 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeManifold-driven Attention Maps for Weakly Supervised Segmentation
Paper and Code
Apr 07, 2020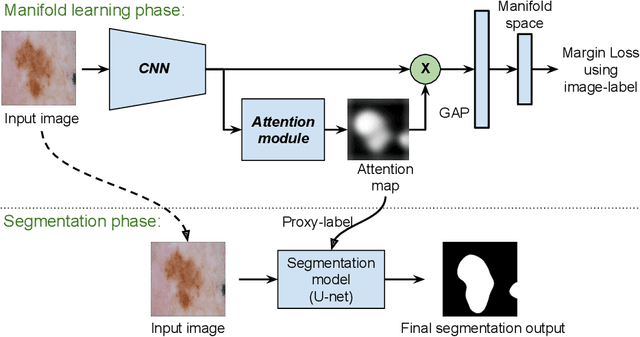
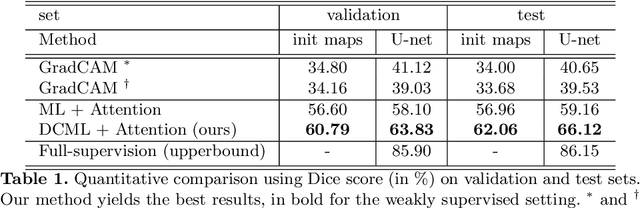
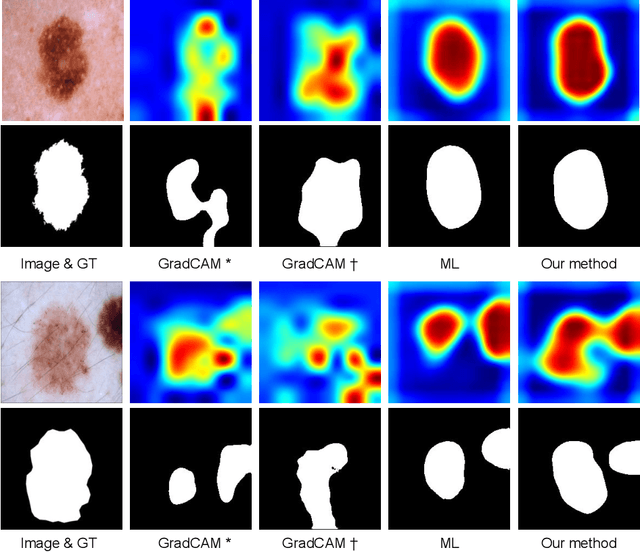
Segmentation using deep learning has shown promising directions in medical imaging as it aids in the analysis and diagnosis of diseases. Nevertheless, a main drawback of deep models is that they require a large amount of pixel-level labels, which are laborious and expensive to obtain. To mitigate this problem, weakly supervised learning has emerged as an efficient alternative, which employs image-level labels, scribbles, points, or bounding boxes as supervision. Among these, image-level labels are easier to obtain. However, since this type of annotation only contains object category information, the segmentation task under this learning paradigm is a challenging problem. To address this issue, visual salient regions derived from trained classification networks are typically used. Despite their success to identify important regions on classification tasks, these saliency regions only focus on the most discriminant areas of an image, limiting their use in semantic segmentation. In this work, we propose a manifold driven attention-based network to enhance visual salient regions, thereby improving segmentation accuracy in a weakly supervised setting. Our method generates superior attention maps directly during inference without the need of extra computations. We evaluate the benefits of our approach in the task of segmentation using a public benchmark on skin lesion images. Results demonstrate that our method outperforms the state-of-the-art GradCAM by a margin of ~22% in terms of Dice score.