstructed images directly from a post-processing neural network is inadequate. In this work, we propose a data consistent reconstruction method, which utilizes deep learning reconstruction as prior for extrapolating truncated projections and a conventional iterative reconstruction to constrain the reconstruction consistent to measured raw data. Its efficacy is demonstrated in our study, achieving small average root-mean-square error of 24 HU inside the FOV and a high structure similarity index of 0.993 for the whole body area on a test patient's CT data.