 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Robust single-particle cryo-EM image denoising and restoration
Jan 02, 2024
Cryo-electron microscopy (cryo-EM) has achieved near-atomic level resolution of biomolecules by reconstructing 2D micrographs. However, the resolution and accuracy of the reconstructed particles are significantly reduced due to the extremely low signal-to-noise ratio (SNR) and complex noise structure of cryo-EM images. In this paper, we introduce a diffusion model with post-processing framework to effectively denoise and restore single particle cryo-EM images. Our method outperforms the state-of-the-art (SOTA) denoising methods by effectively removing structural noise that has not been addressed before. Additionally, more accurate and high-resolution three-dimensional reconstruction structures can be obtained from denoised cryo-EM images.
Application of 2D Homography for High Resolution Traffic Data Collection using CCTV Cameras
Jan 14, 2024Traffic cameras remain the primary source data for surveillance activities such as congestion and incident monitoring. To date, State agencies continue to rely on manual effort to extract data from networked cameras due to limitations of the current automatic vision systems including requirements for complex camera calibration and inability to generate high resolution data. This study implements a three-stage video analytics framework for extracting high-resolution traffic data such vehicle counts, speed, and acceleration from infrastructure-mounted CCTV cameras. The key components of the framework include object recognition, perspective transformation, and vehicle trajectory reconstruction for traffic data collection. First, a state-of-the-art vehicle recognition model is implemented to detect and classify vehicles. Next, to correct for camera distortion and reduce partial occlusion, an algorithm inspired by two-point linear perspective is utilized to extracts the region of interest (ROI) automatically, while a 2D homography technique transforms the CCTV view to bird's-eye view (BEV). Cameras are calibrated with a two-layer matrix system to enable the extraction of speed and acceleration by converting image coordinates to real-world measurements. Individual vehicle trajectories are constructed and compared in BEV using two time-space-feature-based object trackers, namely Motpy and BYTETrack. The results of the current study showed about +/- 4.5% error rate for directional traffic counts, less than 10% MSE for speed bias between camera estimates in comparison to estimates from probe data sources. Extracting high-resolution data from traffic cameras has several implications, ranging from improvements in traffic management and identify dangerous driving behavior, high-risk areas for accidents, and other safety concerns, enabling proactive measures to reduce accidents and fatalities.
Data-Efficient Multimodal Fusion on a Single GPU
Jan 02, 2024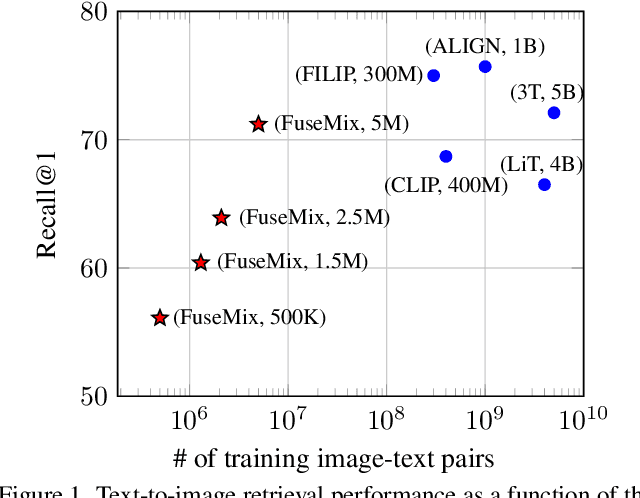
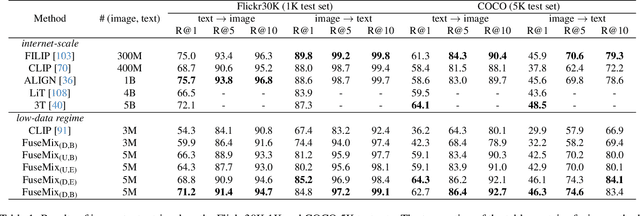
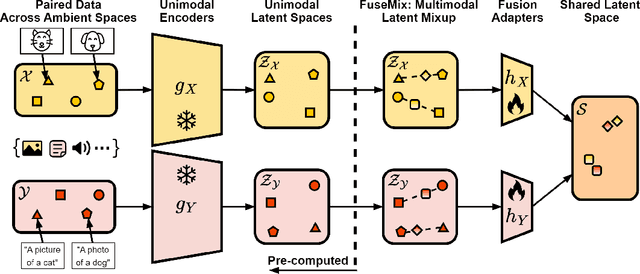
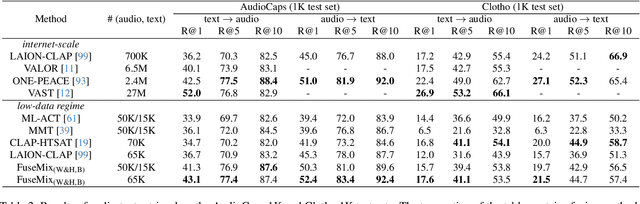
The goal of multimodal alignment is to learn a single latent space that is shared between multimodal inputs. The most powerful models in this space have been trained using massive datasets of paired inputs and large-scale computational resources, making them prohibitively expensive to train in many practical scenarios. We surmise that existing unimodal encoders pre-trained on large amounts of unimodal data should provide an effective bootstrap to create multimodal models from unimodal ones at much lower costs. We therefore propose FuseMix, a multimodal augmentation scheme that operates on the latent spaces of arbitrary pre-trained unimodal encoders. Using FuseMix for multimodal alignment, we achieve competitive performance -- and in certain cases outperform state-of-the art methods -- in both image-text and audio-text retrieval, with orders of magnitude less compute and data: for example, we outperform CLIP on the Flickr30K text-to-image retrieval task with $\sim \! 600\times$ fewer GPU days and $\sim \! 80\times$ fewer image-text pairs. Additionally, we show how our method can be applied to convert pre-trained text-to-image generative models into audio-to-image ones. Code is available at: https://github.com/layer6ai-labs/fusemix.
APLe: Token-Wise Adaptive for Multi-Modal Prompt Learning
Jan 12, 2024Pre-trained Vision-Language (V-L) models set the benchmark for generalization to downstream tasks among the noteworthy contenders. Many characteristics of the V-L model have been explored in existing research including the challenge of the sensitivity to text input and the tuning process across multi-modal prompts. With the advanced utilization of the V-L model like CLIP, recent approaches deploy learnable prompts instead of hand-craft prompts to boost the generalization performance and address the aforementioned challenges. Inspired by layer-wise training, which is wildly used in image fusion, we note that using a sequential training process to adapt different modalities branches of CLIP efficiently facilitates the improvement of generalization. In the context of addressing the multi-modal prompting challenge, we propose Token-wise Adaptive for Multi-modal Prompt Learning (APLe) for tuning both modalities prompts, vision and language, as tokens in a sequential manner. APLe addresses the challenges in V-L models to promote prompt learning across both modalities, which indicates a competitive generalization performance in line with the state-of-the-art. Preeminently, APLe shows robustness and favourable performance in prompt-length experiments with an absolute advantage in adopting the V-L models.
AffordanceLLM: Grounding Affordance from Vision Language Models
Jan 12, 2024Affordance grounding refers to the task of finding the area of an object with which one can interact. It is a fundamental but challenging task, as a successful solution requires the comprehensive understanding of a scene in multiple aspects including detection, localization, and recognition of objects with their parts, of geo-spatial configuration/layout of the scene, of 3D shapes and physics, as well as of the functionality and potential interaction of the objects and humans. Much of the knowledge is hidden and beyond the image content with the supervised labels from a limited training set. In this paper, we make an attempt to improve the generalization capability of the current affordance grounding by taking the advantage of the rich world, abstract, and human-object-interaction knowledge from pretrained large-scale vision language models. Under the AGD20K benchmark, our proposed model demonstrates a significant performance gain over the competing methods for in-the-wild object affordance grounding. We further demonstrate it can ground affordance for objects from random Internet images, even if both objects and actions are unseen during training. Project site: https://jasonqsy.github.io/AffordanceLLM/
Moonshot: Towards Controllable Video Generation and Editing with Multimodal Conditions
Jan 03, 2024Most existing video diffusion models (VDMs) are limited to mere text conditions. Thereby, they are usually lacking in control over visual appearance and geometry structure of the generated videos. This work presents Moonshot, a new video generation model that conditions simultaneously on multimodal inputs of image and text. The model builts upon a core module, called multimodal video block (MVB), which consists of conventional spatialtemporal layers for representing video features, and a decoupled cross-attention layer to address image and text inputs for appearance conditioning. In addition, we carefully design the model architecture such that it can optionally integrate with pre-trained image ControlNet modules for geometry visual conditions, without needing of extra training overhead as opposed to prior methods. Experiments show that with versatile multimodal conditioning mechanisms, Moonshot demonstrates significant improvement on visual quality and temporal consistency compared to existing models. In addition, the model can be easily repurposed for a variety of generative applications, such as personalized video generation, image animation and video editing, unveiling its potential to serve as a fundamental architecture for controllable video generation. Models will be made public on https://github.com/salesforce/LAVIS.
SIGNeRF: Scene Integrated Generation for Neural Radiance Fields
Jan 03, 2024Advances in image diffusion models have recently led to notable improvements in the generation of high-quality images. In combination with Neural Radiance Fields (NeRFs), they enabled new opportunities in 3D generation. However, most generative 3D approaches are object-centric and applying them to editing existing photorealistic scenes is not trivial. We propose SIGNeRF, a novel approach for fast and controllable NeRF scene editing and scene-integrated object generation. A new generative update strategy ensures 3D consistency across the edited images, without requiring iterative optimization. We find that depth-conditioned diffusion models inherently possess the capability to generate 3D consistent views by requesting a grid of images instead of single views. Based on these insights, we introduce a multi-view reference sheet of modified images. Our method updates an image collection consistently based on the reference sheet and refines the original NeRF with the newly generated image set in one go. By exploiting the depth conditioning mechanism of the image diffusion model, we gain fine control over the spatial location of the edit and enforce shape guidance by a selected region or an external mesh.
A Transformer-Based Adaptive Semantic Aggregation Method for UAV Visual Geo-Localization
Jan 03, 2024This paper addresses the task of Unmanned Aerial Vehicles (UAV) visual geo-localization, which aims to match images of the same geographic target taken by different platforms, i.e., UAVs and satellites. In general, the key to achieving accurate UAV-satellite image matching lies in extracting visual features that are robust against viewpoint changes, scale variations, and rotations. Current works have shown that part matching is crucial for UAV visual geo-localization since part-level representations can capture image details and help to understand the semantic information of scenes. However, the importance of preserving semantic characteristics in part-level representations is not well discussed. In this paper, we introduce a transformer-based adaptive semantic aggregation method that regards parts as the most representative semantics in an image. Correlations of image patches to different parts are learned in terms of the transformer's feature map. Then our method decomposes part-level features into an adaptive sum of all patch features. By doing this, the learned parts are encouraged to focus on patches with typical semantics. Extensive experiments on the University-1652 dataset have shown the superiority of our method over the current works.
* 12 pages
Fast High Dynamic Range Radiance Fields for Dynamic Scenes
Jan 11, 2024Neural Radiances Fields (NeRF) and their extensions have shown great success in representing 3D scenes and synthesizing novel-view images. However, most NeRF methods take in low-dynamic-range (LDR) images, which may lose details, especially with nonuniform illumination. Some previous NeRF methods attempt to introduce high-dynamic-range (HDR) techniques but mainly target static scenes. To extend HDR NeRF methods to wider applications, we propose a dynamic HDR NeRF framework, named HDR-HexPlane, which can learn 3D scenes from dynamic 2D images captured with various exposures. A learnable exposure mapping function is constructed to obtain adaptive exposure values for each image. Based on the monotonically increasing prior, a camera response function is designed for stable learning. With the proposed model, high-quality novel-view images at any time point can be rendered with any desired exposure. We further construct a dataset containing multiple dynamic scenes captured with diverse exposures for evaluation. All the datasets and code are available at \url{https://guanjunwu.github.io/HDR-HexPlane/}.
Latent Diffusion Models with Image-Derived Annotations for Enhanced AI-Assisted Cancer Diagnosis in Histopathology
Dec 15, 2023Artificial Intelligence (AI) based image analysis has an immense potential to support diagnostic histopathology, including cancer diagnostics. However, developing supervised AI methods requires large-scale annotated datasets. A potentially powerful solution is to augment training data with synthetic data. Latent diffusion models, which can generate high-quality, diverse synthetic images, are promising. However, the most common implementations rely on detailed textual descriptions, which are not generally available in this domain. This work proposes a method that constructs structured textual prompts from automatically extracted image features. We experiment with the PCam dataset, composed of tissue patches only loosely annotated as healthy or cancerous. We show that including image-derived features in the prompt, as opposed to only healthy and cancerous labels, improves the Fr\'echet Inception Distance (FID) from 178.8 to 90.2. We also show that pathologists find it challenging to detect synthetic images, with a median sensitivity/specificity of 0.55/0.55. Finally, we show that synthetic data effectively trains AI models.