 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Prompting Meets Feature Reconstruction-Based Anomaly Detection with Dual-Teacher Supervision
Jun 08, 2026Recent Anomaly Detection methods achieve perfect detection and segmentation scores on well-established datasets, such as MVTec. However, many of these methods face challenges when foundational assumptions - such as consistent object scale, viewpoint, background, illumination, and centered placement - are violated. Those variations that occur render anomaly detection methods unusable in many real-world scenarios. To address these limitations, we introduce three key contributions: (1) a visual prompting pipeline that isolates objects using foreground-background masking; (2) a mechanism for unfreezing the teacher in student-teacher models to improve domain adaptability; and (3) a data augmentation strategy leveraging diffusion-generated synthetic images to enhance anomaly detection performance. We achieve a 3.5 percentage point improvement over the previous state-of-the-art on the challenging AeBAD dataset by using the Masked Multiscale Reconstruction (MMR) model as our backbone.
Cracks in the Foundation: A Civil Infrastructure Dataset to Challenge Vision Foundation Models
May 19, 2026Automated structural health monitoring is essential to prevent catastrophic infrastructure failures. Precise, pixel-level defect segmentation is needed to accurately assess structural integrity, but progress in defect segmentation for civil infrastructures has been held back by an extreme scarcity of data, which requires costly expert annotation. The need for data is accentuated by algorithmic hurdles intrinsic to the problem, including center-bias and the need to rely more on shape when inspecting nearly textureless building materials. To remove the bottleneck, we introduce Cracks in the Foundation (CiF), the largest and most detailed civil infrastructure (instance) segmentation dataset to date, comprising $\approx$150,000 high-resolution images meticulously curated over five years in collaboration with civil engineering experts. With the help of this unprecedented data source, we expose a blind spot of current visual AI: despite the advent of promptable Foundation Models (FMs) and Vision Language Models (VLMs), and despite the impressive abilities of today's specialised segmentation models, it turns out that dense image understanding in the built environment is nowhere near solved. Our evaluations indicate that even the most recent zero-shot FMs face significant challenges when deployed on real-world infrastructure and even the performance of specialised models with domain-specific supervision plateaus at $\approx$25% mAP. CiF establishes inspection of civil infrastructure, an elementary and seemingly easy perceptual task, as an open challenge that reveals fundamental weaknesses of present-day models trained predominantly on internet images, literally and figuratively highlighting cracks in the current foundation model paradigm.
ChartNet: A Million-Scale, High-Quality Multimodal Dataset for Robust Chart Understanding
Mar 28, 2026Understanding charts requires models to jointly reason over geometric visual patterns, structured numerical data, and natural language -- a capability where current vision-language models (VLMs) remain limited. We introduce ChartNet, a high-quality, million-scale multimodal dataset designed to advance chart interpretation and reasoning. ChartNet leverages a novel code-guided synthesis pipeline to generate 1.5 million diverse chart samples spanning 24 chart types and 6 plotting libraries. Each sample consists of five aligned components: plotting code, rendered chart image, data table, natural language summary, and question-answering with reasoning, providing fine-grained cross-modal alignment. To capture the full spectrum of chart comprehension, ChartNet additionally includes specialized subsets encompassing human annotated data, real-world data, safety, and grounding. Moreover, a rigorous quality-filtering pipeline ensures visual fidelity, semantic accuracy, and diversity across chart representations. Fine-tuning on ChartNet consistently improves results across benchmarks, demonstrating its utility as large-scale supervision for multimodal models. As the largest open-source dataset of its kind, ChartNet aims to support the development of foundation models with robust and generalizable capabilities for data visualization understanding. The dataset is publicly available at https://huggingface.co/datasets/ibm-granite/ChartNet
Q-SAM2: Accurate Quantization for Segment Anything Model 2
Jun 11, 2025The Segment Anything Model 2 (SAM2) has gained significant attention as a foundational approach for promptable image and video segmentation. However, its expensive computational and memory consumption poses a severe challenge for its application in resource-constrained scenarios. In this paper, we propose an accurate low-bit quantization method for efficient SAM2, termed Q-SAM2. To address the performance degradation caused by the singularities in weight and activation distributions during quantization, Q-SAM2 introduces two novel technical contributions. We first introduce a linear layer calibration method for low-bit initialization of SAM2, which minimizes the Frobenius norm over a small image batch to reposition weight distributions for improved quantization. We then propose a Quantization-Aware Training (QAT) pipeline that applies clipping to suppress outliers and allows the network to adapt to quantization thresholds during training. Our comprehensive experiments demonstrate that Q-SAM2 allows for highly accurate inference while substantially improving efficiency. Both quantitative and visual results show that our Q-SAM2 surpasses existing state-of-the-art general quantization schemes, especially for ultra-low 2-bit quantization. While designed for quantization-aware training, our proposed calibration technique also proves effective in post-training quantization, achieving up to a 66% mIoU accuracy improvement over non-calibrated models.
VP Lab: a PEFT-Enabled Visual Prompting Laboratory for Semantic Segmentation
May 21, 2025Large-scale pretrained vision backbones have transformed computer vision by providing powerful feature extractors that enable various downstream tasks, including training-free approaches like visual prompting for semantic segmentation. Despite their success in generic scenarios, these models often fall short when applied to specialized technical domains where the visual features differ significantly from their training distribution. To bridge this gap, we introduce VP Lab, a comprehensive iterative framework that enhances visual prompting for robust segmentation model development. At the core of VP Lab lies E-PEFT, a novel ensemble of parameter-efficient fine-tuning techniques specifically designed to adapt our visual prompting pipeline to specific domains in a manner that is both parameter- and data-efficient. Our approach not only surpasses the state-of-the-art in parameter-efficient fine-tuning for the Segment Anything Model (SAM), but also facilitates an interactive, near-real-time loop, allowing users to observe progressively improving results as they experiment within the framework. By integrating E-PEFT with visual prompting, we demonstrate a remarkable 50\% increase in semantic segmentation mIoU performance across various technical datasets using only 5 validated images, establishing a new paradigm for fast, efficient, and interactive model deployment in new, challenging domains. This work comes in the form of a demonstration.
Counterfactual Image Generation for adversarially robust and interpretable Classifiers
Oct 01, 2023



Neural Image Classifiers are effective but inherently hard to interpret and susceptible to adversarial attacks. Solutions to both problems exist, among others, in the form of counterfactual examples generation to enhance explainability or adversarially augment training datasets for improved robustness. However, existing methods exclusively address only one of the issues. We propose a unified framework leveraging image-to-image translation Generative Adversarial Networks (GANs) to produce counterfactual samples that highlight salient regions for interpretability and act as adversarial samples to augment the dataset for more robustness. This is achieved by combining the classifier and discriminator into a single model that attributes real images to their respective classes and flags generated images as "fake". We assess the method's effectiveness by evaluating (i) the produced explainability masks on a semantic segmentation task for concrete cracks and (ii) the model's resilience against the Projected Gradient Descent (PGD) attack on a fruit defects detection problem. Our produced saliency maps are highly descriptive, achieving competitive IoU values compared to classical segmentation models despite being trained exclusively on classification labels. Furthermore, the model exhibits improved robustness to adversarial attacks, and we show how the discriminator's "fakeness" value serves as an uncertainty measure of the predictions.
MAEDAY: MAE for few and zero shot AnomalY-Detection
Nov 25, 2022



The goal of Anomaly-Detection (AD) is to identify outliers, or outlying regions, from some unknown distribution given only a set of positive (good) examples. Few-Shot AD (FSAD) aims to solve the same task with a minimal amount of normal examples. Recent embedding-based methods, that compare the embedding vectors of queries to a set of reference embeddings, have demonstrated impressive results for FSAD, where as little as one good example is provided. A different approach, image-reconstruction-based, has been historically used for AD. The idea is to train a model to recover normal images from corrupted observations, assuming that the model will fail to recover regions when encountered with an out-of-distribution image. However, image-reconstruction-based methods were not yet used in the low-shot regime as they need to be trained on a diverse set of normal images in order to properly perform. We suggest using Masked Auto-Encoder (MAE), a self-supervised transformer model trained for recovering missing image regions based on their surroundings for FSAD. We show that MAE performs well by pre-training on an arbitrary set of natural images (ImageNet) and only fine-tuning on a small set of normal images. We name this method MAEDAY. We further find that MAEDAY provides an orthogonal signal to the embedding-based methods and the ensemble of the two approaches achieves very strong SOTA results. We also present a novel task of Zero-Shot AD (ZSAD) where no normal samples are available at training time. We show that MAEDAY performs surprisingly well at this task. Finally, we provide a new dataset for detecting foreign objects on the ground and demonstrate superior results for this task as well. Code is available at https://github.com/EliSchwartz/MAEDAY .
Generating Efficient DNN-Ensembles with Evolutionary Computation
Sep 18, 2020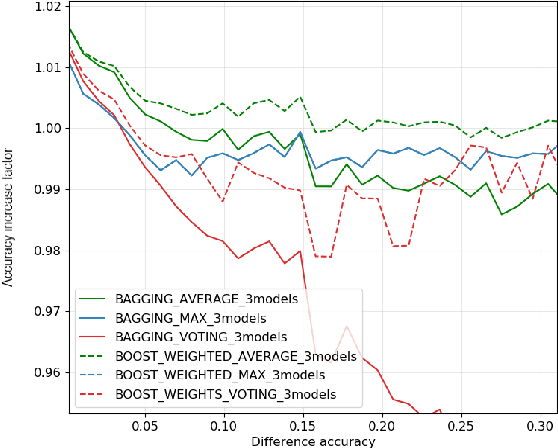
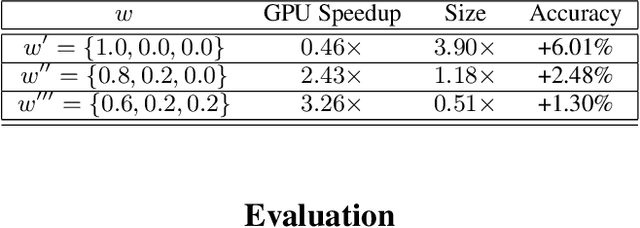
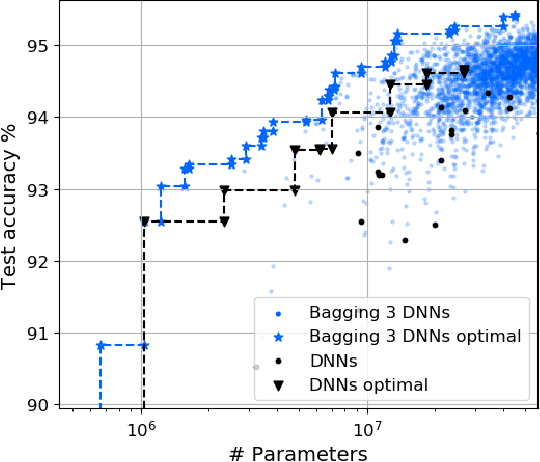
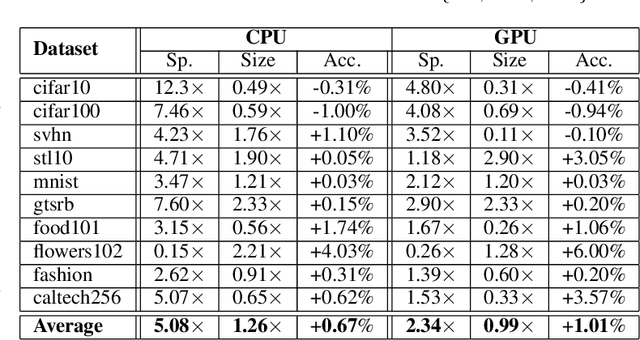
In this work, we leverage ensemble learning as a tool for the creation of faster, smaller, and more accurate deep learning models. We demonstrate that we can jointly optimize for accuracy, inference time, and the number of parameters by combining DNN classifiers. To achieve this, we combine multiple ensemble strategies: bagging, boosting, and an ordered chain of classifiers. To reduce the number of DNN ensemble evaluations during the search, we propose EARN, an evolutionary approach that optimizes the ensemble according to three objectives regarding the constraints specified by the user. We run EARN on 10 image classification datasets with an initial pool of 32 state-of-the-art DCNN on both CPU and GPU platforms, and we generate models with speedups up to $7.60\times$, reductions of parameters by $10\times$, or increases in accuracy up to $6.01\%$ regarding the best DNN in the pool. In addition, our method generates models that are $5.6\times$ faster than the state-of-the-art methods for automatic model generation.
Constrained deep neural network architecture search for IoT devices accounting hardware calibration
Sep 24, 2019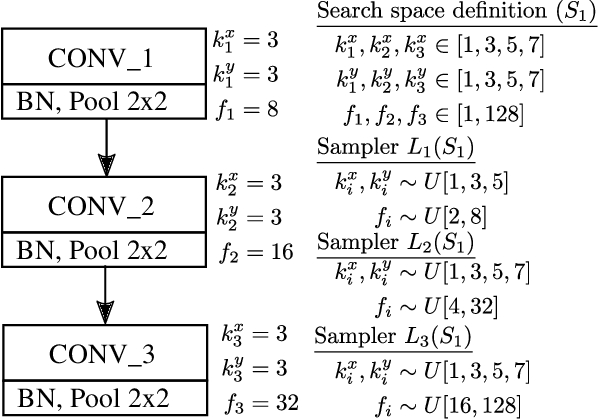
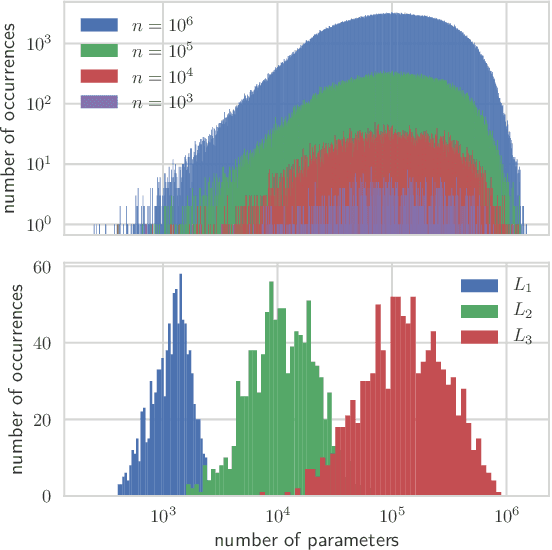
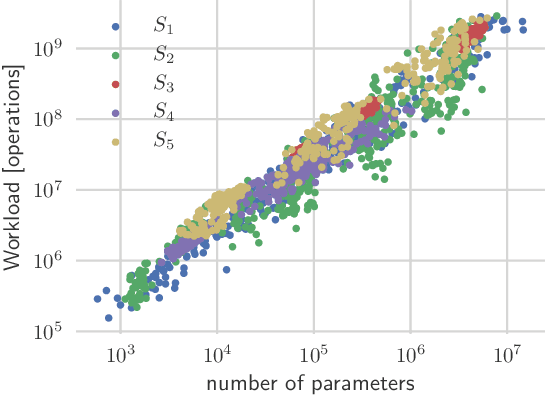
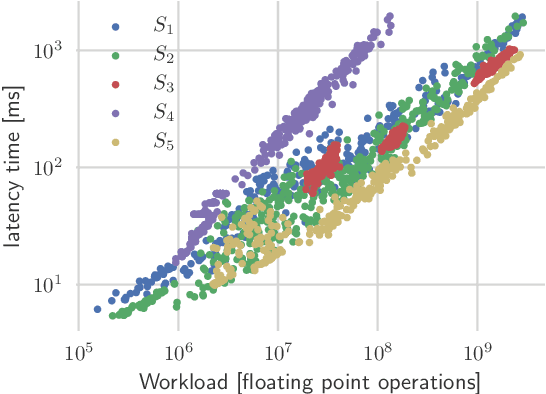
Deep neural networks achieve outstanding results in challenging image classification tasks. However, the design of network topologies is a complex task and the research community makes a constant effort in discovering top-accuracy topologies, either manually or employing expensive architecture searches. In this work, we propose a unique narrow-space architecture search that focuses on delivering low-cost and fast executing networks that respect strict memory and time requirements typical of Internet-of-Things (IoT) near-sensor computing platforms. Our approach provides solutions with classification latencies below 10ms running on a $35 device with 1GB RAM and 5.6GFLOPS peak performance. The narrow-space search of floating-point models improves the accuracy on CIFAR10 of an established IoT model from 70.64% to 74.87% respecting the same memory constraints. We further improve the accuracy to 82.07% by including 16-bit half types and we obtain the best accuracy of 83.45% by extending the search with model optimized IEEE 754 reduced types. To the best of our knowledge, we are the first that empirically demonstrate on over 3000 trained models that running with reduced precision pushes the Pareto optimal front by a wide margin. Under a given memory constraint, accuracy is improved by over 7% points for half and over 1% points further for running with the best model individual format.
NeuNetS: An Automated Synthesis Engine for Neural Network Design
Jan 17, 2019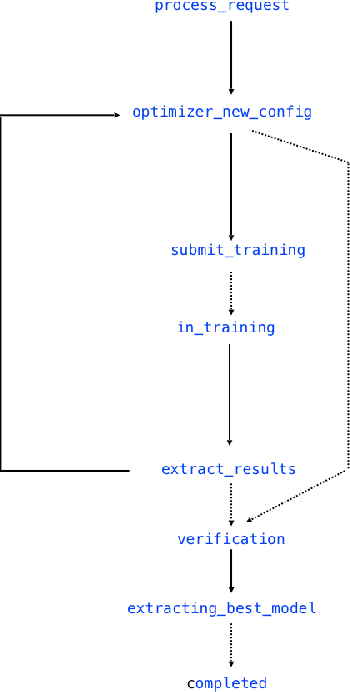
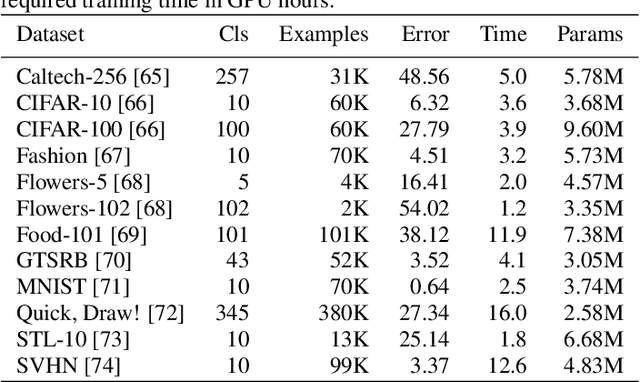
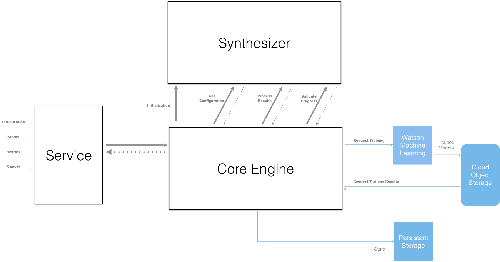
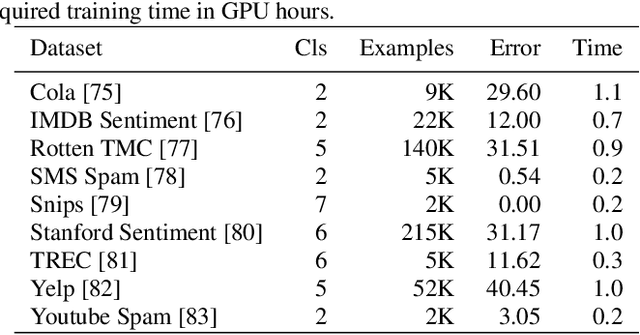
Application of neural networks to a vast variety of practical applications is transforming the way AI is applied in practice. Pre-trained neural network models available through APIs or capability to custom train pre-built neural network architectures with customer data has made the consumption of AI by developers much simpler and resulted in broad adoption of these complex AI models. While prebuilt network models exist for certain scenarios, to try and meet the constraints that are unique to each application, AI teams need to think about developing custom neural network architectures that can meet the tradeoff between accuracy and memory footprint to achieve the tight constraints of their unique use-cases. However, only a small proportion of data science teams have the skills and experience needed to create a neural network from scratch, and the demand far exceeds the supply. In this paper, we present NeuNetS : An automated Neural Network Synthesis engine for custom neural network design that is available as part of IBM's AI OpenScale's product. NeuNetS is available for both Text and Image domains and can build neural networks for specific tasks in a fraction of the time it takes today with human effort, and with accuracy similar to that of human-designed AI models.