 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Deep learning and its application to medical image segmentation
Mar 23, 2018
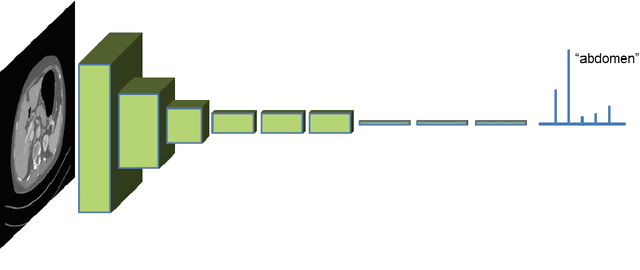
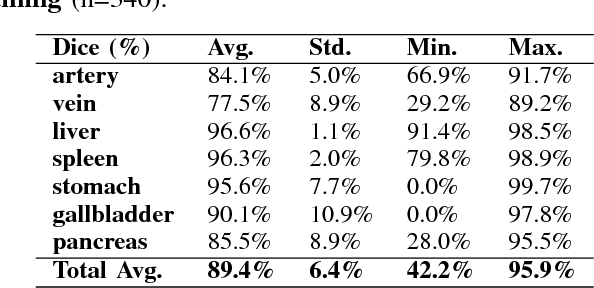
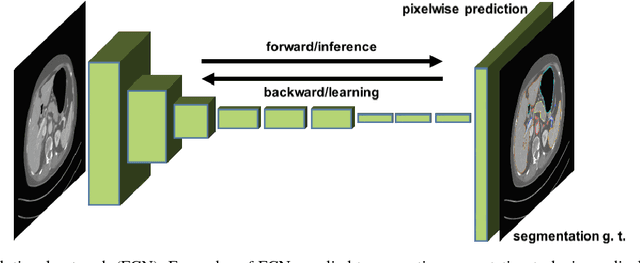
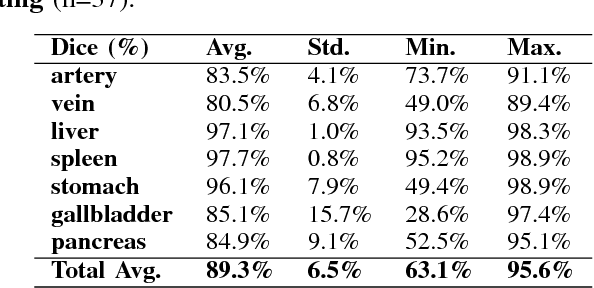
One of the most common tasks in medical imaging is semantic segmentation. Achieving this segmentation automatically has been an active area of research, but the task has been proven very challenging due to the large variation of anatomy across different patients. However, recent advances in deep learning have made it possible to significantly improve the performance of image recognition and semantic segmentation methods in the field of computer vision. Due to the data driven approaches of hierarchical feature learning in deep learning frameworks, these advances can be translated to medical images without much difficulty. Several variations of deep convolutional neural networks have been successfully applied to medical images. Especially fully convolutional architectures have been proven efficient for segmentation of 3D medical images. In this article, we describe how to build a 3D fully convolutional network (FCN) that can process 3D images in order to produce automatic semantic segmentations. The model is trained and evaluated on a clinical computed tomography (CT) dataset and shows state-of-the-art performance in multi-organ segmentation.
* Accepted for publication in the journal of the Japanese Society of Medical Imaging Technology (JAMIT)
Channel Pruning via Multi-Criteria based on Weight Dependency
Nov 06, 2020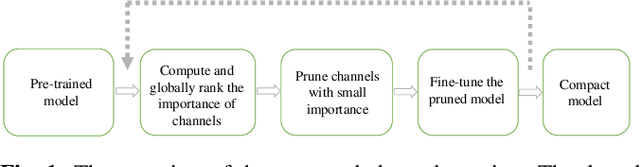
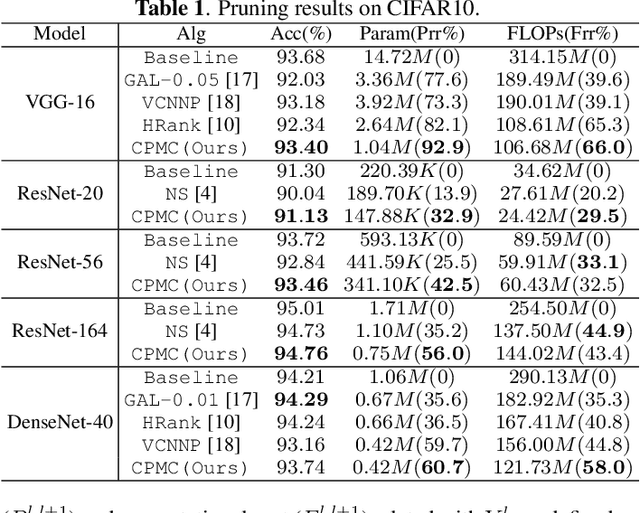
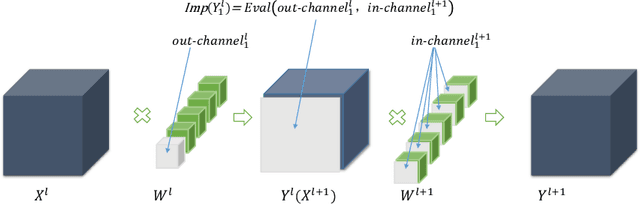
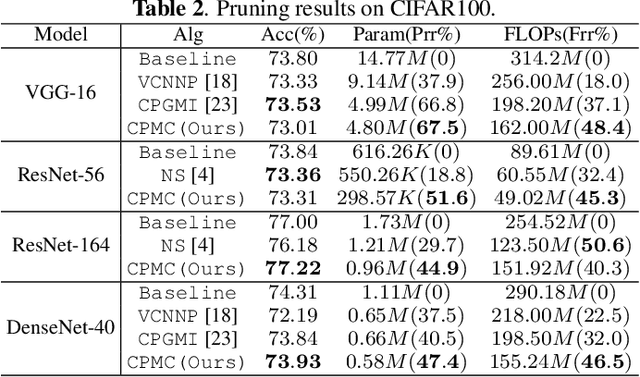
Channel pruning has demonstrated its effectiveness in compressing ConvNets. In many prior arts, the importance of an output feature map is only determined by its associated filter. However, these methods ignore a small part of weights in the next layer which disappear as the feature map is removed. They ignore the dependency of the weights, so that, a part of weights are pruned without being evaluated. In addition, many pruning methods use only one criterion for evaluation, and find a sweet-spot of pruning structure and accuracy in a trial-and-error fashion, which can be time-consuming. To address the above issues, we proposed a channel pruning algorithm via multi-criteria based on weight dependency, CPMC, which can compress a variety of models efficiently. We design the importance of the feature map in three aspects, including its associated weight value, computational cost and parameter quantity. Use the phenomenon of weight dependency, We get the importance by assessing its associated filter and the corresponding partial weights of the next layer. Then we use global normalization to achieve cross-layer comparison. Our method can compress various CNN models, including VGGNet, ResNet and DenseNet, on various image classification datasets. Extensive experiments have shown CPMC outperforms the others significantly.
CovidCTNet: An Open-Source Deep Learning Approach to Identify Covid-19 Using CT Image
May 08, 2020Coronavirus disease 2019 (Covid-19) is highly contagious with limited treatment options. Early and accurate diagnosis of Covid-19 is crucial in reducing the spread of the disease and its accompanied mortality. Currently, detection by reverse transcriptase polymerase chain reaction (RT-PCR) is the gold standard of outpatient and inpatient detection of Covid-19. RT-PCR is a rapid method, however, its accuracy in detection is only ~70-75%. Another approved strategy is computed tomography (CT) imaging. CT imaging has a much higher sensitivity of ~80-98%, but similar accuracy of 70%. To enhance the accuracy of CT imaging detection, we developed an open-source set of algorithms called CovidCTNet that successfully differentiates Covid-19 from community-acquired pneumonia (CAP) and other lung diseases. CovidCTNet increases the accuracy of CT imaging detection to 90% compared to radiologists (70%). The model is designed to work with heterogeneous and small sample sizes independent of the CT imaging hardware. In order to facilitate the detection of Covid-19 globally and assist radiologists and physicians in the screening process, we are releasing all algorithms and parametric details in an open-source format. Open-source sharing of our CovidCTNet enables developers to rapidly improve and optimize services, while preserving user privacy and data ownership.
Visual Language Modeling on CNN Image Representations
Nov 09, 2015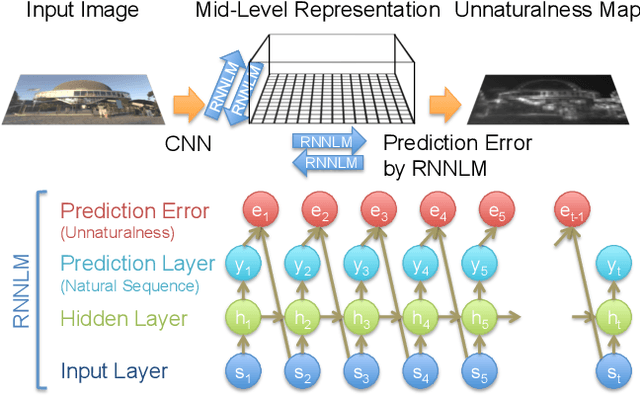
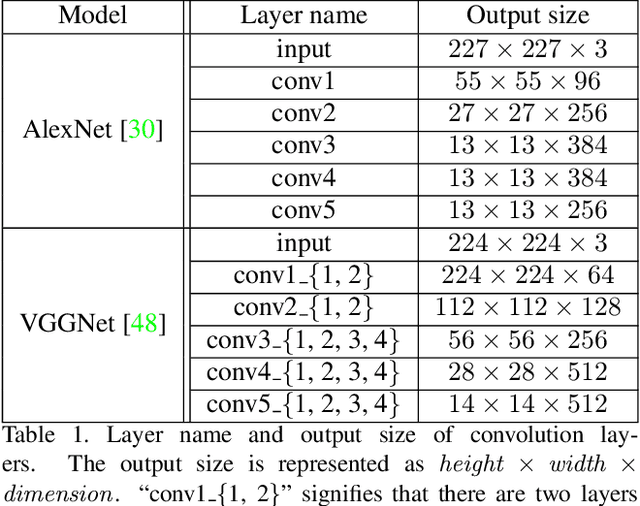

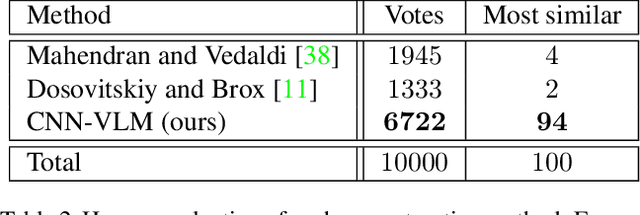
Measuring the naturalness of images is important to generate realistic images or to detect unnatural regions in images. Additionally, a method to measure naturalness can be complementary to Convolutional Neural Network (CNN) based features, which are known to be insensitive to the naturalness of images. However, most probabilistic image models have insufficient capability of modeling the complex and abstract naturalness that we feel because they are built directly on raw image pixels. In this work, we assume that naturalness can be measured by the predictability on high-level features during eye movement. Based on this assumption, we propose a novel method to evaluate the naturalness by building a variant of Recurrent Neural Network Language Models on pre-trained CNN representations. Our method is applied to two tasks, demonstrating that 1) using our method as a regularizer enables us to generate more understandable images from image features than existing approaches, and 2) unnaturalness maps produced by our method achieve state-of-the-art eye fixation prediction performance on two well-studied datasets.
CCML: A Novel Collaborative Learning Model for Classification of Remote Sensing Images with Noisy Multi-Labels
Dec 19, 2020
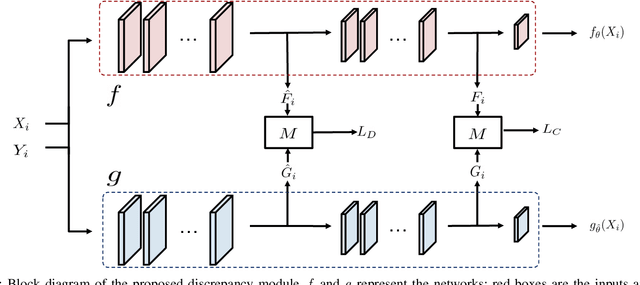
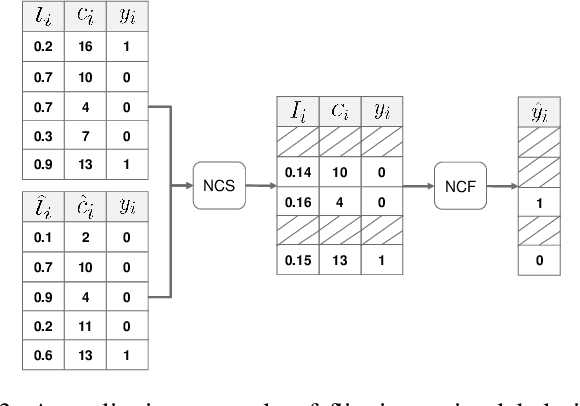
The development of accurate methods for multi-label classification (MLC) of remote sensing (RS) images is one of the most important research topics in RS. Deep Convolutional Neural Networks (CNNs) based methods have triggered substantial performance gains in RS MLC problems, requiring a large number of reliable training images annotated by multiple land-cover class labels. Collecting such data is time-consuming and costly. To address this problem, the publicly available thematic products, which can include noisy labels, can be used for annotating RS images with zero-labeling cost. However, multi-label noise (which can be associated with wrong as well as missing label annotations) can distort the learning process of the MLC algorithm, resulting in inaccurate predictions. The detection and correction of label noise are challenging tasks, especially in a multi-label scenario, where each image can be associated with more than one label. To address this problem, we propose a novel Consensual Collaborative Multi-Label Learning (CCML) method to alleviate the adverse effects of multi-label noise during the training phase of the CNN model. CCML identifies, ranks, and corrects noisy multi-labels in RS images based on four main modules: 1) group lasso module; 2) discrepancy module; 3) flipping module; and 4) swap module. The task of the group lasso module is to detect the potentially noisy labels assigned to the multi-labeled training images, and the discrepancy module ensures that the two collaborative networks learn diverse features, while obtaining the same predictions. The flipping module is designed to correct the identified noisy multi-labels, while the swap module task is devoted to exchanging the ranking information between two networks. Our code is publicly available online: http://www.noisy-labels-in-rs.org
A statistical theory of semi-supervised learning
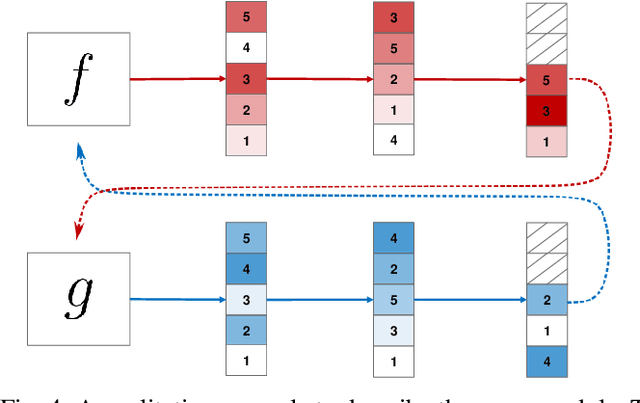
Aug 13, 2020
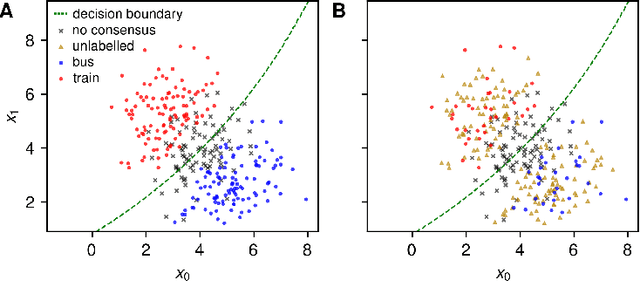
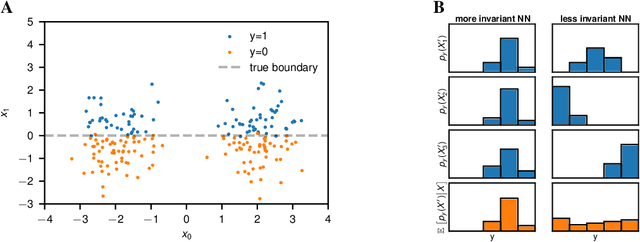
We currently lack a solid statistical understanding of semi-supervised learning methods, instead treating them as a collection of highly effective tricks. This precludes the principled combination e.g. of Bayesian methods and semi-supervised learning, as semi-supervised learning objectives are not currently formulated as likelihoods for an underlying generative model of the data. Here, we note that standard image benchmark datasets such as CIFAR-10 are carefully curated, and we provide a generative model describing the curation process. Under this generative model, several state-of-the-art semi-supervised learning techniques, including entropy minimization, pseudo-labelling and the FixMatch family emerge naturally as variational lower-bounds on the log-likelihood.
Weakly Supervised Salient Object Detection Using Image Labels
Mar 17, 2018
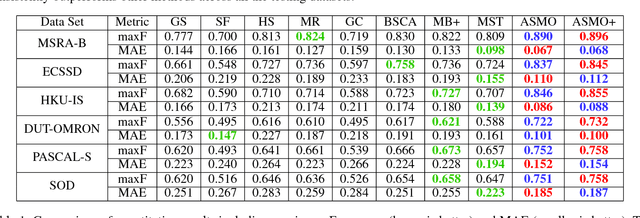
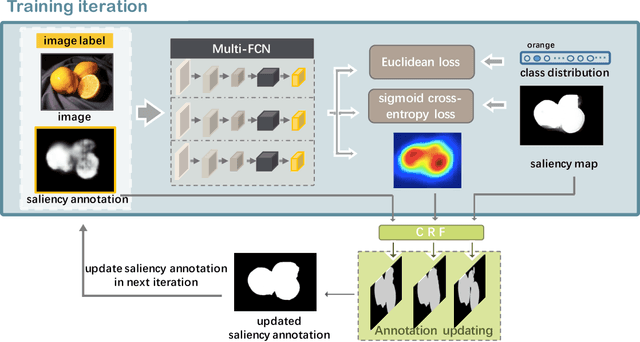

Deep learning based salient object detection has recently achieved great success with its performance greatly outperforms any other unsupervised methods. However, annotating per-pixel saliency masks is a tedious and inefficient procedure. In this paper, we note that superior salient object detection can be obtained by iteratively mining and correcting the labeling ambiguity on saliency maps from traditional unsupervised methods. We propose to use the combination of a coarse salient object activation map from the classification network and saliency maps generated from unsupervised methods as pixel-level annotation, and develop a simple yet very effective algorithm to train fully convolutional networks for salient object detection supervised by these noisy annotations. Our algorithm is based on alternately exploiting a graphical model and training a fully convolutional network for model updating. The graphical model corrects the internal labeling ambiguity through spatial consistency and structure preserving while the fully convolutional network helps to correct the cross-image semantic ambiguity and simultaneously update the coarse activation map for next iteration. Experimental results demonstrate that our proposed method greatly outperforms all state-of-the-art unsupervised saliency detection methods and can be comparable to the current best strongly-supervised methods training with thousands of pixel-level saliency map annotations on all public benchmarks.
Dual Illumination Estimation for Robust Exposure Correction
Oct 30, 2019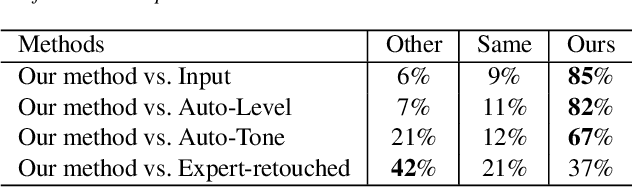

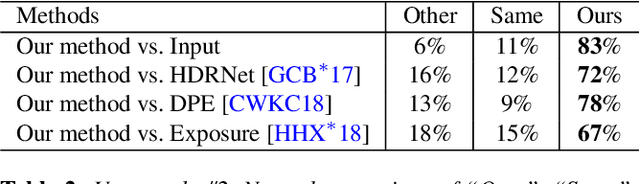

Exposure correction is one of the fundamental tasks in image processing and computational photography. While various methods have been proposed, they either fail to produce visually pleasing results, or only work well for limited types of image (e.g., underexposed images). In this paper, we present a novel automatic exposure correction method, which is able to robustly produce high-quality results for images of various exposure conditions (e.g., underexposed, overexposed, and partially under- and over-exposed). At the core of our approach is the proposed dual illumination estimation, where we separately cast the under- and over-exposure correction as trivial illumination estimation of the input image and the inverted input image. By performing dual illumination estimation, we obtain two intermediate exposure correction results for the input image, with one fixes the underexposed regions and the other one restores the overexposed regions. A multi-exposure image fusion technique is then employed to adaptively blend the visually best exposed parts in the two intermediate exposure correction images and the input image into a globally well-exposed image. Experiments on a number of challenging images demonstrate the effectiveness of the proposed approach and its superiority over the state-of-the-art methods and popular automatic exposure correction tools.
Hyperspectral Image Restoration via Global Total Variation Regularized Local nonconvex Low-Rank matrix Approximation
May 08, 2020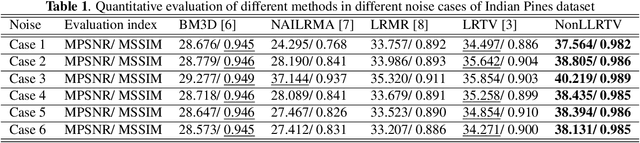


Several bandwise total variation (TV) regularized low-rank (LR)-based models have been proposed to remove mixed noise in hyperspectral images (HSIs). Conventionally, the rank of LR matrix is approximated using nuclear norm (NN). The NN is defined by adding all singular values together, which is essentially a $L_1$-norm of the singular values. It results in non-negligible approximation errors and thus the resulting matrix estimator can be significantly biased. Moreover, these bandwise TV-based methods exploit the spatial information in a separate manner. To cope with these problems, we propose a spatial-spectral TV (SSTV) regularized non-convex local LR matrix approximation (NonLLRTV) method to remove mixed noise in HSIs. From one aspect, local LR of HSIs is formulated using a non-convex $L_{\gamma}$-norm, which provides a closer approximation to the matrix rank than the traditional NN. From another aspect, HSIs are assumed to be piecewisely smooth in the global spatial domain. The TV regularization is effective in preserving the smoothness and removing Gaussian noise. These facts inspire the integration of the NonLLR with TV regularization. To address the limitations of bandwise TV, we use the SSTV regularization to simultaneously consider global spatial structure and spectral correlation of neighboring bands. Experiment results indicate that the use of local non-convex penalty and global SSTV can boost the preserving of spatial piecewise smoothness and overall structural information.
Self-Guided Multiple Instance Learning for Weakly Supervised Disease Classification and Localization in Chest Radiographs
Sep 30, 2020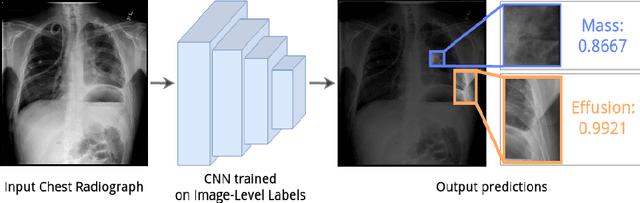
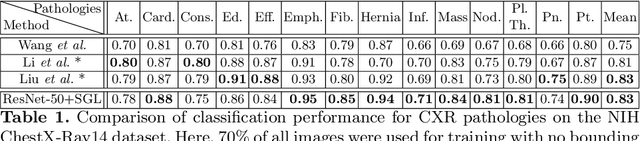
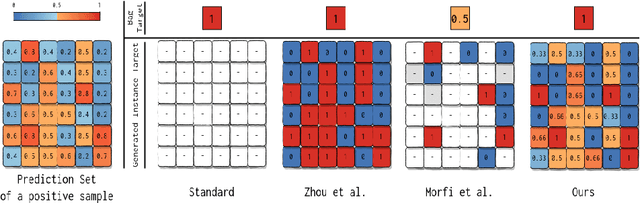
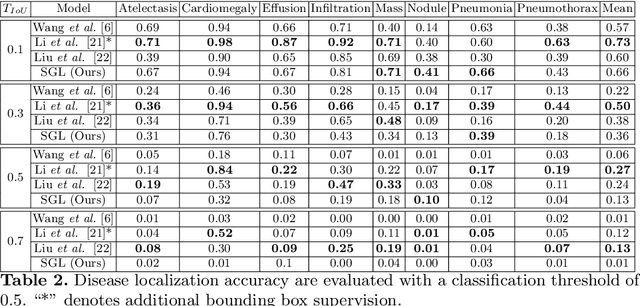
The lack of fine-grained annotations hinders the deployment of automated diagnosis systems, which require human-interpretable justification for their decision process. In this paper, we address the problem of weakly supervised identification and localization of abnormalities in chest radiographs. To that end, we introduce a novel loss function for training convolutional neural networks increasing the \emph{localization confidence} and assisting the overall \emph{disease identification}. The loss leverages both image- and patch-level predictions to generate auxiliary supervision. Rather than forming strictly binary from the predictions as done in previous loss formulations, we create targets in a more customized manner, which allows the loss to account for possible misclassification. We show that the supervision provided within the proposed learning scheme leads to better performance and more precise predictions on prevalent datasets for multiple-instance learning as well as on the NIH~ChestX-Ray14 benchmark for disease recognition than previously used losses.