 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Deep learning for biomedical photoacoustic imaging: A review
Nov 05, 2020
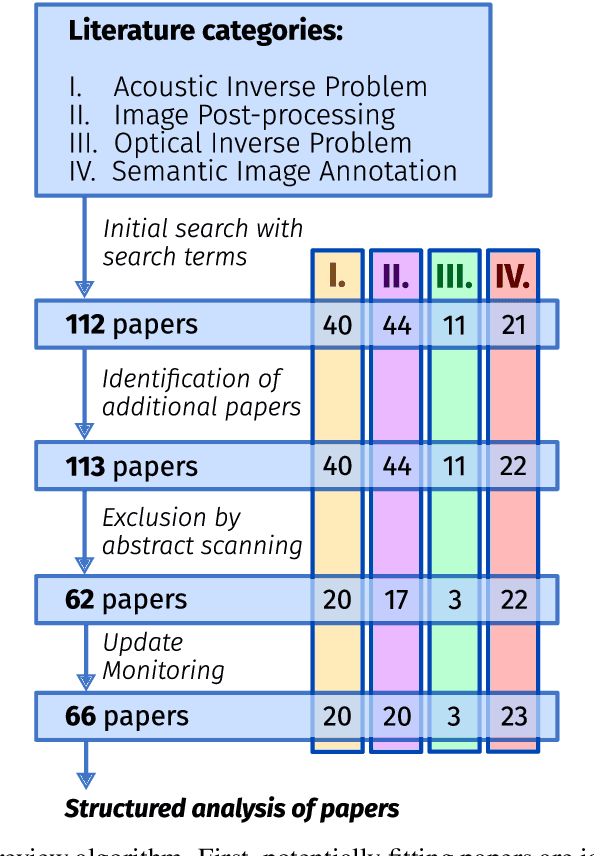
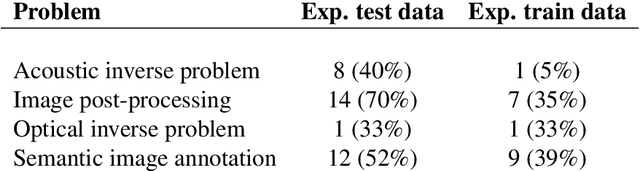
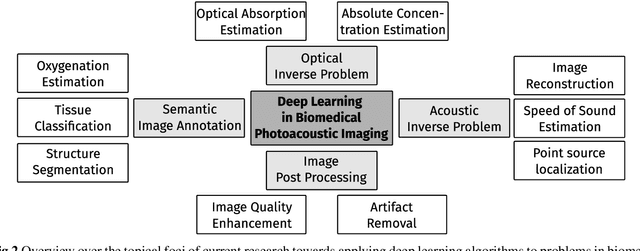

Photoacoustic imaging (PAI) is a promising emerging imaging modality that enables spatially resolved imaging of optical tissue properties up to several centimeters deep in tissue, creating the potential for numerous exciting clinical applications. However, extraction of relevant tissue parameters from the raw data requires the solving of inverse image reconstruction problems, which have proven extremely difficult to solve. The application of deep learning methods has recently exploded in popularity, leading to impressive successes in the context of medical imaging and also finding first use in the field of PAI. Deep learning methods possess unique advantages that can facilitate the clinical translation of PAI, such as extremely fast computation times and the fact that they can be adapted to any given problem. In this review, we examine the current state of the art regarding deep learning in PAI and identify potential directions of research that will help to reach the goal of clinical applicability
Event Specific Multimodal Pattern Mining with Image-Caption Pairs
Jan 05, 2016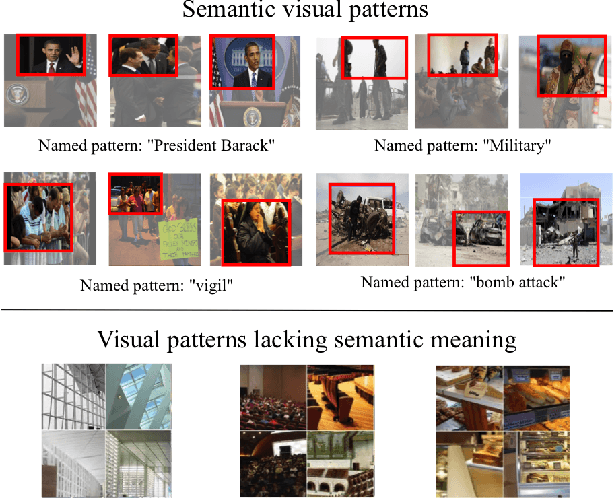

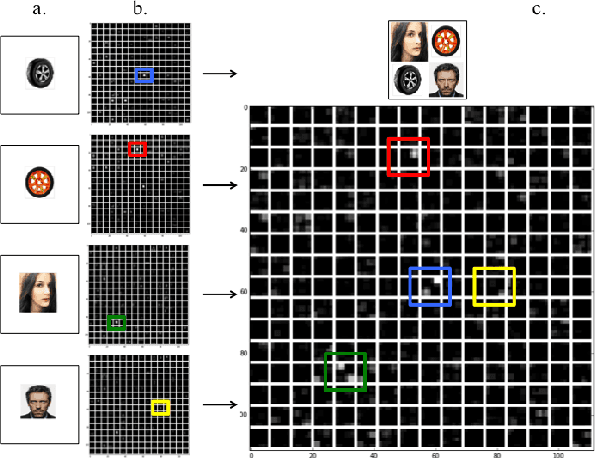
In this paper we describe a novel framework and algorithms for discovering image patch patterns from a large corpus of weakly supervised image-caption pairs generated from news events. Current pattern mining techniques attempt to find patterns that are representative and discriminative, we stipulate that our discovered patterns must also be recognizable by humans and preferably with meaningful names. We propose a new multimodal pattern mining approach that leverages the descriptive captions often accompanying news images to learn semantically meaningful image patch patterns. The mutltimodal patterns are then named using words mined from the associated image captions for each pattern. A novel evaluation framework is provided that demonstrates our patterns are 26.2% more semantically meaningful than those discovered by the state of the art vision only pipeline, and that we can provide tags for the discovered images patches with 54.5% accuracy with no direct supervision. Our methods also discover named patterns beyond those covered by the existing image datasets like ImageNet. To the best of our knowledge this is the first algorithm developed to automatically mine image patch patterns that have strong semantic meaning specific to high-level news events, and then evaluate these patterns based on that criteria.
An Overview Of 3D Object Detection
Oct 29, 2020
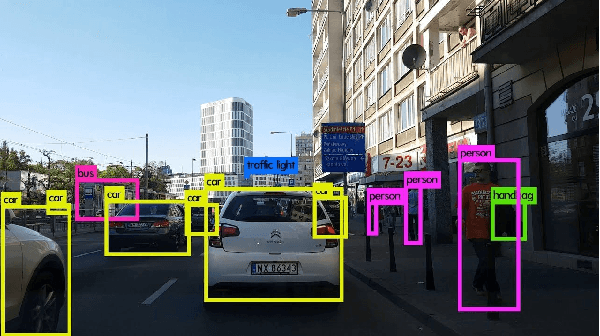


Point cloud 3D object detection has recently received major attention and becomes an active research topic in 3D computer vision community. However, recognizing 3D objects in LiDAR (Light Detection and Ranging) is still a challenge due to the complexity of point clouds. Objects such as pedestrians, cyclists, or traffic cones are usually represented by quite sparse points, which makes the detection quite complex using only point cloud. In this project, we propose a framework that uses both RGB and point cloud data to perform multiclass object recognition. We use existing 2D detection models to localize the region of interest (ROI) on the RGB image, followed by a pixel mapping strategy in the point cloud, and finally, lift the initial 2D bounding box to 3D space. We use the recently released nuScenes dataset---a large-scale dataset contains many data formats---to training and evaluate our proposed architecture.
Auditing ImageNet: Towards a Model-driven Framework for Annotating Demographic Attributes of Large-Scale Image Datasets
Jun 04, 2019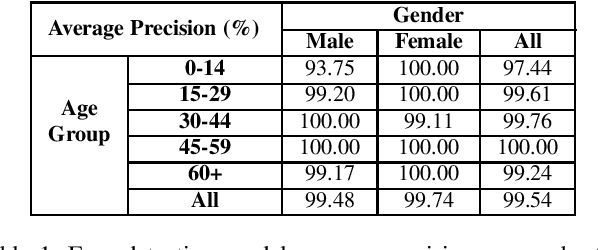
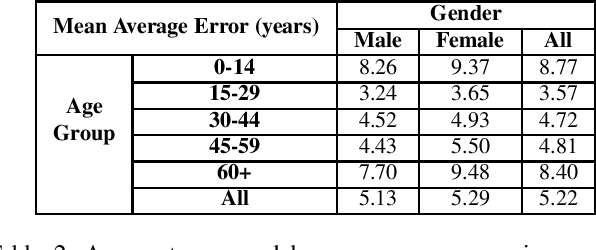
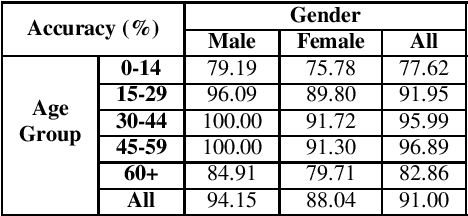
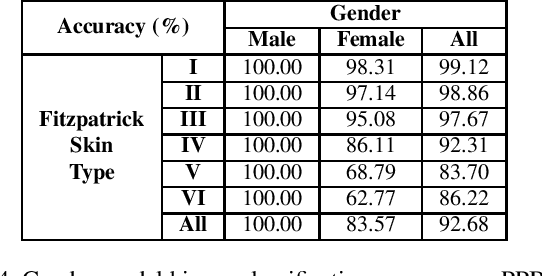
The ImageNet dataset ushered in a flood of academic and industry interest in deep learning for computer vision applications. Despite its significant impact, there has not been a comprehensive investigation into the demographic attributes of images contained within the dataset. Such a study could lead to new insights on inherent biases within ImageNet, particularly important given it is frequently used to pretrain models for a wide variety of computer vision tasks. In this work, we introduce a model-driven framework for the automatic annotation of apparent age and gender attributes in large-scale image datasets. Using this framework, we conduct the first demographic audit of the 2012 ImageNet Large Scale Visual Recognition Challenge (ILSVRC) subset of ImageNet and the "person" hierarchical category of ImageNet. We find that 41.62% of faces in ILSVRC appear as female, 1.71% appear as individuals above the age of 60, and males aged 15 to 29 account for the largest subgroup with 27.11%. We note that the presented model-driven framework is not fair for all intersectional groups, so annotation are subject to bias. We present this work as the starting point for future development of unbiased annotation models and for the study of downstream effects of imbalances in the demographics of ImageNet. Code and annotations are available at: http://bit.ly/ImageNetDemoAudit
Plug-and-Play Algorithms for Video Snapshot Compressive Imaging
Jan 13, 2021
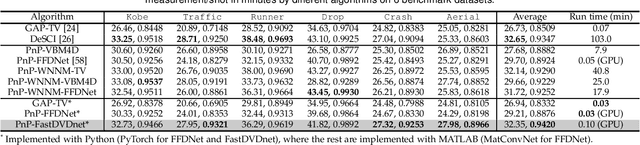


We consider the reconstruction problem of video snapshot compressive imaging (SCI), which captures high-speed videos using a low-speed 2D sensor (detector). The underlying principle of SCI is to modulate sequential high-speed frames with different masks and then these encoded frames are integrated into a snapshot on the sensor and thus the sensor can be of low-speed. On one hand, video SCI enjoys the advantages of low-bandwidth, low-power and low-cost. On the other hand, applying SCI to large-scale problems (HD or UHD videos) in our daily life is still challenging and one of the bottlenecks lies in the reconstruction algorithm. Exiting algorithms are either too slow (iterative optimization algorithms) or not flexible to the encoding process (deep learning based end-to-end networks). In this paper, we develop fast and flexible algorithms for SCI based on the plug-and-play (PnP) framework. In addition to the PnP-ADMM method, we further propose the PnP-GAP (generalized alternating projection) algorithm with a lower computational workload. We first employ the image deep denoising priors to show that PnP can recover a UHD color video with 30 frames from a snapshot measurement. Since videos have strong temporal correlation, by employing the video deep denoising priors, we achieve a significant improvement in the results. Furthermore, we extend the proposed PnP algorithms to the color SCI system using mosaic sensors, where each pixel only captures the red, green or blue channels. A joint reconstruction and demosaicing paradigm is developed for flexible and high quality reconstruction of color video SCI systems. Extensive results on both simulation and real datasets verify the superiority of our proposed algorithm.
Efficient Spatially Adaptive Convolution and Correlation
Jun 23, 2020
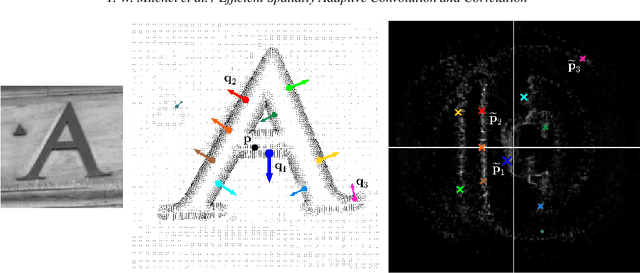

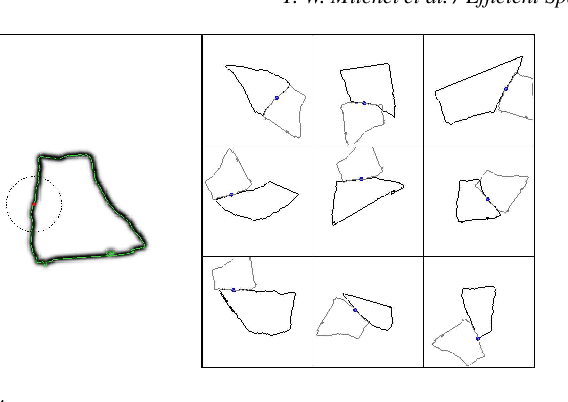
Fast methods for convolution and correlation underlie a variety of applications in computer vision and graphics, including efficient filtering, analysis, and simulation. However, standard convolution and correlation are inherently limited to fixed filters: spatial adaptation is impossible without sacrificing efficient computation. In early work, Freeman and Adelson have shown how steerable filters can address this limitation, providing a way for rotating the filter as it is passed over the signal. In this work, we provide a general, representation-theoretic, framework that allows for spatially varying linear transformations to be applied to the filter. This framework allows for efficient implementation of extended convolution and correlation for transformation groups such as rotation (in 2D and 3D) and scale, and provides a new interpretation for previous methods including steerable filters and the generalized Hough transform. We present applications to pattern matching, image feature description, vector field visualization, and adaptive image filtering.
Is a Green Screen Really Necessary for Real-Time Portrait Matting?
Nov 29, 2020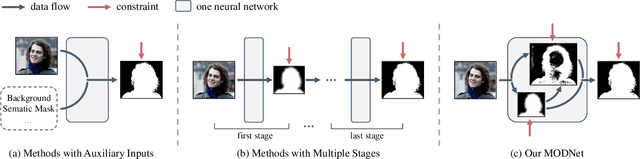
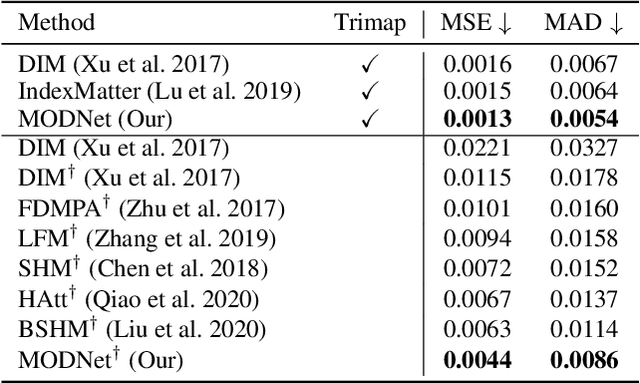
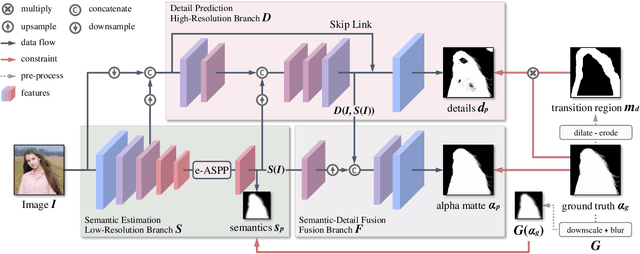
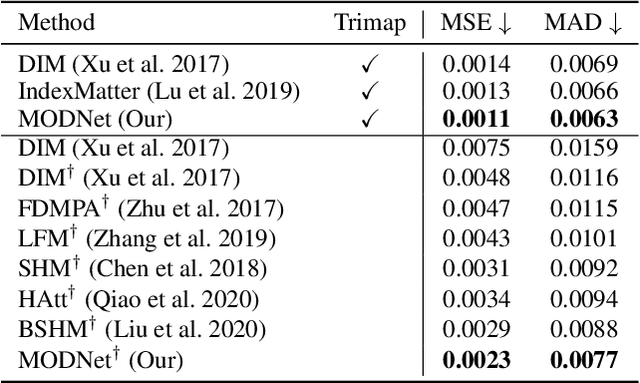
For portrait matting without the green screen, existing works either require auxiliary inputs that are costly to obtain or use multiple models that are computationally expensive. Consequently, they are unavailable in real-time applications. In contrast, we present a light-weight matting objective decomposition network (MODNet), which can process portrait matting from a single input image in real time. The design of MODNet benefits from optimizing a series of correlated sub-objectives simultaneously via explicit constraints. Moreover, since trimap-free methods usually suffer from the domain shift problem in practice, we introduce (1) a self-supervised strategy based on sub-objectives consistency to adapt MODNet to real-world data and (2) a one-frame delay trick to smooth the results when applying MODNet to portrait video sequence. MODNet is easy to be trained in an end-to-end style. It is much faster than contemporaneous matting methods and runs at 63 frames per second. On a carefully designed portrait matting benchmark newly proposed in this work, MODNet greatly outperforms prior trimap-free methods. More importantly, our method achieves remarkable results in daily photos and videos. Now, do you really need a green screen for real-time portrait matting?
Training EfficientNets at Supercomputer Scale: 83% ImageNet Top-1 Accuracy in One Hour
Nov 05, 2020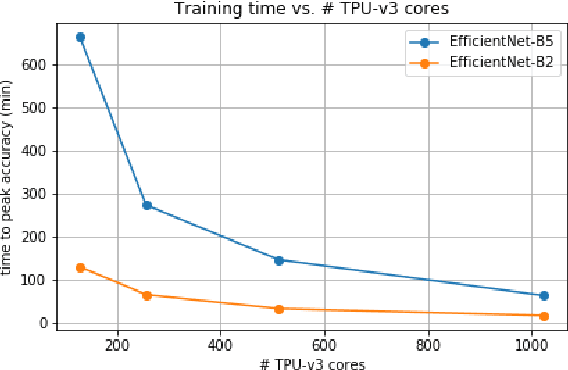
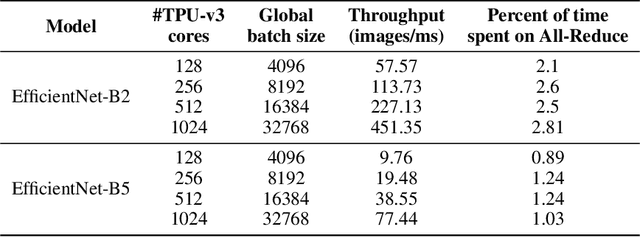
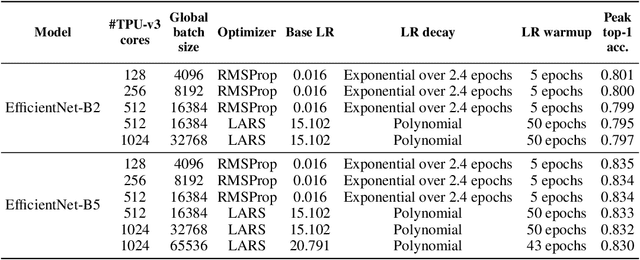
EfficientNets are a family of state-of-the-art image classification models based on efficiently scaled convolutional neural networks. Currently, EfficientNets can take on the order of days to train; for example, training an EfficientNet-B0 model takes 23 hours on a Cloud TPU v2-8 node. In this paper, we explore techniques to scale up the training of EfficientNets on TPU-v3 Pods with 2048 cores, motivated by speedups that can be achieved when training at such scales. We discuss optimizations required to scale training to a batch size of 65536 on 1024 TPU-v3 cores, such as selecting large batch optimizers and learning rate schedules as well as utilizing distributed evaluation and batch normalization techniques. Additionally, we present timing and performance benchmarks for EfficientNet models trained on the ImageNet dataset in order to analyze the behavior of EfficientNets at scale. With our optimizations, we are able to train EfficientNet on ImageNet to an accuracy of 83% in 1 hour and 4 minutes.
CUNet: A Compact Unsupervised Network for Image Classification
Jul 06, 2016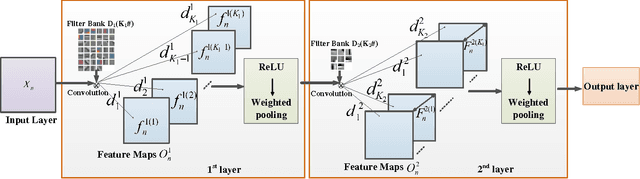
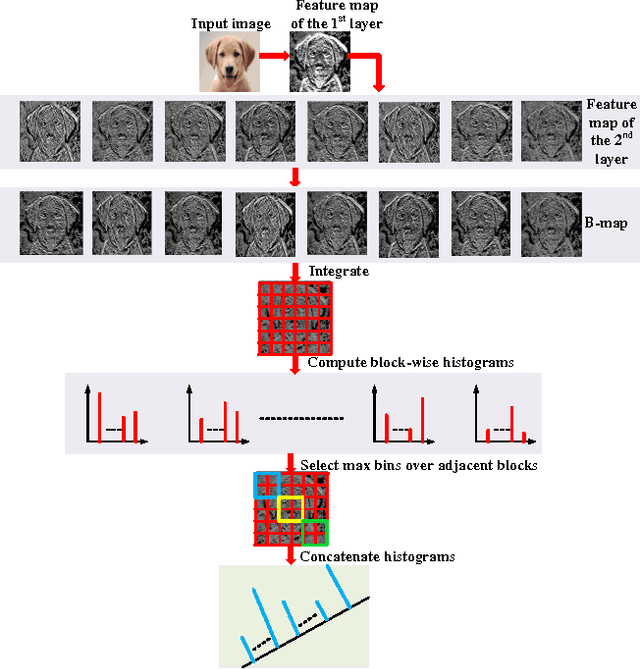


In this paper, we propose a compact network called CUNet (compact unsupervised network) to counter the image classification challenge. Different from the traditional convolutional neural networks learning filters by the time-consuming stochastic gradient descent, CUNet learns the filter bank from diverse image patches with the simple K-means, which significantly avoids the requirement of scarce labeled training images, reduces the training consumption, and maintains the high discriminative ability. Besides, we propose a new pooling method named weighted pooling considering the different weight values of adjacent neurons, which helps to improve the robustness to small image distortions. In the output layer, CUNet integrates the feature maps gained in the last hidden layer, and straightforwardly computes histograms in non-overlapped blocks. To reduce feature redundancy, we implement the max-pooling operation on adjacent blocks to select the most competitive features. Comprehensive experiments are conducted to demonstrate the state-of-the-art classification performances with CUNet on CIFAR-10, STL-10, MNIST and Caltech101 benchmark datasets.
Hypergraph p-Laplacian Regularization for Remote Sensing Image Recognition
Jun 21, 2018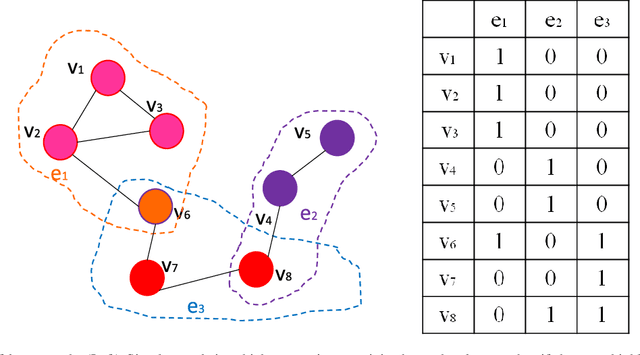
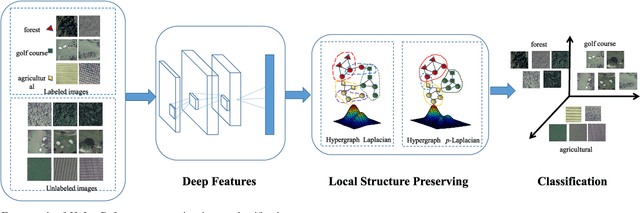
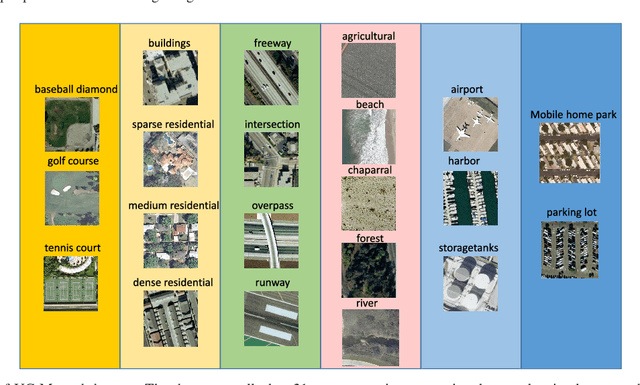
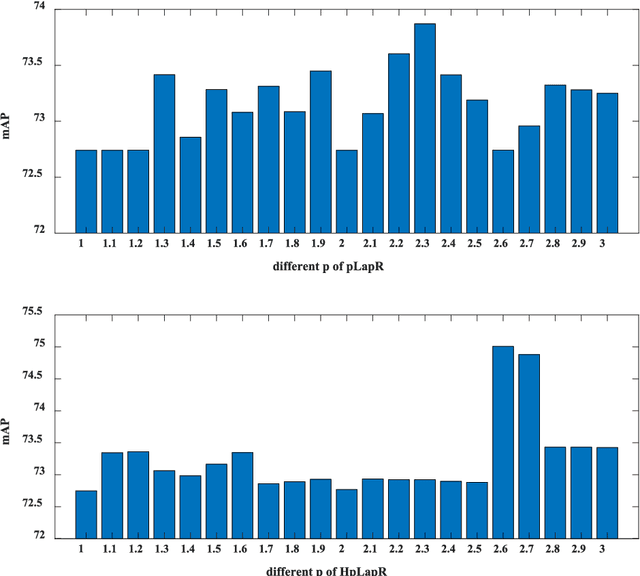
It is of great importance to preserve locality and similarity information in semi-supervised learning (SSL) based applications. Graph based SSL and manifold regularization based SSL including Laplacian regularization (LapR) and Hypergraph Laplacian regularization (HLapR) are representative SSL methods and have achieved prominent performance by exploiting the relationship of sample distribution. However, it is still a great challenge to exactly explore and exploit the local structure of the data distribution. In this paper, we present an effect and effective approximation algorithm of Hypergraph p-Laplacian and then propose Hypergraph p-Laplacian regularization (HpLapR) to preserve the geometry of the probability distribution. In particular, p-Laplacian is a nonlinear generalization of the standard graph Laplacian and Hypergraph is a generalization of a standard graph. Therefore, the proposed HpLapR provides more potential to exploiting the local structure preserving. We apply HpLapR to logistic regression and conduct the implementations for remote sensing image recognition. We compare the proposed HpLapR to several popular manifold regularization based SSL methods including LapR, HLapR and HpLapR on UC-Merced dataset. The experimental results demonstrate the superiority of the proposed HpLapR.