 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArbor: Explicit Geometric Conditioning for Controllable 3D Asset Generation
Jun 22, 2026Text and image conditioned 3D models now generate convincing assets, but they still offer little direct control over the space an object should occupy or avoid. In authoring, this spatial intent is often known before generation starts. A chair should fit a seating envelope, a prop should leave clearance for motion, or a part should expose a contact surface. Prompts and image views are poor carriers for such constraints, requiring the need for an explicit control interface. We present Arbor, a trainable attachment for text conditioned latent 3D generation. Arbor introduces constraint meshes as a native 3D control interface. The interface uses hull regions where geometry should exist, avoidance regions that should remain empty, and touch regions the object should contact. Unlike completion or whole object scaffold control, these meshes are not target evidence. They are local typed requirements and can include regions where no surface should appear. Arbor keeps this signal as geometry by converting constraint meshes into tokens and learning a routed attachment inside a frozen denoiser. Each latent region can therefore receive the part of the constraint that matters for its spatial location. We evaluate Arbor on automatic and artist curated control benchmarks with hull, avoidance, and touch constraints, and compare the metric trends to a user preference study. Even without dedicated compliance losses, Arbor improves constraint obedience while preserving object quality and variation under fixed constraints.
ReLi3D: Relightable Multi-view 3D Reconstruction with Disentangled Illumination
Mar 20, 2026Reconstructing 3D assets from images has long required separate pipelines for geometry reconstruction, material estimation, and illumination recovery, each with distinct limitations and computational overhead. We present ReLi3D, the first unified end-to-end pipeline that simultaneously reconstructs complete 3D geometry, spatially-varying physically-based materials, and environment illumination from sparse multi-view images in under one second. Our key insight is that multi-view constraints can dramatically improve material and illumination disentanglement, a problem that remains fundamentally ill-posed for single-image methods. Key to our approach is the fusion of the multi-view input via a transformer cross-conditioning architecture, followed by a novel unified two-path prediction strategy. The first path predicts the object's structure and appearance, while the second path predicts the environment illumination from image background or object reflections. This, combined with a differentiable Monte Carlo multiple importance sampling renderer, creates an optimal illumination disentanglement training pipeline. In addition, with our mixed domain training protocol, which combines synthetic PBR datasets with real-world RGB captures, we establish generalizable results in geometry, material accuracy, and illumination quality. By unifying previously separate reconstruction tasks into a single feed-forward pass, we enable near-instantaneous generation of complete, relightable 3D assets. Project Page: https://reli3d.jdihlmann.com/
* Project Page: https://reli3d.jdihlmann.com/
MatSpray: Fusing 2D Material World Knowledge on 3D Geometry
Dec 20, 2025Manual modeling of material parameters and 3D geometry is a time consuming yet essential task in the gaming and film industries. While recent advances in 3D reconstruction have enabled accurate approximations of scene geometry and appearance, these methods often fall short in relighting scenarios due to the lack of precise, spatially varying material parameters. At the same time, diffusion models operating on 2D images have shown strong performance in predicting physically based rendering (PBR) properties such as albedo, roughness, and metallicity. However, transferring these 2D material maps onto reconstructed 3D geometry remains a significant challenge. We propose a framework for fusing 2D material data into 3D geometry using a combination of novel learning-based and projection-based approaches. We begin by reconstructing scene geometry via Gaussian Splatting. From the input images, a diffusion model generates 2D maps for albedo, roughness, and metallic parameters. Any existing diffusion model that can convert images or videos to PBR materials can be applied. The predictions are further integrated into the 3D representation either by optimizing an image-based loss or by directly projecting the material parameters onto the Gaussians using Gaussian ray tracing. To enhance fine-scale accuracy and multi-view consistency, we further introduce a light-weight neural refinement step (Neural Merger), which takes ray-traced material features as input and produces detailed adjustments. Our results demonstrate that the proposed methods outperform existing techniques in both quantitative metrics and perceived visual realism. This enables more accurate, relightable, and photorealistic renderings from reconstructed scenes, significantly improving the realism and efficiency of asset creation workflows in content production pipelines.
3D-RE-GEN: 3D Reconstruction of Indoor Scenes with a Generative Framework
Dec 19, 2025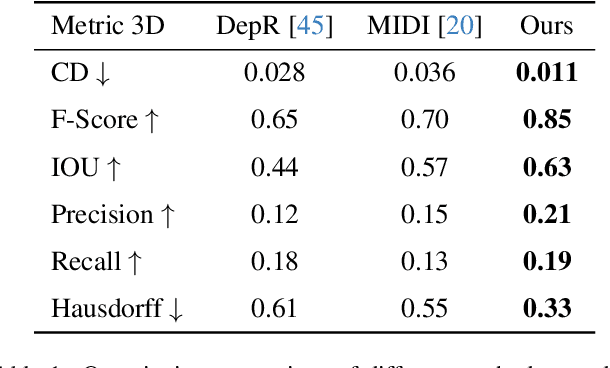
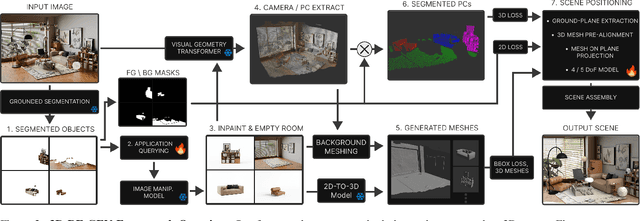
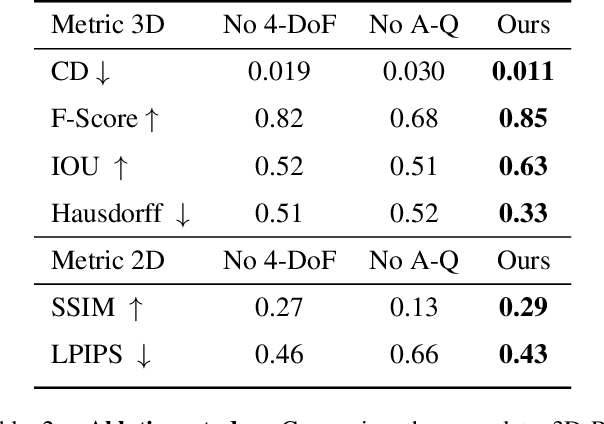
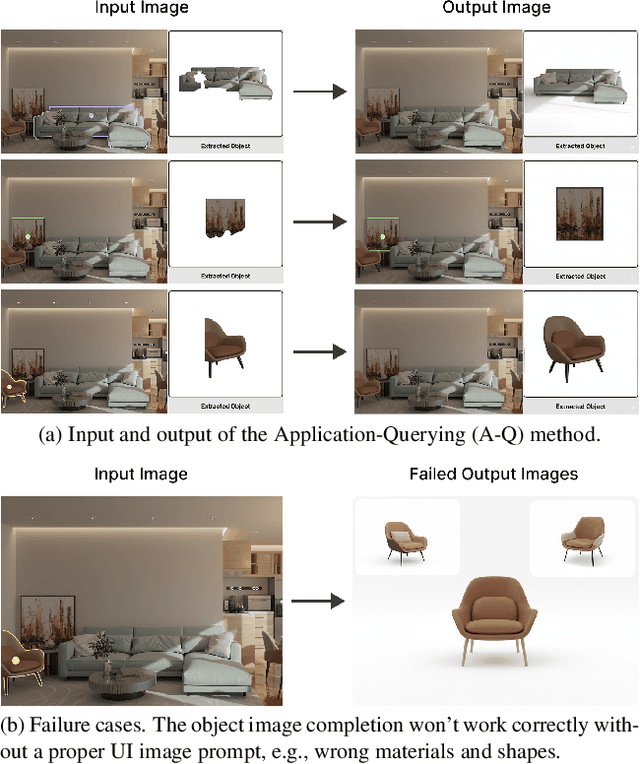
Recent advances in 3D scene generation produce visually appealing output, but current representations hinder artists' workflows that require modifiable 3D textured mesh scenes for visual effects and game development. Despite significant advances, current textured mesh scene reconstruction methods are far from artist ready, suffering from incorrect object decomposition, inaccurate spatial relationships, and missing backgrounds. We present 3D-RE-GEN, a compositional framework that reconstructs a single image into textured 3D objects and a background. We show that combining state of the art models from specific domains achieves state of the art scene reconstruction performance, addressing artists' requirements. Our reconstruction pipeline integrates models for asset detection, reconstruction, and placement, pushing certain models beyond their originally intended domains. Obtaining occluded objects is treated as an image editing task with generative models to infer and reconstruct with scene level reasoning under consistent lighting and geometry. Unlike current methods, 3D-RE-GEN generates a comprehensive background that spatially constrains objects during optimization and provides a foundation for realistic lighting and simulation tasks in visual effects and games. To obtain physically realistic layouts, we employ a novel 4-DoF differentiable optimization that aligns reconstructed objects with the estimated ground plane. 3D-RE-GEN~achieves state of the art performance in single image 3D scene reconstruction, producing coherent, modifiable scenes through compositional generation guided by precise camera recovery and spatial optimization.
FrameDiffuser: G-Buffer-Conditioned Diffusion for Neural Forward Frame Rendering
Dec 18, 2025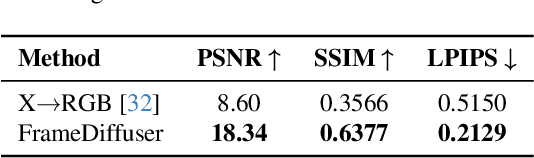
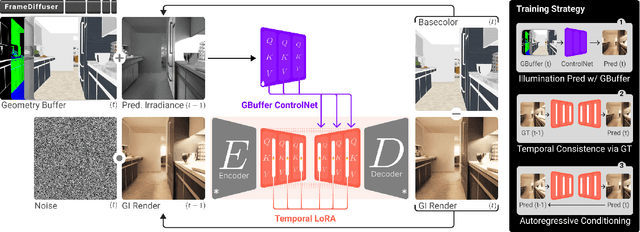
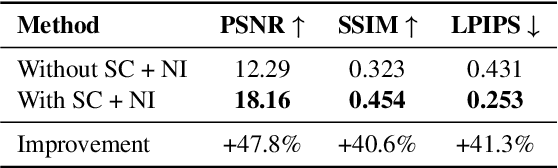

Neural rendering for interactive applications requires translating geometric and material properties (G-buffer) to photorealistic images with realistic lighting on a frame-by-frame basis. While recent diffusion-based approaches show promise for G-buffer-conditioned image synthesis, they face critical limitations: single-image models like RGBX generate frames independently without temporal consistency, while video models like DiffusionRenderer are too computationally expensive for most consumer gaming sets ups and require complete sequences upfront, making them unsuitable for interactive applications where future frames depend on user input. We introduce FrameDiffuser, an autoregressive neural rendering framework that generates temporally consistent, photorealistic frames by conditioning on G-buffer data and the models own previous output. After an initial frame, FrameDiffuser operates purely on incoming G-buffer data, comprising geometry, materials, and surface properties, while using its previously generated frame for temporal guidance, maintaining stable, temporal consistent generation over hundreds to thousands of frames. Our dual-conditioning architecture combines ControlNet for structural guidance with ControlLoRA for temporal coherence. A three-stage training strategy enables stable autoregressive generation. We specialize our model to individual environments, prioritizing consistency and inference speed over broad generalization, demonstrating that environment-specific training achieves superior photorealistic quality with accurate lighting, shadows, and reflections compared to generalized approaches.
Subsurface Scattering for 3D Gaussian Splatting
Aug 22, 2024



3D reconstruction and relighting of objects made from scattering materials present a significant challenge due to the complex light transport beneath the surface. 3D Gaussian Splatting introduced high-quality novel view synthesis at real-time speeds. While 3D Gaussians efficiently approximate an object's surface, they fail to capture the volumetric properties of subsurface scattering. We propose a framework for optimizing an object's shape together with the radiance transfer field given multi-view OLAT (one light at a time) data. Our method decomposes the scene into an explicit surface represented as 3D Gaussians, with a spatially varying BRDF, and an implicit volumetric representation of the scattering component. A learned incident light field accounts for shadowing. We optimize all parameters jointly via ray-traced differentiable rendering. Our approach enables material editing, relighting and novel view synthesis at interactive rates. We show successful application on synthetic data and introduce a newly acquired multi-view multi-light dataset of objects in a light-stage setup. Compared to previous work we achieve comparable or better results at a fraction of optimization and rendering time while enabling detailed control over material attributes. Project page https://sss.jdihlmann.com/
SIGNeRF: Scene Integrated Generation for Neural Radiance Fields
Jan 03, 2024



Advances in image diffusion models have recently led to notable improvements in the generation of high-quality images. In combination with Neural Radiance Fields (NeRFs), they enabled new opportunities in 3D generation. However, most generative 3D approaches are object-centric and applying them to editing existing photorealistic scenes is not trivial. We propose SIGNeRF, a novel approach for fast and controllable NeRF scene editing and scene-integrated object generation. A new generative update strategy ensures 3D consistency across the edited images, without requiring iterative optimization. We find that depth-conditioned diffusion models inherently possess the capability to generate 3D consistent views by requesting a grid of images instead of single views. Based on these insights, we introduce a multi-view reference sheet of modified images. Our method updates an image collection consistently based on the reference sheet and refines the original NeRF with the newly generated image set in one go. By exploiting the depth conditioning mechanism of the image diffusion model, we gain fine control over the spatial location of the edit and enforce shape guidance by a selected region or an external mesh.