 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTextual Bayes: Quantifying Uncertainty in LLM-Based Systems
Jun 11, 2025



Although large language models (LLMs) are becoming increasingly capable of solving challenging real-world tasks, accurately quantifying their uncertainty remains a critical open problem, which limits their applicability in high-stakes domains. This challenge is further compounded by the closed-source, black-box nature of many state-of-the-art LLMs. Moreover, LLM-based systems can be highly sensitive to the prompts that bind them together, which often require significant manual tuning (i.e., prompt engineering). In this work, we address these challenges by viewing LLM-based systems through a Bayesian lens. We interpret prompts as textual parameters in a statistical model, allowing us to use a small training dataset to perform Bayesian inference over these prompts. This novel perspective enables principled uncertainty quantification over both the model's textual parameters and its downstream predictions, while also incorporating prior beliefs about these parameters expressed in free-form text. To perform Bayesian inference, a difficult problem even for well-studied data modalities, we introduce Metropolis-Hastings through LLM Proposals (MHLP), a novel Markov chain Monte Carlo (MCMC) algorithm that combines prompt optimization techniques with standard MCMC methods. MHLP is a turnkey modification to existing LLM pipelines, including those that rely exclusively on closed-source models. Empirically, we demonstrate that our method yields improvements in both predictive accuracy and uncertainty quantification (UQ) on a range of LLM benchmarks and UQ tasks. More broadly, our work demonstrates a viable path for incorporating methods from the rich Bayesian literature into the era of LLMs, paving the way for more reliable and calibrated LLM-based systems.
Inconsistencies In Consistency Models: Better ODE Solving Does Not Imply Better Samples
Nov 13, 2024



Although diffusion models can generate remarkably high-quality samples, they are intrinsically bottlenecked by their expensive iterative sampling procedure. Consistency models (CMs) have recently emerged as a promising diffusion model distillation method, reducing the cost of sampling by generating high-fidelity samples in just a few iterations. Consistency model distillation aims to solve the probability flow ordinary differential equation (ODE) defined by an existing diffusion model. CMs are not directly trained to minimize error against an ODE solver, rather they use a more computationally tractable objective. As a way to study how effectively CMs solve the probability flow ODE, and the effect that any induced error has on the quality of generated samples, we introduce Direct CMs, which \textit{directly} minimize this error. Intriguingly, we find that Direct CMs reduce the ODE solving error compared to CMs but also result in significantly worse sample quality, calling into question why exactly CMs work well in the first place. Full code is available at: https://github.com/layer6ai-labs/direct-cms.
MSc-SQL: Multi-Sample Critiquing Small Language Models For Text-To-SQL Translation
Oct 16, 2024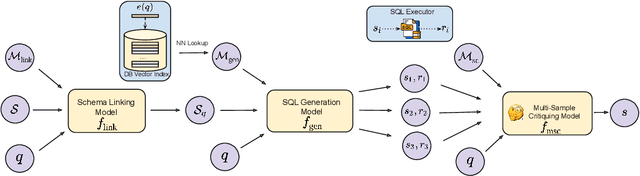
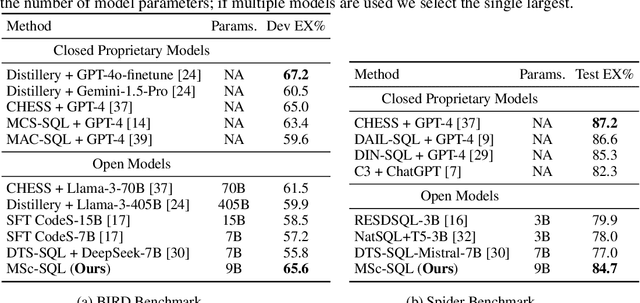

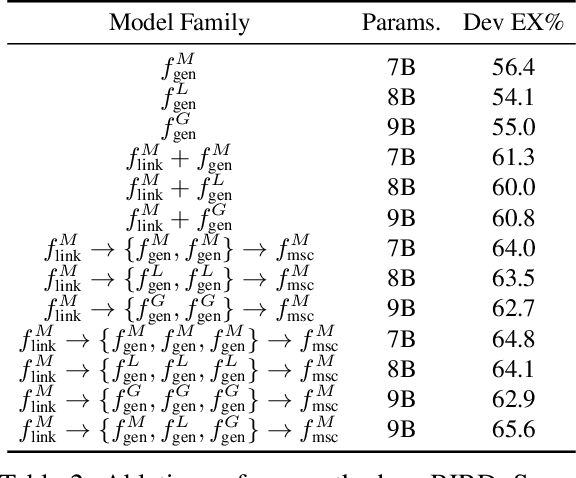
Text-to-SQL generation enables non-experts to interact with databases via natural language. Recent advances rely on large closed-source models like GPT-4 that present challenges in accessibility, privacy, and latency. To address these issues, we focus on developing small, efficient, and open-source text-to-SQL models. We demonstrate the benefits of sampling multiple candidate SQL generations and propose our method, MSc-SQL, to critique them using associated metadata. Our sample critiquing model evaluates multiple outputs simultaneously, achieving state-of-the-art performance compared to other open-source models while remaining competitive with larger models at a much lower cost. Full code can be found at github.com/layer6ai-labs/msc-sql.
Conformal Prediction Sets Improve Human Decision Making
Feb 01, 2024



In response to everyday queries, humans explicitly signal uncertainty and offer alternative answers when they are unsure. Machine learning models that output calibrated prediction sets through conformal prediction mimic this human behaviour; larger sets signal greater uncertainty while providing alternatives. In this work, we study the usefulness of conformal prediction sets as an aid for human decision making by conducting a pre-registered randomized controlled trial with conformal prediction sets provided to human subjects. With statistical significance, we find that when humans are given conformal prediction sets their accuracy on tasks improves compared to fixed-size prediction sets with the same coverage guarantee. The results show that quantifying model uncertainty with conformal prediction is helpful for human-in-the-loop decision making and human-AI teams.
Data-Efficient Multimodal Fusion on a Single GPU
Jan 02, 2024



The goal of multimodal alignment is to learn a single latent space that is shared between multimodal inputs. The most powerful models in this space have been trained using massive datasets of paired inputs and large-scale computational resources, making them prohibitively expensive to train in many practical scenarios. We surmise that existing unimodal encoders pre-trained on large amounts of unimodal data should provide an effective bootstrap to create multimodal models from unimodal ones at much lower costs. We therefore propose FuseMix, a multimodal augmentation scheme that operates on the latent spaces of arbitrary pre-trained unimodal encoders. Using FuseMix for multimodal alignment, we achieve competitive performance -- and in certain cases outperform state-of-the art methods -- in both image-text and audio-text retrieval, with orders of magnitude less compute and data: for example, we outperform CLIP on the Flickr30K text-to-image retrieval task with $\sim \! 600\times$ fewer GPU days and $\sim \! 80\times$ fewer image-text pairs. Additionally, we show how our method can be applied to convert pre-trained text-to-image generative models into audio-to-image ones. Code is available at: https://github.com/layer6ai-labs/fusemix.