 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Residual Spatial Attention Network for Retinal Vessel Segmentation
Sep 18, 2020
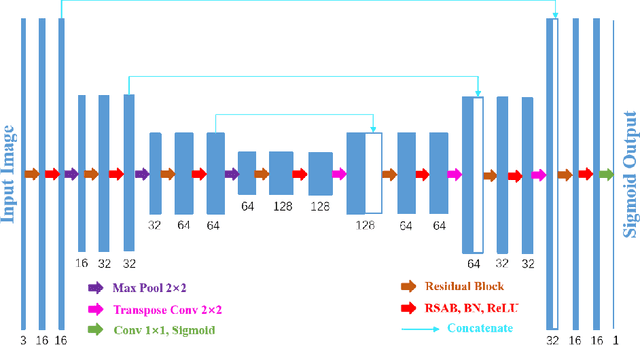
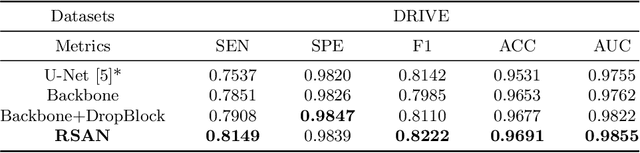
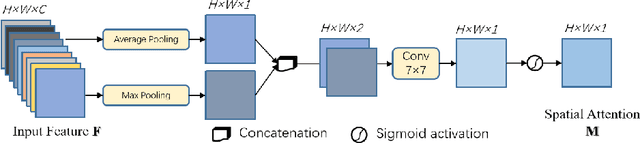
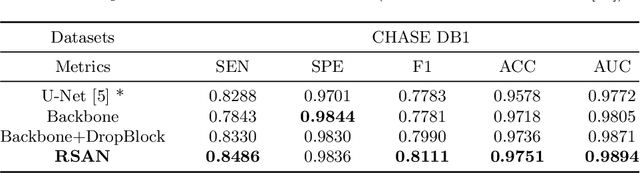
Reliable segmentation of retinal vessels can be employed as a way of monitoring and diagnosing certain diseases, such as diabetes and hypertension, as they affect the retinal vascular structure. In this work, we propose the Residual Spatial Attention Network (RSAN) for retinal vessel segmentation. RSAN employs a modified residual block structure that integrates DropBlock, which can not only be utilized to construct deep networks to extract more complex vascular features, but can also effectively alleviate the overfitting. Moreover, in order to further improve the representation capability of the network, based on this modified residual block, we introduce the spatial attention (SA) and propose the Residual Spatial Attention Block (RSAB) to build RSAN. We adopt the public DRIVE and CHASE DB1 color fundus image datasets to evaluate the proposed RSAN. Experiments show that the modified residual structure and the spatial attention are effective in this work, and our proposed RSAN achieves the state-of-the-art performance.
Multiscale Detection of Cancerous Tissue in High Resolution Slide Scans
Oct 01, 2020
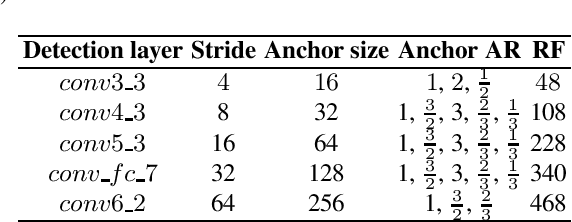


We present an algorithm for multi-scale tumor (chimeric cell) detection in high resolution slide scans. The broad range of tumor sizes in our dataset pose a challenge for current Convolutional Neural Networks (CNN) which often fail when image features are very small (8 pixels). Our approach modifies the effective receptive field at different layers in a CNN so that objects with a broad range of varying scales can be detected in a single forward pass. We define rules for computing adaptive prior anchor boxes which we show are solvable under the equal proportion interval principle. Two mechanisms in our CNN architecture alleviate the effects of non-discriminative features prevalent in our data - a foveal detection algorithm that incorporates a cascade residual-inception module and a deconvolution module with additional context information. When integrated into a Single Shot MultiBox Detector (SSD), these additions permit more accurate detection of small-scale objects. The results permit efficient real-time analysis of medical images in pathology and related biomedical research fields.
Generating Efficient DNN-Ensembles with Evolutionary Computation
Sep 18, 2020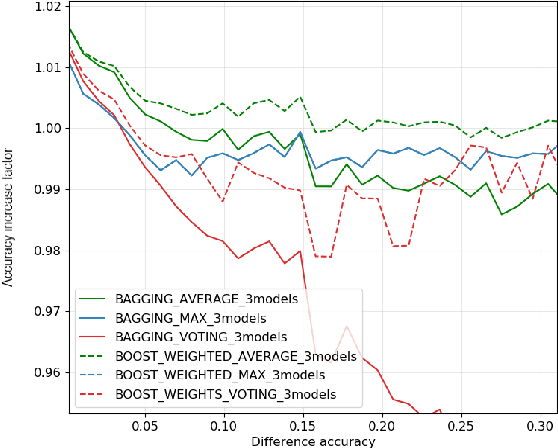
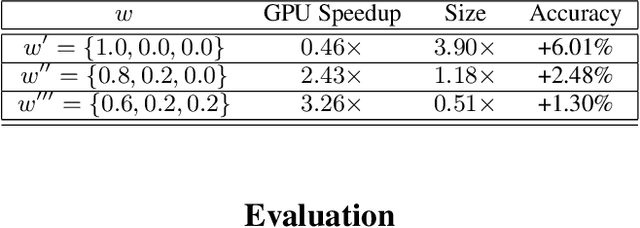
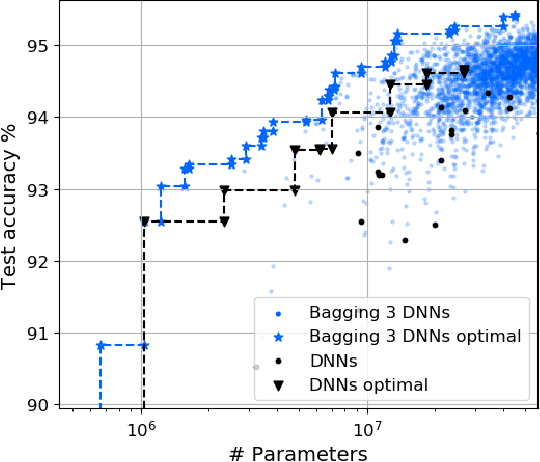
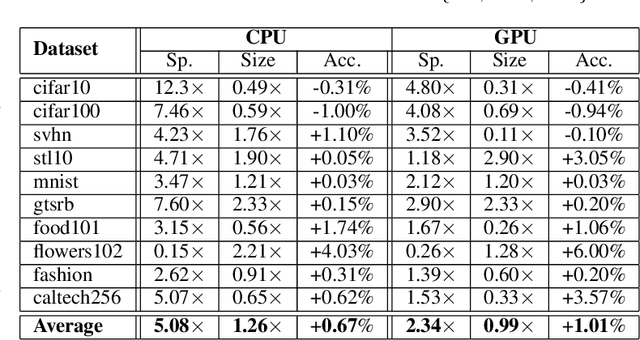
In this work, we leverage ensemble learning as a tool for the creation of faster, smaller, and more accurate deep learning models. We demonstrate that we can jointly optimize for accuracy, inference time, and the number of parameters by combining DNN classifiers. To achieve this, we combine multiple ensemble strategies: bagging, boosting, and an ordered chain of classifiers. To reduce the number of DNN ensemble evaluations during the search, we propose EARN, an evolutionary approach that optimizes the ensemble according to three objectives regarding the constraints specified by the user. We run EARN on 10 image classification datasets with an initial pool of 32 state-of-the-art DCNN on both CPU and GPU platforms, and we generate models with speedups up to $7.60\times$, reductions of parameters by $10\times$, or increases in accuracy up to $6.01\%$ regarding the best DNN in the pool. In addition, our method generates models that are $5.6\times$ faster than the state-of-the-art methods for automatic model generation.
Searching for Low-Bit Weights in Quantized Neural Networks
Sep 18, 2020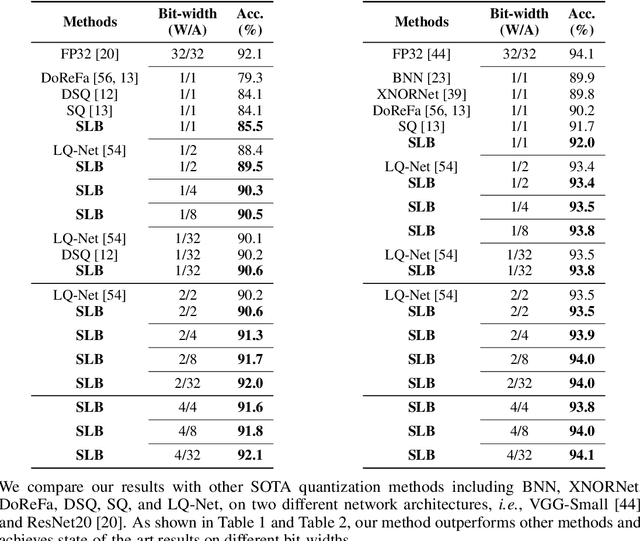
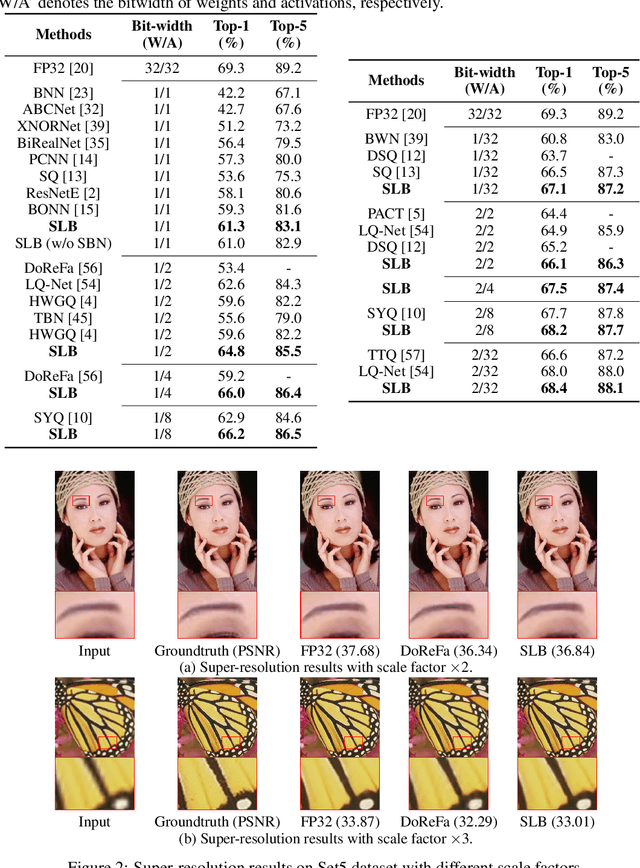
Quantized neural networks with low-bit weights and activations are attractive for developing AI accelerators. However, the quantization functions used in most conventional quantization methods are non-differentiable, which increases the optimization difficulty of quantized networks. Compared with full-precision parameters (i.e., 32-bit floating numbers), low-bit values are selected from a much smaller set. For example, there are only 16 possibilities in 4-bit space. Thus, we present to regard the discrete weights in an arbitrary quantized neural network as searchable variables, and utilize a differential method to search them accurately. In particular, each weight is represented as a probability distribution over the discrete value set. The probabilities are optimized during training and the values with the highest probability are selected to establish the desired quantized network. Experimental results on benchmarks demonstrate that the proposed method is able to produce quantized neural networks with higher performance over the state-of-the-art methods on both image classification and super-resolution tasks.
Deep-CAPTCHA: a deep learning based CAPTCHA solver for vulnerability assessment
Jun 15, 2020

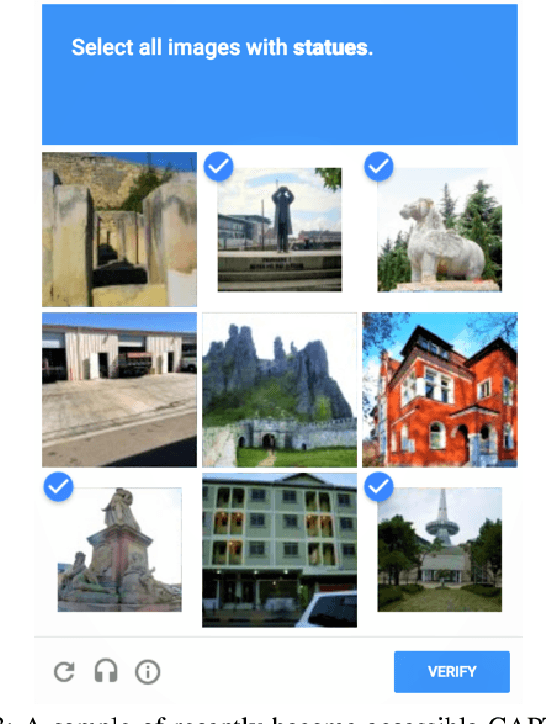
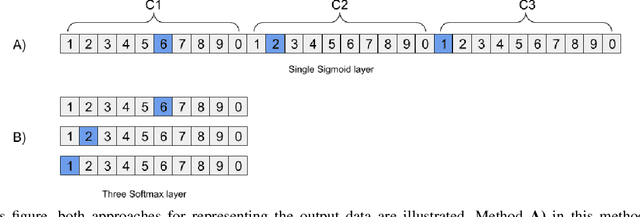
CAPTCHA is a human-centred test to distinguish a human operator from bots, attacking programs, or any other computerised agent that tries to imitate human intelligence. In this research, we investigate a way to crack visual CAPTCHA tests by an automated deep learning based solution. The goal of the cracking is to investigate the weaknesses and vulnerabilities of the CAPTCHA generators and to develop more robust CAPTCHAs, without taking the risks of manual try and error efforts. We have developed a Convolutional Neural Network called \Deep-CAPTCHA to achieve this goal. We propose a platform to investigate both numerical and alphanumerical image CAPTCHAs. To train and develop an efficient model, we have generated 500,000 CAPTCHAs using Python Image-Captcha Library. In this paper, we present our customised deep neural network model, the research gaps and the existing challenges, and the solutions to overcome the issues. Our network's cracking accuracy results leads to 98.94\% and 98.31\% for the numerical and the alpha-numerical Test datasets, respectively. That means more works need to be done to develop robust CAPTCHAs, to be non-crackable against bot attaches and artificial agents. As the outcome of this research, we identify some efficient techniques to improve the CAPTCHA generators, based on the performance analysis conducted on the Deep-CAPTCHA model.
Multi-task Supervised Learning via Cross-learning
Oct 24, 2020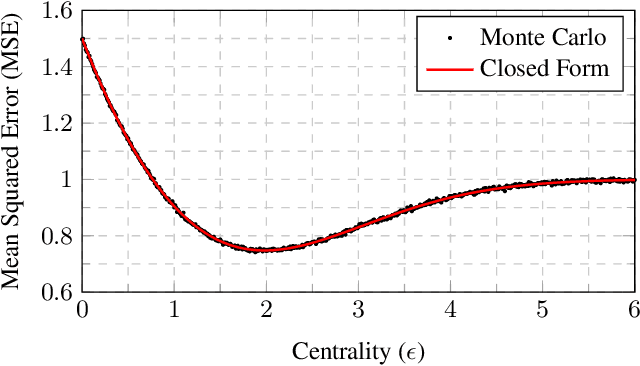

In this paper we consider a problem known as multi-task learning, consisting of fitting a set of classifier or regression functions intended for solving different tasks. In our novel formulation, we couple the parameters of these functions, so that they learn in their task specific domains while staying close to each other. This facilitates cross-fertilization in which data collected across different domains help improving the learning performance at each other task. First, we present a simplified case in which the goal is to estimate the means of two Gaussian variables, for the purpose of gaining some insights on the advantage of the proposed cross-learning strategy. Then we provide a stochastic projected gradient algorithm to perform cross-learning over a generic loss function. If the number of parameters is large, then the projection step becomes computationally expensive. To avoid this situation, we derive a primal-dual algorithm that exploits the structure of the dual problem, achieving a formulation whose complexity only depends on the number of tasks. Preliminary numerical experiments for image classification by neural networks trained on a dataset divided in different domains corroborate that the cross-learned function outperforms both the task-specific and the consensus approaches.
Semi Few-Shot Attribute Translation
Oct 16, 2019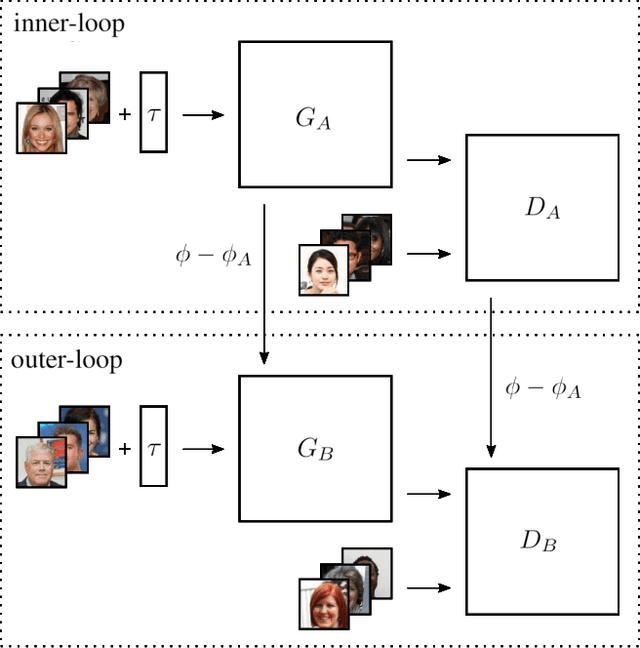
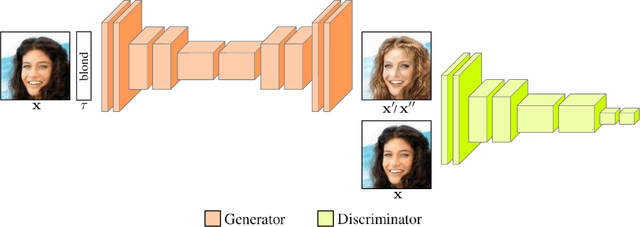


Recent studies have shown remarkable success in image-to-image translation for attribute transfer applications. However, most of existing approaches are based on deep learning and require an abundant amount of labeled data to produce good results, therefore limiting their applicability. In the same vein, recent advances in meta-learning have led to successful implementations with limited available data, allowing so-called few-shot learning. In this paper, we address this limitation of supervised methods, by proposing a novel approach based on GANs. These are trained in a meta-training manner, which allows them to perform image-to-image translations using just a few labeled samples from a new target class. This work empirically demonstrates the potential of training a GAN for few shot image-to-image translation on hair color attribute synthesis tasks, opening the door to further research on generative transfer learning.
MUTANT: A Training Paradigm for Out-of-Distribution Generalization in Visual Question Answering
Sep 18, 2020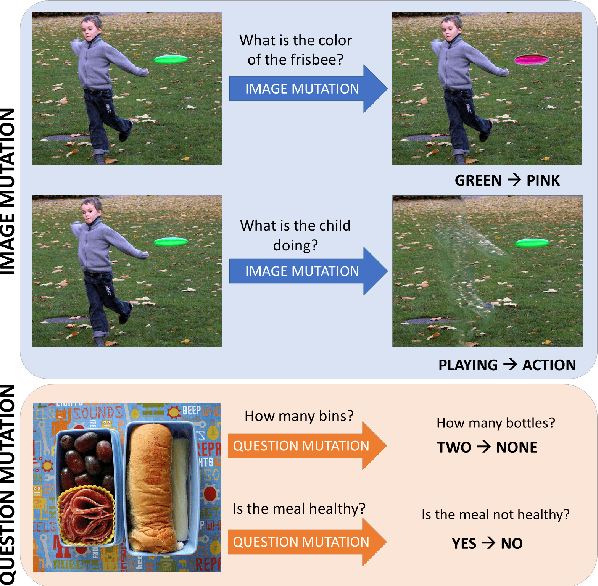
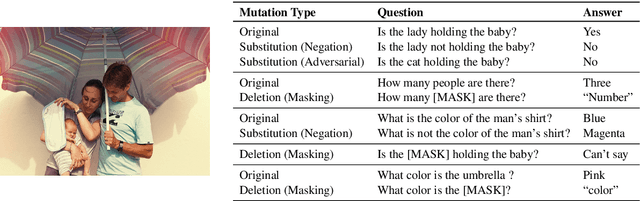
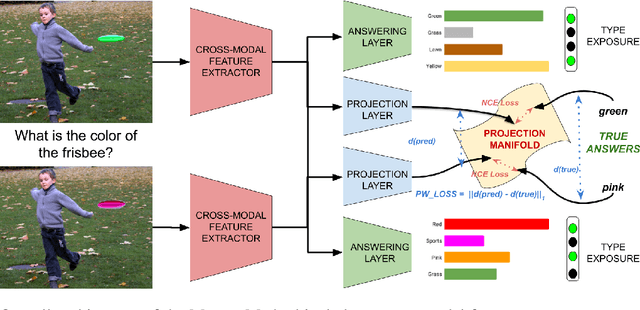

While progress has been made on the visual question answering leaderboards, models often utilize spurious correlations and priors in datasets under the i.i.d. setting. As such, evaluation on out-of-distribution (OOD) test samples has emerged as a proxy for generalization. In this paper, we present \textit{MUTANT}, a training paradigm that exposes the model to perceptually similar, yet semantically distinct \textit{mutations} of the input, to improve OOD generalization, such as the VQA-CP challenge. Under this paradigm, models utilize a consistency-constrained training objective to understand the effect of semantic changes in input (question-image pair) on the output (answer). Unlike existing methods on VQA-CP, \textit{MUTANT} does not rely on the knowledge about the nature of train and test answer distributions. \textit{MUTANT} establishes a new state-of-the-art accuracy on VQA-CP with a $10.57\%$ improvement. Our work opens up avenues for the use of semantic input mutations for OOD generalization in question answering.
Manifold-driven Attention Maps for Weakly Supervised Segmentation
Apr 07, 2020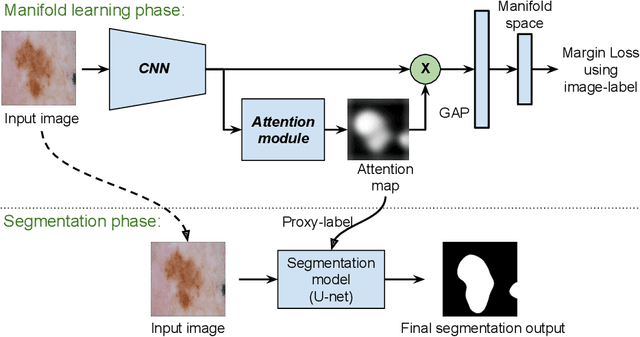
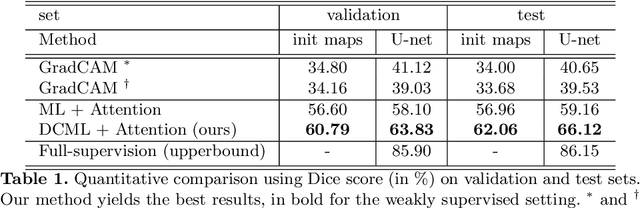
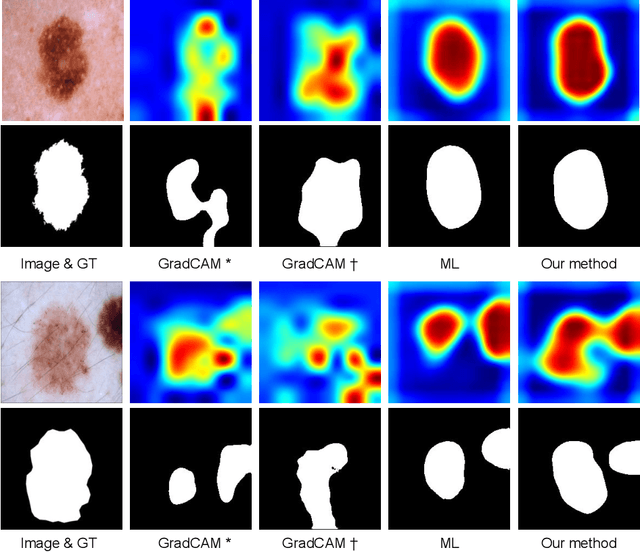
Segmentation using deep learning has shown promising directions in medical imaging as it aids in the analysis and diagnosis of diseases. Nevertheless, a main drawback of deep models is that they require a large amount of pixel-level labels, which are laborious and expensive to obtain. To mitigate this problem, weakly supervised learning has emerged as an efficient alternative, which employs image-level labels, scribbles, points, or bounding boxes as supervision. Among these, image-level labels are easier to obtain. However, since this type of annotation only contains object category information, the segmentation task under this learning paradigm is a challenging problem. To address this issue, visual salient regions derived from trained classification networks are typically used. Despite their success to identify important regions on classification tasks, these saliency regions only focus on the most discriminant areas of an image, limiting their use in semantic segmentation. In this work, we propose a manifold driven attention-based network to enhance visual salient regions, thereby improving segmentation accuracy in a weakly supervised setting. Our method generates superior attention maps directly during inference without the need of extra computations. We evaluate the benefits of our approach in the task of segmentation using a public benchmark on skin lesion images. Results demonstrate that our method outperforms the state-of-the-art GradCAM by a margin of ~22% in terms of Dice score.
Growing Efficient Deep Networks by Structured Continuous Sparsification
Jul 30, 2020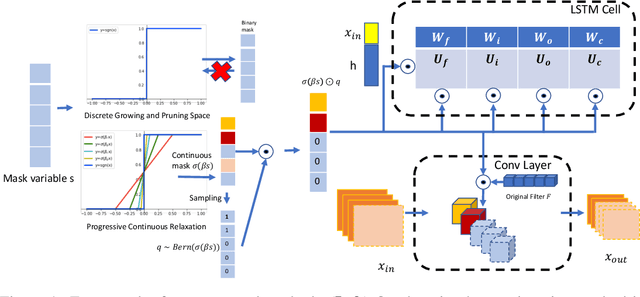
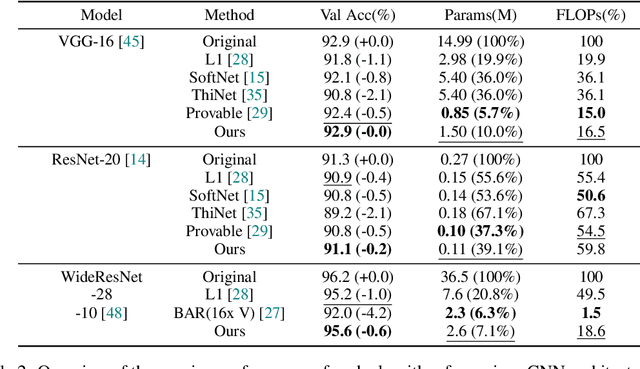
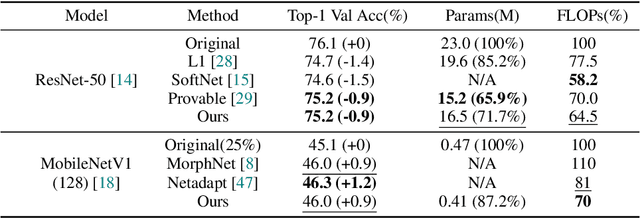
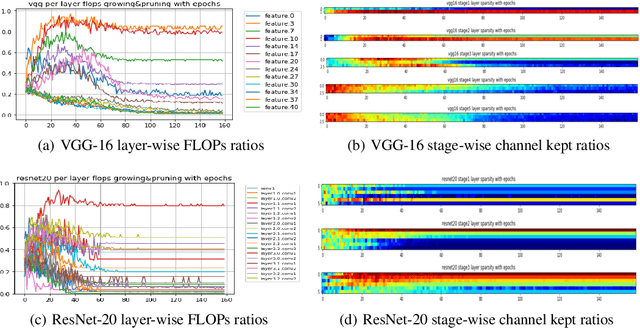
We develop an approach to training deep networks while dynamically adjusting their architecture, driven by a principled combination of accuracy and sparsity objectives. Unlike conventional pruning approaches, our method adopts a gradual continuous relaxation of discrete network structure optimization and then samples sparse subnetworks, enabling efficient deep networks to be trained in a growing and pruning manner. Extensive experiments across CIFAR-10, ImageNet, PASCAL VOC, and Penn Treebank, with convolutional models for image classification and semantic segmentation, and recurrent models for language modeling, show that our training scheme yields efficient networks that are smaller and more accurate than those produced by competing pruning methods.